- +1
“9.11比9.9大”,Grok3还不如小学生?“最聪明的AI”翻车


AI大模型的数字陷阱,连Grok-3都翻车
科技旋涡作者|贾桂鹏
日前,马斯克与xAI团队,在直播中正式发布了最新版本Grok3。
此前,马斯克将Grok-3描述为“地球上最聪明的AI”。他在X平台上表示:“自己整个周末都在和团队打磨产品。”

不过,据媒体报道,有人测试了最新的Beta版Grok3,并提出了那个经典的用来刁难大模型的问题:“9.11与9.9哪个大?”遗憾的是,在不加任何定语以及标注的情况下,号称目前最聪明的Grok3,仍然无法正确回答这个问题。
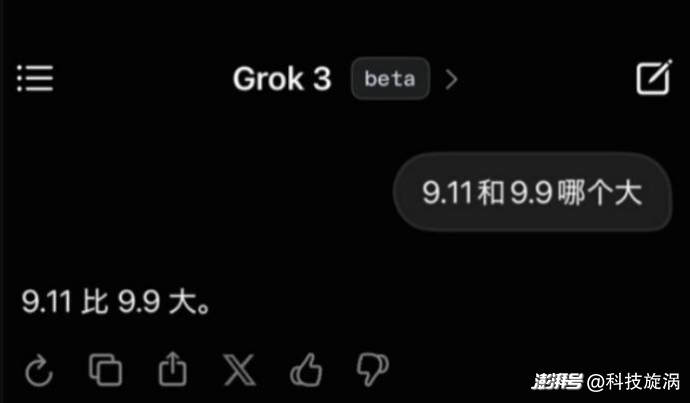
难道马斯克口中“地球上最聪明的AI”就给出了这种答案吗?Grok3到底行不行?
9.11和9.9哪个大这个看似很简单的问题为什么Grok3会出现错误呢?其实,大模型在处理“9.11”时,可能会将其拆分为“9”、“11”两个部分。由于小数点后的“11”大于“9”,这导致了错误地判断。
而且,在某些情况下,如日期或章节编号,9.11确实比9.9大。例如,“9月11日”比“9月9日”晚,“第9章第11节”也比“第9章第9节”晚。大模型可能在学习过程中积累了这些badcase,从而产生了错误的判断。
还有,在分析大模型的底层注意力机制时,我们发现大模型对小数点后的“11”和“9”更为关注。这可能是导致错误的原因之一。然而,当我们排除这些明显的可能性时,问题可能出在位置编码或大模型更底层的推理逻辑上。
因此,不仅是Grok3,包括ChatGPT在内的很多大模型都在这个问题上跌了跟头。
值得一提的是,用同样的问题询问DeepSeek时,无论是否开启深度思考(R1)模式,对方都给出了正确的答案:9.9大于9.11。

而且,除了这个数字问题外,在xAI发布会直播中,在分析游戏《流放之路 2》的职业与升华效果时,Grok 3也给出了大量错误答案,并且马斯克也没有看出这些明显的错误。
尽管在官方PPT中,Grok3在大模型竞技场Chatbot Arena中看似“遥遥领先”,但实际上其与DeepSeek R1和GPT4.0的差距仅为1%到2%。
不过,对此这个问题马斯克并不以为然,其公开回应称,当前的Grok 3仅是测试版,这个阶段错误越多越好,而完整版将在未来几个月推出,并邀请用户反馈使用问题。
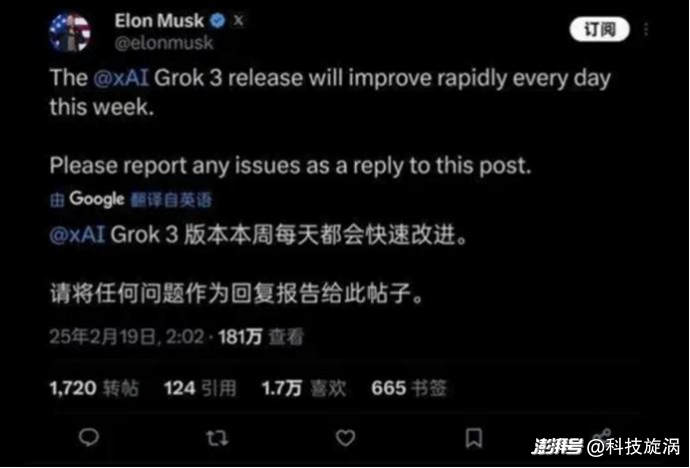
另外,此外,马斯克在直播中透露,未来,最快一周后Grok应用程序将具备“语音模式”,这将为Grok模型提供合成语音。几个月后,xAI将开源上一代模型Grok 2。“我们的一般做法是,当下一个版本完全推出时,我们将开源上一个版本(Grok)。”
马斯克曾多次警告说,人工智能会给人类文明带来风险,但他仍在极力推动加大对这一领域的投资。
我们从本次发布的Grok 3里面,可以看出来,马斯克还是押注大算力AI,Grok 3无论在训练集群规模、用电量上都是首屈一指的,这也在一定程度上转化为了Grok 3在多个基准测试上的SOTA表现。不过,马斯克这次押注能不能成功,我们还要接下来继续看AI的发展。
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。









- 今年以来最大地震
- 中国地震局迅速启动地震应急响应
- 曼谷进入紧急状态,高楼倒塌致3死
- 国内商品期货夜盘开盘,沪锡涨超2%
- 建行副行长:今年以来房贷受理量、投放量延续良好势头
- 上海一个具有65年历史的国际音乐节,2025年3月23日第40届开幕
- 被美誉为“孤篇盖全唐”,由诗人张若虚所写的著名诗篇


- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2025 上海东方报业有限公司

