- +1
你站在街上歪头瞅摄像机,我在100年后隔着屏幕瞅你
原创 木子Yanni 浅黑科技 来自专辑隐秘往事
你站在街上歪头瞅摄像机
我在 100 年后隔着屏幕瞅你
文 | 木子Yanni
比「改编自真实事件」更震撼的,是直接站在真实面前。
前段时间,一位叫做大谷的 90 后北京小伙儿,无意中看到了一段拍摄于 1920 年左右的珍贵影像视频,他灵光一闪,借助科技的力量,用人工智能对视频进行了修复,让我们有幸目睹了 100 年前北京城真实的烟火气。
街道上,行人、车马交错而行,《骆驼祥子》里的黄包车穿梭而过;如今要深入沙漠才寻得到的骆驼,正驮着货物稳步走在大街上;小小的院儿门口,有催促孩童的动,也有挑担卖货的静,甚至在 30 秒内,就上演了三种不同的问候方式;与现在不同,那时街上悠然闲逛的大多都是男性;一个转头,还能瞅见街边兴致盎然接力逗狗的老哥。

截图来源于YouTube:人民日报
没想到,时隔月余,大谷的“老北京 Vlog”第二弹又来了。
这一次修复的视频,拍摄于 1928 年前后,与第一弹视频仅相隔 10 年,却能明显看到变化:十年前,人们在街头看到摄像机时,或盯住几秒钟后仓皇逃开,或原地看呆逐渐石化,或因好奇而一步三回头,想看又不敢看。

截图来源于YouTube:人民日报
十年后,在小院儿里剃头的随便一位路人小伙儿,都能神态自若的对着镜头,潇洒的拍拍自己刚剃好的头,用地道的老北京话反复念叨着:“不错、剃挺好,不错、剃挺好...”

截图来源于B站:大谷的游戏创作小屋
街边一拥而上打午饭的孩子们,眼睛盯着摄像头,等着端饭的手却丝毫没受影响:吃饭最重要,害怕?不存在的。

截图来源于B站:大谷的游戏创作小屋
你再瞧这个舔碗的靓仔,是不是跟你小时候如出一辙?

截图来源于B站:大谷的游戏创作小屋
此外,视频中还有摩肩接踵的集市、街头的民俗乐队等场景,一个熟悉又陌生的年代,瞬间跃然于眼前。
古人不见今时月,今月曾经照古人。
你站在街上歪头瞅摄像机,我在 100 年后隔着屏幕看你。视频中的他们,见证了历史,而我们正在回望,如果要说遗憾,大概是模糊的画面,遍布历史划痕;黑白的色调,失了时代本色。
于是,大谷利用人工智能,从三个方面对视频进行了修复。值得一提的是,第一弹视频中的声音,是用素材后期配的,而这一次的修复,全部都是时代原声,有兴趣的话,各位可以去看完整版视频(比如 B 站搜索「大谷的游戏创作小屋」)。
接下来,我们一起来看看,当你在看修复版视频的时候,视频到底修复了些什么。
(一)顿顿顿顿顿
如果你看过早期的影视作品,比如 83 版射雕、86 版西游记、94 版三国,大概率会有这样的感受:明显看到画面在跳动,仿佛摄影师得了帕金森一般。
为什么会这样呢?
我们需要先弄清楚一个问题:当你在看视频时,你看的到底是什么?剧情、演技,还是中间插播的广告?都不是。
其实是一连串图片。
我们现在看到的电影,绝大多数都是 24 帧,意思是每秒由 24 张图片组成。电影在播放时,24 帧既能保证你看到的画面是流畅的,也能恰到好处地继承优良传统:最初,电影拍摄离不开胶卷,虽然帧数越多,细节表现就越好,但每一帧都是钱啊,经过认(扣)真(门)对比,优秀的电影人发现,24 帧是性价比最高的选择,既不会浪费胶卷,画面的流畅度也能达标。尽管如今已经是数码时代,但 24 帧的传统依然保留了下来。
如此看来,老旧视频卡顿的问题就有答案了,因为帧数不够。刚才有提到,要想画面流畅,每秒就不能少于 24 帧,而老电影是低于这个数字的,比如大谷修复的那部 100 年前“老北京 Vlog”,帧数都在 10 以下,用我们已经娇生惯养出的好莱坞大片观感来审视,只能是囫囵吞水,“顿顿顿顿顿”。
帧数不够,补帧来救。但要清楚一点:因为补出的帧,原本是不存在的,所以补帧需要依靠想象力。
传统的补帧方法主要有三种:帧采样、帧混合,以及光流法。看到这儿,有句话恐怕要应验了:专有名词一出现,吃瓜群众走一半。其实,Duck 不必,我们逐一来看。
第一种,帧采样。是指把前一帧复制到后一帧,简单来说就是 112233。
第二种,帧混合。是指在前后两帧中间合成一个新的帧,同时调整新合成帧的透明度,做出画面过渡的感觉,也就是1、1.5、2、2.5、3。
第三种,光流法。什么是光流呢?当一只蝴蝶从你眼前飞过,蝴蝶的移动轨迹会在你的视网膜上形成一连串变化的图像,仿佛光在流动,于是,你就看到了蝴蝶的飞舞路线。换句话说,光流有记录物体位置移动信息的能力。光流法补帧,就可以简单理解为,找到物体在相邻两帧之间的位移,在位移中补出中间帧。
举个栗子,我们看下面这张图,假设物体在帧 1 中的位置是 1,在帧 2 中的位置是 3,在帧 3 中的位置是 5,那么,根据光流确定相邻两帧中物体的位移情况,就能在 1 和 3 中补出 2,在 3 和 5 中补出 4,这样一来,原本 3 帧的视频就补成了 5 帧,看起来,物体的运动就会流畅很多。

以上这三种补帧方法,在物体处于平移状态的时候,效果比较好,但是,如果物体处于旋转跳跃不停歇的状态下,效果就要大打折扣了。比如一只正在跳旋转舞的小熊,上一帧你还只能看到臀部,下一帧它的小短尾巴就出现了,像这种上一帧没有、下一帧突然出现的情况,传统的补帧方法就不太好用了。
另外,在补帧的时候,还有一种非常难处理、但又非常常见的情况,就是有其他物体乱入,导致目标物体被遮挡。
比如你在海边想给女朋友拍一段冲浪的视频,但海里都是人,不停有人挡在你女朋友面前,这种情况下,如果你后期想把视频从 24 帧补到 30 帧,就非常难,你想,软件正在专心脑补你女朋友的冲浪动作,一位路人甲突然出现,把软件的预测给打断了,画面就会出现一种情况:叠影。

针对这种复杂场景下的补帧,AI 的优势就显现出来了。
在修复 100 年前的“老北京 Vlog”时,大谷用到的 AI 工具是 DAIN (Depth-Aware Video Frame Interpolation),中文名叫做“深度感知视频帧插值”,这是一个开源的人工智能补帧软件。它的优秀之处在于兼顾了光流和深度,不但能准确追踪物体的位置移动,还能检测到物体遮挡。光流刚刚已经讲过了,这里再来说说物体遮挡检测。

你眼中的视频是平面的没错,但视频中的世界却是立体的。DAIN 利用算法,可以猜测出每一帧中不同物体的深度信息,根据深度的不同,AI 就能知道是谁遮住了谁,接下来,根据“遮挡物近、被遮挡物远”的原则,就能较为精准地确定画面中物体的边缘轮廓,避免出现叠影,从而产生更好的补帧效果。

(二)糊糊糊糊糊
对于视频来说,画面流畅远远不够,清晰也很重要。
如果画面很朦胧,你连主演的表情都看不真切,就不能揪着 Ta 的演技口吐芬芳,从而失去一个闲谈时的八卦谈资,进而你会质疑当下的视频制作水平,你的不信任就会阻碍视频行业的健康发展,为了这一切不会发生,画面必须要清楚。
提到清晰度,你肯定会想到 480P、720P、1080P、2K、4K,那么问题来了,怎么才能把 480P 的视频提升到 720P 呢?重拍。
除了重拍呢?那就是超分辨率重建。
超分辨率,意思是用硬件或软件提高原图的分辨率,这个处理过程,就叫做超分辨率重建。
超分辨率重建技术可以分为两种,一种是多合一,多张低分辨率图片合成一张高分辨率图片,另一种是单重建,用单张低分辨率图片恢复一张高分辨率图片。大谷在修复 100 年前的“老北京 Vlog” 时,用的扩增分辨率工具 ESRGAN,就属于后者。
ESRGAN 全称叫做「增强型超分辨率生成对抗网络」,是由 SRGAN (超分辨率生成对抗网络) 升级而来,它们都是基于生成对抗网络的超分辨率方案。
生成对抗网络 (Gan) 可以看做是两个小人在博弈,一个小人叫做生成模型,另一个小人叫做判别模型,生成模型小人的任务是以假乱真,用超分辨率技术造出可媲美原图的照片,而判别模型小人的任务则是明辨真假,判断眼前的照片究竟是原图还是对手生成的,两个小人在长期的斗智斗勇中,水平越来越高,基于这个模型训练出来的 AI,就能够越来越精确的重建出高分辨率图片。
ESRGAN 不仅继承了前身 SRGAN 优良的全局把控力,而且通过调整算法,弥补了之前的短板:容易丢失细节。如此重建出来的图片,与原图相差无几。
从下图中可以明显看出,用 ESRGAN 重建的照片,细节 (胡须) 呈现的更好。
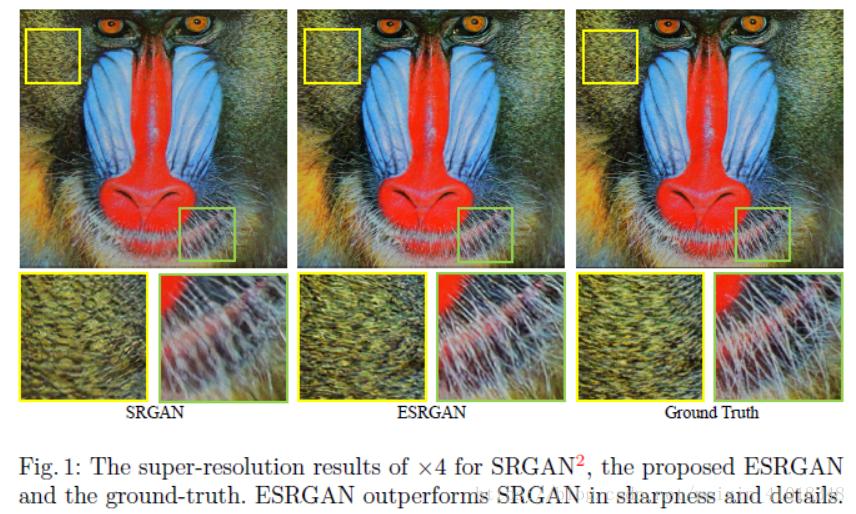
与实际画面的对比
但不得不说,有时候,“画至清、则有瑕”,画质太过清晰,也难免会把“瑕疵”推到观众眼前,这一点在老电影修复的过程中,就常常会发生。比如在《亮剑》修复版中,就出现了无比醒目的穿帮镜头:

所以,在此友情提示:观影重在沉浸感,你可以专注于看剧情、看演员、看特效,别的就算了,能过就过,千万别较真,比如我就根本没有注意到某部电影中精良的化妆技术。

(三)给黑白加彩
1839 年,法国画家达盖尔成功做出了世界上第一台照相机,人们惊奇的看着这个奇怪的木匣子,兴奋又忐忑地围观着这门独一无二的“新艺术”。然而,当照片呈现在眼前,人们的兴奋却变成了失望。
照片,记录下了每一个精致的细节,可是颜色去哪儿了呢?
本着“顾客就是上帝,上帝不能失望”的商业准则,一场声势浩大的色彩捕捉行动开始了。科学家、摄影师、艺术家都参与其中,拼命想找出能让照片显示出色彩的办法,然而一圈下来,毫无进展。
情急之下,一个替代方案诞生了:上色。
值得一提的是,绝大多数情况下,摄影师和上色技师并不是同一个人,最后的呈现效果,极大依赖于技师的理解和审美。所以你瞧,照片上色这个事儿,从一开始就属于二次主观创作。
照片上色主要经历了三个阶段,首先是彩色胶卷问世之前,当时的照片上色纯靠手工,也就是画。鸦片战争打开了中国国门,让摄影技术进入了人们的视线,也催熟了国内的照片上色行业,甚至在新中国成立之后,还专门举办了上色技师评比大赛,大家说好,才是真的好。

明星周璇17岁时的手工上色照片
手工上色从工艺上来看,分为水色和油色两种,水色就是水彩类颜料,优点是画面通透,油色则是油性颜料,优点是保存持久。相比之下,油色更受欢迎。
上色不是直接用笔在照片上画,需要先给照片褪色:先用铁氰化钾,把照片上的黑色变成白色;再用硫化钠,把照片整体调成棕色;接下来,就可以在这张棕色的“画布”上进行填色了。
1935 年,柯达克罗姆彩色胶卷问世,彩色摄影成了主旋律,照片上色也走进了第二个阶段:数码调色。工具就是各位熟知的 Photoshop (PS),可谓是“PS 在手,万物皆可彩色”,不变的,依然是二次主观创作的属性。
时间再往后走,照片上色来到了第三个阶段:AI 填色。
人工智能本不认识颜色,看的多了,也就会猜了。修复 100 年前的“老北京 Vlog”时,大谷用的 AI 上色工具叫做 DeOldify,是由一位美国小哥首发在 Twitter 上的开源软件,我们先来看几个它过往的作品。


如果给人工智能一个完美的数据集,它恐怕能给灵魂涂上颜色。
起初,DeOldify 只被用来做照片上色,鉴于它出色的表现,才开始让它为老电影上色,从效果来看,依然惊艳,正如在“老北京 Vlog”中的表现一样,DeOldify 带我们穿越历史,跳出曾经无数次背诵过的历史考点,隔着百年时光,感受属于小人物的平凡和精彩。

为1936年的老电影上色
而在第二弹视频中,大谷使用了 AI 新技术 DeepRemaster,在全局表现效果来看,更加优于 DeOldify,这就是 AI 后浪的力量。
不过,从实际效果来看,惊艳中仍有遗憾,比如视频中的上色不是 100% 精确的,因为人工智能学习使用的数据集,还不能涵盖这一历史时期的所有色彩样本,所以只能说,这种上色效果是合乎常理的,是人工智能基于现实所带来的浪漫复现:给不了你真实,只能给你一种真实的可能性。
突然想起一句话:我们所谓的故乡,不过是祖先流浪的最后一站。
回望视频中的这些人,他们一生经历了些什么,我们不得而知,但在 AI 的修复下,时光突然被折叠,我们有幸得以瞥见他们人生中的一瞬真实,已经是科技最好的馈赠了。
是路人,也该好好路过。

后之视今
亦犹今之视昔
原标题:《你站在街上歪头瞅摄像机,我在 100 年后隔着屏幕瞅你》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2025 上海东方报业有限公司

