- +1
防控力度多大才能遏制疫情发展? 网络动力学推演给你答案
原创 张江 集智俱乐部

近期新型冠状病毒(2019-nCov)引发的疫情备受关注,已经有一些针对病毒起源、机理、传播的研究。春运返岗大潮将至,多地区纷纷限制公共交通,背后的原因是什么?本文特别关注由于人群迁徙引起的病毒传播和疫情扩散,根据经典论文提出的方法,采用截至 1 月 28 日的最新人流数据,预测人群迁徙背景下,疫情在多个城市二次爆发的风险,并尝试为多个地区的交通管制提供理论支持。
声明:本文在无人为干预的假设下,依据《The Hidden Geometry of Complex, Network-Driven Contagion Phenomena》一文提供的方法,针对现有数据进行了初步分析,仅作为科学探讨,不构成决策依据。在现有的强力交通管制下,疫情扩散速度应远小于本文预测的数据。
新型冠状病毒(2019-nCov)的爆发牵动着全国14亿人民,甚至是全球70亿人的心。病毒传播的速度非常之快,我们有必要通过大数据分析,建模模拟等手段对数据进行分析。
目前,无论是正式学术刊物发表的文章还是网络上传播的文章来看,大多集中在对于新型冠状病毒的来源,以及传播特性的估算。特别是,基本再生数作为一个能够反映病毒传播速度的参数引起了广泛的争论。然而,目前的这些讨论大多集中在对武汉疫情的分析,而较少关注疫情随着人类的迁徙行为而引发的全国乃至全球城市的传播。也有一些文章通过各种渠道的人类迁徙数据来分析病毒的传播,但这些分析大多是对从武汉迁出的各种渠道的流量进行计算,尚没有讨论这些迁徙行为对病毒在其它城市的爆发进行广泛的讨论。进一步,目前我们尚未看到对这种二级爆发现象的定量分析文章。
本文将试图对由于大量的人口流动而导致的病毒二级甚至三级爆发的可能性进行了探讨。而且,我们采用的是定量化计算机模拟与数据拟合并进的手段来完成的多城市间病毒传播与扩散行为的分析。我们采纳了2013年Dirk Brockmann与 Dirk Helbing二人合著的经典文章《The Hidden Geometry of Complex, Network-Driven Contagion Phenomena》一文(后面简称《几何》)中所述及的方法,并结合利用百度迁徙公布的每个城市到各个目标城市的流出比例数据,以及澎湃新闻美数课整理提供数据,以及2016年的百度迁徙数据等多数据来源选定参数进行建模分析的。
一、有效距离
在《几何》一文中,作者们提出了一种全新的距离概念,被称为有效距离,并声称在病毒扩散传播中,该距离远比地理距离起到了更加至关重要的作用。那么,这种有效距离是什么呢?其实就是现代人类乘坐交通工具进行的长程迁徙而形成的一种几何效应。
具体来讲,我们不妨假设人们是一个毫无目的的随机游走粒子,则它们的一些可能从A出发沿着交通路网中的所有可能路径到达B地,在这些粒子中,最先到达B的粒子所跳转的步数就是有效距离。这种情况下,即使A和B没有道路,粒子也可能通过其它城市中转到B。另外,就是当粒子从A出发有多个城市可以到达的时候,它会按照交通流量大小而随机选择下一步的城市。总之,有效路径可以更好地刻画人们乘坐交通工具的出行行为。
我们将最新2020年的从百度迁徙上获得的流量比例数据混合2016年的流量数据得到任意两城之间的跳转概率,并根据这个概率计算得到任意两城市之间的有效距离。我们可以看看,从武汉出发到达的所有城市,按照有效距离从小到大的顺序排序得到:
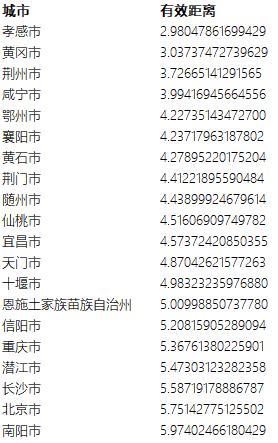
那么,根据《几何》中的结论,这个排名基本就是病毒传播在时间上的先后顺序了。然而,在大家关注武汉疫情的早期,无论是媒体还是公众都忽略了诸如孝感、黄冈、荆州等湖北省的非武汉城市。而最近的疫情爆出了这几个城市的感染人数都是非常大的,这从另一个角度佐证了这个有效距离的有效性。
在之前的一些文章中,有人根据武汉出发的交通流量数据来估算最容易被感染的城市,这是有道理的,事实上在我们的数据中,有效距离与流量之间有着非常好的负相关性:
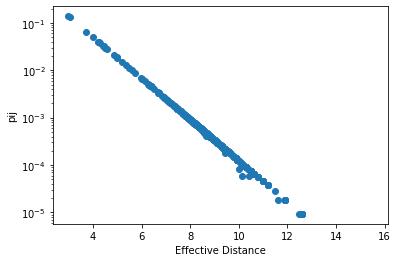
该图即佐证了有效距离与流量之间的关系。可以说从武汉出发到达某城市的流量越大,则该城市爆发疫情的时间就越早。
实证数据是否支持我们的判断呢?让我们将疫情数据代入进来,并计算得到每个城市最先报道病例的时间,然后去看这一时间与该城市有效距离的关系,如下图:
首先,我们来看有效距离,该数值可以衡量病毒扩散到该城市的快慢和先后顺序。我们绘制出首报病例的发病日期和有效距离的关系:
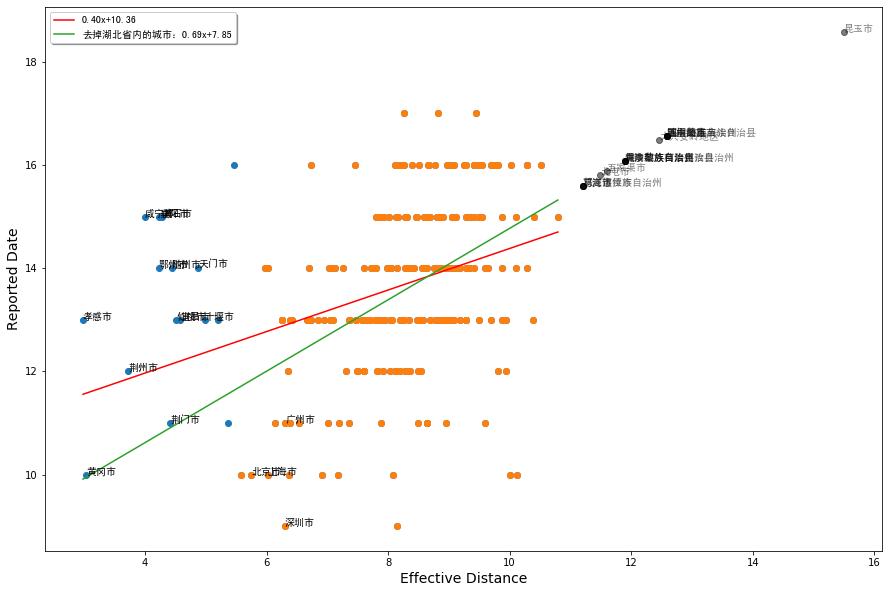
我们采取了两种拟合方式,一种是忽略湖北省的大部分城市,因为我们怀疑这些城市报告的病例并不准,很有可能病毒比报告日期更早地到达了这些区域(见下文讨论),则可以得到更高的斜率,决定系数RSquare也会从0.34提高到0.43。
但是,这种相关性并不强,远比《几何》文章里汇报的结果要差。分析原因有可能有三个:一是《几何》一文大多汇报的是全球尺度、国家级别的传播事件,利用航空数据做估算会比较准确。而我们的流量数据可能不够准确,在基本假设上也可能不满足该文的要求。二是可能纵坐标的这种病例确诊时间远比疾病的首达时间要晚很多。而且,对于部分湖北省内城市,这一偏离可能会非常大。
为了验证这一猜测,我们可以用 “nCoV疫情地图”项目组提供的包含了病人自己汇报的感染日期来计算的首报病例时间来进行作证。
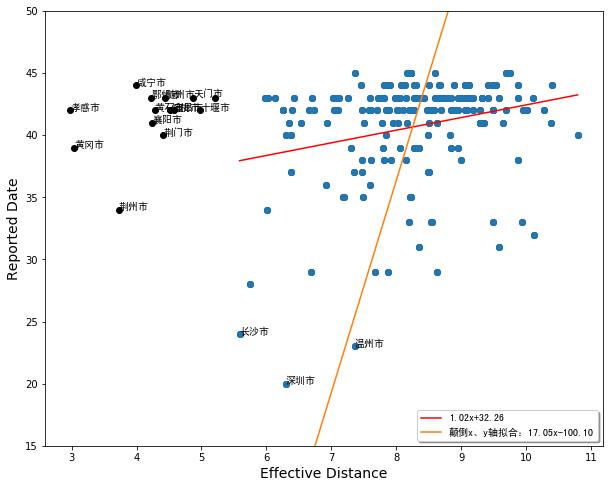
该图中,横坐标同样是有效距离,纵坐标则是清华数据中病例汇报的感染时间(如果这一数据缺失,则我们仍然用确诊时间补充)。在该图中,我们能明显看出长沙、深圳、温州等市汇报的日期要比一般城市的汇报日期更短。因此,我们怀疑,湖北的城市有明显迟报的现象。因此,我们在做第二条拟合线的时候,忽略了这些城市。特别是对于图4,忽略之后的拟合线的斜率达到了17左右,这个数量级是与《几何》一文中一致的。
除了验证这一关系外,我们还可以得到一些预测结果。如图3中,右侧部分延展出去的城市都是一些目前尚无报告病例,而我们根据外推估算出来的首发病例报告时间,例如北屯市将在1月25日左右发现,而昆玉市将可能在29号左右发现。
二、病毒爆发趋势
《几何》一文还给出了一个交通网络上的病毒扩散传播模型,该模型是在SIR模型的基础上改进而得到的,其方程如下:
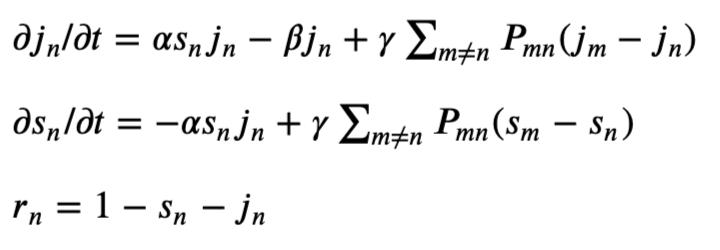
其中jn是n城市感染比例;Sn是n城市疑似人群比例,rn 是n城市恢复健康或死亡的人群比例。α,β,γ 都是参数。下面,分别进行解释并给出取值说明。

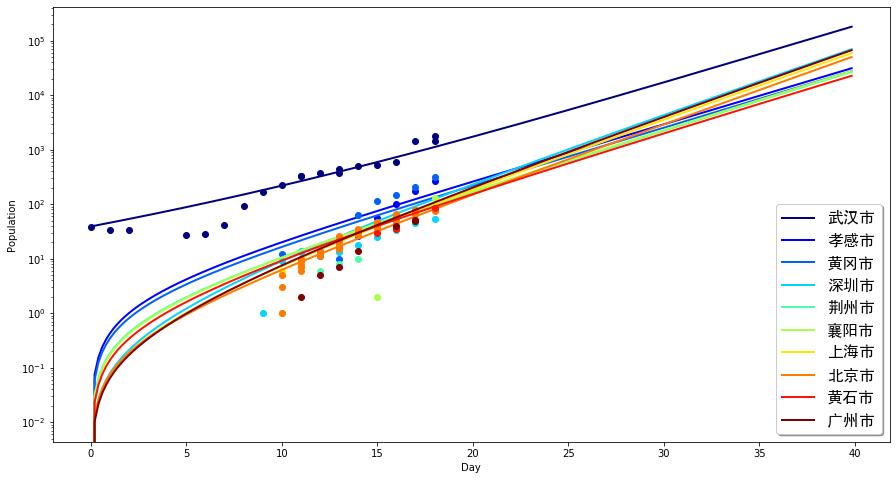
该图横坐标为从1月10日(我们数据中的第一个确诊病例日期)开始的时间,单位是天。纵坐标是不同城市中感染人口。我们挑选了一些武汉周边的城市和北京、上海、广州、深圳这样的大城市,将实际数据与模型计算的结果进行了比较(由于实际情况是指数增长,故而,我们将纵坐标轴取了对数)。我们发现,模型与数据吻合得非常好。这说明我们的模型是可用的。
接下来,就让我们看看,当保持这组参数不变,也就意味着如果我们不采取任何措施的情况下,病毒扩散的情况:
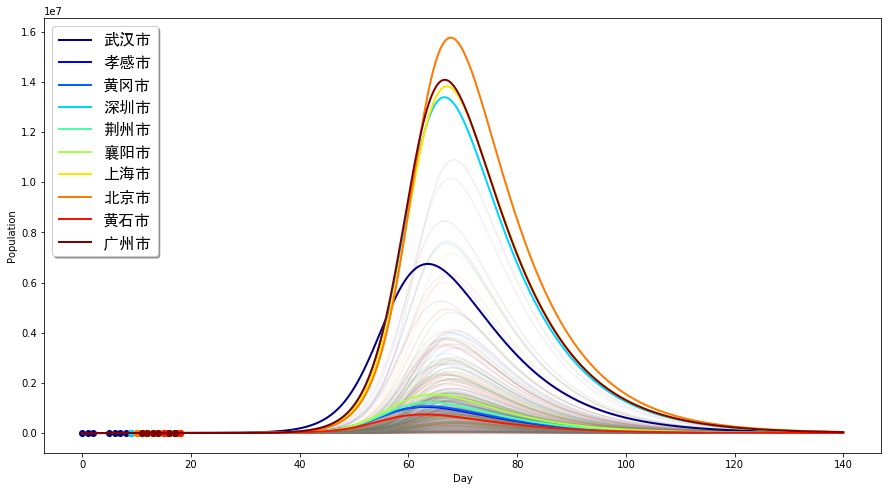
该图就是病毒在无任何限定条件下的扩散传播情况,几个选出来的观察城市用不同颜色较清晰地绘制而出,而所有城市用了比较淡的颜色作为背景绘制而出形成一个带形区域。另外,目前我们能够得到的数据也绘制在了同一张图上,用圆圈点表示(左下角)。从这张图中,我们能够得出以下一些结论:
在不采取任何措施的情况下,现在疾病的扩散仍然处于非常早期的阶段(左下角);而真正的指数增长大爆发要到大概距今20天左右的时间才到来。
在自然条件下,疾病最终退去要等到距今大概120天以后,也就是5月底将近6月。
感染人口最多的城市将是北京,而非武汉,这是因为北京人口基数更大;而其他几个大型城市的感染人数都会比武汉多。纵坐标的数字是10的7次方数量级,这意味着,如果我们不控制疫情的话,感染人数将达到千万量级。比如北京峰值会接近1千6百万。
对于我们关注的城市来看,疾病扩散会明显存在着两个峰,第一个峰是以武汉为首的湖北境内城市,将会在45天后左右到达高峰;第二个峰则是以北京、深圳等大城市为主的,这个峰得到来会比武汉推迟将近10天左右。因此,大致可以说,北京、广州等大城市在“拷贝”十天前的武汉的发展情况。
这表明我们的管控措施绝对是必要的,我们要积极配合。
三、疾病的干预与控制
这些结论可能有些过于骇人听闻,毛骨悚然了。但别忘了,这是在绝对自然的情况下。而现实情况是,我们早已经全社会动员起来了,我们已经对疾病的传播进行了干预和控制。那么,如果将这种干预控制引入到我们的模型中会带来什么效果呢?接下来,就让我们来建模这种情况。
首先,我们将介绍我们的建模思路。在基于(1)式的基础上,我们引入了一个 ξ 项,如下式:
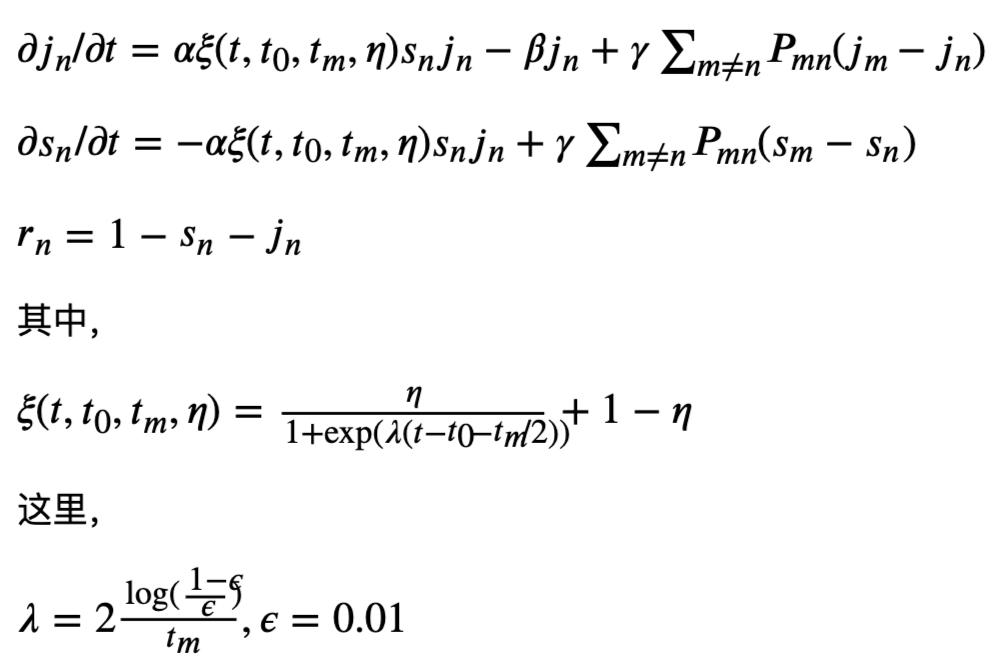
这个 ξ 项就模拟了我们人为干预、控制疾病传播的因素。首先, ξ 是一个介于 η 到1之间的小数乘到了(1)式中的交互作用项上面了,和 α 起到了等同的作用,直接影响健康者与感染者的交互概率。其中 η 是我们人为控制能达到的最小值,这个可以根据能够达到的最小的基础再生数估算出来(后面详细给出)。这个 ξ 是 t 的函数,并且由一组参数:t0, tm 和 η 来控制,也就是说 ξ 会随着时间 t 而变化。
为了形象化看到 ξ 的作用,我们还是绘制出了图形:
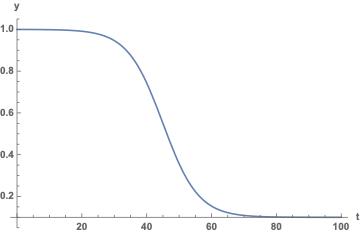
我们观察这个曲线,有两个关键拐点,一个是开始显著下降的点,这个点由参数t0来刻画,表示我们全国开始对疾病进行了干预控制,上图曲线,t0=20;第二个拐点是曲线显著接近于0.1的时间(从t0开始计时),这个时间长度就是我们最终完全将疾病控制住所需要花费的时间,用参数tm来刻画。在上面的曲线中,tm=50。
那么,这些参数怎么取值呢?见下表:

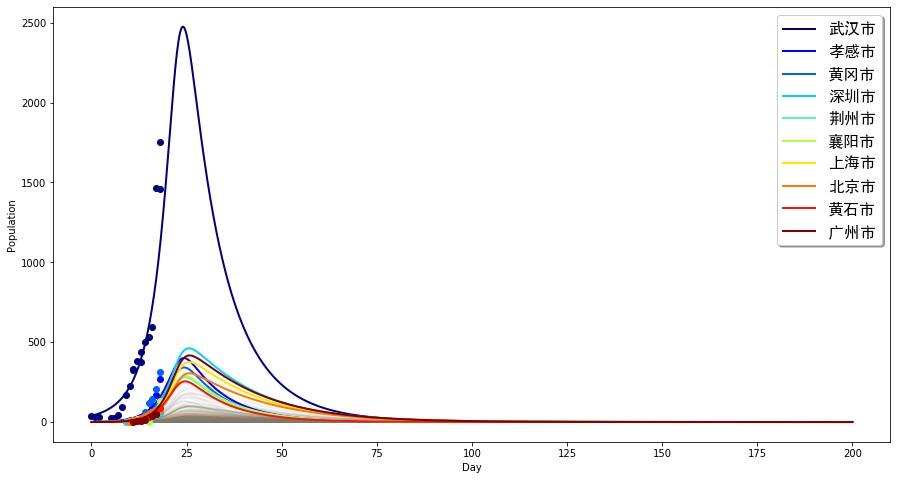
横坐标为时间(1月10日为原点),纵坐标为每个城市感染人口的数量。在这种情况下,我们可以看到,各个城市基本都将会在一周内达到峰值。且武汉感染最多可达2500人左右就开始回落,而深圳市将会达到500左右,其它城市均不到500。而最终感染完全消失要到差不多距今80天以后。
那么,如果更合理一些,我们的管控措施并不能很快地将全国人民动员起来,可能要等到一个月以后才达到目标效果(基本再生数降低到原来的1/4),那么,得到的模拟曲线是:
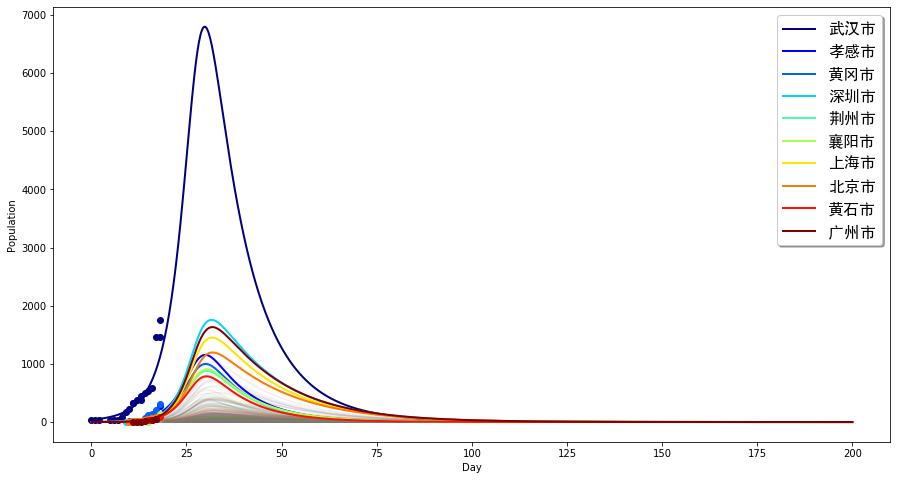
与前面的曲线比,形状没有发生很大变化,但是峰值会明显延后和提高。大概将在距今10天后达到(这一数字和钟南山最新的估计是差不多的),最高到达接近7000的人数,深圳、广州等差不多落后3-5天达到峰值,差不多2000。然而该疾病再过了峰值以后仍然会维持相当长时间的时间,该疾病扩散将维持到80天以后,即到4月份。
其实,这一情况也有可能出现。虽然我们生活在大城市的人都接触这方面消息非常多,因此比较谨慎,管控效果很好。但是,考虑到绝大多数偏远地区、小城镇,则人们可能普遍意识不够强;抑或者过几天的春运高峰的到来也有可能会增加人们交互的比例,而出现这种情况。
下面让我们考虑最糟糕的一种情况。假设我们需要100天(3个月多)的时间,将疾病基础复制数控制在原来的1/4,则会出现下面的情况:
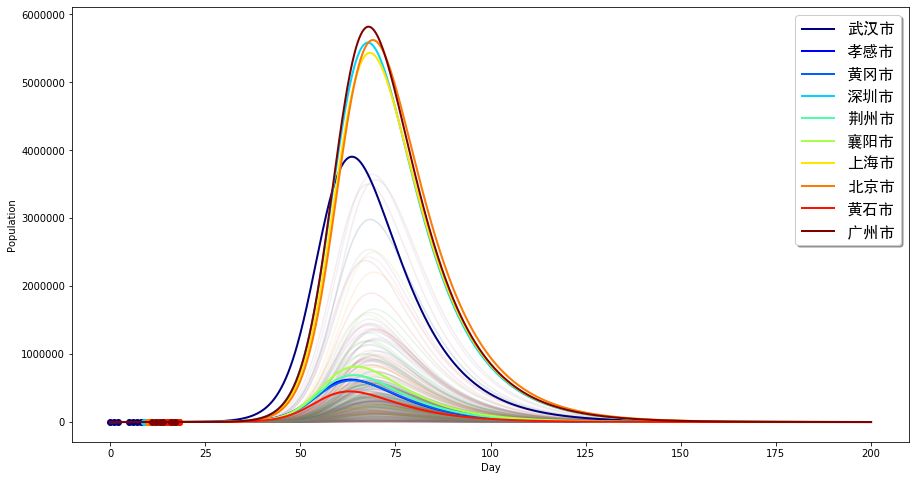
这其实与没有控制的情况差不多。疾病将在大概50天后达到峰值,而且广州、深圳的峰值会远比前面的情况高,武汉、广州等城市最高可达600万不到的感染人数。
在第一种比较保守的估计情况下(即在30天内将病情控制住),我们可以计算全国总的感染人数和死亡人数。我们用病死率来估算死亡人数,考虑到随着人们治疗该病的手段及其疫苗的研制会逐步提升,我们假设最终该病平均的致死率按照3.1%来计算,那么可以得到全国相应的累积死亡人数曲线。我们将全国总感染人数、累积康复人数和累积死亡人数绘制成如下图:
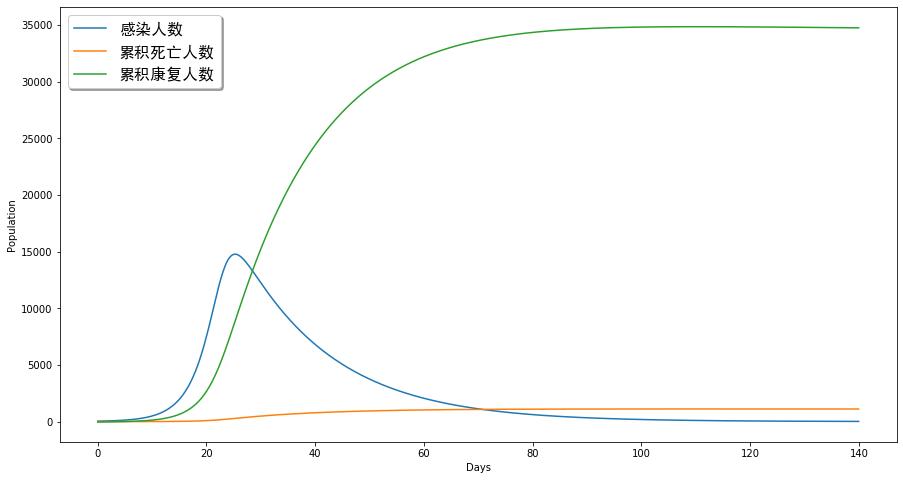
即累积感染人数总量将达到3万5千人,死亡人数将接近1200人。这个数字看起来可能偏向保守,但是如果我们考虑如下因素也有可能正确:
大量确诊病例很有可能会被最终治愈,但目前仍然在医院中观察,故而可能我们估算的死亡比例会过高了;
随着我们对病毒的认识,以及疫苗的研发,将会使得死亡率大大降低,从而导致我们的这个数字估计过高。
死亡人数将接近1200左右。
总之,nCov虽然来势凶猛,但是如果我们加强管控力度,该病毒还是有可能得到有效控制的。我们期待着这场战争最终的胜利。
参考文献:
[1]D. Brockman and D. Helbing: The Hidden Geometry of Complex, Network-Driven Contagion Phenomena, Science 2013
[2] J. M. Read, J. R. E. Bridgen, D. A. T. Cummings, A. Ho, C. P. Jewell, Novel coronavirus 2019-nCoV: early estimation of epidemiological parameters and epidemic predictions, Preprint in MedRXiv 2020.
[3] 周涛文章:
https://new.qq.com/omn/20200126/20200126A08P9W00.html?pc
数据来源:
1、疫情数据由澎湃新闻美数课整理提供 ,并参考“nCoV疫情地图“项目组整理的疫情数据
2、2016年百度迁徙数据
3、2020年百度迁徙部分比例数据
项目地址:
在此我们公开本研究的GitHub项目,欢迎大家找到我们的错误,并批评、挑战这个模型,项目地址为:
https://github.com/jakezj/hidden_geometry_of_nCoV
我们的数据来源有限,如果大家有更精确、更详细的相关数据,请联系相关负责人微信:18621066378
附录:
有关有效路径的进一步解释:
具体来说,如下图,假设从A到B及其周围城市的交通路径(可包括飞机、火车、汽车等一切手段)如左图所示,而其流量大小如连边上的数字所示。当我们计算有效距离的时候,我们先要将连边上的流量数字转化为占比数字,即从A到B的流量所占从A出发的所有流量的比例,如右图所示。
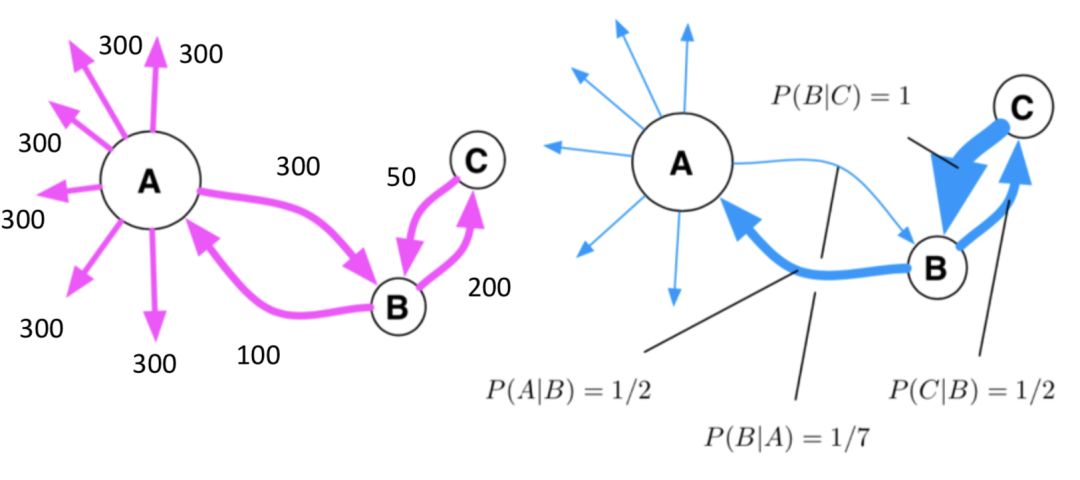
这个时候,我们就能计算有效距离了。例如,A到B的有效距离就是
d(A-->B) = 1 - logP(B|A)=1-log7
为什么要取对数,为什么又要减1?这个请听我在线上讲座的解释(讲座视频录像见文末):为什么病毒扩散这么快?从网络科学视角看大规模流行病传播。
然后A到C的有效距离可以这样来算:
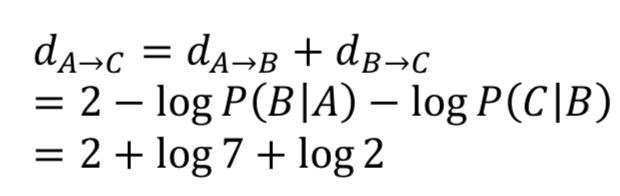
当两点之间存在着多条路径的情况下,我们可以遍历所有路径,并用有效距离最短的一条作为最终的两点间的路径长度,如下面的从A到D的例子:

致谢:
感谢董磊、章彦博、网友乌克里协助数据建模分析,感谢“澎湃新闻美数课”、“nCoV疫情地图“项目组、百度迁徙、丁香园的数据源。
作者:张江
审校:刘培源
编辑:赵千里
推荐视频
2013年Dirk Brockman等人在Science上发表的The Hidden Geometry of Complex, Network-Driven Contagion Phenomena一文就指出疾病的传播其实与城市间的地理距离没啥关系,而与城市间的“等效”距离密切相关。这里的等效距离就是指根据城市间交通流量数据而折合以后的距离。北京师范大学张江老师录制了视频解读这篇论文,供感兴趣的读者参考。
课程链接:https://campus.swarma.org/play/play?id=11116
我们也在针对武汉到全国各大城市之间的流量数据做分析,欢迎感兴趣的朋友参与,详情请见推文《新型冠状病毒通过交通流的传播数据推演(含公开数据集)》。
原标题:《防控力度多大才能遏制疫情发展? 网络动力学推演给你答案》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

