- +1
治道|面对肺炎疫情,政府的数据开放还有很大空间
自武汉新型冠状病毒感染的肺炎疫情爆发以来,国家和地方各级政府部门通过各种渠道发布了许多领导指示、疫情通报、自我防护知识、相关政策通知,这些信息的发布有助于公众获知疫情的发展情况和相关知识,在一定程度上满足了公众的信息需求。
然而,进入了大数据时代,除了以上政府发布的信息,公众可能还想知道一些更具体的数据,比如:所在城市或区县每天有多少确诊和疑似病例,增长情况如何?也想了解一些有关病人基本情况的数据,比如:病人从哪里来,去过哪里,哪天发病的,那些疑似病例后来确诊了没有,如果没确诊,他们得的又是什么病?
虽然我也不断会从网上和身边的朋友那里得到各种各样的小道“消息”,但这些消息是真是假,难以确定。而且这些信息比较零碎,无法让我全面系统地了解疫情的进展情况。我想知道有关疫情的最新的、权威的、准确的官方数据。
一、国家卫健委网站数据
于是,我来到了国家卫生健康委员会的网站,看看这里有没有公开的官方数据。打开国家卫健委的官网后,首先在网页最上方位置看到了“全力做好新型冠状病毒感染的肺炎疫情防控工作”横条。(以下未经特别注明者,均截图于1月23日。)

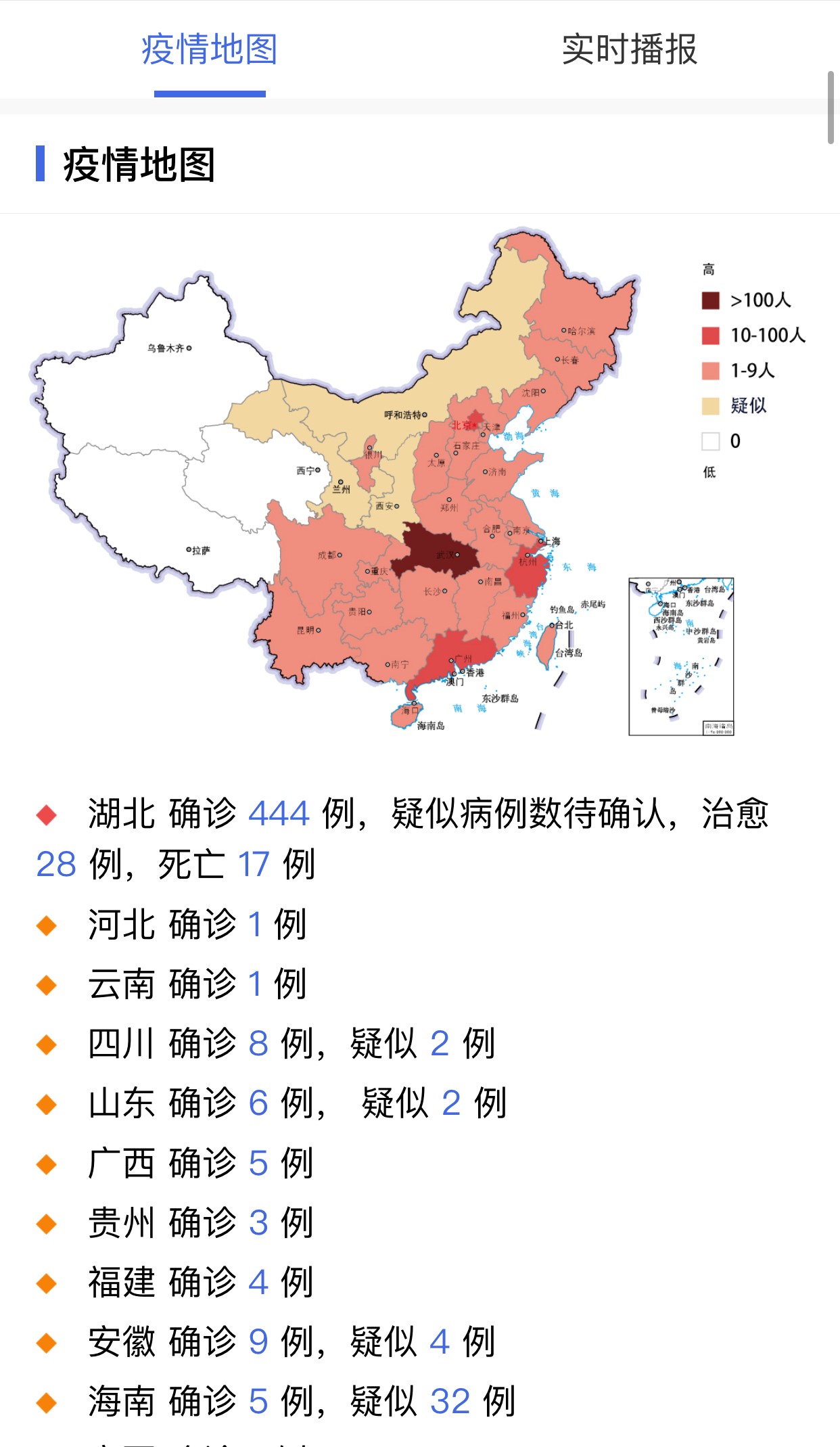
点进横条,可以看到页面最上方是“疫情通报”、“防空动态”两个版块,在“疫情通报”中可以看到国家卫健委发布的各省确诊病例和疑似病例数据。

1月23日这天发布的疫情通报详细列出了17例死亡病例的病情介绍。但是,我如果还想知道其他几百例确诊和疑似病例的情况,就无从得知了。

此外,国家卫健委发布的数据只到了省一级,而没有每个城市或区的数据。于是,我搜到了武汉市卫健委的官网,来看看这里有没有城市一级的数据。
二、武汉市卫健委网站数据
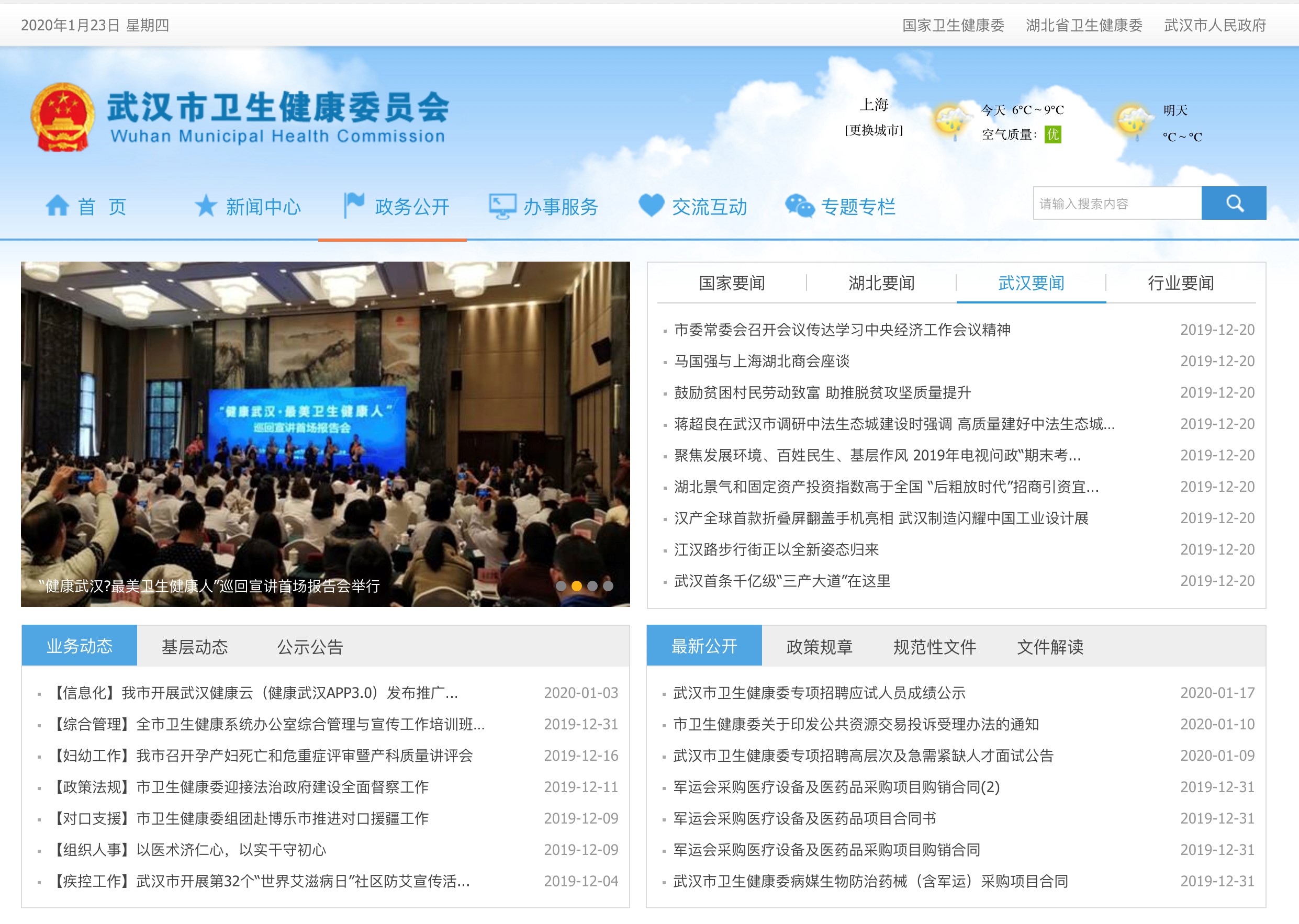
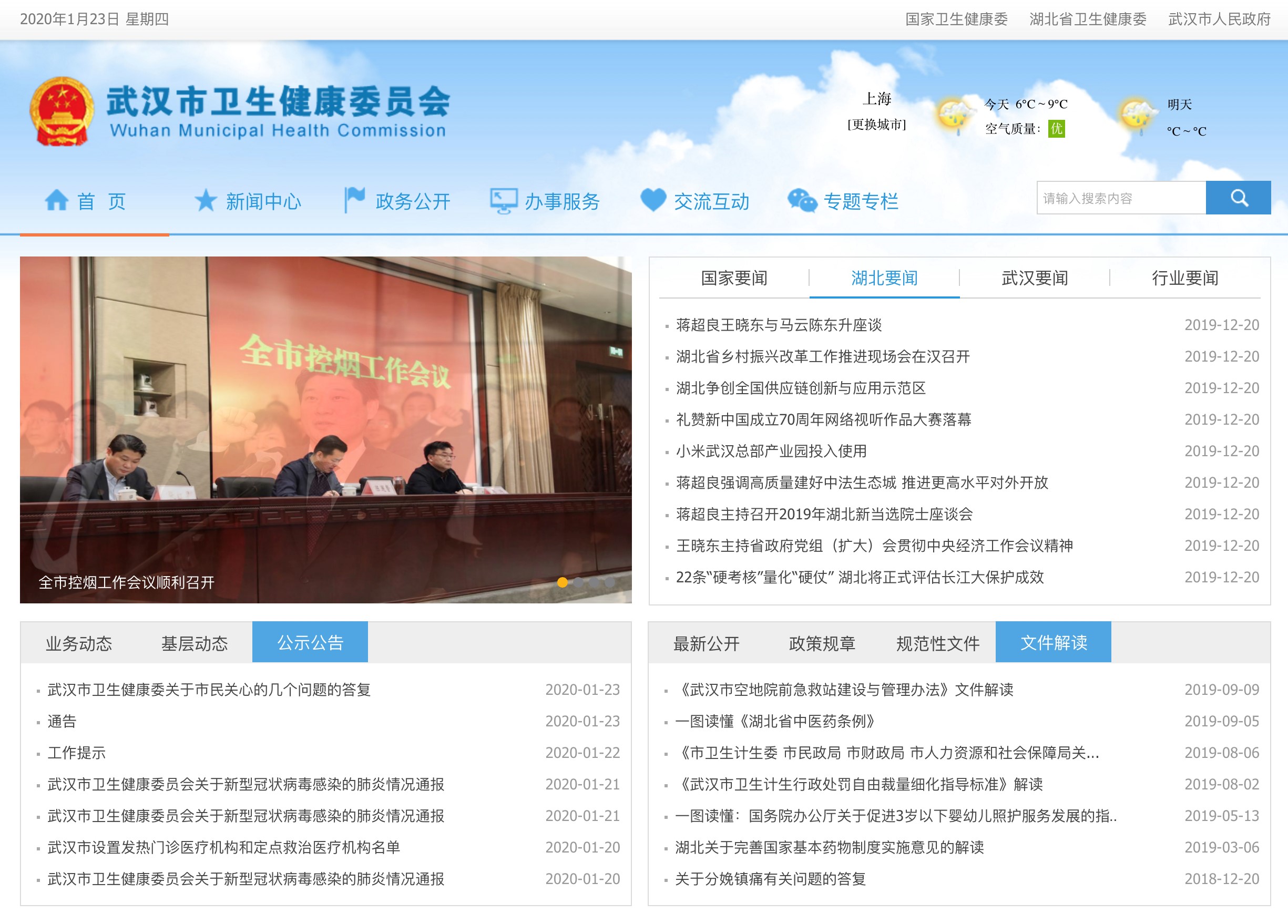


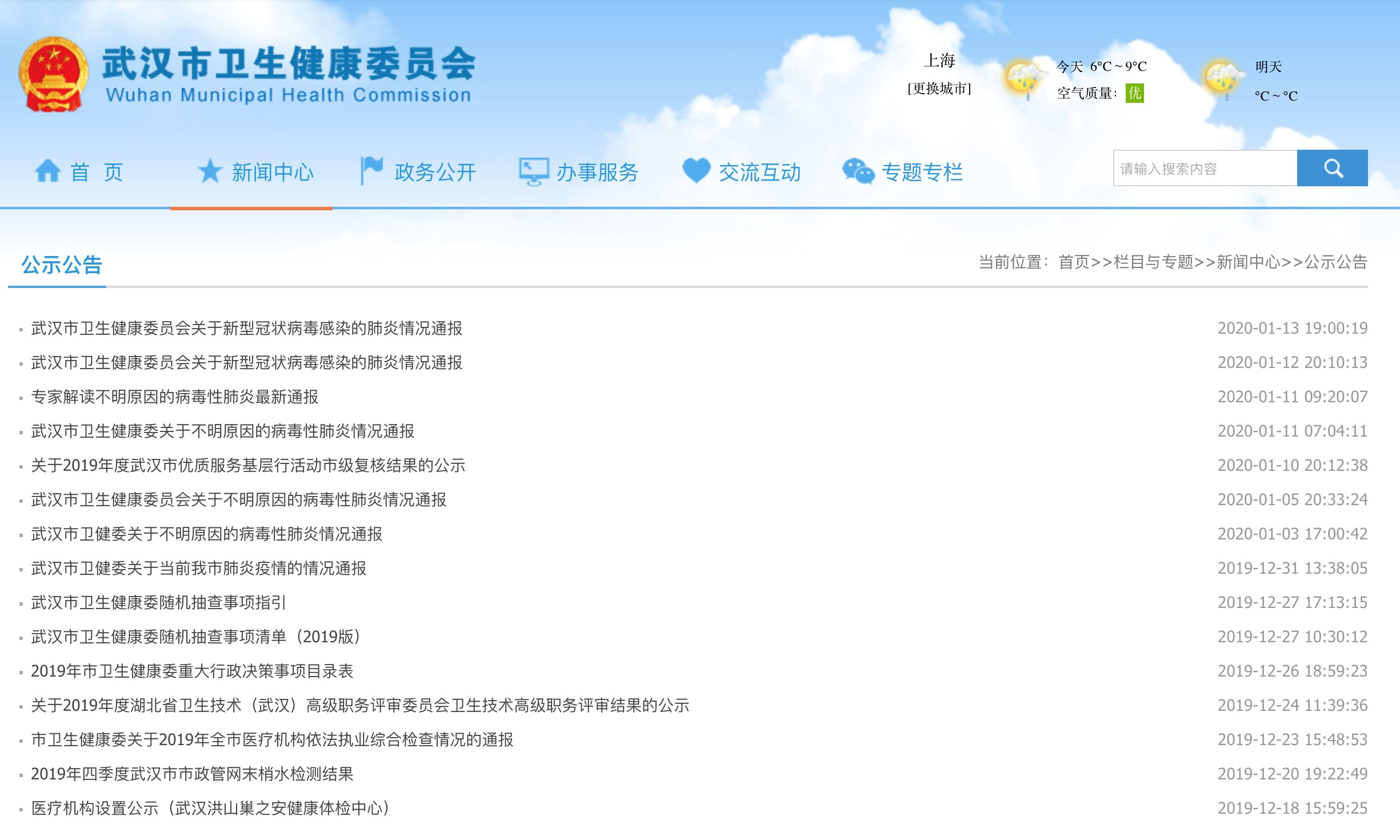
然而,无论在国家、湖北,还是武汉卫健委的网站上,我都没有找到这样一张表格。实际情况是,有关疫情的数据以碎片化的、不连续的、不完整的方式散落在不同的政府网站、页面和文件里。大部分公众不可能有精力和能力去各个政府网站上提取和整理这些数据,其结果是,虽然各级政府认为它们已经发布了这些疫情数据,但老百姓并没有获得感。
武汉市卫健委发布的情况通报中还包括了新增病人的男女人数、病人最小和最大年龄等统计数据。然而,这些数据是对原始数据进行加工和归总形成的结果,并不是一手的原始数据。原始数据可以用来做进一步的深入分析,但统计数据的再利用空间就很小了。
比如,情况通报中公布了新增病例的最小年龄是15岁,最大年龄是88岁,但15岁到88岁这个区间实在是太大了,如果我想知道在15-88岁之间,病人主要集中在哪个年龄段,我和我的家人是否正好属于这个年龄段,仅通过15和88岁这两个统计数据是无法回答我的这些问题的,只有得到经过统计归总前的每一个病人的年龄数据才行。
当然,我并不需要知道每个病人的姓名、住址和电话等个人信息,而只需要得到有关他们的一些基本特征的数据就可以了。这些经过匿名化处理的数据,既能被用来做出有用的分析,又不会侵犯到病人的隐私。
之后,我还在人民日报官方微博上看到过每日发布的“疫情速报”,这些帖子以短平快的方式发布最新疫情。但这些数据仍然是碎片化的,无法帮助我系统全面地了解疫情全貌。

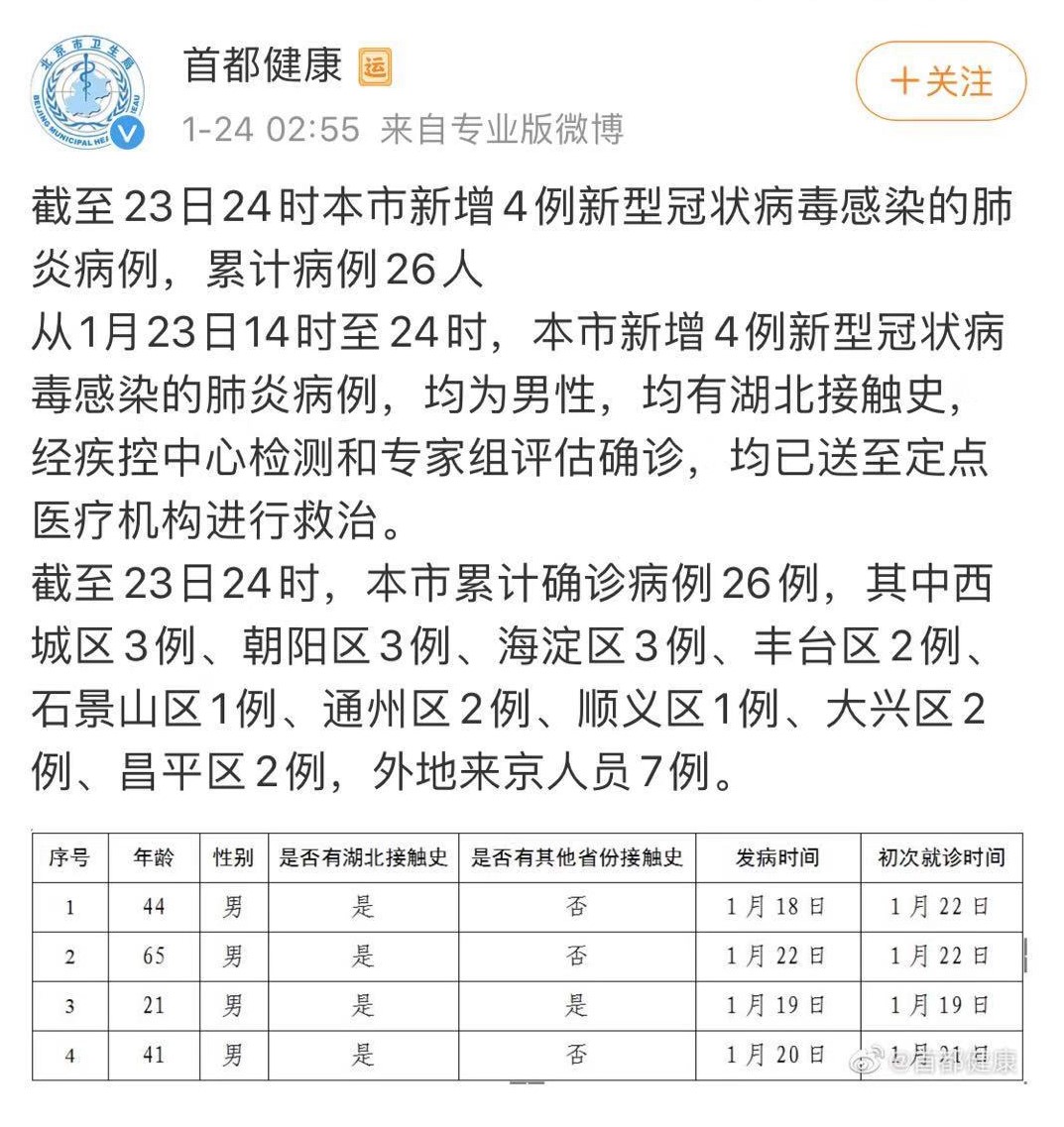
1月24日,我在手机上看到了由医学知识共享网站“丁香园”和澎湃新闻 “美数课”栏目制作的全国疫情数据,这些数据的呈现,相较于政府网站要系统、直观和清晰很多。
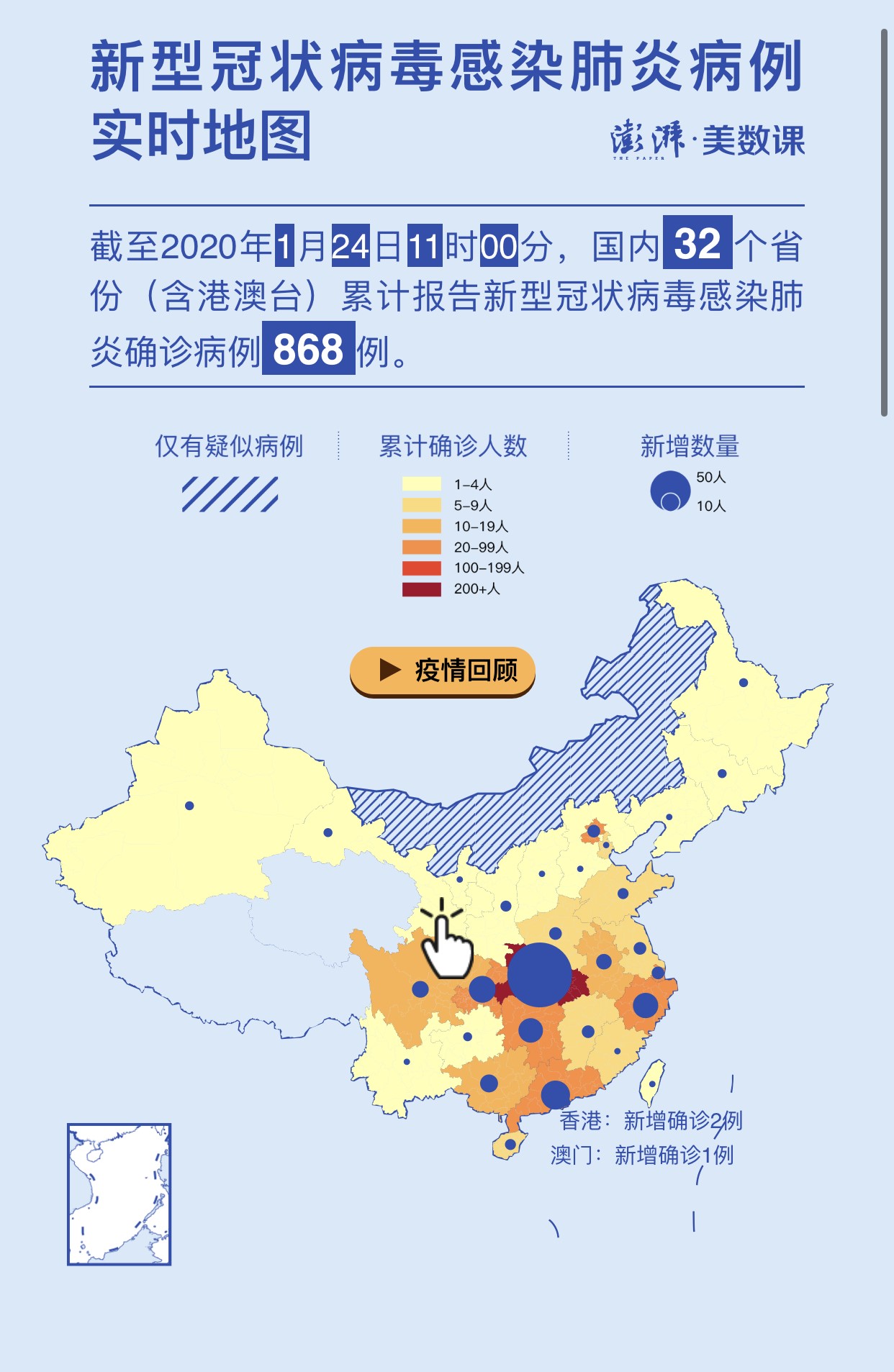

为采集和整理这些数据并进行符合受众需要的制作,这些社会化机构一定花了不少时间和精力。然而,由于政府发布的数据具有碎片化、不完整、颗粒度低等特点,它们的数据展现方式虽然已经非常不错,但在展现内容上仍然无法提供出更全更细的数据。
四、香港特区政府卫生署网站数据
有鉴于此,我来到了香港特别行政区政府卫生署的网站。在这个网站的首页上,我在第一排的显眼位置就看到了“严重新型传染性病源体呼吸系统病”的版块。
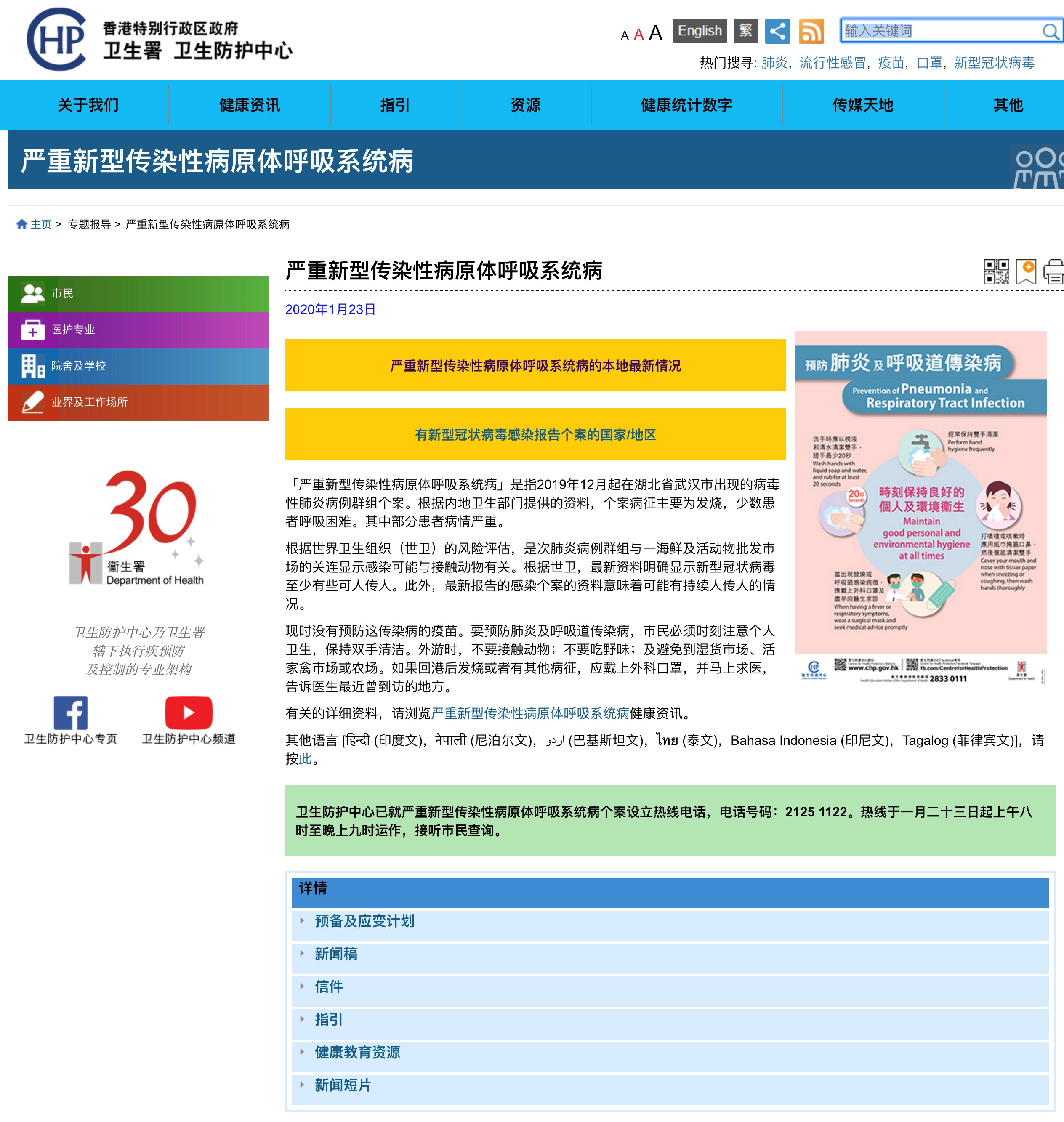
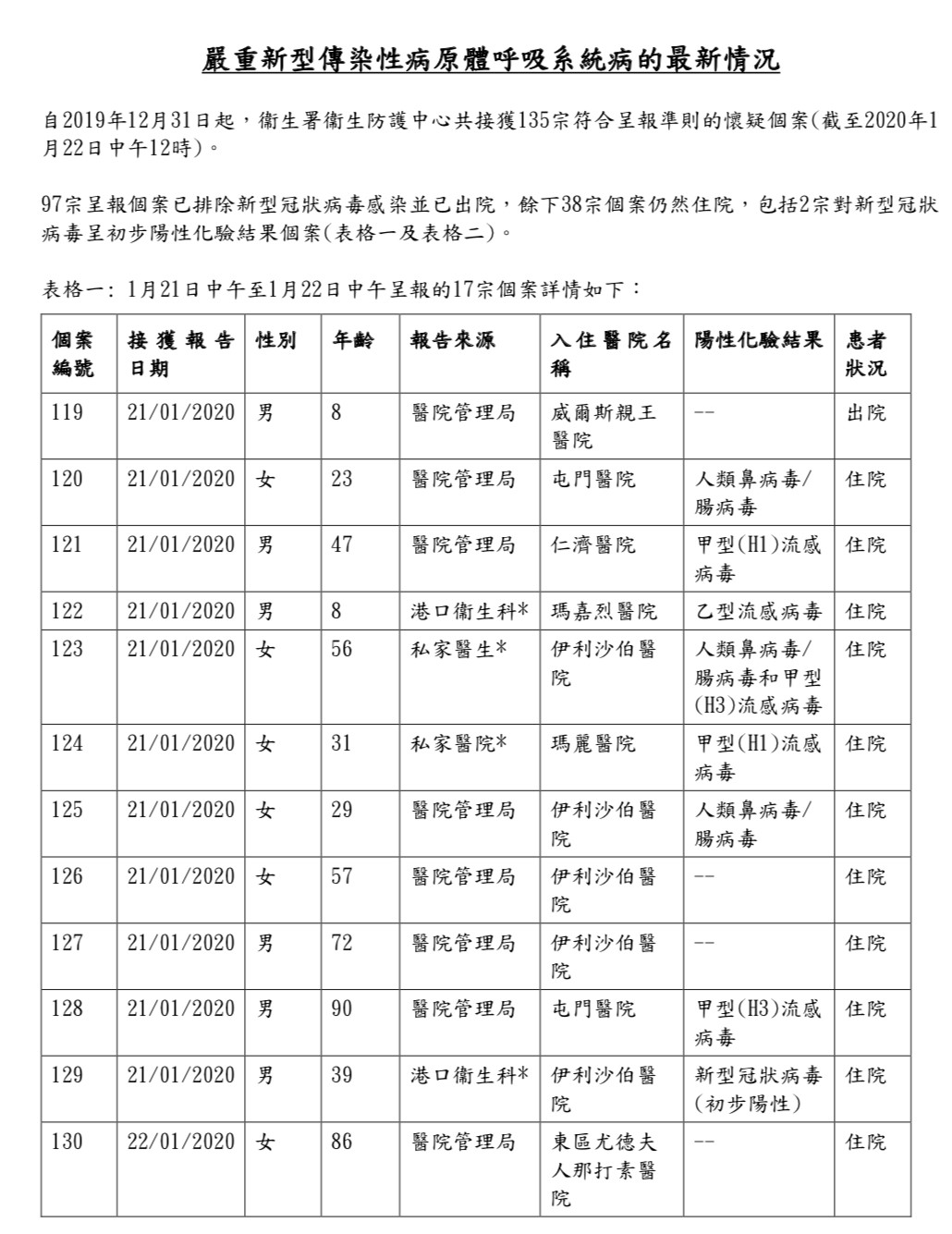
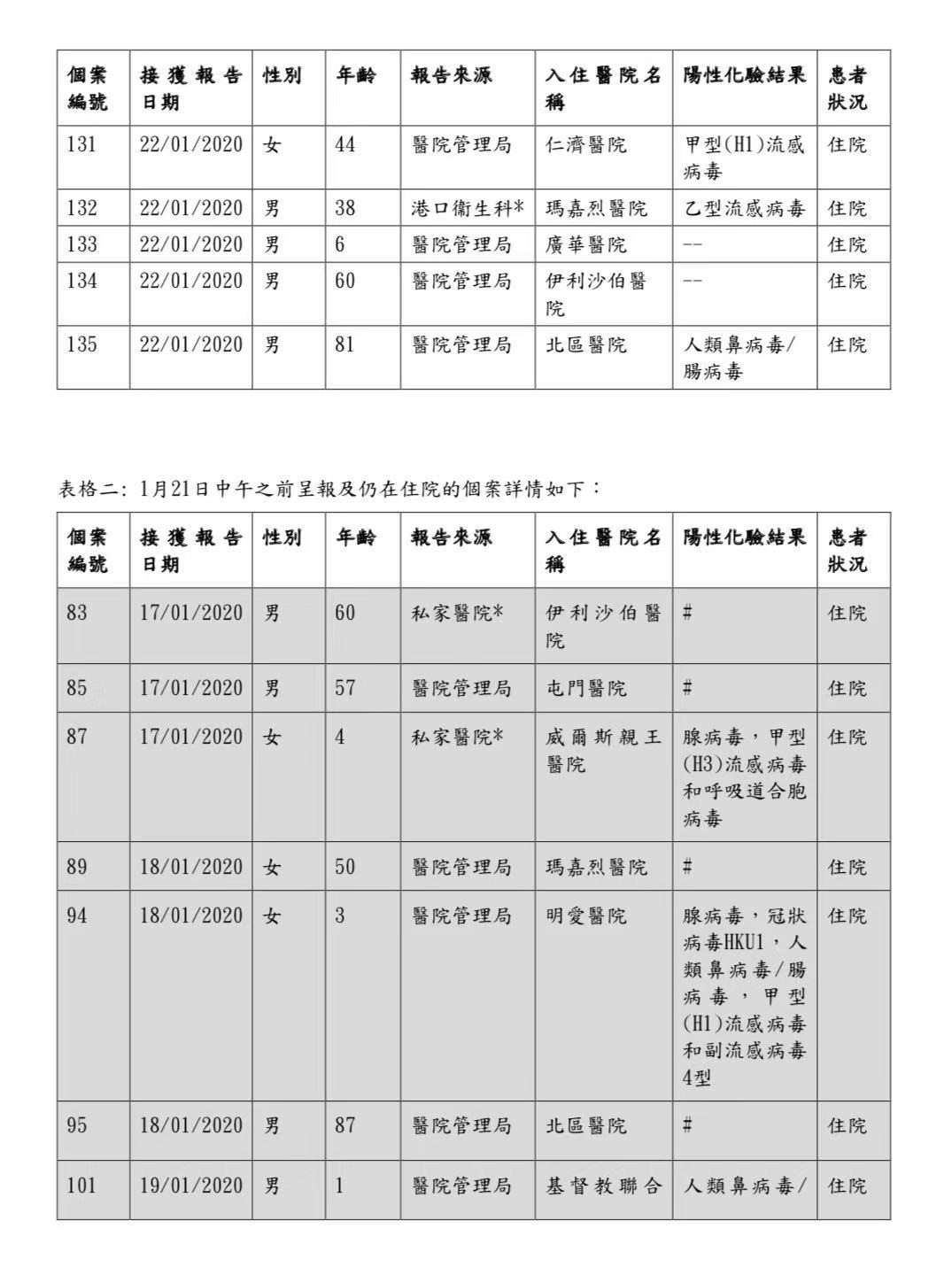
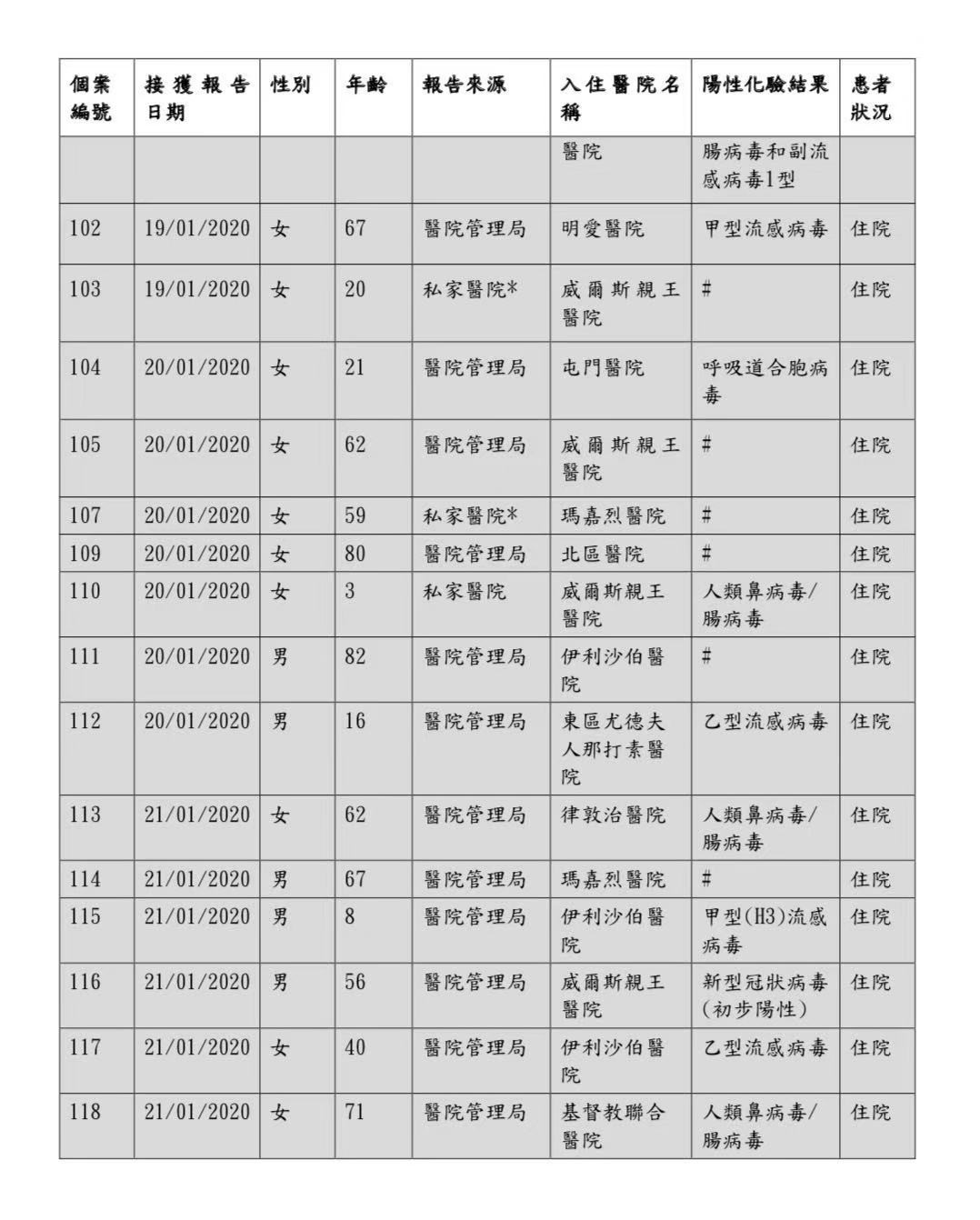

同时,这张表格上还有多个细节值得关注。
首先,在发布病人基本信息的同时,去除了患者的具体姓名,保护了个人信息。
其次,在发布当日新增数据的同时,还在后面列出了之前发布的累计数据,并将当日数据和历史数据用白色和阴影两种颜色区分开来。这样公众就不用再去“爬楼”, 把之前发布的一个个表格下载下来再整合起来了。就这一个贴心的举手之劳,就给用户带来很大的便利。
第三,特别需要关注的一个细节是,在表格之后还附上了“备注”,对数据采集的背景方法和呈现方式进行了详细说明。不要小看这个备注,这能帮助公众更准确地理解和使用表格中的数据,避免误解和误用。
朴素干净的一张表,却填满了细节和温度,体现了背后真正的用户视角和数据思维。
唯一的小遗憾是,这些数据还是以PDF的格式发布的,还需要人工做一下转换处理后才能直接利用。PDF格式便于阅读,不易被修改,但不便机器读取,以进行加工利用。如果能在PDF格式之外,还能提供机器可以读取的excel或csv等格式,就更加便于专业研究者用户进行分析利用了。
五、政府数据开放的基本原则
畅想一下,如果类似“丁香园”这样的社会化机构也能得到这样的疫情数据,它们能开发出来的可视化应用会更全更细,给用户带来更好的体验。而且,它们也不再需要花费大量的时间精力去搜集整理各种碎片化的、不符合标准格式的政府数据,而是可以集中精力将数据可视化应用做得更直观更生动。
在这个过程中,政府作为数据的供给侧把数据开放出来,市场上的专业组织作为数据的利用者把数据开发成各种应用,然后一起为社会公众提供信息服务。政府和市场实际上以数据为原料实现了一种协同治理,便于共同应对疫情。
而这正是数据开放和信息公开的一个重要区别。政府信息公开的主要目标是保障公众的知情权,提高政府透明度,而政府数据开放则不仅要让社会知情,还要让社会能对政府数据进行开发利用,从而释放数据的能量,创造社会和经济价值。
目前,在各国的政府数据开放实践中,开放数据通常呈现为以电子化、结构化、可机读格式开放的数据集。数据集是指由数据组成的集合,通常以表格形式出现,每一列代表一个特定变量,每一行则代表一个样本单位,这样的形式更便于数据利用者进行开发利用。
为推动数据的开放和利用,2007年,一群开放数据倡导者提出了政府数据开放的八项基本原则:
第一,完整(Complete)。除非涉及国家安全、商业机密、个人隐私或其他特别限制,所有的政府数据都应开放,以开放为原则,不开放为例外。
第二,一手(Primary)。开放从源头采集到的一手数据,尽可能保持数据的高颗粒度,而不是开放被修改或加工过的数据。
第三,及时(Timely)。数据尽可能以最快速度发布,以保持数据的价值。
第四,可获取(Accessible)。尽可能地拓宽开放数据的用户范围和利用目的。
第五,可机读(Machine-readable)。对数据进行合理的结构化处理,使之可被计算机自动处理。
第六,非歧视性(Non-discriminatory)。数据对所有人都平等开放,无需登记。
第七,非专属性(Non-proprietary)。数据以非专属格式存在,从而使任何实体都不能独占和排他。
第八,免授权(License-free)。数据不受版权、专利、商标或贸易秘密规则的约束,除非有合理的隐私、安全和特别限制。
目前,该标准已被国际开放数据领域广泛接受。
六、面对疫情的政府数据开放当大有作为
面对疫情,公众只有掌握了充分的信息,才能做出更理性的决定,采取更有利的行动。有量化研究表明,媒体的报道量增加十倍,传染病的感染数将会减少33.5%。在互联网和社交媒体已如此发达的数字社会,公众如果不能及时获得来自政府的权威数据,而只能在网上看到各种真真假假的小道消息,只会增加他们的恐慌感。
因此,让公众在疫情初期就能获得充分的信息,从而加强自我防护,减少出行聚会,有利于政府防控疫情。反之,片面地以避免社会恐慌为出发点,采取“外松内紧”的策略,即政府虽然在内部努力防控,但却没有将疫情信息充分告知社会,会造成公众在不知情的情况下,继续毫无防护地四处游走,最终反而助长疫情的传播。
进入大数据时代,社会公众的信息需求也发生了变化。面对疫情,公众想知道的不仅仅是自我防护知识、官方疫情通报、相关政策通知,还想获得权威的、完整的、一手的、准确的、及时的数据。显然,目前各级政府相关部门在各个渠道上发布的碎片化的、不连续的、不完整的数据,还不能满足公众的数据需求。
传统的信息公开主要以非结构化的、文本的形式提供,而在大数据时代,公众希望能获得结构化的、可机读的数据,便于其理解和加工利用。政府数据开放由此走上前台,将开放的对象推进到了信息的底层——数据层。
而且,防控疫情也不能只靠政府一方来孤军奋战,还需要整个社会的充分参与。政府将自己掌握的疫情数据作为一种基本的原料开放给社会,然后社会力量可以将这些数据开发成各种应用,更好地满足公众的数据需求。最终,政府和社会之间可以实现协同治理,控制疫情,让广大民众受惠于大数据带来的便利。
近年来,我国中央和地方层面已出台了多项有关公共数据开放的政策法规。2017年2月,中央全面深化改革领导小组第三十二次审议通过了《关于推进公共信息资源开放的若干意见》,要求推进公共信息资源开放,促进信息惠民,着力推进重点领域公共信息资源开放,释放经济价值和社会效应。2018年1月,中央网信办等多部委联合印发了《公共信息资源开放试点工作方案》,确定在北京、上海、浙江、福建、贵州开展公共信息资源开放试点,并要求试点地区着力提高开放数据质量、促进社会化利用,探索建立制度规范。
2019年8月,上海市政府第61次常务会议审议通过了我国第一部专门针对公共数据开放的地方政府规章《上海市公共数据开放暂行办法》。该办法要求上海市各级公共管理和服务机构向社会提供具备原始性、可机器读取、可供社会化再利用的公共数据集。
近年来,我国的政府数据开放工作也正在稳步推进。根据复旦大学数字与移动治理实验室近期发布的《中国地方政府数据开放报告(2019年下半年)》,自上海市于2012年6月上线了我国第一个地方政府数据开放平台后,截至2019年下半年,我国内地已有102个地级以上的地方政府推出了数据开放平台,国家公共数据开放平台也将于近期上线。
然而,当前的政府数据开放仍然面临着很多挑战和难点问题。例如,政府数据开放,在字段和颗粒度上做到多细才合适?怎样开放数据才能既满足公众知情权,有利于社会对数据进行开发利用,又能维护社会安定和个人隐私?怎样防止数据在开放后被人滥用,以保护公共利益和第三方利益?如何才能在数据开放利用全过程的事前、事中、事后各个阶段既促进数据利用,又加强安全防护?如何面向不同人群,针对不同类型的数据,以不同的方式分级分类地开放?这些问题都还需要各地各级政府进一步探索和研究。
无论如何,面对疫情,政府数据开放还有很大空间可以作为。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

