- +1
周伯文对话斯坦福教授曼宁:人机对话智能新进展需要新“图灵测试”
原创 Synced 机器之心
机器之心报道
机器之心编辑部
6 月 22 日,在 2020 智源大会上,有一场大佬对大佬的精彩会谈。
过去一年里,人工智能进展最大的方向在自然语言处理(NLP),BERT、GPT-2 等预训练模型引领了很多方向的新时代,又催生出了大量商业应用机会。面对技术的进步,AI 领域的顶级学者和从业高管是如何看待未来前景的?近日,2020 智源大会在线上召开,在为期四天的会议中,5 位图灵奖得主、上百位业内专家在 19 个专题论坛云上共同畅想了人工智能的下一个十年。
在智源大会上,京东集团技术委员会主席、京东智联云总裁、京东人工智能研究院院长、IEEE Fellow 周伯文与斯坦福大学教授、人工智能实验室负责人克里斯托弗 · 曼宁(Christopher Manning)展开了一次精彩的交流。他们讨论了自然语言处理领域近期的进展,预训练模型兴起之后的未来发展方向,甚至还为人工智能的标杆评测基准——图灵测试找到了一个「替代方案」。
在交流过程中,两人也提及了京东最近被人工智能顶会 ACL-2020 接收的研究,以及曼宁刚刚发表的工作,有关预训练模型学习到的语言结构。
语言理解 & 人机对话领域过去一年的进展
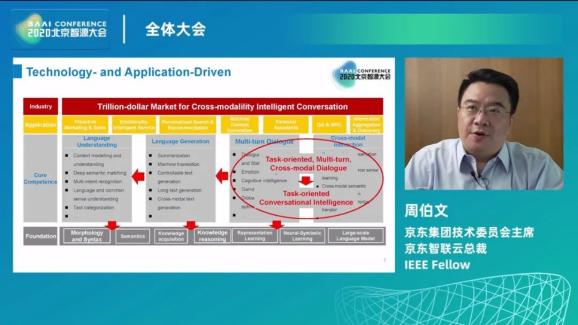
周伯文与曼宁在对话伊始回顾了在 2019 年智源大会上尖峰对话中达成的共识:任务导向的多轮对话是 NLP 下一个十年重点的研究和应用方向。周伯文还创造了一个新词「任务导向型对话智能」(Task-oriented Conversational Intelligence),一方面,任务导向型对话智能可以反向推动许多基础技术能力的进步,另一方面,它的发展也将对经济方面产生巨大影响,带来人机交互技术驱动的万亿级市场。
曼宁表示:「其中的代表就是 GPT-2 和 GPT-3,也包含 BERT、RoBERTA 和 ALBERT、ERNIE 等等不少 BERT 变种。它们使得自然语言理解与生成有了非常大的发展。我们也看到传统 AI 领域有了很大转变,很多任务目前都倾向于被大型模型来解决。」
人工智能发展的 40 多年来,我们一直在努力试图让 AI 可以回答科学问题。我们过去尝试使用的思路是研究知识的表达方法,阿兰图灵实验室的 Aristo Project 试图让 AI 理解科学道理,进而深度理解世界,这一思路在最初的十年推动了知识的表达与推理。
在 2020 年,我们通过超大尺寸模型实现了巨大的进步。基于 RoBERTa 预训练模型,我们可以实现 95% 的科学问题回答准确率,这看起来是目前解决知识问题的最好方法了。
这些进步为新一轮商业应用打开了道路。「未来的方向虽然还无法确定,但我们可以看到基于预训练语言模型,为搜索引擎公司等科技企业带来了很多新商业机会,」曼宁表示。「他们可以实现近十年来最大的单个技术进步,构建更好的机器翻译系统,对话 AI,人工智能客服系统等等。现在,我们正在经历 NLP 领域激动人心的时刻。」
NLP 领域最近发生了从特定任务模型向多任务,大规模预训练模型方向转变的重要变化。一方面,工业界乐于看到 BERT 这样模型在下游应用上的前景。但对于学界研究者来说,这种发展大大提高了新研究的门槛。看看 GPT-2 到 GPT-3,它的参数从 15 亿增加到了 1750 亿。但如果仔细观察的话,你会发现模型对知识的获取和推理性能的提高,可没有参数增加的数量那么多。
针对这一问题,周伯文指出「在查看 GPT-2、GPT-3 相关论文后,有一件事情引起了我的注意,那就是 - 当我们从零样本学习 (zero-shot) 到单样本 (one-shot) 学习时,我认为 GPT-3 改进了很多。这有效证明了,从小型模型转换为大型模型时,预训练等于更多的信息。」
与此同时,周伯文发现,从单样本 (one-shot) 学习过渡到少样本 (few-shot) 学习时,GPT-3 或 GPT-2 的改进非常非常有限。周伯文指出:「我认为这从另一方面证明,这些更大规模的模型可能并没有学习到足够多的信息。」
由此观之,知识的获取和表征可能仍是 NLP 的正确方向。
曼宁认为,目前的大规模预训练模型可能存在一些「根本性」的错误——这些模型非常低效率。从现实世界人们的对话中学习知识的表征,总不是一个好方法。可能 5 年后人们往回看就会嘲笑现在的工作:「看看这些人吧,只想着把模型做得越来越大就妄想能够实现人工智能了。」
对于研究者来说,我们必须寻找更加有趣的,让模型可以思考、能够更高效提取知识的方法。某种程度上,人们应该需要找到更好的知识编码机制,这有关知识空间,语义连接的更好表达方式。这可能和传统 NLP 的知识图谱和知识表征有关。所以让模型记忆和推断真实世界的情况,看起来从基础上就不是一个正确的,高效的方法。
「人类不是通过这种方法学习知识的。人类存储的知识很少,但可以理解大量知识。」曼宁说道。

作为一个在该领域中务实的研究人员,周伯文非常关注最近预训练的大规模语言模型以及对语言任务进行微调的功能。在一个月前放榜的自然语言处理顶会 ACL 2020 上,周伯文等人有两篇论文被接收。
「在论文《Orthogonal Relation Transforms with Graph Context Modeling for Knowledge Graph Embedding》中,我们得出的结论是通过预训练模型,我们可以生成非常自然的商品介绍,内容来自预训练模型,还有图片、知识图谱和用户的评价,」周伯文表示。
另一个例子是在论文《Self-Attention Guided Copy Mechanism for Abstractive Summarization》中,自注意力机制(self-attention)可以帮助我们在对话任务和文本摘要任务上,生成了更多更自然的语句。
据了解,京东智联云在跨模态内容生成上已取得诸多成果,并正式应用到京东的业务流程中。目前京东智联云打造的智能写作产品,是基于商品图谱和语言模型构建的营销内容智能生成服务,在 2020 年京东 618 期间,已覆盖京东零售过半数的商品品类,创作出的导购素材,曝光点击率相较于人工撰写的内容高出 40%,让用户在大促高峰期间也享受到优质服务。
这样一些接近实用化的方向已经受到了 NLP 新范式的帮助。毫无疑问,使用预训练的模型现在可以生成很自然的文本以及对话。但目前的预训练模型还称不上完美,曼宁指出,我们还没法控制这些模型生成的内容。
超越图灵测试的 AI 新基准
若想实现更好的人工智能,我们必须拥有完美的评测基准(Benchmark),几十年以来我们一直将图灵测试作为「真正人工智能」的测试标准。但图灵测试是以 AI 模仿人类,试图「欺骗」测试者进行无特定内容对话的形式来进行的。对于研究者来说,这个过程一直存在难以量化的问题。
在 NLP 技术发展多年后的今天,「我们会不会出现可以代替图灵测试的新基准呢?」周伯文在对话中提出了这个问题,「过去的几十年中,图灵测试一直是基准,但是在日常研究中,它让我们的研究目标变得明确,对结果推动又没有太多直接的帮助。」
「这个问题很有趣,也很难回答,」曼宁表示。「我同意这个看法——图灵测试不是非常清楚的基准。某种程度上我们需要找一个另外的方法,标量真正的理解、真正的持续对话。但我一时没法给出完美的答案。」
不过周伯文有一个「稍显疯狂」的主意,有关最近正火的直播带货:热门主播几个小时可以带几千万元的货。这种互动形式看起来非常吸引人,究其根本,它是一个实时的、富有交互性的方式。在这里播主和观众用弹幕和语音实时交流,这似乎为对话型 AI 提出了更多的要求。
原本的图灵测试,不会预先指出被测试者的身份,通过评判相似性去界定智能化水平;那么,我们是不是可以直接公开使用两个对话型 AI 做直播带货,通过统计以每小时能卖出多少商品的可量化指标来对比哪个 AI 的对话更吸引人,从而评估对话型 AI 的智能化水平?
这样的话,所有评价指标都可以量化,形式也非常接近于真实世界。
「这是一个非常有趣的想法,可以带来非常清楚的评价指标,」曼宁表示。「直播对于我来说是一个很新鲜的概念,某种程度上来说,这是一个非常直接的评价方式。我不清楚是否完美,但它很有创意:一个人类销售想要成功,并不取决于对潜在消费者传递信息的完美平衡,有时还需要提出超出实际一点点的主张,更加强烈地表达自己的观点。」
周伯文表示,在未来几个月里,京东会对这个方向进行一些尝试和研究。
学术界如何在预训练时代引领前瞻性研究
今天的人工智能研究正凭借算力的增长而快速发展,随着模型体量的增加,学界研究者面临的挑战越来越大。对于研究者们来说,即使希望方法足够创新,也会在大会上宣讲论文时受到这样的挑战:「你使用的基准是最新的吗?」这意味着你不得不直面大量数据。
周伯文表示:「近来,我常被问到一个问题,在如今的云计算 + AI 时代,研究人员和学者如何跟上?」
据了解,2019 年底,京东整合云计算、人工智能、物联网业务资源,形成京东云与 AI 事业部,并于 3 月 5 日面向技术服务领域推出全新的「京东智联云」品牌。在刚刚过去的京东 618,京东智联云提供了全面、稳定、安全、可信赖的技术保障,成为京东 618 的技术基石,并秉持着「成为最值得信赖的智能技术提供者」的愿景,对外输出更多、更好、更融合、更场景化的技术与服务。
目前云服务在商业公司中的布局已日趋成熟。那么在斯坦福大学,教授们是怎样平衡增量创新与理论创新的?研究者们是如何使用算力的?
「近年来我们的工作方式有了很大变化。在 20 年前,大学里才有最大的超级计算机、最快的网络。但在最近这些年里,情况有了翻天覆地的变化——现在算力都在商业公司那里了,」曼宁说道。
如何解决算力不足的问题,每所大学都有不少思路,最直接的方式就是购买数量有限的,当前最顶配的 GPU,让很多博士生共用以满足 80% 时间的需求。「我想这是很多大学都在使用的方法,如果你的实验室里有 20 名博士生,这要比每人配置一台机器节省三倍成本,」曼宁表示。「现在我们构建起了小型集群,斯坦福 NLP 实验室有 15 名研究者,我们有大约 100 块 GPU。你看,这不是一个很大的数字。」
另一个思路就是和京东智联云这样的科技公司合作,在一些需要更多计算的研究中,斯坦福也在购买云端算力。
每年冬天,曼宁都会亲自为斯坦福 NLP 大课 CS224N 授课。这门课可以吸引 500 名学生,他们的作业都需要使用 CPU、GPU 来训练模型,而所有学生在课程期间的算力需求是大学负担不起的。因此,斯坦福接受业界的捐赠。

最后,研究方向也是个问题。「让模型越来越大可能在最近五年可以实现很大的进展,但在下个十年就不一定了,」曼宁说道。「我们现在可以构建出更大的模型,然后发出论文。但这个对于基础方向的研究没有什么帮助。未来 5-7 年里可能会出现一个窗口,最聪明的研究者可以用普通电脑和 GPU 构建出 SOTA 模型,打败大公司的巨大模型。」
「但未来也有可能不是这样,看看其他行业,如果你是个机械工程的 PhD,你肯定没法上来就盖世界最高的摩天大楼,如果你是个航空工程学生,你肯定不会试图造一架比波音还好的飞机。你需要做的是寻找新的想法。」
研究学者需要更加注重于寻找具有开创性的新想法,并提出原型。举个例子:机器学习领域里的 Dropout,其实是在很小的数据集上首次实践的。
构建可信赖的 AI:可解释性和真实世界的鲁棒性
最近一段时间,周伯文曾在多个不同场合表达了对于可信赖的 AI(Trustworthy AI)的看法,并指出可信赖的 AI 将是智能经济未来 10 年的新原点。
目前有关可信赖的 AI 已经达成 6 个共识,包含公平、鲁棒性(技术的可用性)、价值对齐(技术提供者、使用者和产品应用方都认为产品带来价值)、可复制、可解释以及负责任。构建可信赖的 AI 一面是对技术的巨大挑战,一面是人文精神,无论是京东智能情感客服传递温暖、亦或京东物流设施传递信赖,都是对人类的社会责任与价值体现。
曼宁认为,人工智能学界目前在可解释性方面已经取得了一些进展。一方面是像 transformer 这样的预训练模型,注意力机制带来的好处——这些模型具有相当高的可解释性。
「我的一些学生发表过论文试图解读 BERT 的运作机制。现在,我们已能够对这些模型进行大量解码,并看到这些模型不仅是巨大的联想学习机器,而且它们实际上是在学习人类语言的结构,其解句子的语法结构,了解哪些词是指同一实体,」曼宁说道。
因此,我们已经能够获得模型内部的可解释性,这意味着模型可以对其整体行为做出某种决定的原因做出一些解释。当然,这里还有很多工作要做,斯坦福研究者们正进行的工作希望就驱动模型决策的特征进行解释。
曼宁教授在 6 月份还以第一作者的形式发表了论文《Emergent linguistic structure in artificial neural networks trained by self-supervision》,其中写到预训练模型实际上可以学习语言结构,不需要任何监督。这解释了为什么大规模的模型是可行的。但是对于下一步如何更好的理解他们是怎么学习到的,这个目前还不太清楚,周伯文指出「这部分需要可信赖的 AI 来解决」。
这些发现非常令人兴奋。之前我们总是认为想让 AI 在某些任务上工作良好,需要是大型有监督模型。因此我们总是以大量资金、雇佣很多人进行数据标注开始。这是过去 20 年来的工作范式,人们也是通过这种形式在某些任务上让 NLP 模型达到接近人类水平的。
「如果下一代人工智能机器本质上和十年前一样,而考虑到训练的内容大幅增加,我们实际上是倒退了,而不是前进了,」曼宁说道。
「从技术角度来看,我将专注于尝试提高 NLP 的鲁棒性以及可解释性。在 NLP 领域中,如果了解 NLP 的结构,了解 NLP 的语义,将是人们构建可信任 AI 向前迈进的一大步,」周伯文表示。「如何预测下一个单词的过程对于人们来说还是一个黑箱。另一个方向是可扩展性,当我们从一个任务转移到另一个任务时,模型需要迁移得足够好。无论如何,可信赖的 AI 非常重要。如果我们可以在这个领域取得更大的进步,AI 市场和 AI 应用将变得越来越大、越来越多,并且适应性也将大大提高。因此,这将是我们长期关注的重点。」
2020 智源 - 京东多模态对话挑战大赛
在 2019 年,京东举办了 JDDC 对话大赛,去年的主题是 Knowledge-enhanced Task-Oriented Dialogue,今年在智源大会上举办的对话大赛则主要关注对话中的多模态交互,即研究如何更好的理解对话中的多模态信息,产生 Task-Oriented Conversational response。
本次竞赛的数据来自于脱敏后的京东真实客服对话日志,共包含约 200 万轮次的对话,其中用户问题涉及约图片约 50 万张。
周伯文介绍到,为支持参赛队伍更好的比赛,本次大赛还提供了约 3 万商品的小型商品知识库,和 2 万张图片的标注数据。大赛开始三周,到目前为止已有超过 400 人参加比赛。

这场连接京东大厦和斯坦福校园的对话,给我们带来了很多启发。由于新冠疫情的影响,周伯文与曼宁无法进行面对面的交谈,不过两人已经开始期待下一次的见面了。
不知下次见面时,人工智能技术将会出现哪些大发展?
本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
原标题:《周伯文对话斯坦福教授曼宁:人机对话智能新进展需要新「图灵测试」》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

