- +1
不吃蘑菇,不捡金币,我用强化学习跑通29关马里奥,刷新最佳战绩
机器之心报道
编辑:张倩、蛋酱
看了用强化学习训练的马里奥,我才知道原来这个游戏的后几关长这样。

这款游戏承载了一代人的回忆,你还记不记得你玩到过第几关?
其实,除了我们这些玩家之外,强化学习研究者也对这款游戏情有独钟。
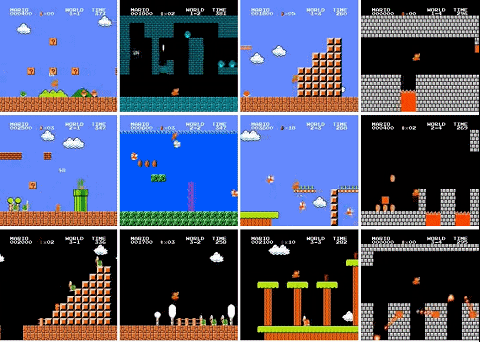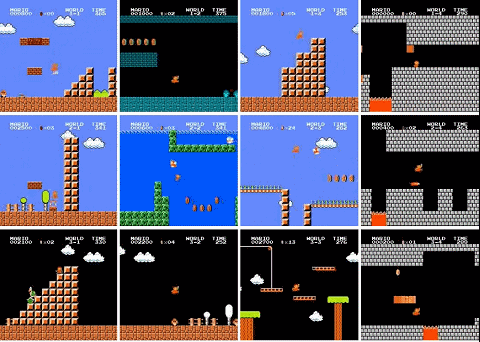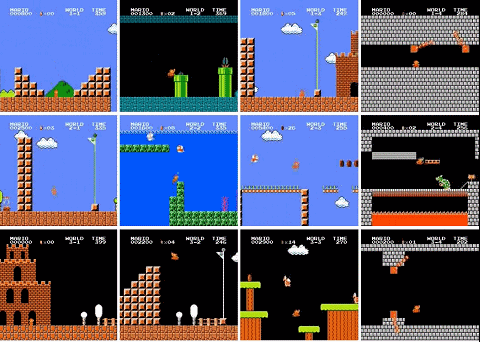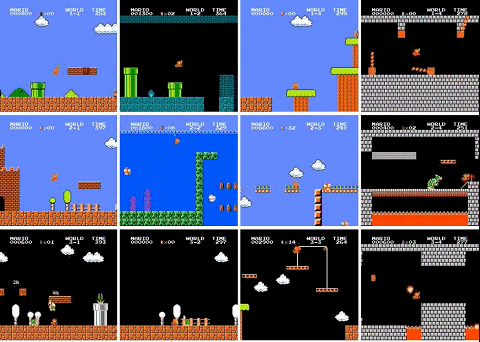
最近,有人用 PPO 强化学习算法训练了一个超级马里奥智能体,已经打通了 29 关(总共 32 关),相关代码也已开源。

使用 PPO 训练的 OpenAI Five 是第一款在电竞游戏中击败人类世界冠军的 AI。2018 年 8 月,OpenAI Five 与 Ti8Dota2 世界冠军 OG 战队展开了一场巅峰对决,最终 OpenAI Five 以 2:0 的比分轻松战胜世界冠军 OG。
此前,作者曾经使用 A3C 算法训练过用于通关超级马里奥兄弟的智能体。尽管智能体可以又快又好地完成游戏,但整体水平是有限的。无论经过多少次微调和测试,使用 A3C 训练的智能体只能完成到第 9 关。同时作者也使用过 A2C 和 Rainbow 等算法进行训练,前者并未实现性能的明显提升,后者更适用于随机环境、游戏,比如乒乓球或太空侵略者。
还有三关没有过是怎么回事?作者解释说,4-4、7-4 和 8-4 关的地图都包含了一些谜题,智能体需要选择正确的路径才能继续前进。如果选错了路径,就得重新把走过的路再走一遍,陷入死循环。所以智能体没能通过这三关。
开源项目地址:https://github.com/uvipen/Super-mario-bros-PPO-pytorch
近端策略优化算法
策略梯度法(Policy gradient methods)是近年来使用深度神经网络进行控制的突破基础,不管是视频游戏、3D 移动还是围棋控制,都是基于策略梯度法。但是通过策略梯度法获得优秀的结果是十分困难的,因为它对步长大小的选择非常敏感。如果迭代步长太小,那么训练进展会非常慢,但如果迭代步长太大,那么信号将受到噪声的强烈干扰,因此我们会看到性能的急剧降低。同时这种策略梯度法有非常低的样本效率,它需要数百万(或数十亿)的时间步骤来学习一个简单的任务。
2017 年,Open AI 的研究者为强化学习提出了一种新型策略梯度法,它可以通过与环境的交互而在抽样数据中转换,还能使用随机梯度下降优化一个「surrogate」目标函数。标准策略梯度法为每一个数据样本执行一个梯度更新,因此研究者提出了一种新的目标函数,它可以在多个 epoch 中实现小批量(minibatch)更新。这种方法就是近端策略优化(PPO)算法。
该算法从置信域策略优化(TRPO)算法获得了许多启发,但它更加地易于实现、广泛和有更好的样本复杂度(经验性)。经过在一组基准任务上的测试,包括模拟机器人移动和 Atari 游戏,PPO 算法展示出了比其他在线策略梯度法更优秀的性能,该算法总体上在样本复杂度、简单性和实际时间(wall-time.)中有非常好的均衡。
近端策略优化可以让我们在复杂和具有挑战性的环境中训练 AI 策略,先看这个 demo 视频:
如上所示,其中智能体尝试抵达粉红色的目标点,因此它需要学习怎样走路、跑动和转向等。同时该智能体不仅需要学会怎样从小球的打击中保持平衡(利用自身的动量),在被撞倒后还需要学会如何从草地上站起来。
PPO 方法有两种主要的变体: PPO-Penalty 和 PPO-Clip。
PPO-Penalty 近似求解一个类似 TRPO 的被 KL - 散度约束的更新,但惩罚目标函数中的 KL - 散度,而不是使其成为优化问题的硬约束, 并在训练过程中自动调整惩罚系数,从而适当地调整其大小。
PPO-Clip 在目标中没有 KL 散度项,也没有约束。取而代之的是在目标函数上进行专门裁剪 (clip), 以消除新策略远离旧策略的激励 (incentives)。
关于该算法的更多信息可以参考原论文。

网友:马里奥的奔跑,是我放荡不羁的青春
项目作者用 Pytorch 实现的《超级马里奥》demo 在 reddit 上引起了上千人围观,作者也现身评论区答疑解惑。
有人说,「他跑得那么快、那么不管不顾,看得我捏了一把汗。」


机器之心联合旷视科技开设线上公开课:零基础入门旷视天元MegEngine,通过6次课程帮助开发者入门深度学习开发。
8月4日,旷视研究院深度学习框架研究员刘清一将带来等二课,主要介绍数据预处理、模型搭建与调参等相关概念。欢迎大家入群学习。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《不吃蘑菇,不捡金币,我用强化学习跑通29关马里奥,刷新最佳战绩》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2025 上海东方报业有限公司

