- +1
常识知识确能被捕获,西湖大学博士探究BERT如何做常识问答
选自arXiv
作者:Leyang Cui等
编辑:小舟、杜伟
BERT 是通过常识知识来解决常识任务的吗?

尤其是,BERT 是依靠浅层句法模式还是较深层常识知识来消除歧义是一个有趣的研究课题。
近日,来自西湖大学、复旦大学和微软亚洲研究院的研究者提出了两种基于注意力的方法来分析 BERT 内部的常识知识,以及这些知识对模型预测的贡献。论文一作 Leyang Cui 为西湖大学文本智能实验室(Text Intelligence Lab)的在读博士生。
该研究发现,注意力头(attention head)成功捕获了以 ConceptNet 编码的结构化常识知识,从而对 BERT 直接解决常识任务提供帮助。此外,微调进一步使 BERT 学习在更高层次上使用常识知识。

任务和模型
在讲解 BERT 的应用之前,研究者首先简要介绍了 CommonsenseQA 的相关知识。
CommonsenseQA
CommonsenseQA(Talmor 等人,2019 年)是一个基于 ConceptNet 知识图谱(Speer 等人,2017 年)构建的多项选择问答数据集,它由关系对的大规模三元集合,即源概念、关系和目标概念组成,「鸟、栖息和乡村」就是一个典型示例。
如下图 2 所示,给定源概念「鸟」和关系类型「栖息」,则存在 3 个目标概念「笼子」、「窗台」和「乡村」。在 CommonsenseQA 数据集的开发过程中,要求参与者分别基于源概念和 3 个目标概念来生成问题和候选答案。
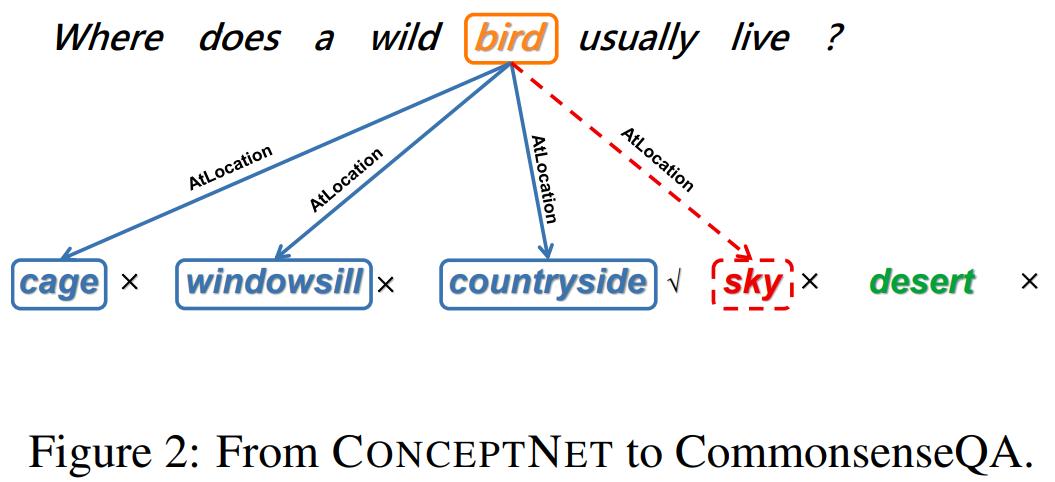
基于 Talmor 等人(2019 年)的研究,研究者将问题中的源概念称为问题概念(question concept),将答案中的目标概念称为答案概念(answer concept)。
为了使任务更加困难,研究者还添加了两个不正确的答案。研究者将 commonsene 链接定义为从答案概念到问题概念的链接。
此外,为了分析基于从答案概念到问题概念的链接的隐式结构常识知识,研究者选择过滤掉了一些问题,并且过滤掉的这些问题不包含 ConceptNet 形式的问题概念(如释义)。
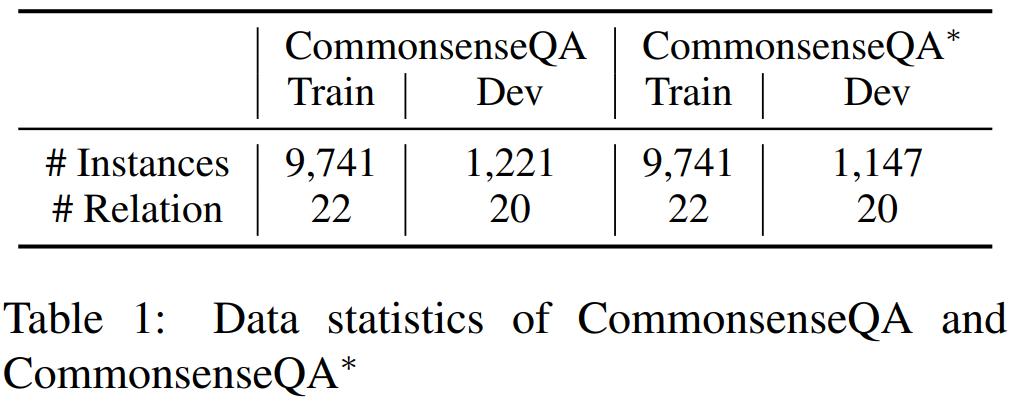
下表 1 汇总了数据集 CommonsenseQA 和 CommonsenseQA * 的详细数据:
研究者采用 Talmor 等人在 2019 年提出的方法,在 CommonsenseQA 上使用 BERT(Devlin 等人,2019 年)。结构如下图 3 所示:
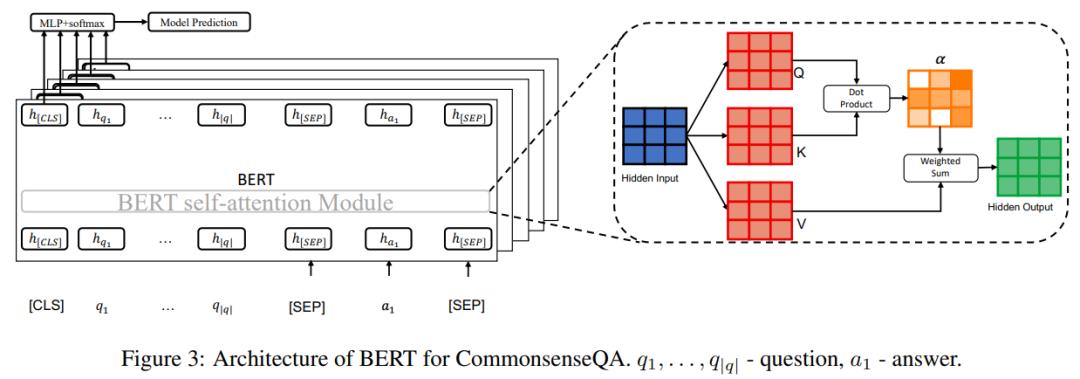
BERT 由 L 个 stacked Transformer 层(Vaswani 等人,2017 年)组成,以对每个句子进行编码。所以,[CLS] token 最后一层的隐状态用于带有 softmax 的线性分类,并且 s_1, ... , s_5 中得分最高的候选对象被选为预测答案。
分析方法
该研究使用注意力权重和相应的归因得分(attribution score)来分析常识链接。
注意力权重
给定一个句子,我们可以将 Transformer 中的注意力权重视为生成下一层表示过程中,每个 token 与其他 token 之间的相对重要性权重(Kovaleva 等人,2019 年;Vashishth 等人,2020 年)。
注意力权重α通过 Q = W^QH 中查询向量和 K = W^KH 中核心向量的缩放点积(scaled dot-product)来计算,然后得到 softmax 归一化:
归因得分
Kobayashi 等人指出,仅分析注意力权重可能不足以调查注意头的行为,因为注意力权重忽略了隐藏向量 H 的值。
作为注意力权重的补充,已经研究了基于梯度的特征归因方法来解释反向传播中每个输入特征对模型预测的贡献。对注意力权重和相应的归因得分的分析有助于更全面地理解 BERT 中的常识链接。
研究者使用一种名为集成梯度(Integrated Gradient,Sundararajan 等人 2017 年提出)的归因方法来解释 BERT 中的常识链接。直观地讲,集成梯度方法模拟剪枝特定注意力头的过程(从初始注意力权重α到零向量α'),并计算反向传播中的集成梯度值。
归因得分直接反映出了注意力权重的变化会对模型输出造成多大程度的改变。通常来说,归因得分越高表示单个注意力权重越重要。
BERT 是否包含结构化常识知识?
研究者首先进行了一组实验来探究常识链接权重,从而可以反映出常识知识是否会被句子的 BERT 表示捕获。
直观地讲,如果答案概念到问题概念的链接权重高于答案概念到其他疑问词的链接权重,则 ConceptNet 中的常识知识是通过经验表示捕获的。
值得注意的是,[CLS] token 的表示不是问题概念,而是直接连接至输出层以进行候选评分。因此,在预训练和微调阶段,对于输出层以及答案概念 token 到问题概念 token 的链接权重,都没有直接的监督信号。
探测任务(probing task)
研究者通过计算最相关的词(most associated word, MAW)来评估链接权重,其中 MAW 是从所有疑问词中的答案概念中获得最大链接权重的问题概念词。研究者计算了每层中每个注意力头的 MAW。
实验结果
下表 2 展示了对于不同的常识关系,原始归一化 BERT 和在 CommonsenseQA 上微调的 BERT 模型的平均和最大准确率结果:
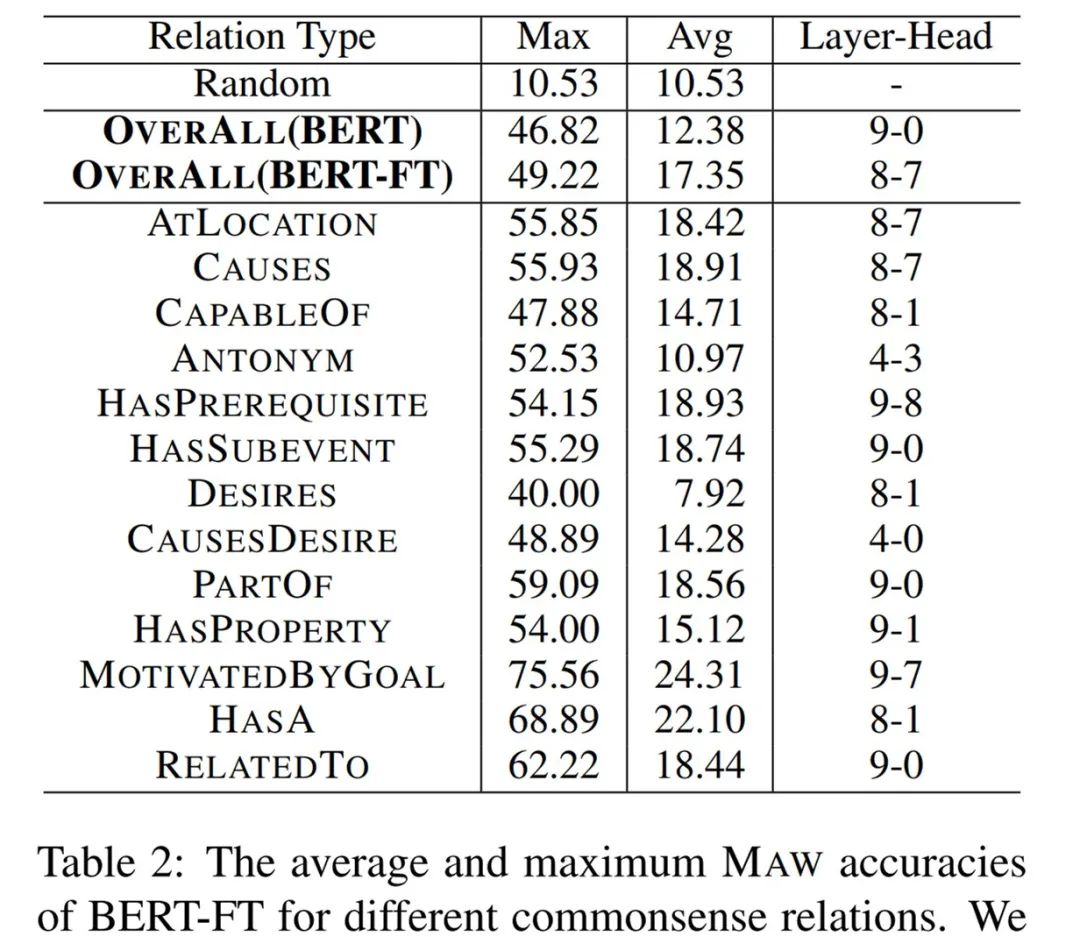
其次,就平均 MAW 准确率和最大 MAW 准确率而言,BERT-FT 均优于 BERT。这表明对常识任务的监督训练可以增强结构化的常识知识。
BERT 如何将常识知识用于常识任务?
研究者进一步进行了一组实验,来描述常识链接与模型预测之间的相关性。目的是为了研究不同候选答案概念到问题概念的链接权重是否会对这些候选答案之间的模型决策造成影响。
具体而言,研究者比较了 5 个候选答案对于同一问题的链接权重,并找出了与相关问题概念最相关的候选答案。这个候选答案被称为最相关候选对象(most associated candidate, MAC)。MAC 和每个问题的模型预测之间也存在着相关性。直观地讲,如果 MAC 与模型预测呈现相关性,则证明模型在预测过程中运用到了常识知识。
研究者进行实验来评估 MAC 对模型决策的贡献,以及 MAC 依赖与输出准确率之间的相关性。实验中使用注意力权重和归因得分来测量链接,这是因为在考虑模型预测时梯度会发挥作用。
此外,对于所有试验来说,归因得分的趋势与使用注意力权重测量的结果保持一致。
探测任务
从形式上,给定一个问题 q 和 5 个候选答案 a1, ..., a5,研究者对相应的 5 个候选句子 s1, ..., s5 进行比较。在每个候选句子中,研究者根据 ConceptNet 计算了答案概念到问题概念的链接权重。
研究者通过测量答案概念到 [CLS]token 的链接权重,进一步定义了最相关句子(most associated sentence, MAS)。这是因为梯度是从 [CLS]token 后向传播,而不是从问题概念或答案概念。
此外,通过比较 MAC 和 MAS,研究者可以获得 MAC 是否对模型决策造成影响的有用信息。
常识链接的重要性
研究者测量了 BERT-FT 和 BERT-Probing(这是一个仅针对输出层进行微调的 BERT 变体)的 MAC 性能,其中 BERT-Probing 是一个线性探测(linear probing)模型。直观地讲,如果线性分类器可以预测常识任务,则未经微调的原始模型可能会编码丰富的常识知识。
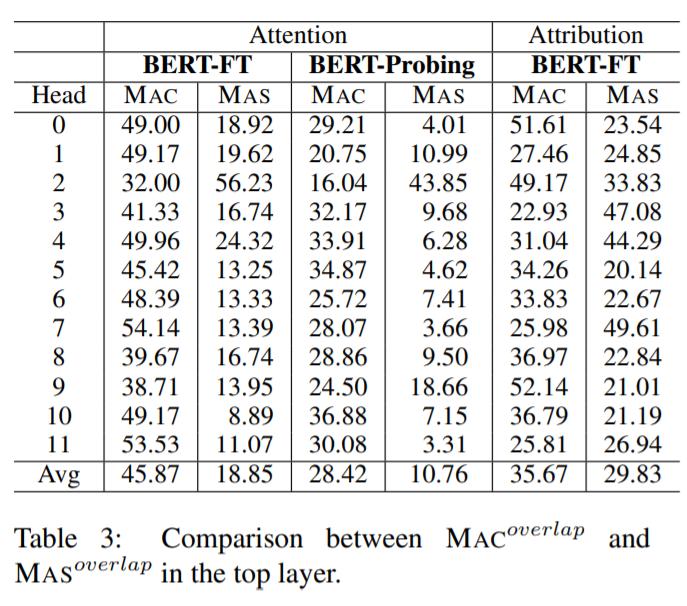
下表 3 为 top Transformer 层中 12 个注意力头条件下,MAC 和 MAS 的重叠率(overlapping rate):
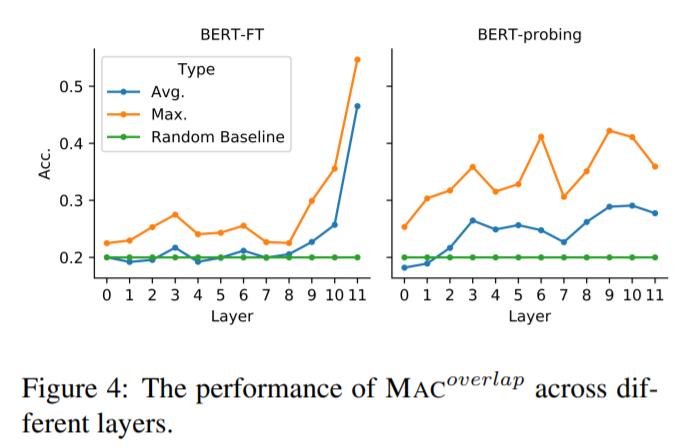
为了进一步探究常识知识对模型预测的贡献,下图 4 展示了每个 Transformer 层上 MAC 和模型预测之间的重叠率:
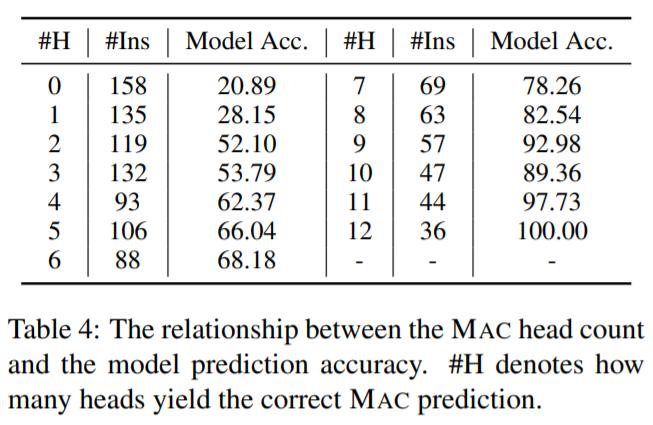
最后,研究者进一步探究了常识知识使用上的两个具体问题。其一,在决策过程中,BERT 最依赖哪个层?其二,BERT 使用的常识知识来自预训练或微调吗?为此,研究者通过连接每个 Transformer 层上的输出层,对 12 个模型变体进行了比较。
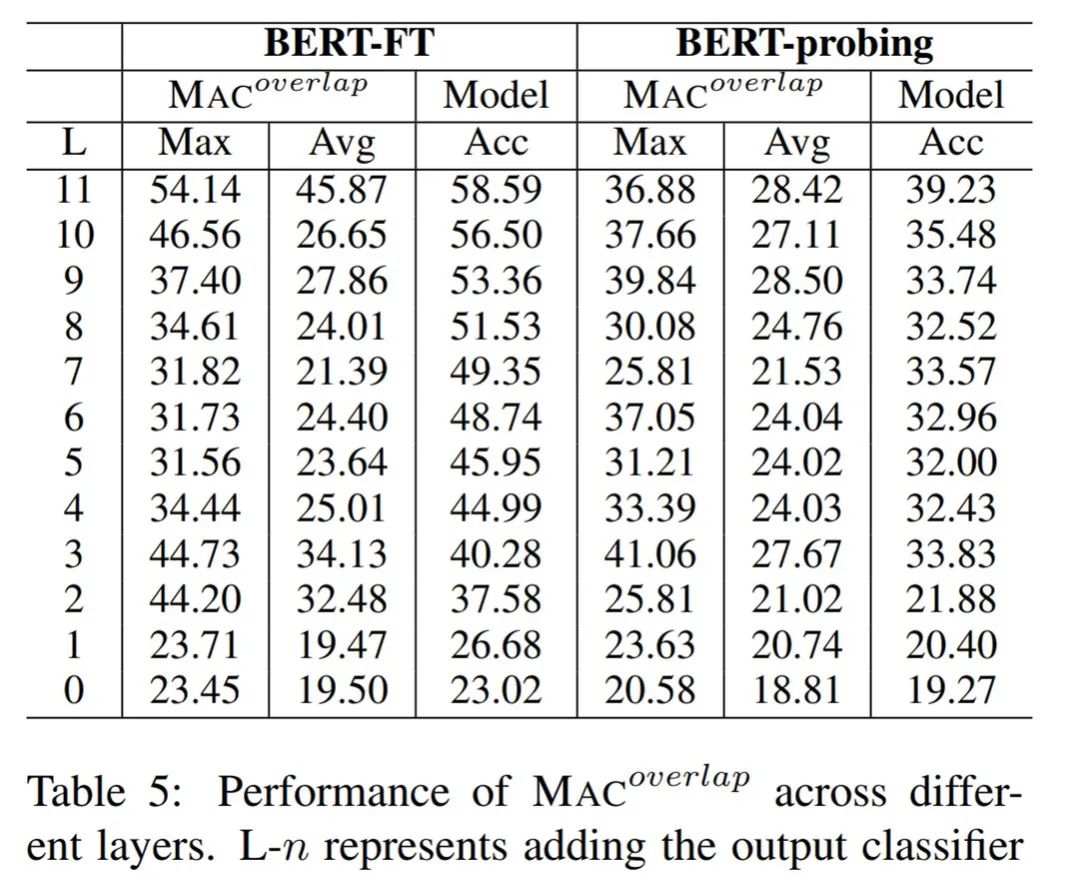
下表 5 展示了模型准确率和 MAC 重叠率的数据:
现在,企业开发者可以免费领取1000元服务抵扣券,轻松上手Amazon SageMaker,快速体验5个人工智能应用实例。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《常识知识确能被捕获,西湖大学博士探究BERT如何做常识问答》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2025 上海东方报业有限公司

