- +1
RTX3090时代,哪款显卡配得上我的炼丹炉?
机器之心报道
机器之心编辑部
黄老板的 RTX 30 系列显卡 9 月 17 日就要发售了,现在我要怎么买 GPU?很急很关键。
在 9 月 2 日 ,英伟达宣传了新显卡在性能上和效率上的优势,并称安培可以超过图灵架构一倍。但另一方面,除了 3090 之外,新一代显卡的显存看起来又有点不够。在做 AI 训练时,新一代显卡效果究竟如何?

众所周知,深度学习是一个很吃算力的领域,所以,GPU 选得好不好直接决定了你的炼丹体验。那么,哪些指标是你在买 GPU 时应该重视的呢?RAM、core 还是 tensor core?如何做出一个高性价比的选择?文本将重点讨论这些问题,同时指出一些选购误区。
选择 GPU 时你需要知道的东西
在选购 GPU 之前,你需要知道一些指标在深度学习中意味着什么。
首先是 Tensor Core,它可以让你在计算乘法和加法时将时钟周期降至 1/16,减少重复共享内存访问,让计算不再是整个流程中的瓶颈(瓶颈变成了获取数据的速度)。现在安培架构一出,更多的人可以用得起带 Tensor Core 的显卡了。
因为处理任务方法的特性,显存是使用 Tensor Core 进行矩阵乘法的周期成本中最重要的部分。具体说来,需要关注的参数是内存带宽(Bandwidth)。如果可以减少全局内存的延迟,我们可以进一步拥有更快的 GPU。
在一些案例中,我们可以体验到 Tensor Core 的强大,它是如此之快,以至于总是在等内存传来的数据——在 BERT Large 的训练中,Tensor Core 的 TFLOPS 利用率约为 30%,也就是说,70%的时间里 Tensor Core 处于空闲状态。这意味着在比较两个具有 Tensor Core 的 GPU 时,最重要的单一指标就是它们的内存带宽。A100 的内存带宽为 1555 GB/s,而 V100 的内存带宽为 900 GB/s,因此 A100 与 V100 的加速比粗略估算为 1555/900 = 1.73x。
我们预计两代配备 Tensor Core 的 GPU 架构之间的差异主要在于内存带宽,其他提升来自共享内存 / L1 缓存以及 Tensor Core 中更好的寄存器使用效率,预估的提升范围约在 1.78-1.87 倍之间。
在实际应用中,通过 NVLink 3.0,Tesla A100 的并联效率又要比 V100 提升 5%。我们可以根据英伟达提供的直接数据来估算特定深度学习任务上的速度。与 Tesla V100 相比,A100 的速度提升是:
SE-ResNeXt101:1.43 倍
Masked R-CNN:1.47 倍
Transformer(12 层机器翻译,在 WMT14 en-de 数据集上):1.70 倍
看来对于计算机视觉任务来说,新架构的提升相对不明显。这可能是因为小张量尺寸、准备矩阵乘法所需的运算无法让 GPU 满负载。也可能是由于特定架构(如分组卷积)导致的结果。在 Transformer 上,预估的提升和实际跑起来非常接近,这可能是因为用于大型矩阵的算法非常简单,我们可以使用这些实际效果来计算 GPU 的成本和效率。
当然,在发布会中英伟达着重指出:安培架构在稀疏网络的训练当中速度提升了一倍。稀疏训练目前应用较少,但是未来的一个趋势。安培还带有新的低精度数据类型,这会使低精度更加容易,但不一定比以前的 GPU 更快。
英伟达花费大量精力介绍了新一代 RTX 3090 的风扇设计,它看起来很好,但并联起来效果如何还要打上问号。在任何情况下水冷都是效果更好的方案,如果想要并联 4 块 GPU,你需要注意水冷的解决方案——它们可能会体积过大。解决散热问题的另一种方法是购买 PCIe 扩展器,并在机箱内原先不可能的位置放 GPU。这非常有效,华盛顿大学的其他博士研究生和作者本人使用这种方法都取得了成功。它看起来不漂亮,但是可以让你的 GPU 保持凉爽!

还有电源问题,RTX 3090 是一个 3 插槽 GPU,因此在采用英伟达默认风扇设计的情况下,你不能在 4x 的主板上使用它。这是合情合理的,因为它的标准功率是 350W,散热压力也更大。RTX 3080 的 320W TDP 压力只是稍稍小一点,想要冷却 4 块 RTX 3080 也将非常困难。
在 4x RTX 3090 的情况下,你很难为 4x 350W = 1400W 的系统找到很好的供电方式。1600W 的电源或许可以,但最好选择超过 1700W 的 PSU——毕竟黄仁勋在发布中希望你给单卡的 RTX 3080 装上 700W 的电源。然而目前市面上并没有超过 1600W 的台式电脑电源,你得考虑服务器或者矿机 PSU 了。
GPU 深度学习性能排行
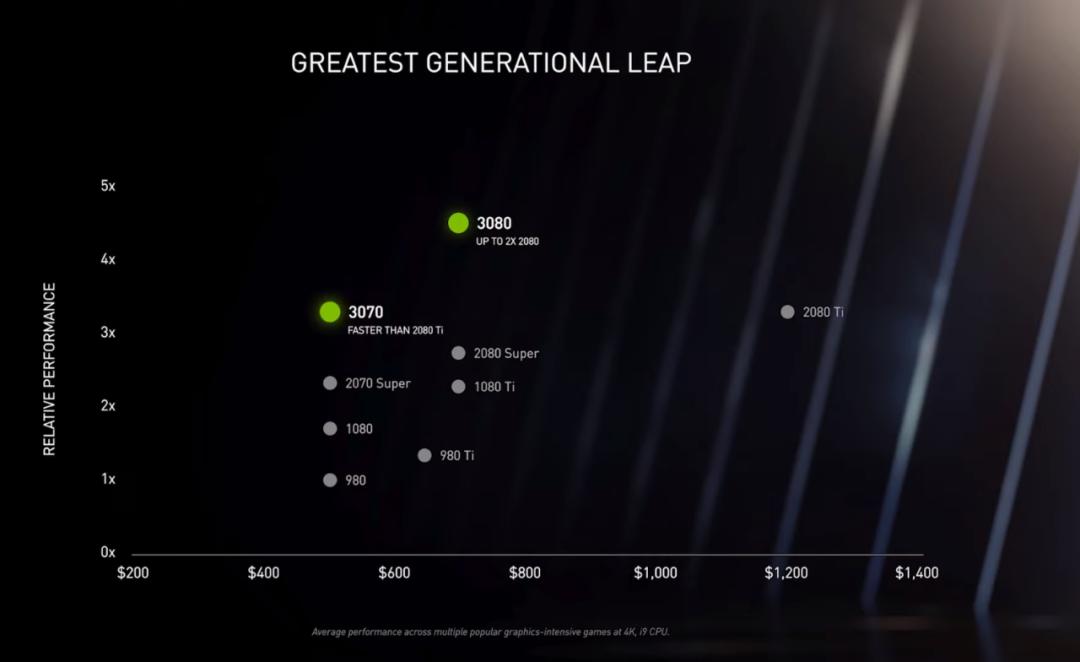
下图展示了当前热门的 Nvidia 显卡在深度学习方面的性能表现(以 RTX 2080 Ti 为对比基准)。从图中可以看出,A100(40GB)在深度学习方面表现最为强劲,是 RTX 2080 Ti 两倍还多;新出的 RTX 3090(24GB)排第二,是 RTX 2080 Ti 的 1.5 倍左右。但比较良心的是,RTX 3090 的价格只涨了 15%。
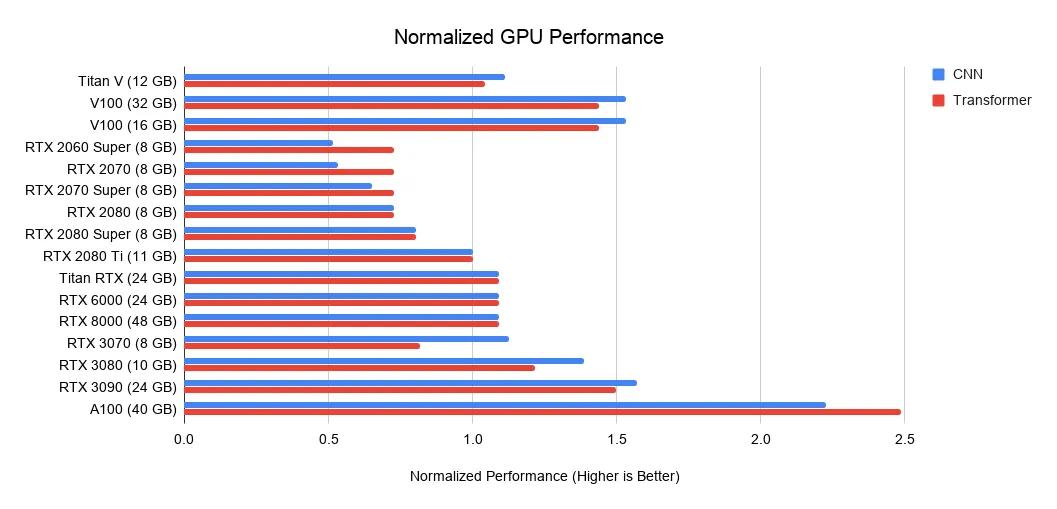
排在天梯图顶端的显卡确实是香,但普通人更关心的还是性价比,也就是一块钱能买到多少算力。在讨论这个问题之前,先来看一下各种任务的大致内存需求:
使用预训练 transformer 和从头训练小型 transformer:>= 11GB;
训练大型 transformer 或卷积网络:>= 24 GB;
原型神经网络(transformer 或卷及网络):>= 10 GB;
Kaggle 比赛:>= 8 GB;
应用计算机视觉:>= 10GB。
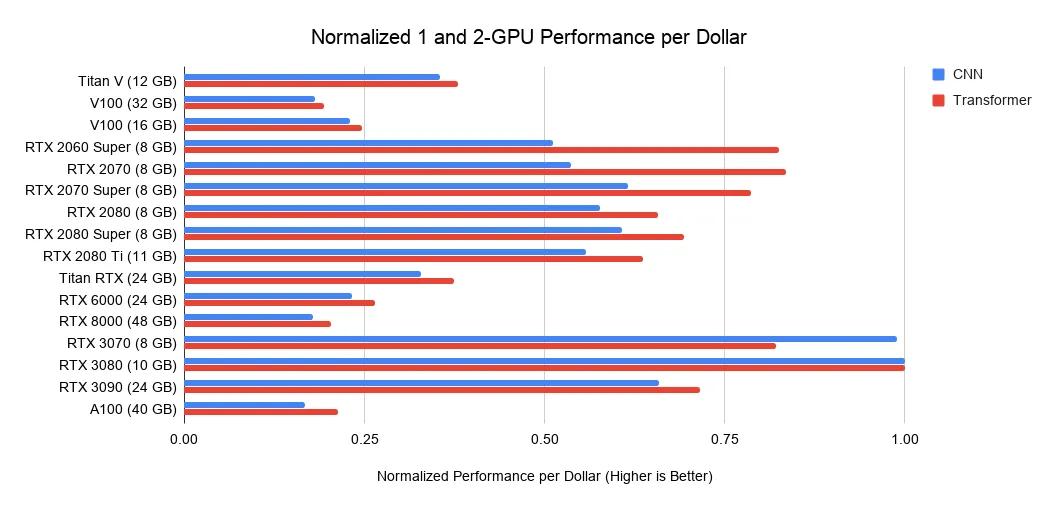
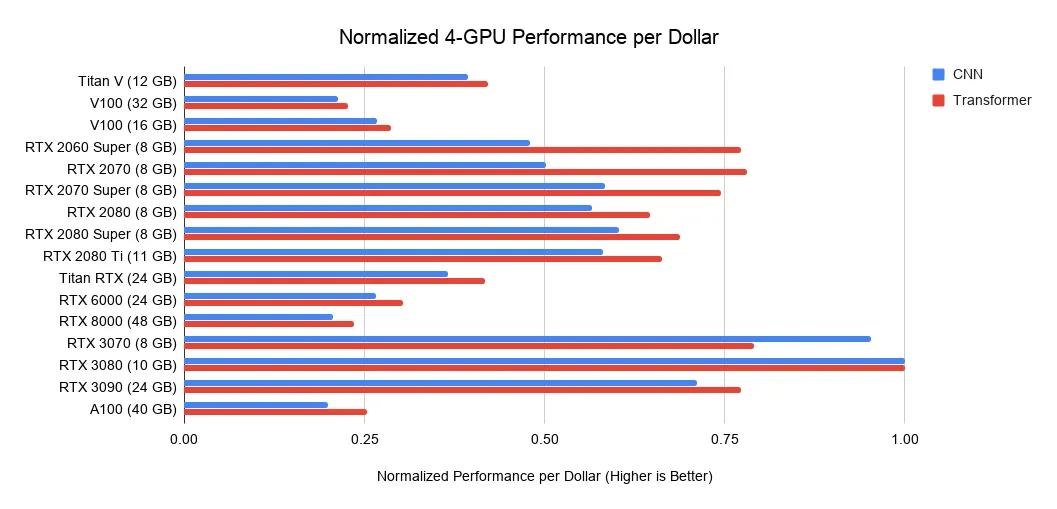
下图是根据各种 GPU 在亚马逊、eBay 上的价格和上述性能排行榜算出的「每一美元的 GPU 性能」:
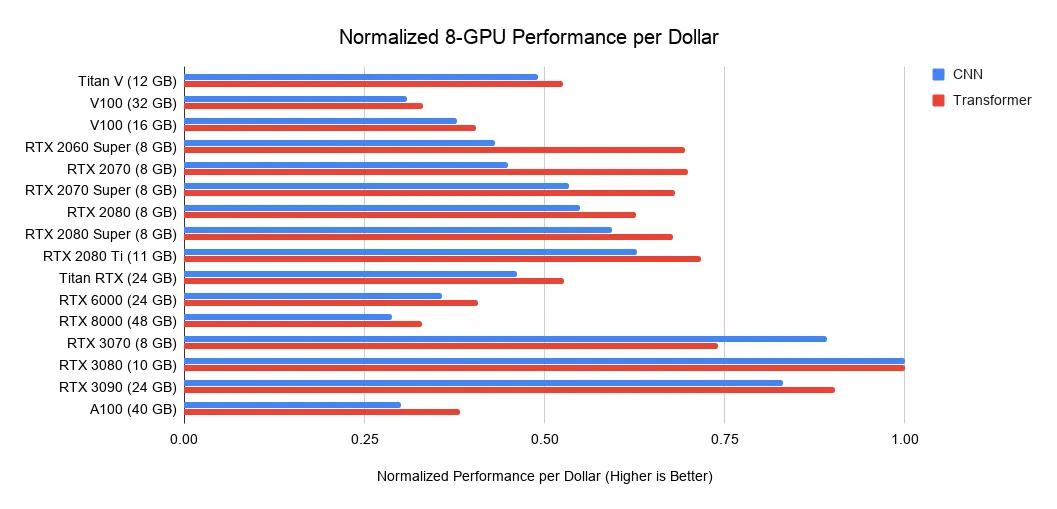
GPU 购买建议
这里首先强调一点:无论你选哪款 GPU,首先要确保它的内存能满足你的需求。为此,你要问自己几个问题:
我要拿 GPU 做什么?是拿来参加 Kaggle 比赛、学深度学习、做 CV/NLP 研究还是玩小项目?
为了实现我的目标,我需要多少内存?
使用上述成本 / 性能图表来找出最适合你的、满足内存标准的 GPU;
我选的这款 GPU 有什么额外要求吗?比如,如果我要买 RTX 3090,我能顺利地把它装进我的计算机里吗?我的电源瓦数够吗?散热问题能解决吗?
针对以上问题,作者给出了一些自己的建议:
什么情况下需要的内存 >= 11GB?
上面说过,如果你要使用预训练 transformer 或从头训练小型 transformer,你的内存至少要达到 11GB;如果你要做 transformer 方向的研究,内存最好能达到 24GB。这是因为,之前预训练好的那些模型大多都对内存有很高的要求,它们的预训练至少用到了 11GB 的 RTX 2080 Ti。因此,小于 11GB 的 GPU 可能无法运行某些模型。
除此之外,医学影像和一些 SOTA 计算机视觉模型等包含很多大型图像的任务(如 GAN、风格迁移)也都对内存有很高的要求。
总之,多留出来一些内存能让你在竞赛、业界、研究中多一丝从容。
什么情况下<11 GB 的内存就够用了?
RTX 3070 和 RTX 3080 性能都很强大,就是内存有点小。但在很多任务中,你确实不需要那么大的内存。
如果你想学深度学习,RTX 3070 是最佳选择,因为把模型或输入图像缩小一点就能学到大部分架构的基本训练技巧。
对于原型神经网络而言,RTX 3080 是迄今为止性价比最高的选择。在原型神经网络中,你想用最少的钱买最大的内存。这里的原型神经网络涉及各个领域:Kaggle 比赛、为初创公司开拓思路 / 模型、以及用研究代码进行实验。RTX 3080 是这些场景的最佳选择。
假设你要领导一个研究实验室 / 创业公司,你可以把 66-80% 的预算投到 RTX 3080 上,20-33% 用于推出带有强大水冷装置的 RTX 3090。这是因为,RTX 3080 性价比更高,而且可以通过一个 slurm 集群设置作为原型机共享。由于原型设计应该以敏捷的方式完成,所以应该使用更小的模型和更小的数据集,RTX 3080 很适合这一点。一旦学生 / 同事有了一个很棒的原型模型,他们就可以在 RTX 3090 机器上推出该模型并将其扩展为更大的模型。
建议汇总
总之,RTX 30 系列是非常强大的,值得大力推荐。选购时还要注意内存、电源要求和散热问题。如果你在 GPU 之间有一个 PCIe 插槽,散热是没有问题的。否则,RTX 30 系列需要水冷、PCIe 扩展器或有效的鼓风机卡。
作者表示,他会向所有买得起 RTX 3090 的人推荐这款 GPU,因为在未来 3-7 年内,这是一款将始终保持强大性能的显卡。他认为,HBM 内存在未来的三年之内似乎不会降价,因此下一代 GPU 只会比 RTX 3090 的性能提升 25% 左右。未来 5-7 年有望看到 HBM 内存降价,但那时你也该换显卡了。
对于那些算力需求没那么高的人(做研究、参加 Kaggle、做初创公司),作者推荐使用 RTX 3080。这是一个高性价比的解决方案,而且可以确保多数网络的快速训练。
RTX 3070 适合用来学深度学习和训练原型网络,比 RTX 3080 便宜 200 美元。
如果你觉得 RTX 3070 还是太贵了,可以选择一个二手 RTX 2070。现在还不清楚会不会有 RTX 3060,但如果你确实预算有限,可以选择再等等。
GPU 集群建议
GPU 集群的设计高度依赖于你的应用场景。对于一个 + 1024 GPU 的系统,网络是最重要的;但如果用户的系统一次只用 32 个 GPU,那大手笔投资网络基础设置就是一种浪费。
一般情况下,RTX 显卡被禁止通过 CUDA 许可协议接入数据中心,但通常高校例外。你可以与英伟达取得联系,以寻求豁免。
如果你被允许使用 RTX 显卡,作者推荐使用装有 RTX 3080 或 RTX 3090 的标准 Supermicro 8 GPU 系统(如果散热没问题的话)。一小组 8x A100 节点就可以保证原型的 rollout,特别是在无法保证 8x RTX 3090 服务器能够有效冷却的情况下。在这种情况下,作者推荐使用 A100,而不是 RTX 6000 / RTX 8000,因为 A100 性价比很高,也颇有潜力。
如果你想在 GPU 集群上训练非常大的网络,作者推荐装备了 A100 的 NVIDIA DGX SuperPOD 系统。在 +256 GPU 的规模下,网络变得非常重要。如果你想扩展到 256 个 GPU 以上,你就需要一个高度优化的系统。
如果到了 + 1024 GPU 的规模,市场上唯一有竞争力的方案就只剩下 Google TPU Pod 和 NVIDIA DGX SuperPod。在这个级别上,作者更推荐 Google TPU Pod,因为它们定制的网络基础设施似乎优于 NVIDIA DGX SuperPod 系统,尽管两个系统非常接近。
与 TPU 系统相比,GPU 系统可以为深度学习模型和应用提供更大的灵活性,但 TPU 系统也有优势,它可以支持更大的模型并提供更好的扩展。
这些 GPU 别买
不建议买 RTX Founders Edition(任何一个)或 RTX Titan,除非你有 PCIec 扩展器能解决散热问题。
不建议买 Tesla V100 或 A100,因为性价比不高,除非你被逼无奈或者想在庞大的 GPU 群集上训练非常大的网络。
不建议买 GTX 16 系列,这些卡没有张量核心,因此在深度学习方面性能较差,不如选 RTX 2070 / RTX 2060 / RTX 2060 Super。
什么时候不要入手新的 GPU?
如果已经拥有 RTX 2080 Ti 或更好的 GPU,升级到 RTX 3090 可能没什么意义。相比于 RTX 30 系列的 PSU 和散热问题,性能提升所带来的好处有些微不足道。从 4x RTX 2080 Ti 升级到 4x RTX 3090 的唯一原因可能是,在做 Transformer 或其他高度依赖算力去训练网络的研究。
如果你有一个或多个 RTX 2070 GPU,这也已经相当不错了。但如果常常受到 8GB 内存的限制,那么转让这些再入手新的 RTX 3090 是值得的。
一言以蔽之,如果内存不够,升级 GPU 还是很有意义的。
GPU 相关疑难问题解答
用户关于 GPU 肯定有很多不了解甚至是误解的地方,本文作者做出了以下相关问答总结,主要涉及 PCle 4.0、RTX3090/3080 以及 NVLink 等等。
我需要 PCle 4.0 吗?
一般来说不需要。如果你有一个 GPU 集群,那么拥有 PCle 4.0 棒极了。如果你有一个 8x GPU 机器,那么拥有 PCle 4.0 也挺好的。但除此之外,PCle 4.0 就没什么用。
PCle 4.0 可以实现更好的并行化处理以及更快的数据传输。但是数据传输不会成为任何应用中的瓶颈。在计算机视觉领域,数据存储可以成为数据传输 pipeline 的瓶颈,但从 CPU 到 GPU 的 PCle 传输却不会成为瓶颈。
所以对于大多数人来说,PCle 4.0 是没有必要的。在 4 个 GPU 设置下,PCle 4.0 只能实现 1%-7% 的并行化提升。
我需要 8x/16x PCle 通路吗?
与 PCle 4.0 一样,一般来说不需要。
在 4x 通路上运行 GPU 就挺好的,特别是当你只有 2 个 GPU 时。在 4 个 GPU 设置下,作者倾向于每个 GPU 上有 8x 通路,但如果你在全部 4 个 GPU 上进行并行化处理,则在 4x 通路上运行可能仅降低大约 5%-10% 的性能。
如果 4x RTX 3090 每个都占用 3 个 PCle 插槽,如何把它们塞进机箱?
你需要一个双插槽变体或者尝试使用 PCle 扩展器。除了空间外,还应该考虑冷却和合适的 PSU。所以最可行的解决方案是获取带有自定义水冷回路的 4x RTX 3090 EVGA Hydro Copper。
PCle 扩展器或许也可以同时解决空间和冷却问题,但你需要确保有足够的空间来扩展 GPU。
我可以使用多个不同型号的 GPU 吗?
当然可以。
也许你想要使用多个不同型号的 GPU 的原因是:想要利用旧的 GPU。这种情况下正常运行是没问题的,但这些 GPU 上的并行化处理将会非常低效,因为速度最快的 GPU 需要等待最慢的 GPU 来赶上一个同步点(通常是梯度更新)。
什么是 NVLink,它有用吗?
一般来说没有用。NVLink 是 GPU 之间的高速互连,当你拥有一个配备 128 个 GPU 以上的 GPU 集群时,它才有用。否则相较于标准 PCle 传输来说,NVLink 几乎没有任何益处。
即使是最便宜的 GPU,我也买不起,怎么办?
买二手 GPU 也没问题。二手的 RTX 2070(400 美元)和 RTX 2060(300 美元)都很棒,如果还是买不起,可以试试二手的 GTX 1070(220 美元)或 GTX 1070 Ti(230 美元),以及 GTX 980 Ti(6GB,150 美元)或 GTX 1650 Super(190 美元)。
实在不行,你还可以薅羊毛,去使用免费的 GPU 云服务。这种通常会有时间、账户等限制,超过之后需要付费。那么,就在不同账户之间切换使用吧,直到你买得起 GPU。
如何跨计算机并行化?
这样的话,需要 + 50Gbits/s 的网卡才能加快速度,之前作者写过一篇文章专门论述这件事(https://timdettmers.com/2014/09/21/how-to-build-and-use-a-multi-gpu-system-for-deep-learning/)。现在的建议是至少要上 EDR Infiniband,也就是至少 50 GBit / s 带宽的网卡,价格大概在 500 美元左右。
我需要一块英特尔 CPU 来支持多 GPU 设置吗?
不建议使用英特尔 CPU,除非你要在 Kaggle 竞赛中大量使用 CPU。即便如此,使用 AMD CPU 也很棒。就深度学习而言,AMD CPU 通常比 Intel CPU 更便宜且更好。
对于内置的 4x GPU,作者的首选是 Threadripper。在大学期间作者曾使用 Threadripper 搭建了数十个系统,它们都运行良好。对于 8x GPU 系统,CPU 和 PCIe / 系统的可靠性比直接的性能或性价比更重要。
我要等等 RTX 3090 Ti 吗?
首先,我们不确定会不会有 RTX 3080 Ti / RTX 3090 Ti / RTX Ampere Titan。
GTX XX90 的名称通常会留给双 GPU 卡,现在英伟达算是打破了这个规则。从价格和性能上看,RTX 3090 似乎取代了 RTX 3080 Ti。
如果你感兴趣,可以在几个月内密切关注一下相关消息。如果没有什么进展,也就意味着不太可能有 RTX 3080 Ti / RTX 3090 Ti / RTX Ampere Titan 了。
电脑机箱的设计对于散热是否重要?
并不。
如果 GPU 之间存在间隙的话,通常能够很好地冷却。机箱的设计会带来 1-3 摄氏度的效果提升,但 GPU 之间的空间将带来 10-30 摄氏度的效果提升,所以说只要 GPU 之间留有空间,散热就不成问题。但如果 GPU 之间没有空间,则需要好的散热器设计(风扇)和其他解决方案(水冷、PCIe 扩展)。
总而言之,散热与机箱设计和机箱风扇都没关系。
AMD GPU + ROCm 是否会赶上 NVIDIA GPU + CUDA?
在未来 1 到 2 年内不会。这个问题分三方面:张量核心、软件和社区。
就纯硅芯片来说,AMD 的 GPU 非常优秀:出色的 FP16 性能和内存带宽。但与英伟达 GPU 相比,在缺少张量核心或等效条件下,AMD 的深度学习性能更差。大量的低精度数学运算也未能解决这个问题。达不到这种硬件功能,AMD GPU 将永远无法与之竞争。有传言表明,一些与张量核心等效的 AMD 数据中心卡计划于 2020 年推出,但估计很少有人会买吧。
即便假设 AMD 将来会推出类似张量核心的硬件功能,但很多人也会说:「可是没有适用于 AMD GPU 的软件,我该如何使用它?」这里存在一些误解,AMD ROCm 平台日渐成熟,并且对 PyTorch 也实现了原生支持,大可不必担心。
如果你解决了软件和不具有张量核心的问题,还会意识到另外一个问题:AMD 的社区不成熟。如果你在使用英伟达 GPU 时遇到了什么问题,可以 Google 一下找到解决方案,而且还能了解到很多的使用技巧和专业人士的经验帖。AMD 在这方面就不那么尽如人意了。
拿编程语言来举例的话,就像是 Python 和 Julia 的关系。Julia 被认为潜力巨大,而且是科学计算领域的高级编程语言,但其使用者数量与 Python 完全无法相提并论。归根结底是因为 Python 社区非常完善。
综上所述,在深度学习领域,英伟达至少还可以垄断两年。
与专用 GPU 台式机 / 服务器相比,何时使用云计算更好?
1 个建议:如果你从事深度学习超过一年,请使用台式机 GPU。
一般来说,台式机 GPU 的利用率如下:
博士生个人台式机:<15%;
博士生 slurm GPU 集群:>35%;
企业级 slurm 研究集群:>60%。
在前沿研究重要性高于开发实体产品的行业,专用 GPU 的利用率较低。从研究领域上看,一些领域的利用率很低(可解释性研究),另一些领域的利用率则高得多(机器翻译、语言建模)。通常人们都会高估个人计算机的利用率,所以作者强烈建议研究小组和企业使用 slurm GPU 集群,但个人的话就不必了。
长求总
现在最好的 GPU:RTX 3080 和 RTX 3090。
对于个人来说,这些 GPU 不要买:任何 Tesla 卡、任何 Quadro 卡、任何「创始版」GPU,还有包括 Titan RTX 的所有型号泰坦。
性价比高,但比较贵的:RTX 3080。
性价比高,且较便宜的:RTX 3070 和 RTX 2060 Super。
还想再便宜点?推荐度依次递减:RTX 2070 ($400)、RTX 2060 ($300)、GTX 1070 ($220)、GTX 1070 Ti ($230)、GTX 1650 Super ($190) 和 GTX 980 Ti (6GB $150)。
什么也别说了,我没有钱:请使用各家云服务的免费额度,直到你买得起 GPU。
我要搞 Kaggle:RTX 3070。
我是一个高端的计算机视觉、预训练模型或者机器翻译研究人员:四块 RTX 3090 并联,但请等散热压得住的版本出现,而且也要考虑电源负载(作者还会继续更新这篇文章,可以等待未来的评测)。
我是普通 NLP 研究者:如果不研究机器翻译、语言模型、预训练等,一块 RTX 3080 应该就够了。
我要入门深度学习,不开玩笑:你可以从购买一块 RTX 3070 开始,如果半年之后仍然热情不减,你可以把 RTX 3070 出售,购买四块 RTX 3080。再远的未来,随着你选择路线不同,需求也会出现变化。
我想试试深度学习:RTX 2060 Super 非常出色,但你可能需要为它更换电源。如果你的主板有 PCIe×16 卡槽,电源有 300W,一块 GTX 1050Ti 是最适合的。
我们组要搭建一百块 GPU 的集群:66% 的八块 RTX 3080 并联和 33% 的八块 RTX 3090 并联是最好选择,但如果 RTX 3090 的冷却真的有问题,你可能需要买 RTX 3080 或 Tesla A100 作为代替。
128 块以上的 GPU 集群:在这个规模上,8 块成组的 Tesla A100 效率更高。如果超过 512 块 GPU,你应该使用 DGX A100 SuperPOD 系统。
作者简介

值得一提的是,Tim Dettmers 在申请读博方面也颇有心得,他拿到了斯坦福大学、华盛顿大学、伦敦大学学院、卡内基梅隆大学以及纽约大学的 offer 并最终选择了华盛顿大学。在 2018 年的一篇博客文章中,他总结了自己申请读博的经验和技巧,需要的同学可以去读一下:《》 。
原文链接:https://timdettmers.com/2020/09/07/which-gpu-for-deep-learning/#How_do_I_cool_4x_RTX_3090_or_4x_RTX_3080
在今年 KDD CUP 中,美团到店广告平台搜索广告算法团队获得了两冠一季的成绩。
为了让大家更清晰地了解如何在竞赛中获胜,9月10日机器之心最新一期线上分享活动邀请到美团搜索广告算法团队成员漆毅,为我们介绍这三道赛题的解决方案。添加机器之心小助手(syncedai5),备注「KDD」,入群一起看直播。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《时代变了,大人:RTX 3090时代,哪款显卡配得上我的炼丹炉?》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

