- +1
博士答辩人没来,导师还赞不绝口?
原创 关注前沿科技 量子位
边策 萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
疫情之下,我们已经看惯了线上的一切:云毕业典礼、云学术会议、云发布会。
但这些“云”终究让人感觉没“内味”。
因为没有身后的PPT投影、手舞足蹈的演讲,终归都是没有灵魂的!
所以,上海交大ACM班校友、南加州大学在读博士黄锃用专业知识,给自己办了场特殊的博士论文答辩。
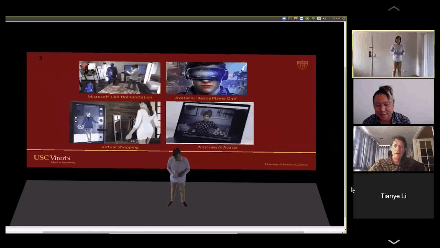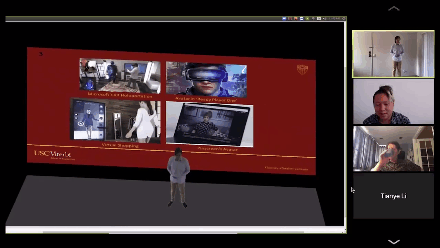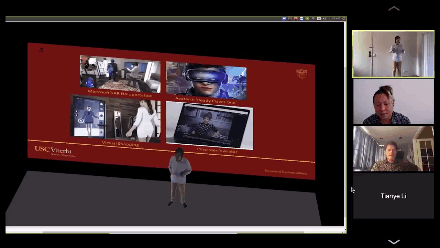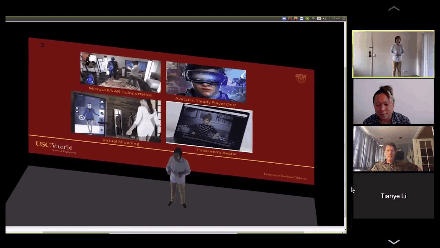
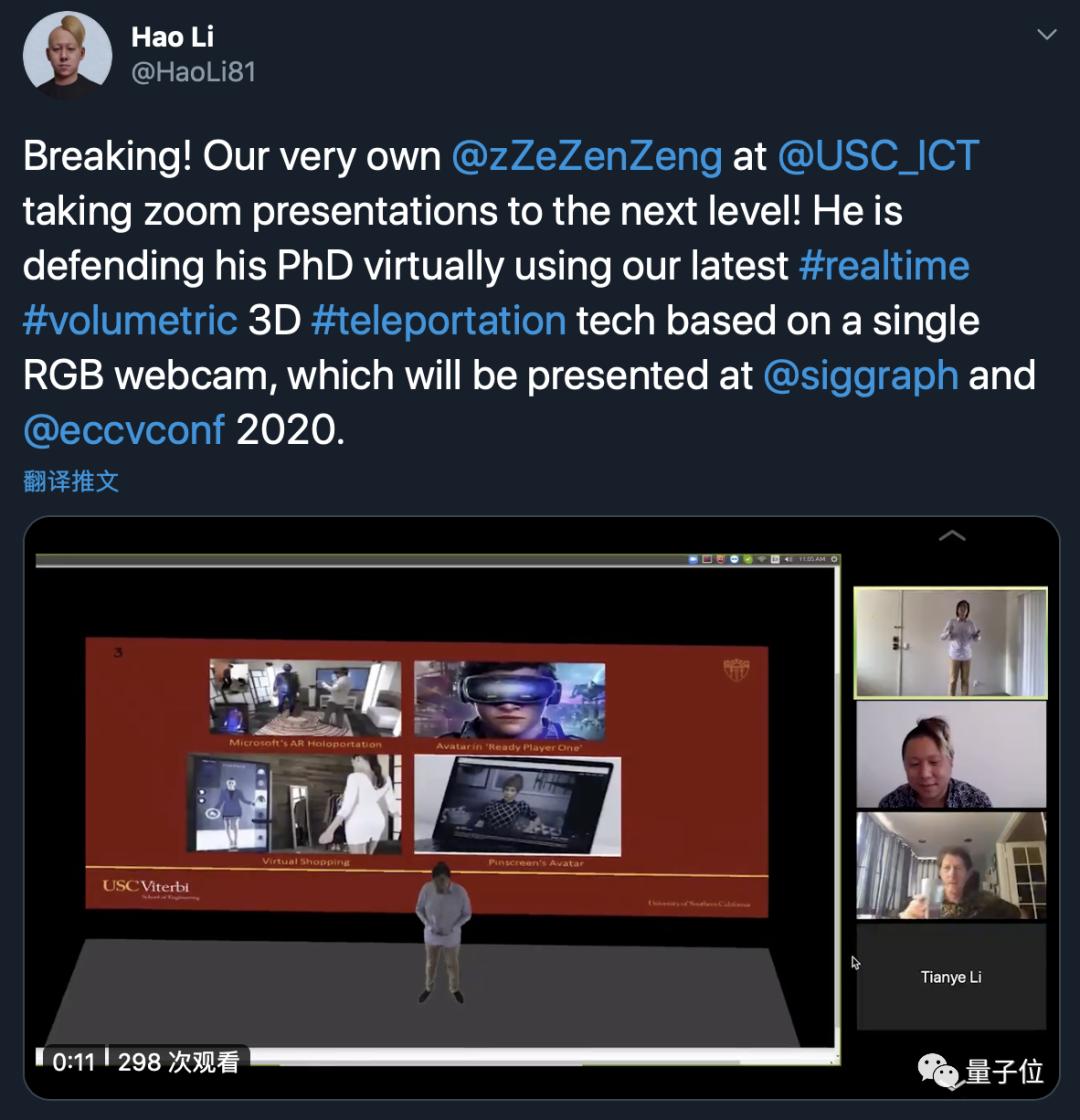
演讲人从2D变成3D,卧室背后的白墙也变成自己展示论文PPT的幕布。
右上角就是真实的黄锃同学,他一边演讲,电脑实时把他变成3D模型投影到场景中,导师们看到这一幕不禁笑了,随手就是一个转发。

背后的技术
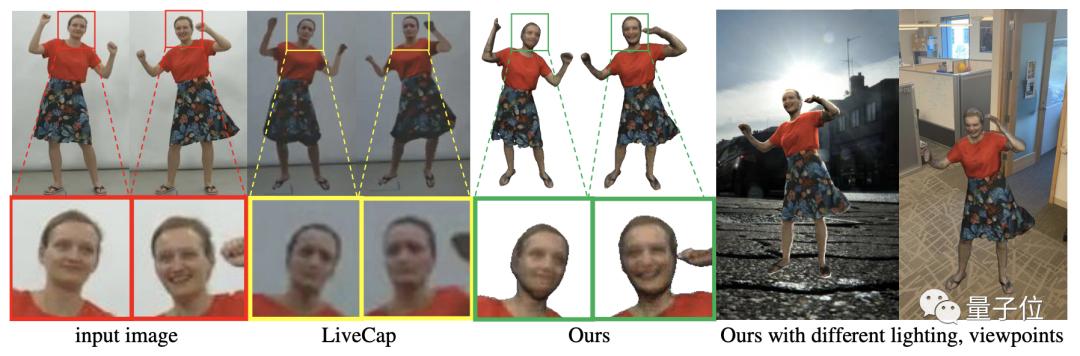
黄锃过去就一直从事3D图像重建的研究工作,去年他参与的一项研究PIFu(像素对齐隐式函数)可以从单张图片重建完全纹理的3D人体图像。

为此,黄锃和团队里的李瑞龙、修宇亮等一起提出了一种新颖的分层表面定位算法,和一种无需显式提取表面网格的直接渲染方法。
通过从粗到细的方式选择不必要的区域进行评估,成功地将3D重建速度提高了两个数量级,同时没有降低质量。
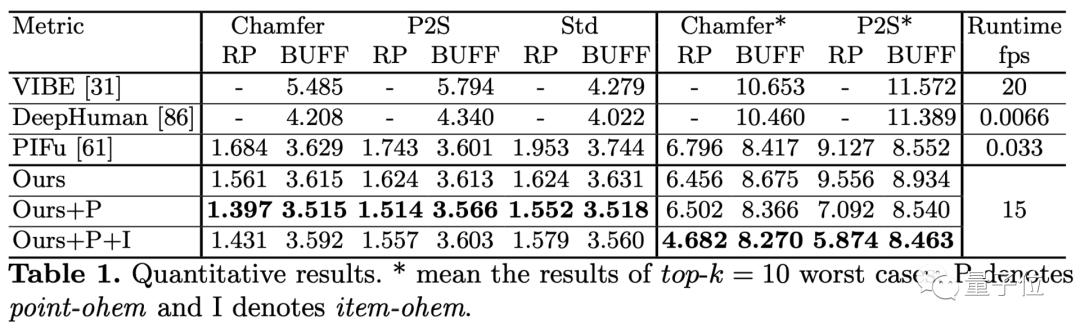
结果证明,这种从单摄像头实时重建3D视频的方法,处理速度可达15fps,3D空间分辨率为2563。
由于算法流水线的主要瓶颈,是要在过多的3D位置上进行估计,因此,减少要估计的点数将大大提高性能。
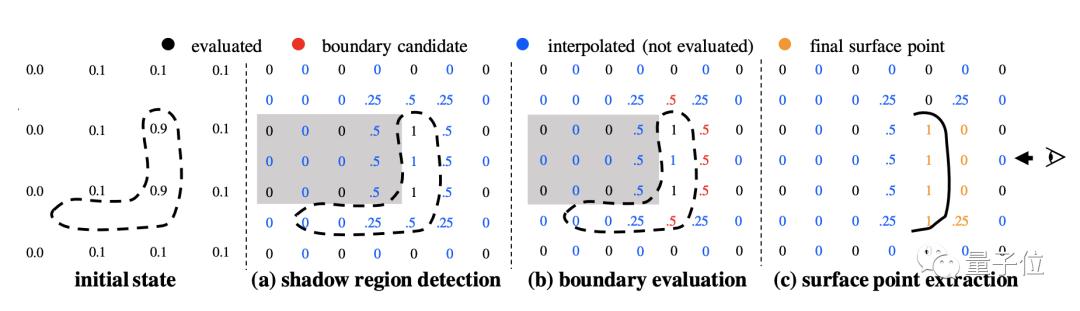
八叉树是用于有效形状重构的通用数据表示,它可以分层减少存储数据的节点数量。
作者提出的这种表面定位算法,保留了原来靠蛮力重建的准确性,而且复杂度与基于朴素八叉树的重建算法相同。
此外,作者通过直接从PIFu生成的视图渲染,来绕过显式网格重建阶段。下图展示了无网格渲染算法的原理,虚线和实线分别表示真实表面和重建表面。
该算法还面临一个问题,那就是有些特殊的姿势和视角很难恢复,因为它们只在训练数据集中占据很小的一部分。
一般的方法是进行数据扩展,但是对于这种3D数据来作扩增是很困难的。
然而,之前的研究证明,改变数据采样分布会直接影响重建的质量,于是作者找到了一种解决训练数据偏差的方法OHEM。
其关键思想,是让网络自动发现困难的样本,自适应地更改采样概率。
最后,作者的方法在没有任何超参数的情况下实现了最快加速,在保持原始重建精度的同时,处理速度从30秒减少到0.14秒。
与无网格渲染技术相结合后,处理一帧图像的时间只需0.06秒。系统的总体延迟平均为0.25秒。
作者指出,本文的主要贡献点在于:
1、从单眼视频中实时生成3D全身视频,可以在各种姿势和服装类型下构造出完全纹理的衣服,而不受拓扑约束。
2、提出一种渐进式表面定位算法,可使表面重建比基线快两个数量级,而且不会影响重建精度,在速度和正确性之间做了很好的取舍。
3、提出无需明确提取表面网格即可直接用于视图合成的渲染技术,进一步提高了整体性能。
4、提出一种有效的训练技术,可解决合成生成的训练数据不平衡问题。
和全息投影相比?
乍一看投影效果,是不是想到了马云今年在人工智能大会上,利用商汤全息投影完成的演讲?

虽然也是将人的影响投影到另一处场景中,不过二者的性质完全不同。
全息投影成像的原理,是利用光的干涉和衍射,再现出物体真实的三维图像记录。
而这次的虚拟答辩效果,实际上是利用AI将摄像头拍到的2D人物图像,转换成3D的效果。
也就是说,二者无论是从原理、还是从设备需求来说都不一样。
不仅如此,应用的场景也有所不同。
全息投影更侧重于真实场景下「互动」的效果,也就是说,你在线下场景中,可以与一个投影出的3D版「真人」互动、或是听一场3D全息投影的演唱会等。

无论是单薄的2D视频、还是无法利用视频呈现的2D照片,利用这项技术都可以还原出仿真的人物形象。
也就是说,一台摄像机拍出来的普通2D效果,利用这项技术就能转换成效果斐然的3D图像。
关于作者
用这项技术答辩的黄锃,本科毕业于上海交通大学ACM班。而这项实时技术的主要贡献,则来自他合作的两位学弟。

李瑞龙毕业于清华基础科学班,在清华获得了物理和数学学士学位,以及计算机科学硕士学位。


本科期间,黄锃曾在微软亚洲研究院实习,师从首席研究员曾文军,参与机器学习、深度神经网络相关的科研课题中。

也是在这里,他开始深入地认识和掌握深度学习的核心概念和技巧,也开始认真思考机器学习的现状和发展。
李瑞龙、修宇亮、黄锃均师从计算机图形学领域有名的黎颢教授,主要研究方向是结合几何处理和深度学习的虚拟人体重建。

博士期间,黄锃曾在Facebook实习,共有9篇论文发表在论文顶会上,其中SIGGRAPH 1篇,ECCV 2篇,CVPR 2篇,ICCV 3篇,ICLR 1篇。
黄锃最近的一项研究ARCH,则发表在CVPR 2020上,这项研究主要是关于穿着衣服人的3D可动画化重构。

有日本网友利用PIFu的技术,将照片上的奥黛丽·赫本和坂本龙马「请」到了自己的家里。

论文地址:
https://arxiv.org/abs/2007.13988
视频介绍:
https://www.bilibili.com/video/av753971174/
黄锃个人主页:
https://zeng.science/
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
原标题:《博士答辩人没来,导师还能赞不绝口!上海交大ACM校友实力演绎学以致用》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2025 上海东方报业有限公司

