- +1
全世界网友如何表达“笑”
服老思和同学们 P话

笑声好像很复杂,即使在现实生活中,似乎也很难分辨出人们的笑背后到底是真心还是假意;放到网上,隔着屏幕,要辨别“笑”背后的情感似乎就更加困难了。“哈哈哈”背后,到底是真的开心,还是在缓解无话可说的尴尬?各类网络用语和热搜词汇层出不穷,还有各类表情包的加持,我们有了更多表达“笑”的形式。于是,有个 The pudding 出品的这个有关“笑”的数据报道。报道由三部分组成,分别从从表达“笑”的语言用法、演变和感知三个方面进行了研究。在你看来,是用“rofl”还是“haha”还是“lolol”表达的开心程度高呢?出品团队使用了 BigQuery 作为主要的数据分析工具,对来自于 Reddit 的 2019 年 1 月到 2019 年 6 月共 7 亿条评论进行文本分析。2019 年上半年最常用来表达“笑”的方式是什么呢?“lol"荣登榜首��

Dai Yi Wan | 戴怡宛
2020 年戛纳国际创意节中国台湾代表队选拔赛选手,利用 AI 做了一个名叫戴怡宛的女孩子,她的所有特征都来自台湾:用 10000 张台湾人的脸做出一个台湾女孩,硕士论文是写儒家文化在政府中的影响等。制作团队甚至为她做了个人履历表、网站并注册了 Linkedin 的账号。她能在向往的国际 NGO 组织找到工作吗?

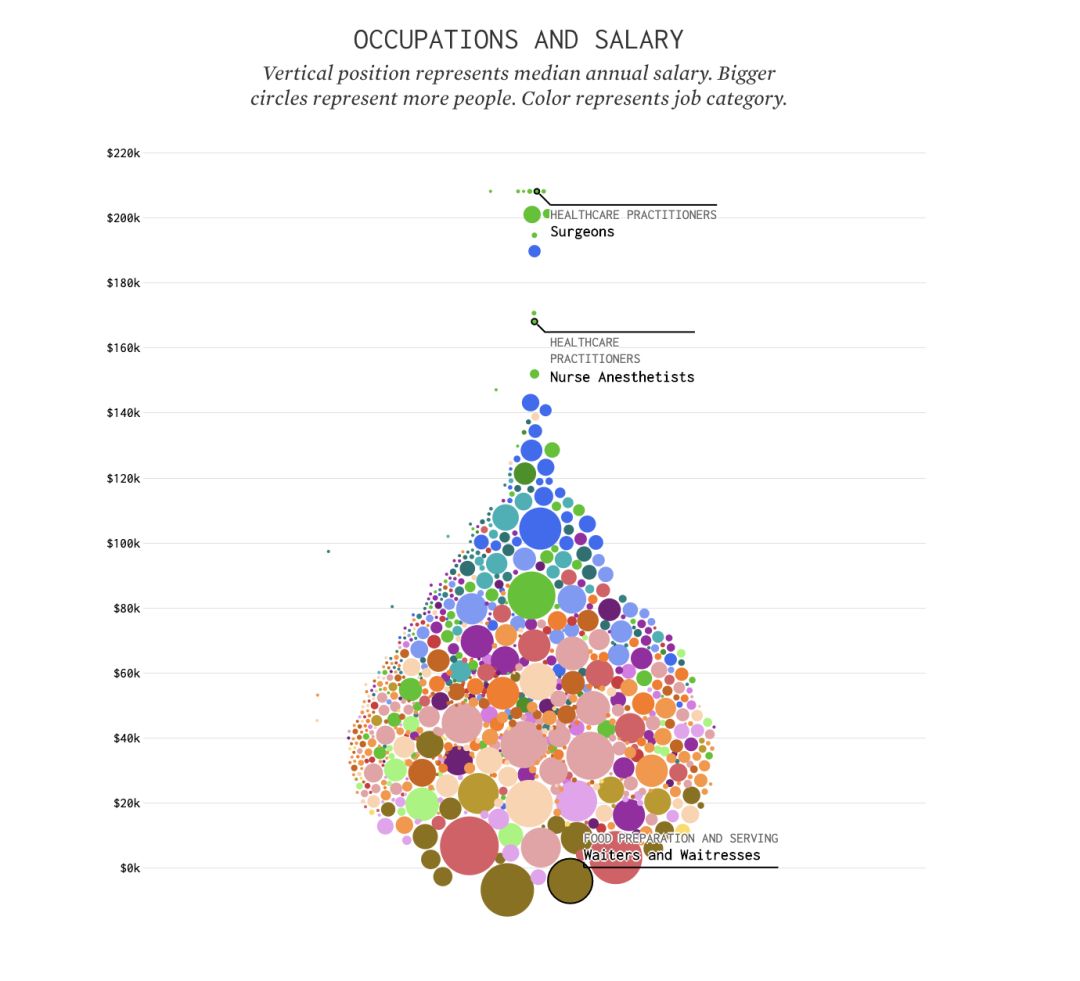
收入和职业
世界上什么哪个职业的工资比较高?哪个职业从事的人数比较多?快来看看你的职业怎么样吧。图表中的每个圆圈代表一个职业,圆圈在纵向位置的高低代表不同职业的年薪中位数,圆圈的大小代表从事职业的人数,不同颜色代表不同的职业种类。整个图表的形状上窄下宽,果然只有少部分人站在社会森林法则的最顶端啊
。
Magi
你知道最近火爆中文互联网世界的 Magi 吗? Magi是什么?来看看官方解释��:
从前的日色变得慢,车,马,邮件都慢,一生只够爱一个人Magi 是由 Peak Labs 研发的基于机器学习的信息抽取和检索系统,它能将任何领域的自然语言文本中的知识提取成结构化的数据,通过终身学习持续聚合和纠错,进而为人类用户和其他人工智能提供可解析、可检索、可溯源的知识体系。
“Peak Labs”公司近日发布了其人工智能系统 Magi 的公众版“ magi.com ”。通过这一搜索引擎,用户输入关键词,即可获取 Magi 从互联网文本中自主学习到的结构化知识和网页搜索结果,每个结构化结果后面都会附上来源链接和其可信度评分。“ magi.com ”上线即掀起了不小的浪头,上线第一周,0 投放达到 100 万用户周活,登上国内第七大搜索引擎的位置,连开发团队 Peak Labs 都未曾预料它会如此火爆。

关于活跃粉丝,新浪和DT财经互掐了一把
DT 数说最近做了一项有关明星粉丝的数据报道,重点分析了粉丝超千万的全部 317 位明星以及入选微博超话榜的流量担当们,利用微博推广功能提供的“可投粉丝”来指代活跃粉丝,计算活跃粉丝占比来评估明星微博粉丝的含水量,探究哪些明星的微博粉丝含水量高,含水量高低有什么规律,并根据粉丝数和活粉率把超话榜明星分成了四大象限:高粉丝数低活粉率、高粉丝数高活粉率、低粉丝数高活粉率、低粉丝数低活粉率。
之后,“新浪微营销” 发布声明质疑文章中“用‘可投粉丝’来指代活跃粉丝”的统计方式并未与官方核实,缺乏事实依据,由此推算出的“活跃粉丝占比”、“含水量”等数据严重失实,给公众带来了误导。��

相关链接:317位顶级明星PK,谁的微博粉丝注水最严重?
新浪微营销相关声明
山西人最喜欢追星?从数据看明星粉丝的地域构成:https://zhuanlan.zhihu.com/p/58661739
谁是最复杂的小说
一个波兰物理学家团队在 2016 年的《Information Sciences》杂志上,发表了一篇名为《量化叙事文本中长期关联的来源和特征》的论文。他们选取了世界范围内的一百多部文学作品进行了文本复杂度分析,探究在叙事文本中是否可以找到有效的与复杂度相关的度量指标,可以用来评判一部叙事文本的优劣程度。研究者们提取了两个指标作为评判一部作品叙事复杂度标准:长程相关性与多重分形复杂度。发现最复杂的小说是著名意识流作家乔伊斯的《芬尼根的守夜灵》 。不过小编表示,和这篇论文相比,这些小说也不算复杂了…… 后附一篇论文的中文摘要,邀请大家一起来烧脑。

中文摘要:谁是最“复杂”的小说:文学叙事中的长程关联与多重分形
活动
—
联合国世界数据论坛征稿启动
第三届联合国世界数据论坛将于 2020 年 10 月 18 日至 10 月 21 日由瑞士联邦统计局主办。联合国世界数据论坛旨在加强各团体(如信息技术,地理空间信息管理者,数据科学家和用户以及民间社会组织)之间的合作。本届论坛旨在举办会议,讨论如何采用创新的数据和统计方法以解决公众关心的问题。这又将是一个大神云集的论坛,也是一个了解交流世界数据前沿动向的好机会。日前,论坛的征稿活动启动,投稿开放时间为 2019 年 12 月 2 日到 2020 年 1 月 31 日。

https://unstats.un.org/unsd/undataforum/call-for-session-proposals-for-united-nations-world-data-forum-2020/
CREDIT
—
爆料人:@ Ingrid @ 包小包 @ 服老思
编辑:@ 包小包
排版:@ 包小包
就是这个人还没点在看
原标题:《全世界网友如何表达“笑”》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

