- +1
OpenAl宕机,并非算力不够,而是……
原创 亲爱的数据 亲爱的数据
原创:亲爱的数据
泼天的流量,
说来就来。
Sora刚公布,热度贼高,
原本有固定数量的 GPU 用于服务现有的模型任务,
结果需要紧急拉更多的GPU去服务Sora,
有员工在推特上的说法是,
configration change(配置更改),
也有的网友说是负载均衡出了问题。
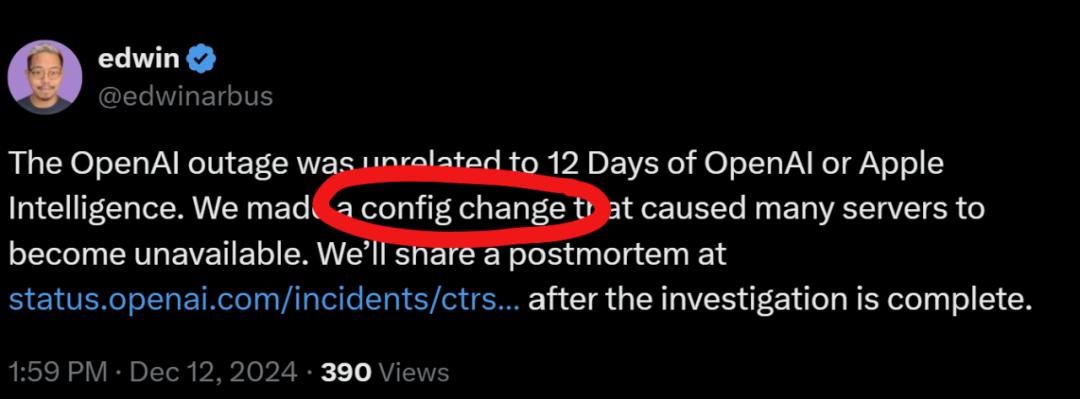

OpenAl宕机当时,
巧了,我正在美国湾区一家AI科技公司访问,
大家立刻“围炉”讨论了一把。
湾区就是这样,
到处都是志同道合,
对AI求知若渴的小伙伴。
我们的结论是:
“OpenAl用户宕机,与其说算力不够,
不如说没有找到控制推理成本的有效方法。“
OpenAl的教训,
是所有人的教训。
既然是开门做生意,
先看钱,
钱是如何花的,
钱是如何赚的,
又是如何省的。
总而言之,你要把AI芯片用好,
以此来争取节约AI芯片的巨大成本,
我不得不说一句,
省下的就是赚到的。
01
钱如何花?

微软是OpenAI大金主,
猛猛给OpenAI钱花,
这图描述了2024年6月,
OpenAI用微软云
做大语言模型推理,
GPU资源分配情况:
最多60000 台 GPU ,
最少 4700 台 GPU ,
一部分是OpenAI 租赁并正在使用的 GPU。
OpenAI也留了一部分 GPU ,
万一有突发需求(如流量高峰),
可以用备用GPU拯救宕机。
再次强调,
这些 GPU是专门用于推理任务,
而不是训练用,不是训练用,不是训练用。
(重要的事情说三遍)
OpenAI大模型这个生意,
需要在推理性能和成本之间找到平衡点。
到底啥是推理?
我的理解是,用户有所求,模型有所应。
回答得快慢好坏,
用户都有一个很直观感受。
只要你慢,
用户一用得不爽,拔腿就跑。
那你的用户留存指标就完蛋了。
02
钱如何赚?
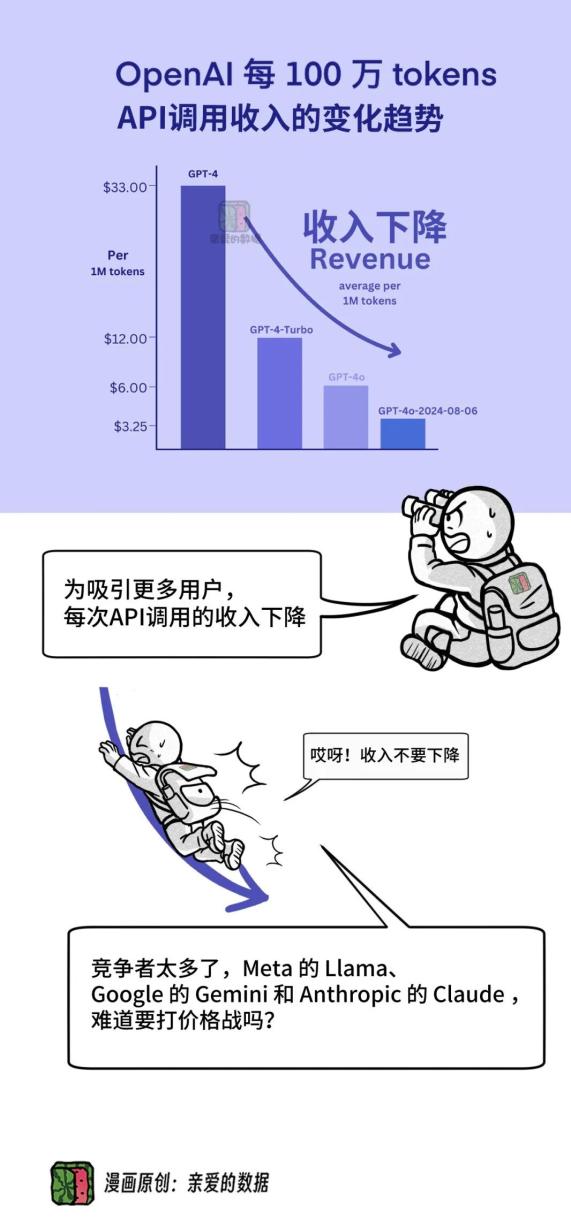
所谓推理成本,
就是运行大语言模型生成输出时要花的钱。
这里就不得不提API经济学了。
把输入和输出的Token算在一起,
通常以每100万token为单位计费。
除了算力费用,
还有基础软件与运维费用,
当然,还得加上电费。
OpenAI 调(直)整(接)定(降)价(价),
没办法,为了市场竞争,
扩大用户群体和市场占有率,
需要降低每 100 万tokens的费用。
03
钱如何省的?
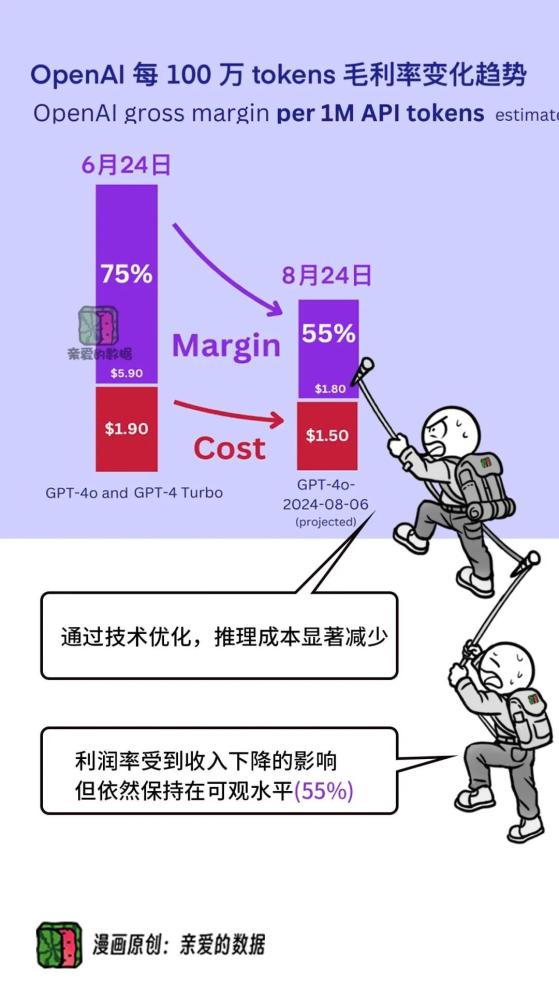
看看图也知道,
OpenAI他们每代模型都在减少推理成本,
这背后一定是很重视推理技术改进。
从2024年6月到8月,
每百万词元的推理成本,‘
从大约从人民币14块(1.9美元),
降到11块(1.5美元)。
降了约3块。
不仅OpenAI在降成本,
人人都想降推理成本,
当然,确实有人还不重视这件事,
可能还在头疼其他事情,
可能应用的用量还不大。
大佬们当然牛逼一点,
早都先人一步,
干得热火朝天,
贾扬清LeptonAI团队在优化GPU推理,
美国斯坦福大学教授的TogatherAI也在优化GPU推理。
OpenAI也得使出全身力气,
推理做得好,
省下的都是赚到的
OpenAI再豪横,
也会在推理上下功夫“省钱”。
Sora所需算力非常大,
存也大,算也大。
虽然生成视频的推理和文生成字的推理不同,
但本质一样。
推理这件事,
想做得好,
“足够快”和“用得足够多”这两件事都得要。
没办法,推理就是一件很商业化的事情,
和钱直接相关。
大家都挖苦大模型公司太亏钱,
初创时期亏钱很正常,
就看后面能不能赚钱,
但是,“用的人多”不是决定赚钱的唯一因素,
核心是当“用的人多”的时候,
你的推理成本是否足够低,
为什么呢?
这里有个大模型赚钱公式
赚到的钱=卖大模型总价格-推理成本。
“省下的钱,就是赚到的钱”,
这句话的含金量还在上升。

04
赔本赚吆喝?
能不能打个比方,
就让大家对推理这件事过目难忘。
那就这样:推理芯片是口锅,推理就是用锅炒米饭,
这里面有两个维度。
我们既想追求单次推理时间越短(出锅快),
又想追求单位时间内可以处理更多请求(很多份饭一起做),
这就是AI推理的矛盾点:
如何让大模型既能快速响应,
又能同时服务更多用户。
很多大模型厂商都买了很多锅,
如果做出来的饭不好吃,
没有人买,
那就等着亏钱吧。
第一口锅:3秒炒好1碗饭,
但厨房只能用这锅一次炒一碗饭。
虽然单次很快,但只能服务一个人,吞吐量较低。
第二口锅:30秒能一次炒好128碗饭,
尽管厨房出锅一次的耗时长了一些,
但它可以同时服务很多人(吞吐量很高)。
推理的难度在于,
这两种出锅能力都要有,
典型的“既要又要”。
大模型公司狂撒几亿元广告费,
就是期望潜在的来吃饭的人多,
来吃饭的人多了,你得有机器人厨房的服务能力。
不能第一个人来吃饭,彻底吃完了,
第二个人才能走进餐厅,坐下吃饭。
一个接一个的排队用餐模式根本不可能,
需要芯片一口气服务很多人,也就是很多人一起用餐。
推理技术不好,
甚至可能来的人越多,赔得越多。
本质就是推理芯片用得好不好。
那如何提高推理效率?
05
芯片制程
第一个答案,提高芯片制程。
也就是提高半导体制造工艺的技术水平,
别人14nm,你7nm,
同样的单位面积的芯片,
你晶体管多,你就赢了。
芯片制程工艺确实在不断提升。
准确来说,
因为晶体管数量的增加使得更多计算单元,
能够被集成到芯片中。
这直接带来了推理芯片更高的算力密度。
此外,制程的缩小通常伴随着功耗降低和效率提升,
这意味着在相同的功耗预算下,
可以实现更高的性能。
因此,制程工艺的进步不仅在晶体管密度上占优,
也为推理芯片的性能和能效带来了显著的提升,
从而在竞争中取得优势。
这点上,因为众所周知的原因,
我们被限制了。
此处,按下不表。
06
软硬配合
第二个答案,提高软硬件配合度。
如何通过软件优化来最大化利用芯片的硬件资源。
因此相关的软件(称为基础软件或系统软件)
需要为芯片提供强有力的支撑。
这件事很难,
基础软件,俗称AI Infra,难度很高,
人才培养很难。
而软硬件配合这点又需要分成两部分来讨论,
其一,软硬件配合包括模型结构与芯片架构适配。
根据芯片架构的特性,
对模型进行调整,
使得模型计算的时候能利用好芯片的硬件特性,
例如,将计算任务分解为适合GPU并行处理的小批量操作,
最大化计算单元的利用效率。
其二,软硬件配合包括选择合适的批次大小。
批次大小这点也对模型的推理效率至关重要。
批次是什么?
就是能处理的用户数量(请求数量)。
我们要做的就是,让批次大小与模型适配。
简单讲,一方面,
如果你把一大堆东西(较大批次)一下子送进模型,
可能会导致内存瓶颈或计算资源不足。
反之,过小的批次可能导致芯片利用率下降。
因此,需要动态调整批次大小。
再讲深一点,
通常,进入到模型中的数据以向量的形式表示,
而这些向量特征各有所不同,
会分出个“高矮胖瘦(长度、大小、形状)”,
比如,长文本输入,短文本输入,
模型推理的效率与“高矮胖瘦”密切相关,
模型要根据这些向量的“体型”来调整,
处理视频数据时,
视频数据通常由帧序列组成,
输入到模型中的每个视频可以看作是一个多维向量,
向量的特性(如帧数、分辨率)会直接影响计算需求。
因此,批次大小需要根据视频特性进行调整。
模型结构与芯片架构的配合很重要,
为何不考虑用有别于英伟达GPU的芯片架构,
来克服上面谈到的问题?
比如,SambaNova的芯片架构,
Reconfigurable-Dataflow-Architecture
就非常有技术含量了。
07
改进算法
第三个答案,好好改进算法。
Transformer 模型有一个问题,
就是它在回答问题时,
需计算每个字和其他所有字之间的关系。
比如说,如果有一句话有 10 个字,
模型需要算出每一个字跟其他 9 个字的关系,
总共要计算 10 × 10 次。
如果有 100 个字,那就要算 100 × 100 次,
计算量会变得奇大,
这种计算方式被叫做“全局自注意力机制”,
它可以帮助模型找到句子中远距离字之间的关系,
头疼的是,句子变长,计算量增长得非常快
(大约是输入长度的平方,数学上写作 O(n⊃2;))。
这就像一个公司,
只要入职一个新员工,
每个员工都要和所有人打招呼,
人数一多,时间不是线性增加,
甚至不是翻倍增加,
而是计算量其实按照平方增长。
传统Transformer 需要改进,
有很多线性 Transformer 架构的研究,
正在探索当中。

第四个答案,降低点精度。
例如,从16位浮点数减少到8位或4位。
AI模型精度与芯片的I/O和数据传输量直接相关。
降低AI模型的精度,
芯片处理的数量量少了,
传输的数据也就少了。
如果以上都做好了,
那真的是全方位协同了。
不仅提升了大模型公司的盈利能力,
成本低了,把API 价格打下来的可能性就大了。
如果没有做到这一点,
技术变革走向产业变革将会十分困难。
最后,OpenAI 宕机,
表面上是算力,
但实际上是推理效率和成本控制上的一次警钟。
如果把芯片比作一块耕地,
大模型就是这片地里长出的庄稼。
耕地有限,如何让产出更高效、更具价值,
关键在于耕种的方法,
而不仅仅是扩展土地的面积。
推理成本的高低,不单纯取决于芯片的数量,
而是取决于算力能否被充分释放。”
谁能控制好推理成本,
谁就能笑到最后。
(完)
one more thing
作为一个吃货,亲口尝试,礼貌评价,
美国湾区领英的食堂真是太好吃了(纸巾擦口水ing)。

更多阅读:
《作者直到最近才费劲弄清楚的……》
1.2.3.4.5.长文系列
1. 2. 4. 5. 6. 7. 8. 9. 10.11.12.13.漫画系列
1. 2. 3. 5. 6.AI安全
1.2.


原标题:《OpenAl宕机,并非算力不够,而是……》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

