- +1
在家憋疯的外国人,用奇怪的方法练起了口技
原创 栗子 果壳

疫情所致,歪果仁也许久不曾出门了。
日子一长,难免开始修习奇妙的法术。
口技便是其中之一。这门古老的艺术,没有经年累月的苦练,恐怕难以运用自如。
不料谷歌众人搬出一只AI。有了它,即便是凡人发出的声响,也能变成乐器的音色。比如萨克斯风的旋律:
卖家秀来自谷歌研究员;买家秀素材来自撒贝宁《经典咏流传》,萨克斯风音色由AI合成丨DDSP
这AI叫做DDSP,已有线上试玩Demo。既然建国之后无法成精,不如就化作戏精吧:
https://colab.research.google.com/github/magenta/ddsp/blob/master/ddsp/colab/demos/timbre_transfer.ipynb
在下服用之后,表示疗效上佳。
模仿,要从源头学起
假如只懂得萨克斯风一种乐器,恐怕还称不上口技。
DDSP还支持长笛、小提琴和小号的修炼。你听,这里有长笛独奏的五环之歌:
五环之歌素材来自《鲁豫有约》,钢琴版《名侦探柯南》主题曲素材来自Lisa's Music Diary,长笛音色由AI合成丨DDSP
当然,原声不见得要人声才好,钢琴声转为长笛依然清脆悠扬。
那么,这般音色生成技能从何而来?谷歌科学家说,DDSP最独到的地方在于:关心声音是如何产生,又是如何被人体感知的。
物体振动的时候,动能和弹性势能周期性地此起彼伏,就像弹簧振子那样丨Oleg Alexandrov
世间万物,都在周期性地振动,这便是声音的来源。而人类的听觉,也在漫长的进化中,变得对周期性振动非常敏感。
那么,AI合成器也该重点学习周期性振动的特点吧?可当代拥有学习能力的AI多用神经网络打造而成,神经网络很少用到振动的周期性。而用上了这层知识的声码器(vocoder)方法,却因为表达能力不足,又难和神经网络结合起来,渐渐被冷落了。
如今,谷歌的科学家们找到新的方法DDSP,利用了声音产生和感知的规律,没有损伤表达能力,也与当代AI融为一体。于是,它登上了机器学习顶会ICLR 2020。
鱼和熊掌,如何兼得?
首先,既然要利用声音产生和感知的规律,团队想起了角落里被冷落的声码器。从前,它主要用来合成人类语音:在人讲话的声波里,有许多周期性的波形,这些周期波便被当做基本的声源信号,被声码器分析和利用起来。

声码器的合成方法,主要分为加法合成与减法合成。加法,是把许多正弦波合在一起;减法,是从原有声波里过滤掉一部分,留下的就是结果。加法比减法的表达能力更强,需要的参数也更多,因为每个正弦波都有自己随着时间变化的振幅(音量)和频率(音高)。
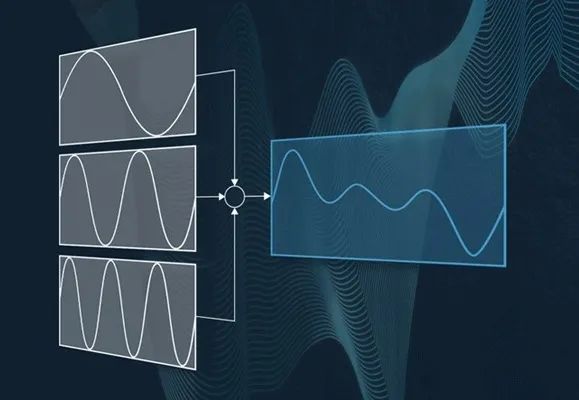
科学家借用了一种来自1990年的音频合成模型,把加和减结合起来。这种方法的加法部分,比其他同类模型拥有更多参数,令表达能力得到了保证;减法部分则滤掉了背景音,让主角的声波能得到更好的处理。并且,最后还可以把背景音加回去,让生成的效果更自然。
更重要的是,每一个模块都是可微分(differentiable)的,这也是DDSP里第一个D的由来。而一个数字信号处理(DSP)模型可微分,表示只要投喂某种乐器演奏的音频,它的训练便能从输入到输出一气呵成;相比之下,每个模块独自训练的模型,总体成绩未必达到最佳。
心有多大,舞台就有多大
现在,来感受一下小提琴的训练成果吧。
《名侦探柯南》主题曲哼唱素材来自作者,小提琴音色由AI合成;真人小提琴演奏片段来自Louis Liao,演奏者Carol Lin丨DDSP
仿佛一只熊孩子,修习小提琴不久,手法不甚娴熟,还没完全渡过拉锯时期。不过,装饰音倒有几分调皮的神采。
练着练着,熊孩子出了一道题。妈妈,你能听出这是哪句话吗:
原句语音素材由谷歌娘TTS合成,小提琴音色由AI合成丨DDSP
妈妈深感孺子可教,并奖励他再练一会儿小号:
《少女终末旅行》插曲与《千与千寻的神隐》主题曲哼唱素材来自作者,小号音色由AI合成丨DDSP
或许气息还有些不足,但至少不会被妈妈听出是AI在吹号了(误)。
以上音频,都是用DDSP线上试玩版生成的。官方提供了四种乐器,且支持音量和音高调节。
除此之外,你也可以自行录下其他乐音(比如猫叫),投喂给DDSP去学习。
说不定哪天,你一开口便能发出你家主子的声音,岂不美哉?只待团队把这口技AI实时化,你就能和主子展开更亲切的会谈了。

参考文献
[1] Engel, J., Hantrakul, L., Gu, C., & Roberts, A. (2020). DDSP: Differentiable Digital Signal Processing. arXiv preprint arXiv:2001.04643.
[2] Theunissen, F. E., & Elie, J. E. (2014). Neural processing of natural sounds. Nature Reviews Neuroscience, 15(6), 355-366.
[3] Serra, X., & Smith, J. (1990). Spectral modeling synthesis: A sound analysis/synthesis system based on a deterministic plus stochastic decomposition. Computer Music Journal, 14(4), 12-24.
作者:栗子
编辑:odette
一个AI
你可猜得出那句10字传世名言?

本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

