- +1
澎湃下午茶︱唐世平:决策的未来,不只是大数据和AI
对于所有决策者来说,其面临的挑战主要有两重,一是信息的缺乏,二是信息处理能力的缺乏。当前社会中所提倡的大数据及人工智能技术都在逐渐减少上述两方面的困难程度,但却无法将两方面充分结合。
8月9日下午,澎湃研究所邀请复旦大学国际关系与公共事务学院教授唐世平作客澎湃大楼,与在座的媒体人和学者等共同探讨,决策究竟需要依赖怎样的数据。

唐世平提出,计算社会科学提倡根据实际决策面临的问题来收集合适的数据,恰好可以填补当前信息及信息处理能力上的不足。

计算社会科学最大的优点在于降低了决策者在决策过程中对专家的依赖。唐世平认为,传统的决策科学过分依赖领域内专家的预测,但事实上,专家的判断也出自于对以往人类社会行为的数据分析,而这一过程在未来有希望被计算社会科学的技术所替代。
什么样的数据才是计算社会科学所需要的数据?针对这一问题,唐世平介绍了“全数据”的概念。目前流行的大数据因为采集范围过于宽泛,对于决策的帮助并不明显。如果了解决策需求,那么只需根据社会科学的研究理论收集与问题相关的数据就足够了,接下来的步骤就是模拟决策过程,从而推算出某个决策可能出现的概率或是某种决策可能引出的结果。
以预测美国某一个州总统大选的投票结果为例,唐世平解释了这一推算过程。预测投票结果除了需要输入基础投票规则和有关选举的社科研究成果外,还需要包括该州的人口数据、社交网络分析以及地理信息数据等基础数据。
而模拟的过程就是将州内的每个选民化作一个数据点,利用基础数据赋予每个选民自己的特性,然后通过计算机重复模拟投票过程,直到最终的投票结果稳定在一定区间,而这一区间即为该州对于大选投票的可能区间。整个预测所需的“全数据”包括宏观、中观和微观三个层面的50余项相关数据。
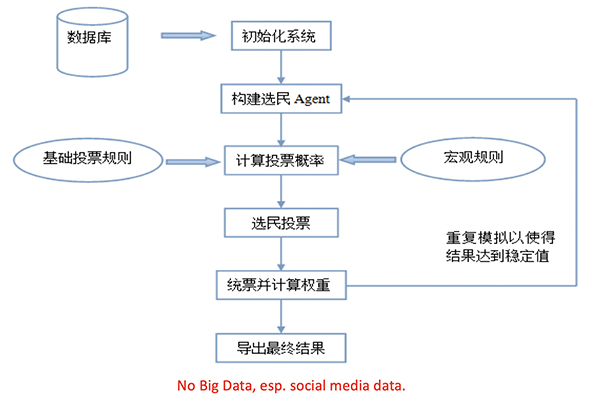

这种模拟过程的优势在于,能够剔除民调和社交媒体中存在的大量虚假信息对选举结果预测的影响,从而更加精准地预判选区的投票倾向。简单来说,只要收集到对应的“全数据”,此类技术便可被应用于预测任何社会事件的结果,从而提高决策者的效率,增加决策的合理性。
唐世平指出,这类技术与我们生活的方方面面都息息相关。人们在社会日常生活中都会面临大大小小的决策难题,大到购置房产,小到旅游出行。当决策需求变得明确,通过计算机对“全数据”进行模拟,未来人们很有可能从“选择困难症”中“痊愈”,生活将会因此变得更加高效。
在互动环节,唐世平还表示,当前社会科学研究面临的一个较大约束就是数据收集的成本问题,因此数据的开放程度越高也就越有利于社会科学的研究。然而,从现实角度看,一个“放之四海而皆准的数据平台”是不存在的。关于上海可以开放哪些数据的提问,唐世平认为四类数据是必须的:社会安全问题问题、城市发展规划数据、推动经济发展与产业升级的数据,以及紧急响应机制的数据。

--------
“澎湃下午茶”是澎湃研究所主办的线下分享会,旨在与中国智库领军人物以及城市管理者一起“聊决策,看上海”。分享会每两周举办一次,并向社会公众开放固定数量名额。往期活动简报、未来活动预告及报名,敬请关注澎湃研究所微信公众号(ppyjs1905)。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

