- +1
惊掉下巴!被字节起诉800万实习生,拿下NeurIPS 2024最佳论文
 新智元报道
新智元报道编辑:编辑部 HYZ
【新智元导读】太戏剧了!攻击字节训练集群的实习生,居然刚刚获得了NeurIPS 2024最佳论文奖?虽然看起来像爽文剧情,但这位高材生接下来的路,应该是难走了。
刚刚,恶意攻击字节训练集群的实习生田柯宇,获得了NeurIPS 2024的最佳论文奖。
 更巧的是,这篇获奖论文,恰恰就是他在字节商业化技术部门实习期间与团队合作发表的。
更巧的是,这篇获奖论文,恰恰就是他在字节商业化技术部门实习期间与团队合作发表的。甚至,这篇论文还是NeurIPS 2024第六高分的论文(7,8,8,8)。
 事情在网上曝出的时候,网友们都震惊了:太有戏剧性了,这是什么短剧的大反转剧情!
事情在网上曝出的时候,网友们都震惊了:太有戏剧性了,这是什么短剧的大反转剧情!根据网友的说法,田柯宇的这篇论文也是今年国内第二篇NeurIPS Best Paper,含金量很高。
在此之前,他就已经有多篇论文中稿顶会。
比如被引次数最多的「Designing BERT for Convolutional Networks: Sparse and Hierarchical Masked Modeling」,就是ICLR 2023的Spotlight。此外还有,NeurIPS 2021和2020的Poster,ECCV 2020的Poster。
 据新智元了解,字节商业化技术团队早在去年就把视觉自回归模型作为重要的研究方向,团队规划了VAR为高优项目,投入研究小组和大量资源。
据新智元了解,字节商业化技术团队早在去年就把视觉自回归模型作为重要的研究方向,团队规划了VAR为高优项目,投入研究小组和大量资源。除了VAR,团队还发表了LlamaGen等相关技术论文,新的研究成果也将在近期陆续放出。
事件始末:恶意注入代码,投毒模型训练
回看整件事情,可谓反转又反转。
两个月前,圈内人都被这样一条消息惊掉下巴:「字节跳动大模型训练被北大实习生攻击,损失巨大」。
什么仇什么怨,要做这样的事?
网友们扒出来,事情起因是这位北大高材生在字节实习期间对团队感到不满,一气之下选择了「投毒」。
具体来说,他利用了Huggingface的load ckpt函数漏洞,craft了一个看似正常的ckpt文件,但其实是加了payload进去,然后就可以远程执行代码,修改参数了。
这种攻击方式,可以通过修改或注入恶意代码,使模型在加载时被篡改模型权重、修改训练参数或截取模型数据。
根据大V「Jack Cui」猜测,这位实习生所用的大概就是这个方法,注入代码动态修改别人的optimer,修改参数梯度的方向,以及在各种地方随机sleep了一小段时间。
修改梯度方向,意味着模型反向传播过程中计算出的梯度被篡改,就导致模型一直朝错误的方向优化;而sleep操作,也会明显降低模型训练的速度。
甚至有人提到,该实习生可能修改了自己的预训练模型,因为模型参数是用ckpt文件保存的,其他人训练时会加载这个注入恶意代码的ckpt文件,因此也会导致模型训练出问题。
就在全网叹为观止之时,田本人却出来「辟谣」称这事和自己没关系——他发完论文后已经从字节离职了,此时有另一个人钻了漏洞修改模型代码,然后趁他离职把锅扣在他头上。
结果一个多月后,此事再一次迎来反转。
有媒体报道称,法院已经正式受理字节跳动对前实习生田某某的起诉。
法院判令田某某赔偿侵权损失800万元及合理支出2万元,同时要求其公开赔礼道歉。
字节官方也澄清说,涉事实习生破坏的是团队研究项目,并不影响商业化正式项目,也不涉及字节跳动大模型等其他业务。
最终,这位实习生被字节辞退,交由校方处理。
 资料显示,田柯宇本科毕业于北航软件学院,研究生就读于北大,师从王立威教授,研究兴趣为深度学习的优化与算法。
资料显示,田柯宇本科毕业于北航软件学院,研究生就读于北大,师从王立威教授,研究兴趣为深度学习的优化与算法。自2021年起,开始在字节跳动实习研究,具体包括超参数优化、强化学习算法、自监督的新型算法。
 超越扩散,VAR开启视觉自回归模型新范式
超越扩散,VAR开启视觉自回归模型新范式这项研究中,他们提出了一种全新范式——视觉自回归建模(Visual Autoregressive Modeling,VAR)。
 论文地址:https://arxiv.org/abs/2404.02905
论文地址:https://arxiv.org/abs/2404.02905与传统的光栅扫描「下一个token预测」方法有所不同,它重新定义了图像上的自回归学习,采用粗到细的「下一个尺度预测」或「下一个分辨率预测」。
这种简单直观的方法使得自回归(AR)Transformer能够快速学习视觉分布,并且具有较好的泛化能力:VAR首次使得类似GPT的AR模型在图像生成中超越了扩散Transformer。
 当前,自回归模型(AR)主要用于语言模型从左到右、逐字顺序生成文本token。同时,也用于图像生成中,即以光栅扫描的顺序从左到右,从上到下顺序生成图像token。
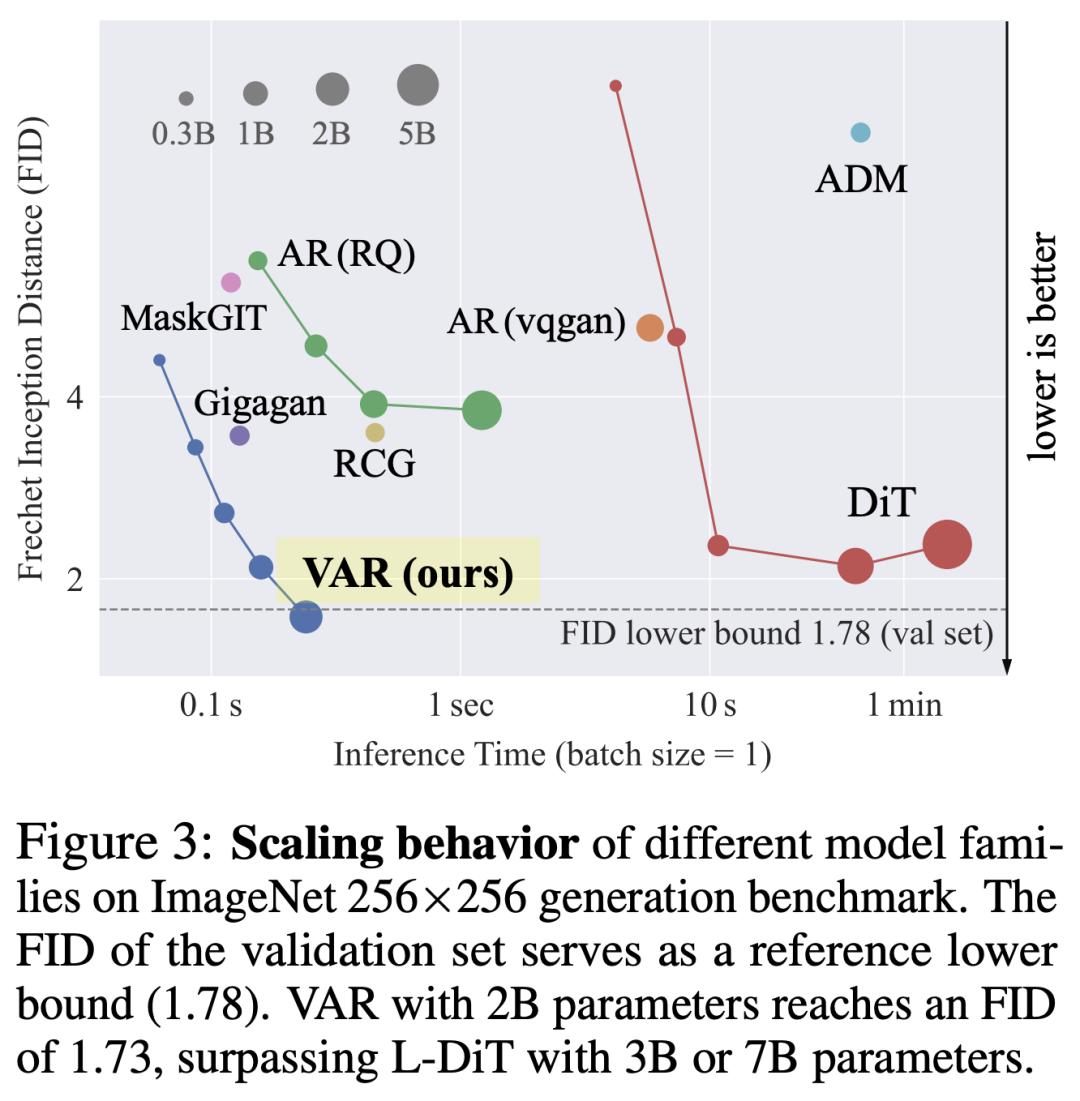
当前,自回归模型(AR)主要用于语言模型从左到右、逐字顺序生成文本token。同时,也用于图像生成中,即以光栅扫描的顺序从左到右,从上到下顺序生成图像token。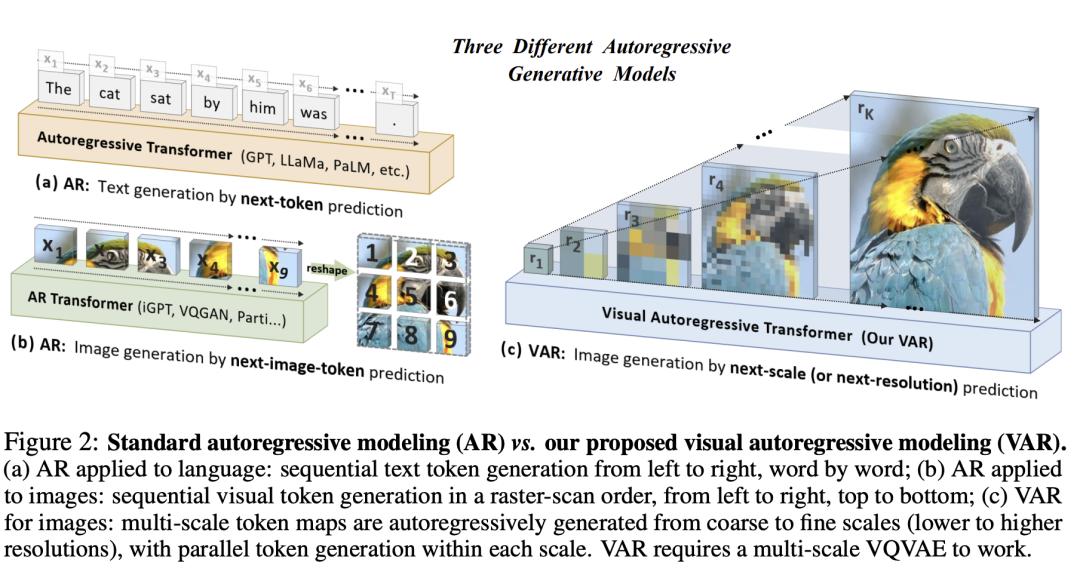 不过,这些AR模型的scaling law未得到充分的探索,而且性能远远落后于扩散模型,如下图3所示。
不过,这些AR模型的scaling law未得到充分的探索,而且性能远远落后于扩散模型,如下图3所示。与语言模型所取得成就相比,计算机视觉中的自回归模型的强大能力却被「禁锢」了起来。
 而自回归建模需要定义数据的顺序,北大字节团队研究中重新考虑了如何「排序」图像:人类通常以分层方式感知或创建图像,首先捕获全局结构,然后捕获局部细节。
而自回归建模需要定义数据的顺序,北大字节团队研究中重新考虑了如何「排序」图像:人类通常以分层方式感知或创建图像,首先捕获全局结构,然后捕获局部细节。这种多尺度、由从粗到细的本质,为图像提供了一种「秩序」。
同样,受到广泛使用的多尺度设计的启发,研究人员将图像的自回归学习定义为图2(c)中的「下一个尺度预测」,不同于传统图2(b)中的「下一个token的预测」。
VAR方法首先将图像编码为多尺度的token映射,然后,自回归过程从1×1token映射开始,并逐步扩展分辨率。
在每一步中,Transformer会基于之前所有的token映射去预测下一个更高分辨率的token映射。
由此,研究人员将此称为视觉自回归建模(VAR)。
VAR包括两个独立的训练阶段:在图像上训练多尺度VQVAE,在token上训练VAR Transformer。
第一阶段,多尺度VQ自动编码器将图像编码为K个token映射R=(r_1,r_2,…,r_K),并通过复合损失函数进行训练。
第二阶段,通过下一尺度预测对VAR Transformer进行训练:它以低分辨率token映射 ([s],r_1,r_2,…,r_K−1)作为输入,预测更高分辨率的token映射 (r_1,r_2,r_3,…,r_K)。训练过程中,使用注意力掩码确保每个r_k仅能关注 r_≤k。训练目标采用标准的交叉熵损失函数,用于优化预测精度。
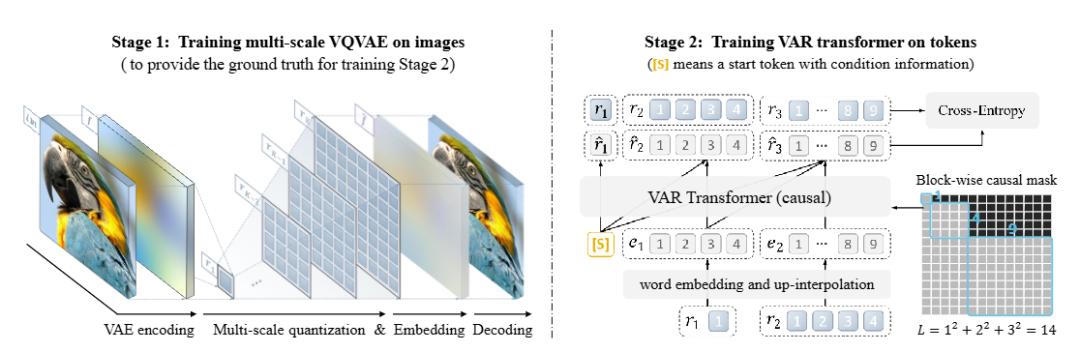 田柯宇团队在ImageNet 256×256和512×512条件生成基准上测试了深度为16、20、24和30的VAR模型,并将其与最先进的图像生成模型家族进行比较,包括生成对抗网络(GAN)、扩散模型(Diff.)、BERT 风格的掩码预测模型(Mask.)和 GPT 风格的自回归模型(AR)。
田柯宇团队在ImageNet 256×256和512×512条件生成基准上测试了深度为16、20、24和30的VAR模型,并将其与最先进的图像生成模型家族进行比较,包括生成对抗网络(GAN)、扩散模型(Diff.)、BERT 风格的掩码预测模型(Mask.)和 GPT 风格的自回归模型(AR)。在ImageNet 256×256基准测试中,VAR显著提高了AR基准性能,将Fréchet Inception距离(FID)从18.65降低到1.73,Inception得分(IS)从80.4提高到350.2,同时推理速度提高了20倍。
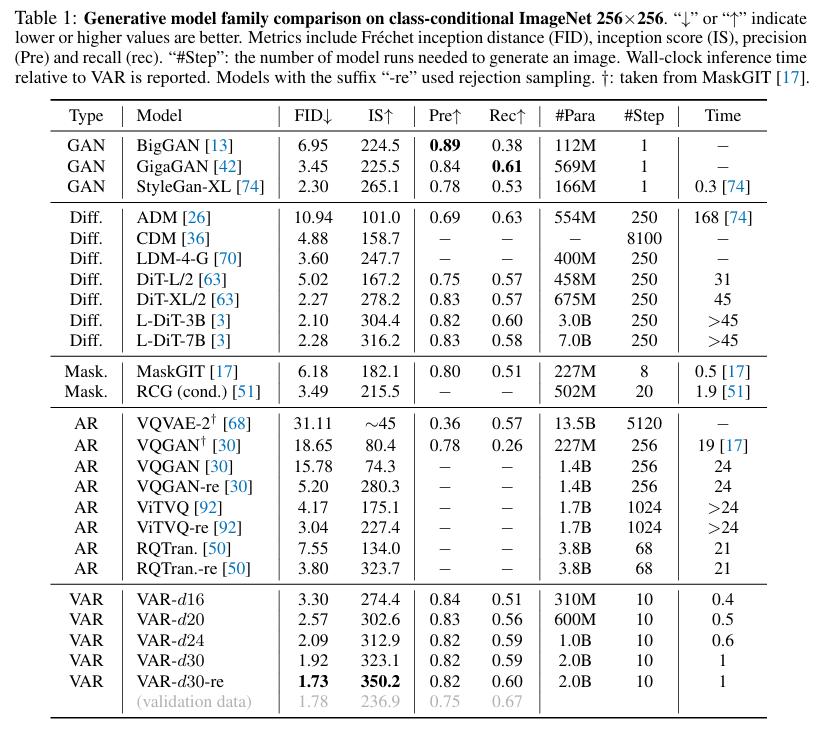 如上表所示,VAR不仅在FID/IS上达到了最佳成绩,还在图像生成速度上表现出色。VAR还保持了良好的精度和召回率,证明了其语义一致性。
如上表所示,VAR不仅在FID/IS上达到了最佳成绩,还在图像生成速度上表现出色。VAR还保持了良好的精度和召回率,证明了其语义一致性。这些优势在512×512合成基准测试中同样得到了体现。
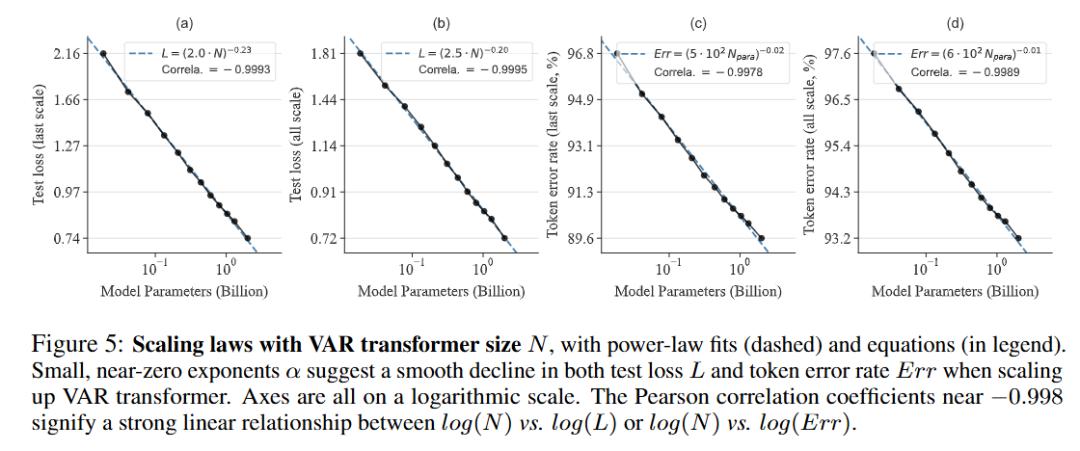
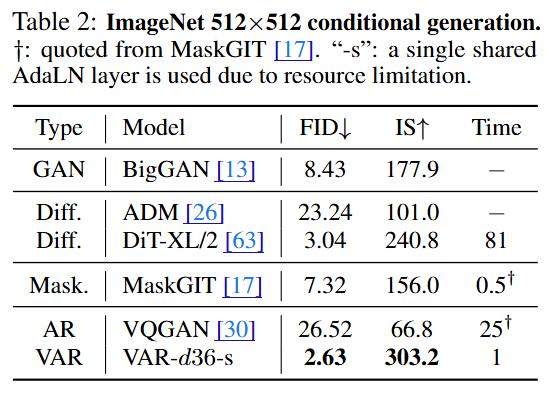 实验证明,VAR在多个维度上超越了扩散Transformer(DiT),包括图像质量、推理速度、数据效率和可扩展性。
实验证明,VAR在多个维度上超越了扩散Transformer(DiT),包括图像质量、推理速度、数据效率和可扩展性。VAR模型的扩展表现出了类似于大语言模型(LLM)的清晰幂律缩放规律,线性相关系数接近−0.998,这提供了强有力的证据。
 VAR还在下游任务中展示了零样本泛化能力,包括图像修复、图像外延和图像编辑等。
VAR还在下游任务中展示了零样本泛化能力,包括图像修复、图像外延和图像编辑等。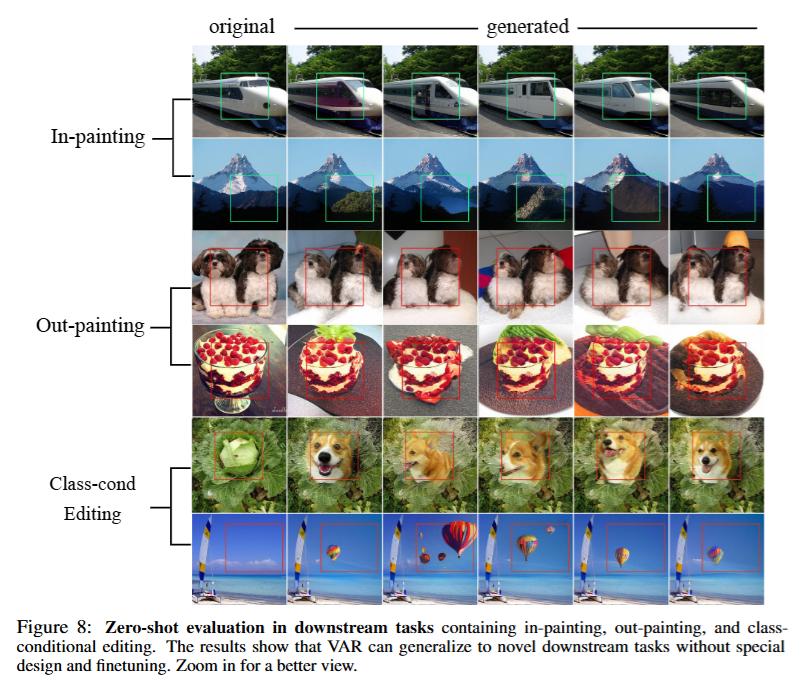 这些结果表明,VAR初步模仿了大语言模型的两个重要特性:缩放规律和零样本泛化能力。
这些结果表明,VAR初步模仿了大语言模型的两个重要特性:缩放规律和零样本泛化能力。田柯宇团队已在GitHub上发布了所有模型和代码,现已斩获4.4k星。
 项目地址:https://github.com/FoundationVision/VAR
项目地址:https://github.com/FoundationVision/VARAI顶会NeurIPS,录用率25.8%
NeurIPS全称神经信息处理系统大会(The Conference on Neural Information Processing Systems),是人工智能(AI)、机器学习(ML)和数据科学领域最负盛名且最具影响力的会议之一。
它于1987年首次举办,当时名字是「神经信息处理系统」(NIPS),主要为快速兴起的神经网络领域提供一个交流思想的平台。
随着会议范围逐渐扩大,涵盖了人工智能和机器学习更广泛的主题,会议名称于2018年更改为NeurIPS。
今年,是NeurIPS第38届年会,将于下周12月9日-15日在温哥华召开。
 NeurIPS顶会同样以严格的同行评审过程而著称,2023年录用率为26.1%,2022年为25.6%。
NeurIPS顶会同样以严格的同行评审过程而著称,2023年录用率为26.1%,2022年为25.6%。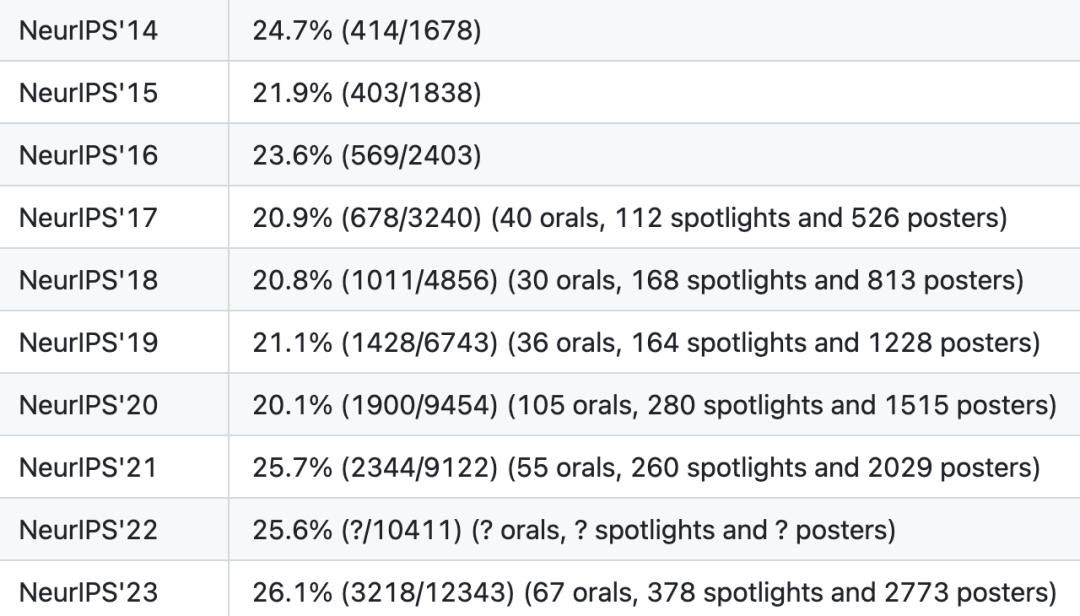 NeurIPS历年接收率
NeurIPS历年接收率今年,顶会一共接受了15671篇论文,录用率为25.8%,其中评审最低分2.2,最高分8.7,具体来说:
- Oral 61篇(0.39%)
- Spotlight 326篇(2.08%)
- Poster 3650篇(23.29%)
 参考资料:
参考资料:https://www.toutiao.com/w/1813324433807370/?log_from=d66b759dee10a_1733273717412
https://github.com/FoundationVision/VAR
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

