- +1
即使在移动AI时代,软件仍将主导业界
机器之心
机器之心专栏
作者:王言治
软硬件都是促进 AI 行业发展的必不可少因素,二者究竟孰轻孰重,各家的看法亦有不同。在本文中,作者首先探讨了 AI 硬件的发展格局,并提出疑问:专用硬件加速是否为正确的发展道路?进而介绍了压缩编译协同设计软件算法方案的细节,并坚信可以改变 AI 边缘计算的格局。本文介绍的压缩 - 编译协同优化系统(CoCoPIE)由美国东北大学王言治研究组,威廉玛丽学院任彬研究组,北卡州立大学慎熙鹏教授研究组共同提出。
人们已经达成了某种共识:那些在边缘设备(edge device)与物联网设备(IoT device)上实现了真正的智能的公司将定义计算的未来。为了实现这一目标,无论是谷歌,微软,亚马逊,苹果和 Facebook 等大型技术公司,还是初创公司,每年在研发上的投入都高达数百亿美元。工业界主要致力于开发用于机器学习和推理的专用硬件加速器,这么做的原因是他们认为硬件因素是实现真正的移动智能的主要限制因素。为此,工业界已经花费了数十亿美元来推动这种智能硬件竞赛。
我们对这种做法有所疑问,并坚信即使在移动 AI 时代,软件仍将主导业界。我们的中心论点是,深度学习应用程序的软件优化潜力仍未得到充分开发。一旦完成了正确的软件优化,我们就可以立即在数十亿个现有移动设备上启用实时深度学习,从而释放一个万亿美元的市场。
在本文的其余部分,我们回顾了 AI 硬件的概况,不同的软件优化方法,并深入研究了我们认为最有希望的方法,即“压缩 - 编译”(compression-compilation)联合设计方法。我们得出的结论是,即使在移动 AI 时代,软件仍在占有并将持续占有整个业界,并且通过纯软件压缩编译协同设计在数十亿个现有移动设备和数万亿个新兴的物联网设备上启用实时 AI 应用程序是最切实可行的方法。
AI 硬件的格局
工业界主要致力于开发用于机器学习和推理的专用硬件加速器,这么做的原因是他们认为硬件因素是实现真正的移动智能的主要限制因素。
芯片制造商英特尔与包括 NVIDIA,AMD 在内的竞争对手以及一些采用 ARM 技术的竞争对手之间的激烈竞争已经使芯片进入 AI 计算市场。如今,在美国,欧洲和亚洲,有 100 多家 AI 芯片初创公司,从重塑可编程逻辑和多核设计(programmable logic and multi-core designs)的公司,到开发自己的全新架构的公司,再到使用神经形态架构(neuromorphic architectures)等未来技术的公司。数百亿美元的风险资金已经投入到这个市场中,以支持这些创业公司,同时也加剧了主要芯片制造商之间的竞争,我们看到英特尔以极高昂的价格收购了 MobilEye,Movidius 和 Altera,Xilinx 收购了 DeePhi,谷歌开发了 TPU,以及 NVIDIA 在自动驾驶处理器方面的大量投资。尽管有大量投入,但到目前为止,输出还是令人失望的,因为我们尚未看到边缘 AI 加速器的任何大规模部署。这不禁使我们思考,专用硬件加速是正确的道路,还是软件仍然主导移动 AI 时代?
经过仔细研究,我们主张通过有效的压缩 - 编译(compression-compilation)协同设计,在不使用特殊硬件加速器的情况下,在现有边缘设备上实现实时人工智能(AI)是可行的。压缩编译协同设计的原理是以手拉手的方式对深度学习模型进行压缩及对压缩后的模型可执行文件的编译。这种协同方法可以有效地优化深度学习模型的大小和速度,还可以大大缩短压缩过程的调整时间,从而极大地缩短了 AI 产品上市的时间。
当我们将深度学习模型部署在主流边缘设备上运行时,我们的设计能在大多数 AI 应用上实现实时性,而这些 AI 应用原本被广泛的认为只有使用特殊的 AI 加速器才能到达实时运行的效果。得益于主流处理器相对于特殊硬件的多重优势,对于实时 AI 的特殊硬件需求可能将会逐渐降低:
上市时间:特殊硬件通常需要数年才能上市。为新开发的硬件加速器创建关联的编译器和系统软件会进一步延长该过程。使用此类硬件的应用程序经常需要使用特殊的 API 并满足许多特殊的约束(例如,将计算限制到特定大小),这会延长 AI 产品的上市时间。
成本:开发专用的 ASIC 处理器非常昂贵,将它们添加到现有系统中会产生额外的费用。
技术成熟度:与通用处理器不同,专用硬件的生产量要小得多;因此,其生产可用的技术通常比通用处理器落后几代。例如,大多数 AI 加速器都基于 28 至 65nm CMOS 技术,其晶体管密度比最新的移动 CPU 或 GPU 低 10 倍以上。
速度:由于采用了旧技术,专用处理器的运行速度比通用处理器要慢得多。
生态系统:通用处理器具有完善的生态系统(调试工具,优化工具,安全措施),这使得高质量应用程序的开发比使用特殊处理器要容易得多。
使用:由于上述所有原因,使用特殊处理器通常仅限于创建该处理器的公司及其很少的密切客户。结果,为特殊处理器开发的 AI 应用程序仅可以被有限数量的设备所采用。
压缩编译协同设计软件算法方案
在本节中,我们介绍了压缩编译协同设计软件算法方案的细节,我们相信这将完全改变 AI 边缘计算的格局。压缩和编译是在硬件上拟合深度学习模型以实现有效执行的两个关键步骤。模型压缩是减少深度学习模型的大小并提高其速度的常用技术。压缩技术分为两类,剪枝(pruning)和量化(quantization)。剪枝会删除层或层中的输出(filter)或输入(channel)通道,而量化会降低参数的精度(例如,浮点数到短整数)。编译是指从给定的深度学习模型生成可执行代码的过程。本质上,编译是将深度学习中的高级操作映射到基础硬件支持的低级指令的过程。编译过程在优化代码以有效执行中起着关键作用。
压缩编译协同设计的原理是同时完成压缩与编译两个组件的设计,并且此协同作用体现在三个层次上。
需求 / 偏好级别:在此级别上,协同作用是在设计另一个组件时考虑一个组件的偏好或需求。一个例子是,主流处理器通常更喜欢具有某些计算模式(pattern)的代码。如果模型压缩步骤可以考虑该首选项,则可以创建一个更可修改的方案,以使得编译步骤有效地工作。
视角 / 内涵级别:在此级别上,协同作用是在处理其中一个组件的问题时采取另一个组件对该问题的视角或内涵。一个例子就是可组合性或模块化原则,这个原则在保持编程系统和编译高效且可扩展方面一直发挥着至关重要的作用。
方法论级别:在此级别上,协同作用是将两个组件的方法论紧密集成在一起。例如,通过自动生成代码以启用新的深度学习剪枝方案的编译器框架,我们可以产生高达 180 倍的加速。
具体来说,我们在上图中提供了压缩编译协同设计架构,该架构包含以下组件:
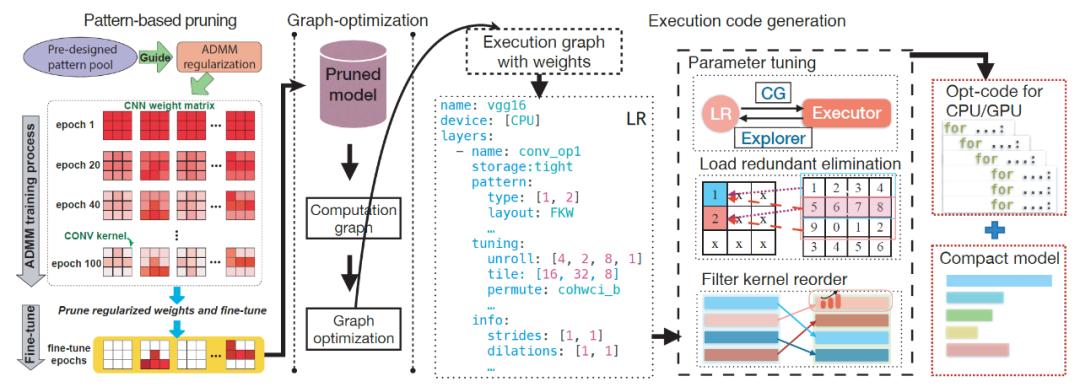
细粒度的 DNN 分层表示(LR)提供了高级别的表示方法,使我们能够从各种资源对 DNN 模型进行常规优化。特别地,LR 包括模式(pattern)和调谐(tuning)相关信息。编译器的优化依赖于 LR 的一系列改进,以生成紧凑模型和优化过的执行代码。
卷积核与输出通道重排(filter kernel reorder)通过将具有相同长度和模式的卷积核组合在一起,解决了模式化剪枝带来的两个挑战,即密集的控制流指令以及线程分散(thread divergence)和负载不均衡(load imbalance)。由于卷积核模式数量相对有限,可以通过适当的卷积核内核重新排序将具有相似模式的内核进行编组,从而显著减少控制流指令并提高指令级并行度。此外,如果不同的线程处理不同的输出通道,则由于每个输出通道中的内核具有相似的计算工作量,因此可以正确解决线程分散和负载不均衡的问题,从而增强了线程级并行度。
压缩权重存储(compressed weight storage)格式是专门为我们的卷积核模式和连通性剪枝设计的。与卷积核与输出通道重排结合后,这种紧凑的数据结构比传统的 CSR(压缩稀疏行)格式能够产生更好的压缩率。
消除负载冗余(load redundancy elimination)通过在内核执行代码生成过程中通过分析处理两个寄存器级负载冗余问题,解决了基于卷积核模式化剪枝对内存性能的挑战。在内存和缓存之间的数据移动已通过高级数据平铺技术进行了优化的前提下,我们的负载冗余消除有着更加重要的意义。
参数自动调整(parameter auto-tuning)专门测试关键性能参数的不同配置,包括将数据放置在各种 GPU/CPU 存储器上,不同的数据平铺大小以及每个处理单元上每个 DNN 层的循环置换的策略。
总而言之,压缩编译协同设计方法允许编译器将剪枝后的内核视为特殊模式,不仅可以实现模型的高精度与高压缩率,还可以有效地将卷积核模式转换为硬件上的性能提升。
性能对比:软件与硬件
为了验证我们的中心论点,即软件仍然主导 AI 时代,我们需要回答的关键问题是,在现有的设备上,“压缩 - 编译”联合设计方法是否优于专用的硬件加速器。我们在三星 Galaxy S10 智能手机上部署了 “压缩 - 编译” 联合设计的框架,并将其性能与在 ASIC 和 FPGA 上实现的硬件加速器进行了比较。

我们可以清楚地看到,我们在现有的移动设备上的解决方案在能效方面始终优于代表性的 ASIC / FPGA 解决方案。这种独特的现象归因于三个原因:
智能手机本身具有超高的能量效率。智能手机计算芯片是使用最先进的技术(例如 7nm,11nm 技术)构建的,并且是技术进步的关键驱动力,而 FPGA / ASIC 解决方案则基于 28nm 或 40nm 技术,而这些技术本身就不那么节能。同样,ARM(用于移动 CPU)和高通(Qualcomm)(用于移动 GPU)尤其擅长高效电路 / 系统设计。
虽然现有的移动编译器框架对不同神经网络的支持有限(例如,不支持 RNN 或大规模 DNN),但我们的编译器可以支持所有主要类型的神经网络,从而释放了移动设备的全部潜力。
由于基于软件的解决方案具有高度的灵活性,因此我们的方法在不同的 DNN 基准上始终保持高性能。相反,可以清楚地看到,当前的 ASIC / FPGA 解决方案针对特定的 DNN 类型 / 大小进行了优化,因此缺乏通用性。具体而言,边缘 TPU 针对小型 DNN 优化,而 Cambricon MLU-100 针对大型 DNN 优化。
压缩编译协同设计与其它软件算法的性能对比
下一个问题就是在相同的硬件条件下,我们的方法能否超出现有的其它软件优化算法,也即压缩编译协同设计方法是否具有显著的优越性。
我们在三星 Galaxy S10 智能手机上测试评估我们的算法性能。S10 拥有最新的高通骁龙(Qualcomm Snapdragon)855 移动平台,包含了高通 Kryo 485 8 核 CPU 和高通 Adreno 640 移动 GPU。
下图显示了在 CPU 和 GPU 上,我们的算法与 TFLite,TVM 以及 MNN 加速框架的性能对比。我们采用了 6 种代表性的 DNN 模型结构,包括 VGG-16 (VGG), ResNet-50 (RNT), and MobileNet-V2 (MBNT) ,在 CIFAR-10 和 ImageNet 这两个数据集上做训练。结果显示在所有的测试环境配置下,我们的压缩编译协同设计算法都超越了其它的加速框架。
在移动 CPU 上,我们的算法相较于 TFLite,实现了 12 倍到 44.5 倍的加速效果,相较于 TVM,实现了 2.3 倍至 8.1 倍的加速效果,相较于 MNN,实现了 1.9 倍至 15.5 倍的加速效果。在 GPU 上,相较于 TFLite,TVM 以及 MNN,分别实现了 2.5 倍至 20 倍,4.1 倍至 11.4 倍,以及 2.5 倍至 6.2 倍的加速效果。对于最大的 DNN 模型 VGG 以及最复杂的 ImageNet 数据集,我们的算法在移动 GPU 上只需要用 18.9 毫秒就能完成单一输入图片的所有卷积层的计算操作,满足了实时性的要求(实时性通常要求实现每秒 30 帧,即每帧 33 毫秒)。

最后但也是最重要的一个问题就是在现有的移动环境和设备下,我们的算法可以实现哪些应用?这个问题直接关联到压缩编译协同设计方法的潜在的商业价值。
为了说明这个问题,我们研究了三种可能的 DNN 应用,包括风格迁移(style transfer),DNN 上色(coloring),以及超分辨率(提高分辨率,super resolution)。风格迁移的模型是基于在微软 COCO 数据集上训练的生成型网络,可以实现视频流的实时风格迁移效果。DNN 上色用 Places scene 数据集去训练一个可以同时抽取与融合全局和局部特征的模型,来实现将一个黑白视频流实时地转化为彩色视频流的功能。超分辨率模型主要利用在 DIV2K 数据集上训练的具有更宽激活层与线性低秩卷积的差分模块,实现将低分辨率的视频流实时转化为高分辨率的视频流的效果。

即使在移动 AI 时代,软件仍然占据主宰地位
我们这篇文章的核心观点是即使在 AI 时代,软件仍将主导业界。我们希望通过这篇文章能够向读者表明,我们还是可以在现有的商业计算设备上实现 AI,并且提供甚至比专业的 AI 硬件加速器更高的加速效果以及能量效率。这能够扩展 AI 在边缘计算设备上的能力,并且改变人们对终端设备上实现实时 AI 就必须采用专业的特殊 AI 硬件的认知。
我们相信这些结果会促使工业界重新审视现有的移动 AI 的发展方向和策略。这些令人振奋的进展显示了很多潜在的未来发展方向,我们这里列举两个。
第一个方向是扩展基于协同设计优化的领域。目前为止,压缩编译协同设计的原理主要聚焦于 DNN 模型。除了 DNN,现实世界的 AI 应用通常包括很多其它的内容,比如数据收集,数据预处理,以及用 DNN 预测之后的操作等等。DNN 在整个应用中扮演着一个很重要的角色,导致我们主要聚焦于 DNN 的优化,而缺乏对整个应用的优化,以至于难以满足用户的实际需求。所以一个很重要的方向就是如何将压缩编译协同设计的原理拓展到对整个 AI 应用的全面优化过程中。
第二个方向是扩展基于协同设计的优化的适用性。这一方向关联到隐私性与安全性,这是在很多 AI 模型构建和部署中很重要的两个因素。如何将它们有机地与压缩编译协同设计过程相结合,这是一个值得研究的问题。通常来说,模型剪枝需要访问模型和整个训练数据集。但是在某些场景下,由于隐私政策或者公司之间的人造边界,模型的优化者可能并不能够访问数据集。有效规避这些拦路石可以扩展协同优化方案的适用性。
压缩编译协同设计软件算法方案可以在数十亿的现有的移动设备以及数万亿的大有可为的物联网设备上,立即实现实时的深度学习应用,产生巨大的商业价值。比如说,这种方法可以极大地提升视频流应用(如 Netflix,YouTube,抖音,或者 Snap)的用户在低宽带场景下的用户体验。这些应用可以推送低分辨率的视频到用户的设备,然后我们可以实时地将之转化为高分辨率的视频。类似的,视频通信类应用,如 Zoom,Skype,和 WebEx,可以利用压缩编译协同设计方法,达到最好的服务质量。此外,这种方法还能够解锁很多之前不可能的实时深度学习应用,例如用一个移动手机摄像头来获得实时的带有艺术风格的视频流。
请联系 info@cocopie.ai 以获得更多的信息。
更多的论据
本章为有兴趣的读者提供更多的细节,以理解压缩编译协同设计是如何运作的。利用压缩编译协同设计方案,我们可以方便的支持所有种类的 DNN,包括 CNN,RNN,transformer,语言模型等等。此外,这种方法实现了最快的 DNN 剪枝与加速的框架, 相较于现有的 DNN 加速方案如 TensorFlow-Lite,它最高可以实现 180 倍的加速。总而言之,压缩编译协同设计方案可以使得 AI 应用在现有的移动设备上实时地运行,这在原来的观念中,被认为是只有专业的硬件设备支持才能够做到的。
如果读者想要挖掘更多的技术细节,可以参考下面的完整的压缩编译协同设计技术概览:https://arxiv.org/abs/2003.06700
我们在下面的网址中展示了利用压缩编译协同设计方案在现有的移动设备上实现实时地视频分辨率提升的视频:https://www.youtube.com/watch?v=UqaRtG5EVR4
关于基于卷积核模式化剪枝以及算法层优化的细节与结果,读者可以参考下面的研究论文:
[AAAI’2020] Xiaolong Ma, Fu-Ming Guo, Wei Niu, Xue Lin, Jian Tang, Kaisheng Ma, Bin Ren, and Yanzhi Wang, PCONV: The Missing but Desirable Sparsity in DNN Weight Pruning for Real-Time Execution on Mobile Device, The 34th AAAI Conference on Artificial Intelligence, February, 2020.
关于基本卷积核模式化剪枝的编译代码生成以及优化的框架,以及与算法层优化和系统层优化相结合的细节与结果,读者可以参考下面的研究论文
[ASPLOS’2020] Wei Niu, Xiaolong Ma, Sheng Lin, Shihao Wang, Xuehai Qian, Xue Lin, Yanzhi Wang, and Bin Ren, PatDNN: Achieving Real-Time DNN Execution on Mobile Devices with Pattern-based Weight Pruning, The 25th International Conference on Architectural Support for Programming Languages and Operating Systems, March, 2020.
关于更快实现 DNN 剪枝的基于具有可组合性(composability)的编译框架的细节与结果,读者可以参考下面的研究论文
[PLDI’2019] “Wootz: A Compiler-Based Framework for Fast CNN Pruning via Composability”, Hui Guan, Xipeng Shen, Seung-Hwan Lim, Programming Language Design and Implementation, Phoenix, AZ, USA, June, 2019.
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

