- +1
DeepMind首次在所有57款雅达利游戏上超越人类玩家
挑战雅达利游戏,一直是DeepMind的研究日常。当地时间3月31日,这家全球最受瞩目的人工智能公司在自己的官方博客上宣布了挑战的最新进展:在57款雅达利游戏中全面超越人类,在该领域里是第一次。

DeepMind 在最新发布的预印本论文和博客中表示,他们构建了一个名为Agent57的智能体,该智能体在街机学习环境(Arcade Learning Environment,ALE)数据集所有57个雅达利游戏中实现了超越人类的表现。
如果Agent57真如DeepMind所描述的那样优秀,那么它将为构建更加强大的AI决策模型奠定基础。想象一下,人工智能不仅可以自动完成平凡、重复性的任务(比如数据输入),还可以自动推理环境。这对于那些希望实现自动化以提高生产力的企业而言,可能就是福音。
为什么选择雅达利游戏
让单个智能体完成尽可能多的任务是DeepMind一直以来的研究目标,也被该公司视为迈向通用人工智能的必经之路。而利用游戏来评估智能体性能是强化学习研究中的一个普遍做法。游戏中的环境是对真实环境的一种模拟,通常来说,智能体在游戏中能够应对的环境越复杂,它在真实环境中的适应能力也会越强。
这次DeepMind挑战的街机学习环境中包含57款雅达利游戏,可以为强化学习智能体提供各种复杂挑战,因此被视为评估智能体通用能力的理想试验场。
选择雅达利游戏作为挑战目标的原因主要有3点。首先,雅达利游戏足够多样化,可以评估智能体的泛化性能;其次,它足够有趣,可以模拟在真实环境中可能遇到的情况;第三,雅达利游戏是由独立的组织构建,可以避免实验偏见。
早在2012年,DeepMind开发Deep Q-Network(DQN)来挑战雅达利57中游戏。DQN是雅达利2600游戏众多挑战者中第一个达到人类控制水平的智能体。期间尽管取得了进步,但经过改进后的 DQN始终没有克服四款比较难的游戏:Montezuma's Revenge、Pitfall、Solaris和Skiing。此次新发布的Agent57改变了这一局面。
Agent57如何实现超越人类
DeepMind在自己的博客上公布了Agent57的框架。Agent57使用强化学习算法,同时运行在多台电脑上,这些AI赋能的智能体在环境中会选择能够最大化奖赏的动作去执行。此前,强化学习在电子游戏领域已经展现出了极大的潜力。OpenAI的OpenAI Five和DeepMind的AlphaStar RL智能体分别打败了 99.4%的Dota 2玩家和99.8%的星际2玩家。
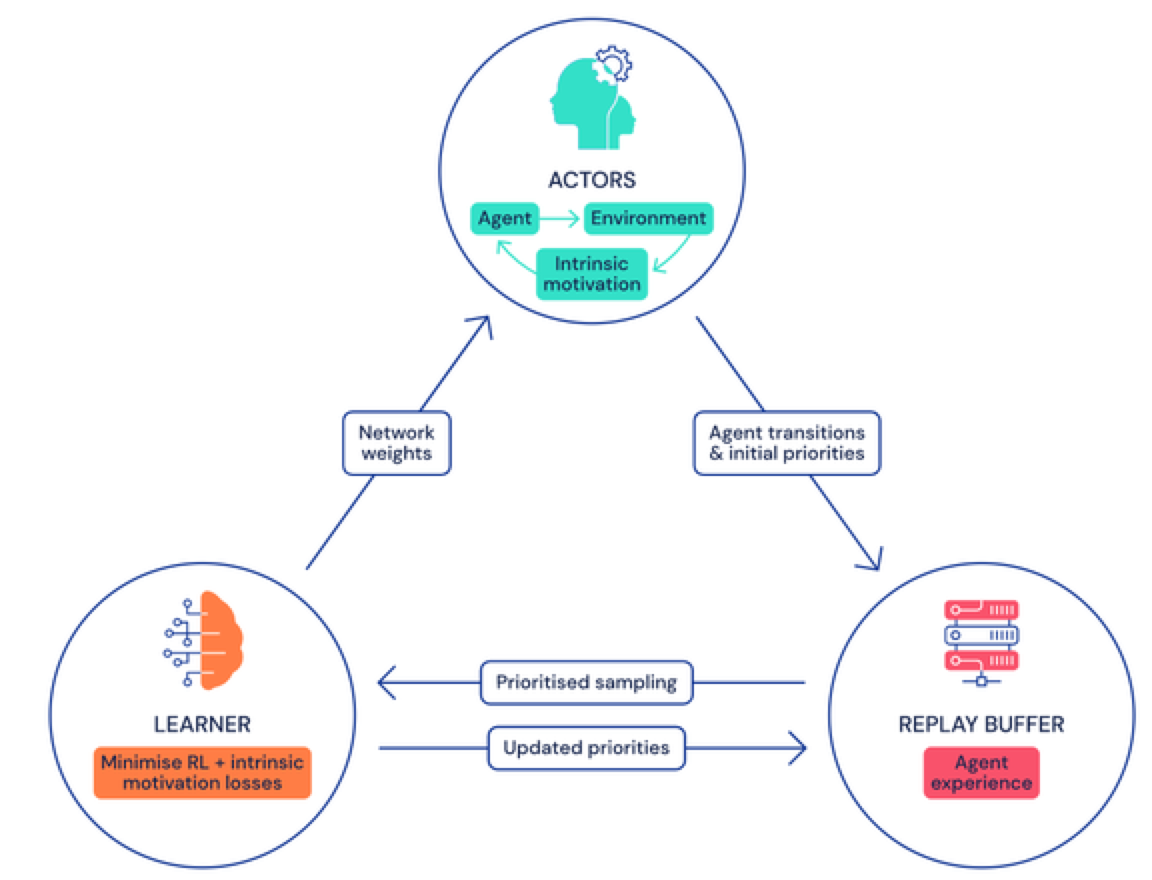
具体来说,Agent57通过将众多actor(actor可以理解为一个有状态的行为)馈入到可以采样的一个中央存储库(也称为经验回溯缓冲器)中学习,进而实现数据收集。该缓冲器包含定期剪枝的过渡序列,它们是在与独立、按优先级排列的游戏环境副本交互的actor进程中产生的。
DeepMind团队使用两种不同的AI模型来近似每个状态动作的价值(state-action value),这些价值能够说明智能体利用给定策略来执行特定动作的好坏程度,这样就使得Agent57可以适应与奖励相对应的均值与方差。他们还整合了一个可以在每个actor上独立运行的元控制器,从而可以在训练和评估时,适应性地选择使用哪种策略。
DeepMind研究团队表示,这个框架模型具有以下两大优势:第一,得益于训练中的策略优先级选择,它可以使得Agent57分配更多的网络容量,来更好地表征与手边任务最相关策略的状态行动值函数;第二,在评估时,它可以用一种自然的方式来选择最佳策略。
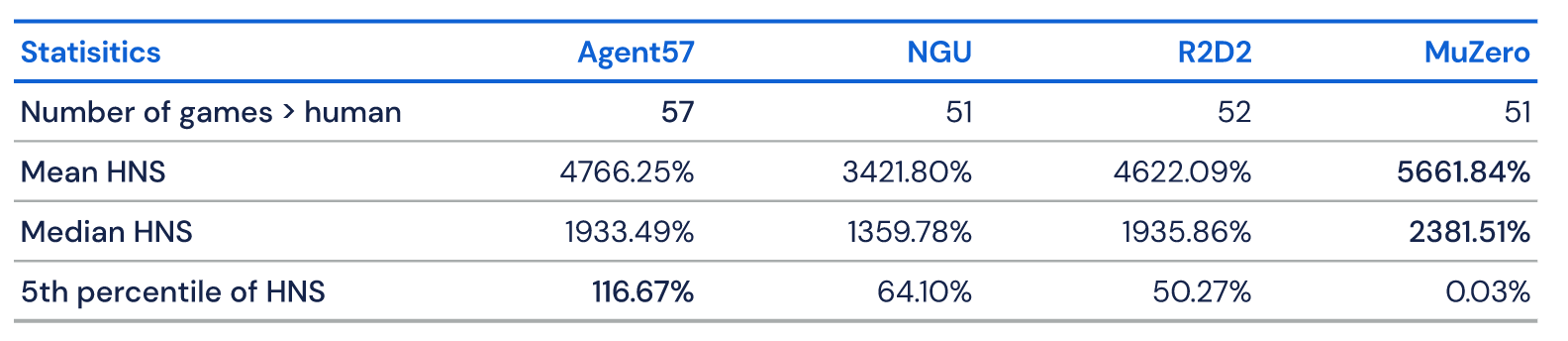
DeepMind团队将自己的算法与MuZero、R2D2和NGU等领先算法进行了对比。其中,MuZero在全部57种游戏中达到了最高平均分(5661.84)和最高中值(2381.51),但在Venture等游戏中表现很差,得分只到和随机策略相当的水平。
与之相比,Agent57的总体表现上限更高(100),训练50亿帧后即在51种游戏上超越了人类,训练780亿帧后在Skiing游戏上超越了人类。
表现优于人类之后
DeepMind团队也在官方博客中透露了团队的下一步计划。“Agent57最终在所有基准测试集最困难的游戏中都超过了人类水平。但这并不意味着雅达利游戏研究的结束,我们不仅要关注数据效率,也需要关注总体表现……未来的主要改进可能会面向 Agent57在探索、规划和信度分配上。”论文合作者之一在官方博客中写道。
不过,对于DeepMind此次的新进展,有不少网友在网上表示祝贺,但也有人提出质疑。有人就认为Agent57表现优于人类的说法并不准确,只能说表现优于人类平均水平,因为在Montezuma's Revenge这款游戏中,Agent57并没有打破人类的最高水平。另一方面,有人认为DeepMind的研究总是侧重于在雅达利等游戏上的性能表现,但如何利用这种模型来解决现实世界的实际问题才更关键。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

