- +1
YOLOv5的妙用:学习手语,帮助听力障碍群体
选自Medium
作者:David Lee
机器之心编译
编辑:魔王、杜伟
计算机视觉可以学习美式手语,进而帮助听力障碍群体吗?数据科学家 David Lee 用一个项目给出了答案。
如果听不到了,你会怎么办?如果只能用手语交流呢?
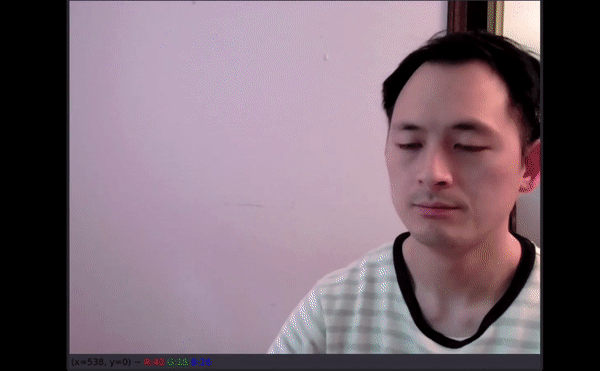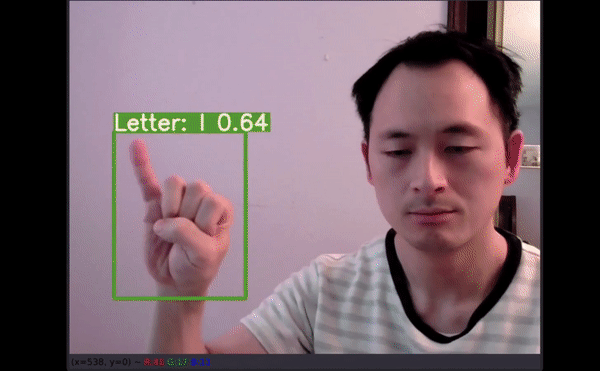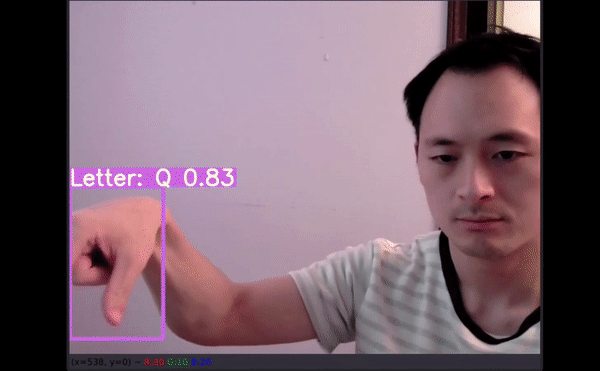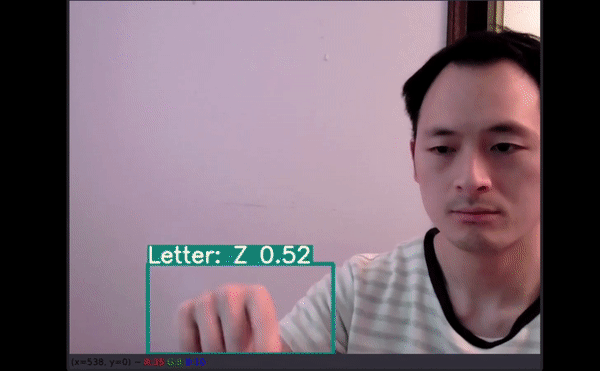
对普通人而言轻轻松松的事情对于听障群体可能是很困难的,他们甚至还会因此遭到歧视。在很多场景下,他们无法获取合格的翻译服务,从而导致失业、社会隔绝和公共卫生问题。
为了让更多人听到听障群体的声音,数据科学家 David Lee 尝试利用数据科学项目来解决这一问题:
计算机视觉可以学习美式手语,进而帮助听力障碍群体吗?
如果通过机器学习应用可以精确地翻译美式手语,即使从最基础的字母表开始,我们也能向着为听力障碍群体提供更多的便利和教育资源前进一步。
数据和项目介绍
出于多种原因,David Lee 决定创建一个原始图像数据集。首先,基于移动设备或摄像头设置想要的环境,需要的分辨率一般是 720p 或 1080p。现有的几个数据集分辨率较低,而且很多不包括字母「J」和「Z」,因为这两个字母需要一些动作才能完成。

项目地址:https://github.com/insigh1/GA_Data_Science_Capstone
数据变形和过采样
David Lee 为该项目收集了 720 张图片,其中还有几张是他自己的手部图像。由于这个数据集规模较小,于是 David 使用 labelImg 软件手动进行边界框标记,设置变换函数的概率以基于同一张图像创建多个实例,每个实例上的边界框有所不同。
下图展示了数据增强示例:

建模
David 选择使用 YOLOv5 进行建模。将数据集中 90% 的图像用作训练数据,10% 的图像用作验证集。使用迁移学习和 YOLOv5m 预训练权重训练 300 个 epoch。

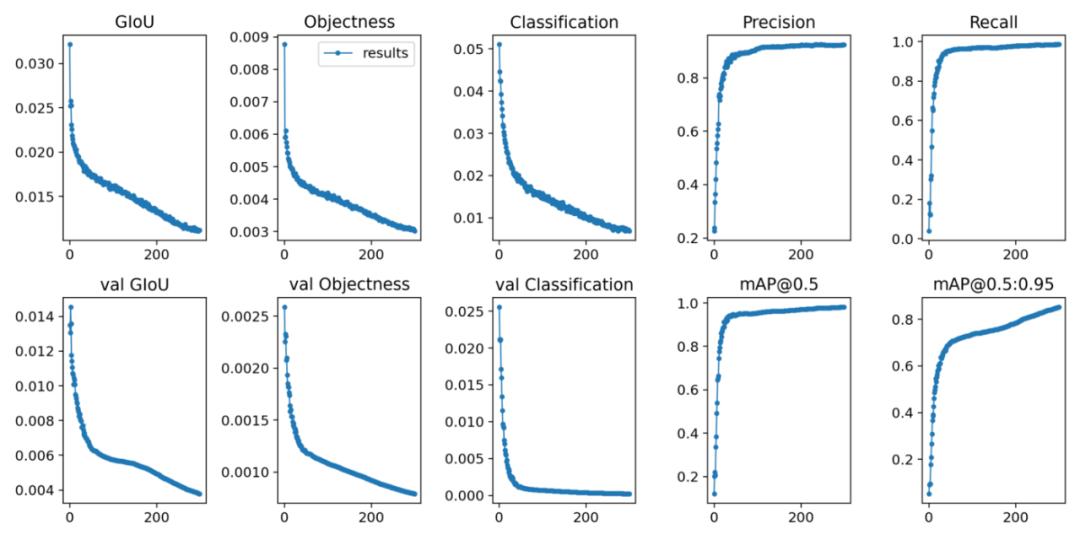
模型最终获得了 85.27% 的 mAP@.5:.95 分数。
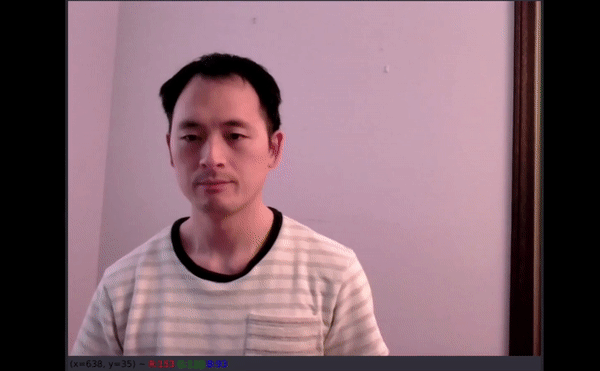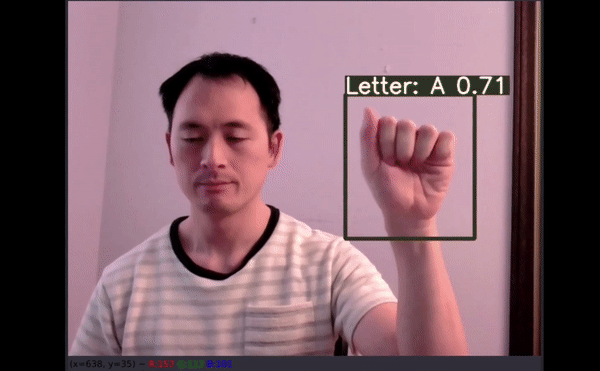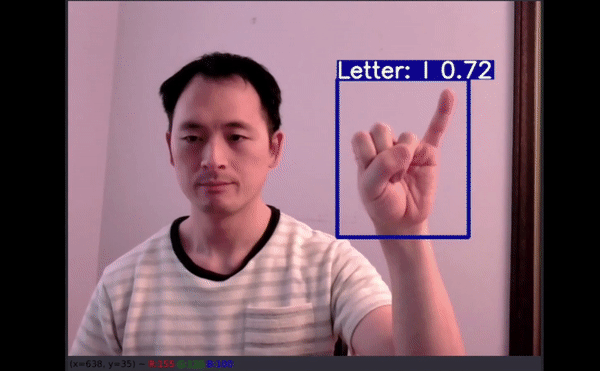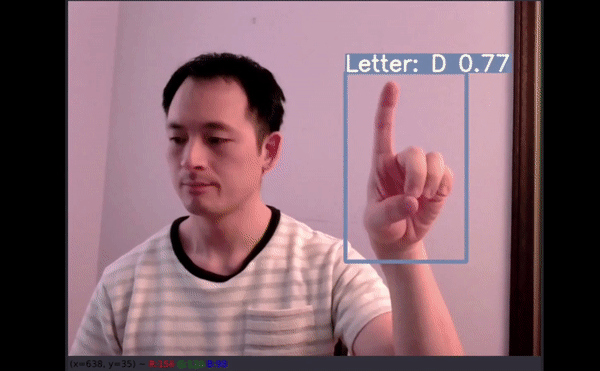
图像推断测试
David 额外收集了他儿子的手部图像数据作为测试集。事实上,还没有儿童手部图像用于训练该模型。理想情况下,再多几张图像有助于展示模型的性能,但这只是个开始。

四个没有得到准确预测:
D 被预测为 F;
E 被预测为 T;
P 被预测为 Q;
R 被预测为 U。
视频推断测试
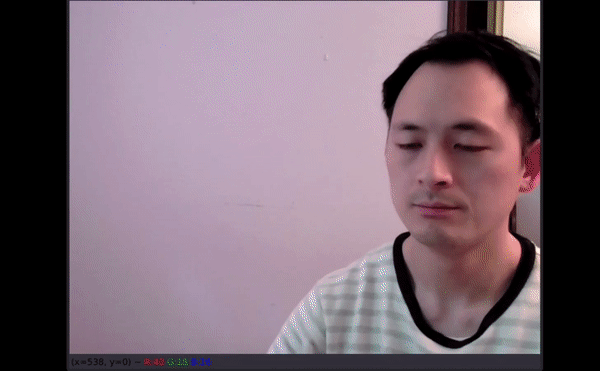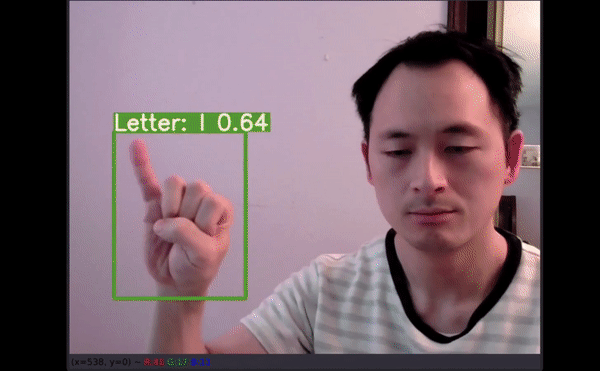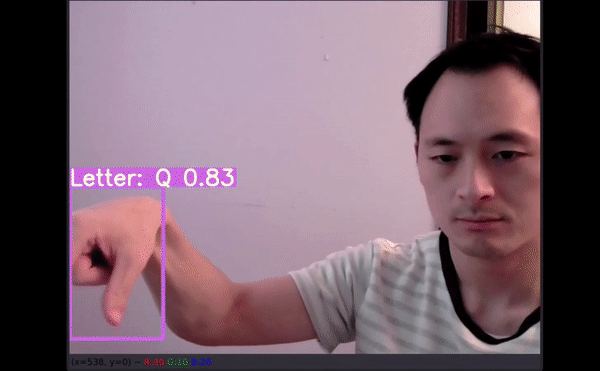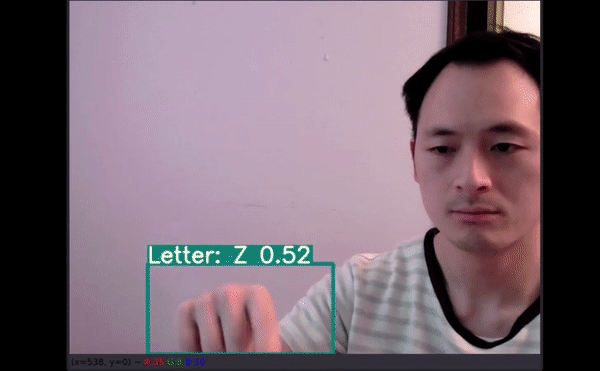
更多数据有助于创建可在多种新环境中使用的模型。
如以上视频所示,即使字母有一部分出框了,模型仍能给出不错的预测结果。最令人惊讶的是,字母 J 和 Z 也得到了准确识别。
其他测试
David 还执行了其他一些测试,例如:
左手手语测试
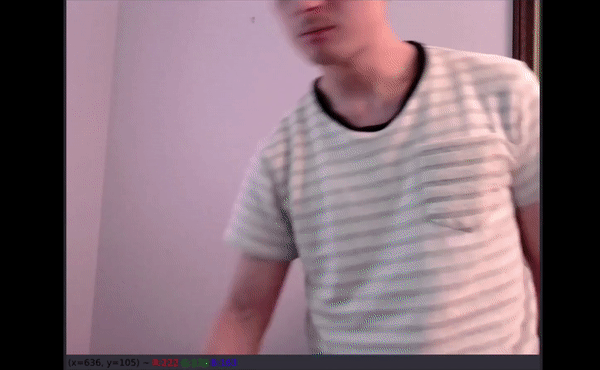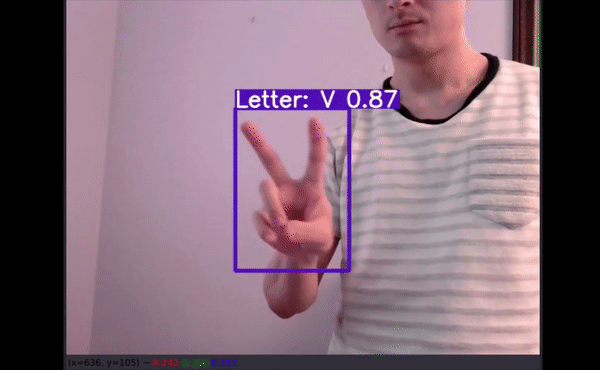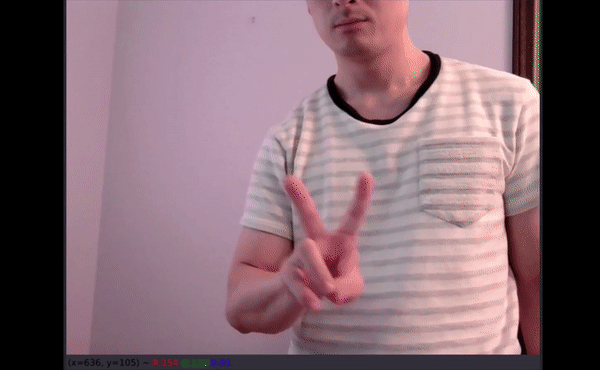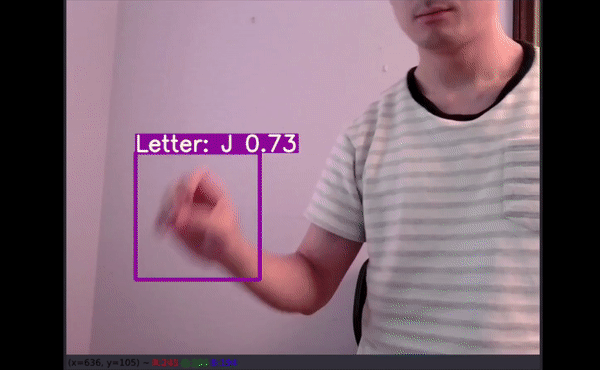
儿童手语测试

多实例

模型局限性
David 发现,该模型还有一些地方有待改进。
距离

新环境

背景推断
结论
这个项目表明:计算机视觉可用于帮助听力障碍群体获取更多便利和教育资源!
该模型在仅使用小型数据集的情况下仍能取得不错的性能。即使对于不同环境中的不同手部,模型也能实现良好的检测结果。而且一些局限性是可以通过更多训练数据得到解决的。经过调整和数据集的扩大,该模型或许可以扩展到美式手语字母表以外的场景。

Yolov5 GitHub 项目:https://github.com/ultralytics/yolov5
Yolov5 requirements:https://github.com/ultralytics/yolov5/blob/master/requirements.txt
Cudnn 安装指南:https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html
OpenCV 安装指南:https://www.codegrepper.com/code-examples/python/how+to+install+opencv+in+python+3.8
Roboflow 增强流程:https://docs.roboflow.com/image-transformations/image-augmentation
常用图像数据增强技术综述论文:https://journalofbigdata.springeropen.com/articles/10.1186/s40537-019-0197-0#Sec3
Pillow 库:https://pillow.readthedocs.io/en/latest/handbook/index.html
labelImg:https://github.com/tzutalin/labelImg
Albumentations 库:https://github.com/albumentations-team/albumentations
原文链接:https://daviddaeshinlee.medium.com/using-computer-vision-in-helping-the-deaf-and-hard-of-hearing-communities-with-yolov5-7d764c2eb614
原标题:《YOLOv5的妙用:学习手语,帮助听力障碍群体》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

