- +1
Nature子刊:用“反事实推断”帮模型识别罕见病,跻身专家水平
机器之心报道
编辑:魔王
如果说科学的本质是寻找变量之间的因果关系,那么过去几年机器学习的研究和努力依然没有触及问题的本质。正如图灵奖获得者、贝叶斯网络之父 Judea Pearl 所言,机器学习不过是在拟合数据和概率分布曲线,而变量的内在因果关系并未得到足够的重视。如果要真正解决科学问题,甚至开发真正意义上的智能机器,因果关系是必然要迈过的一道坎。最近发表在 Nature Communications 上的一项研究通过建立反事实因果诊断模型,提升了机器学习在医疗诊断领域的效果。

近年来,人工智能和机器学习成为解决不同领域复杂问题的强大工具。在医疗诊断方面,机器学习辅助诊断有望通过大量病人数据提供精确、个性化的诊断,从而革新临床决策和诊断。
然而,人类医生的诊断流程与现有的机器学习诊断方法从原理上来说大相径庭。
在医疗诊断中,医生需要确定病因,进而向病人解释症状。然而,现有的机器学习诊断方法是完全基于相关性的,它可以识别出与病人症状强相关的疾病。
最近,来自英国数字医疗公司 Babylon Health 的研究人员在《Nature Communications》上发表论文,表明无法将相关性与因果性解耦会导致次优甚至危险的诊断结果。为了克服这一点,该研究将诊断重新形式化为反事实推断(counterfactual inference)任务,并得到反事实诊断算法。
研究人员将其反事实算法与标准关联算法(associative algorithm)和 44 名医生进行性能对比。结果表明,关联算法的准确率在医生团队中能排到 top 48%,而反事实算法可以排到 top 25%,实现了专家级别的临床准确率。
这一结果表明:因果推理是将机器学习应用到医疗诊断中的重要缺失元素。

这篇论文先介绍了当前算法诊断方法的底层基本原则和假设;然后详述了这类方法由于因果混杂(causal confounding)而崩溃的场景,并提出了设计能够克服这些缺陷的诊断算法的一组原则;最后,研究人员利用这些原则提出了两种诊断算法,它们均基于必要且充分的因果关系。
关联诊断
因其形式定义,基于模型的诊断等同于:给出发现结果 ϵ,使用模型 θ 估计 fault component D 的似然:

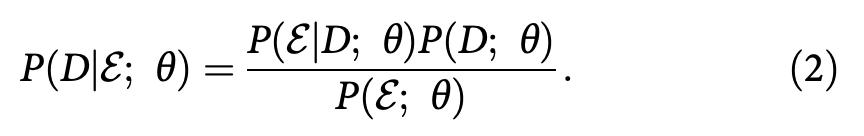
因果诊断
基于人类医生的诊断流程,这项研究提出了「因果诊断」的定义:
基于病史,识别出最可能导致病人症状的疾病。
尽管大量文献将因果推理置于诊断的核心位置,但迄今为止尚未有基于模型的诊断方法使用现代因果分析技术。
利用后验来识别因果关系在绝大多数因果场景中会导致谬误的结论(最简单的因果场景除外),这种现象叫做「因果混杂」(confounding)。
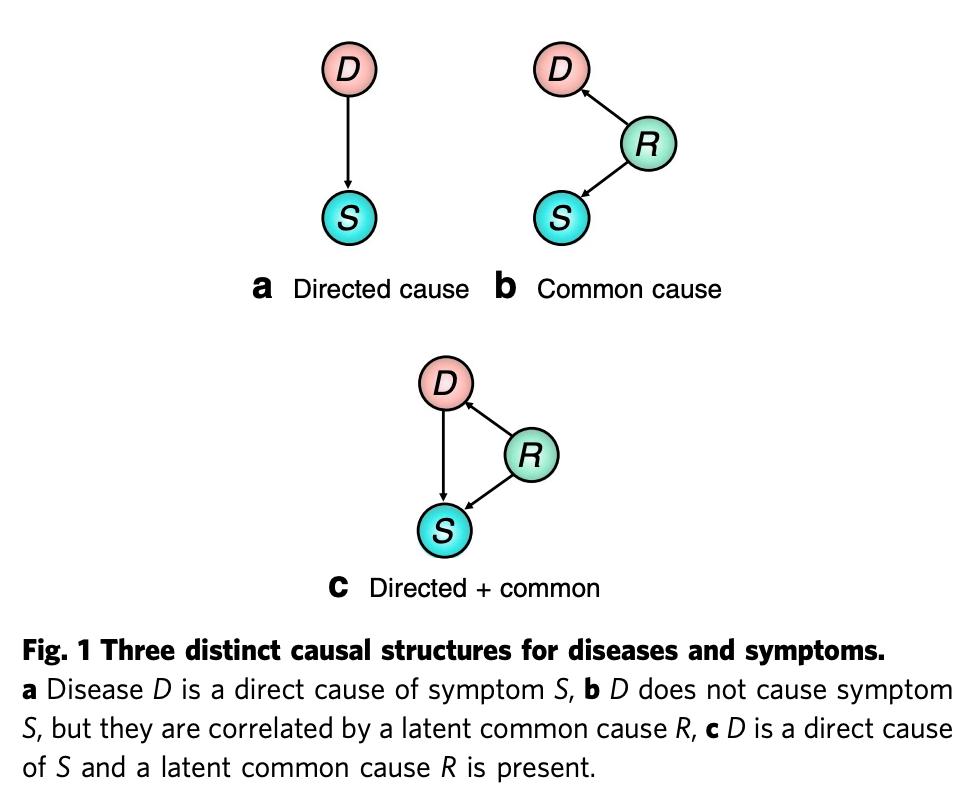
下图 1 展示了疾病与症状之间的 3 种不同的因果结构,图 b 中的 R 即是 D 和 S 的混杂因素。
关联诊断方法的替代方案是推断因果责任(或因果归因)——目标原因 D 导致目标结果 S 的概率。这就需要一个诊断度量 M(D, ϵ),对存在证据 ϵ 的情况下,疾病 D 导致病人症状的概率进行排序。为满足这一诊断度量,研究人员提出了以下三个基本原则:
1. 疾病 D 导致病人症状的可能性应与疾病的后验似然成比例,
1(一致性);
2. 未导致病人症状的疾病 D 不构成诊断,M(D, ϵ) = 0(因果性);
3. 能够解释更多病状的疾病应具备更高的可能性(简洁性)。
反事实诊断
为了量化疾病导致病状的似然,该研究使用了反事实推断。研究人员提出两种反事实诊断度量,分别定义了「expected disablement」和「expected sufficiency」。定理 1 表明这两种度量均满足上述三原则。



新型诊断模型:结构因果模型
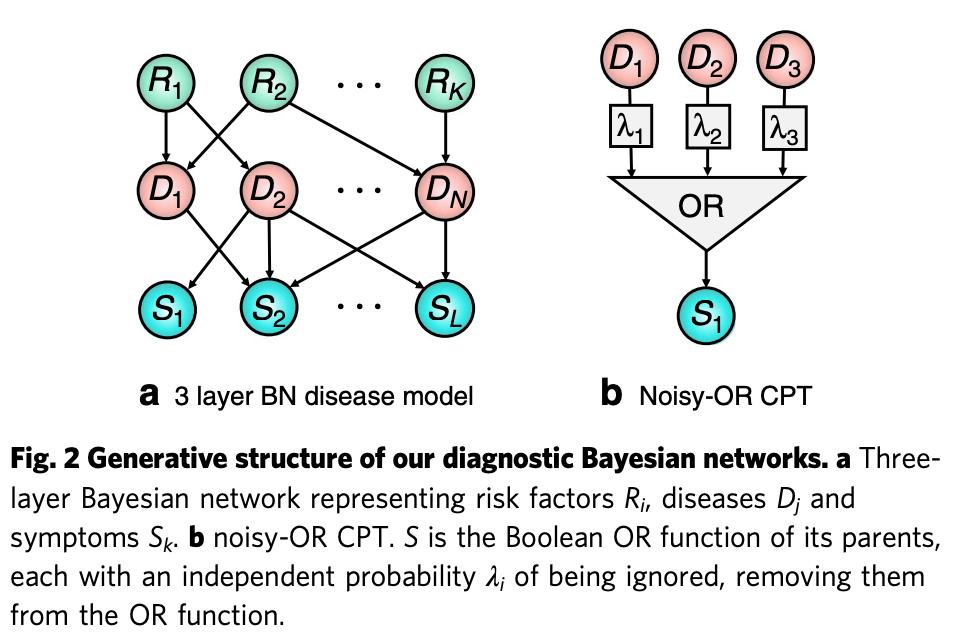
该研究使用的疾病模型是贝叶斯网络(BN),可建模数百种疾病、风险因子和症状之间的关系。
BN 是一个有向无环图(DAG),下图 2a 即是 BN 的一个简单示例。
Noisy-OR twin 诊断网络
在构建疾病模型时,通常会在 DAG 结构以外做出一些额外的建模假设,最常用的就是 noisy-OR 模型,参见图 2b。
这项研究使用 [64,71] 提出的计算反事实的 twin-network 方法,推导出这些模型 expected disablement 和 expected sufficiency 的表达式。该方法在一个 SCM 中表示真实和反事实的变量——即 twin network,基于此我们可以利用标准推断技术计算反事实概率。相比于 abduction 而言,这一方法大幅分摊了计算反事实的推断成本。
研究人员将这类诊断模型称作「twin 诊断网络」(twin diagnostic network)。

实验
诊断模型和数据集
该研究使用的测试集包含 1671 个临床场景,这些场景由至少达到全科医生级别的各组医生生成。
实验中所用的反事实算法和关联算法均使用相同的疾病模型,以确保诊断准确率的差异可完全归因于所用的 ranking query。
反事实算法 vs 关联算法
研究人员首先使用后验 (1)、expected disablement 和 expected sufficiency (5) 对比了排名靠前的疾病的诊断准确率。对比结果参见下图 3:
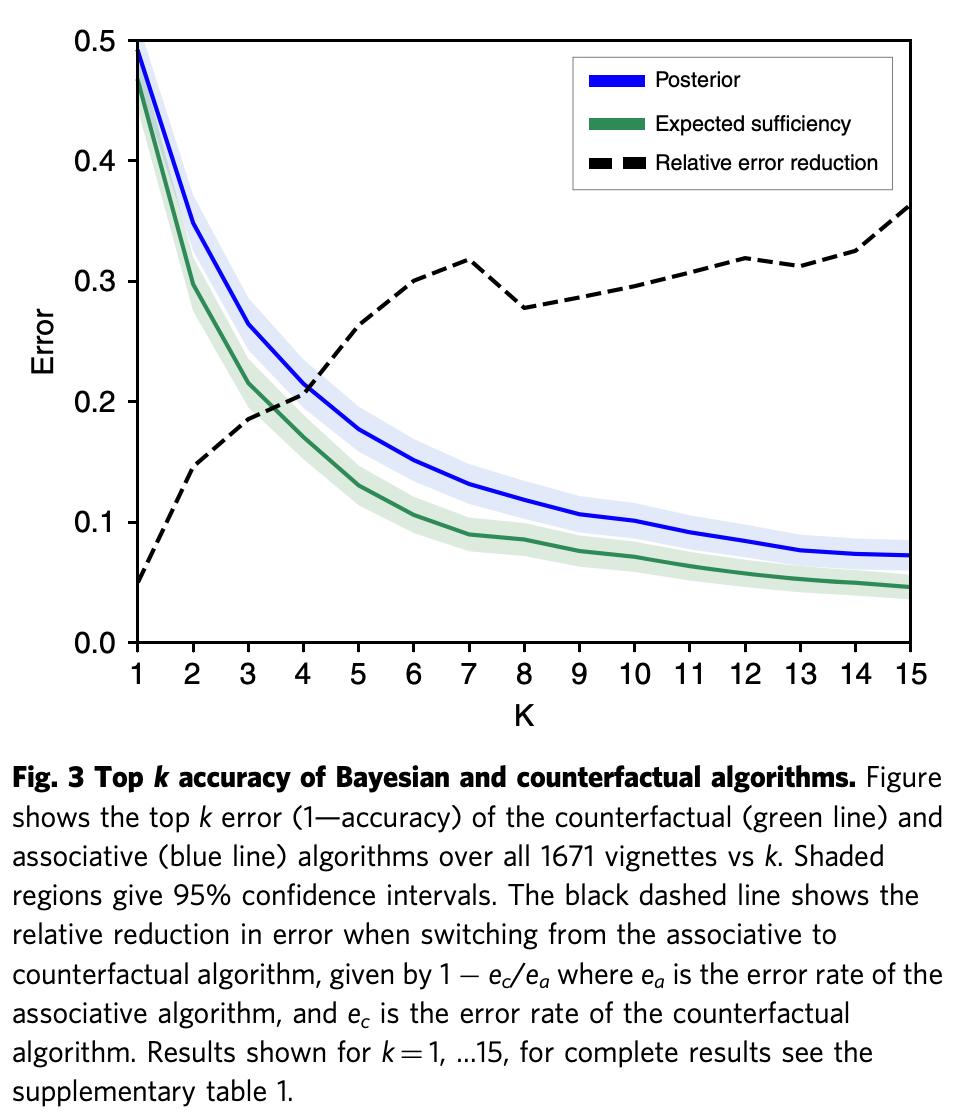
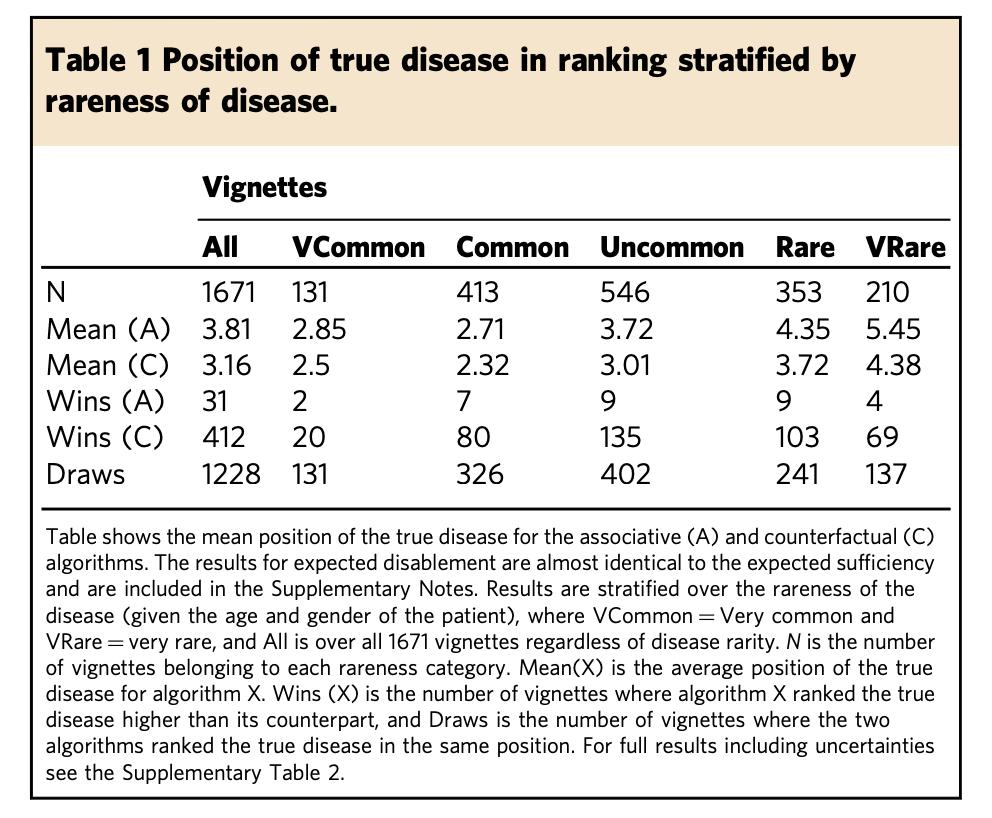
这一提升非常重要,因为罕见病通常更难诊断,包含很多重症病例,而诊断误差将对这些病例带来严重后果。
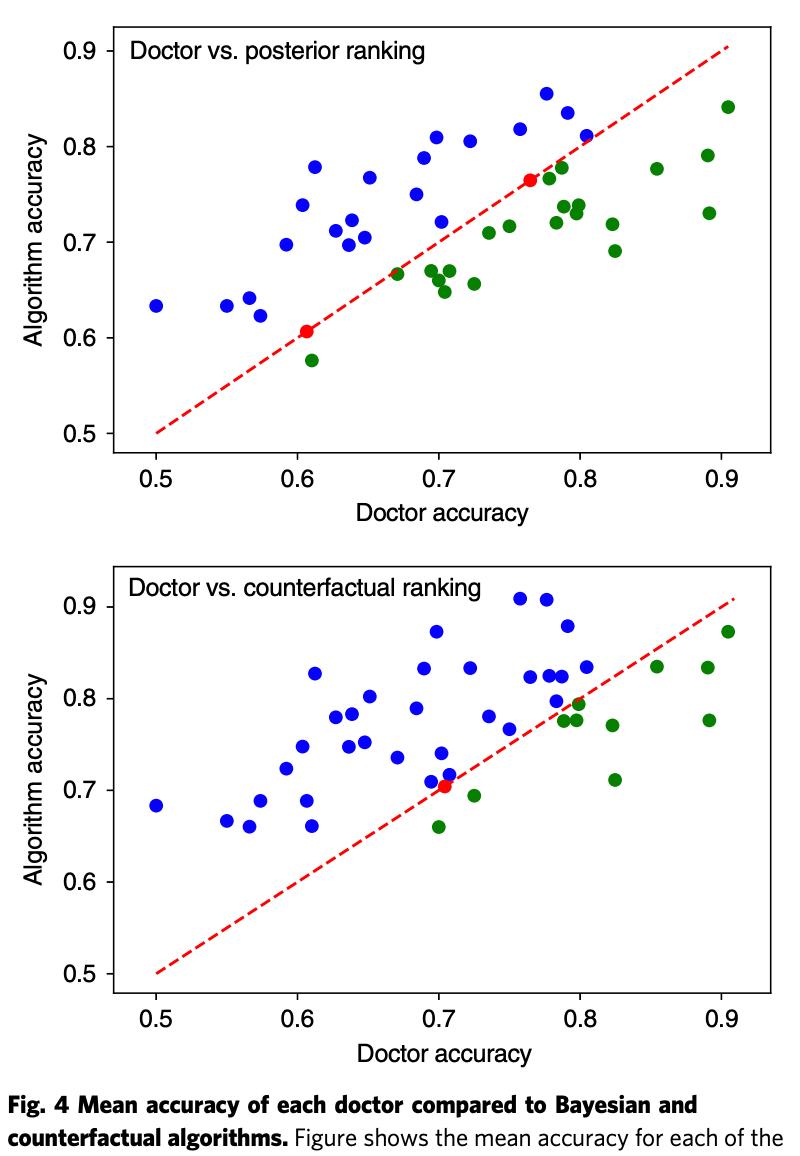
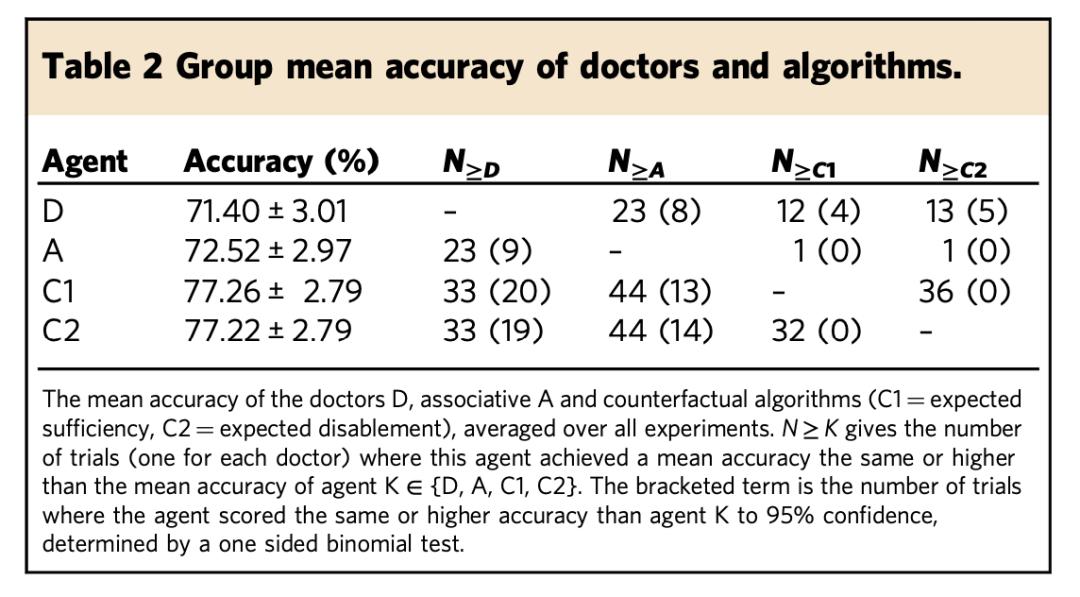
与人类医生进行对比
第二个实验将反事实算法和关联算法与 44 名医生进行了对比。
Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 模型。SageMaker完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。
现在,企业开发者可以免费领取1000元服务抵扣券,轻松上手Amazon SageMaker,快速体验5个人工智能应用实例。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《Nature子刊:用「反事实推断」帮模型识别罕见病,跻身专家水平,Judea Pearl力荐》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

