- +1
国防科技大学推出 AI 材料科学家 MatPilot;Anthropic 提出 LLM 越狱缓解新…
今日值得关注的大模型前沿论文
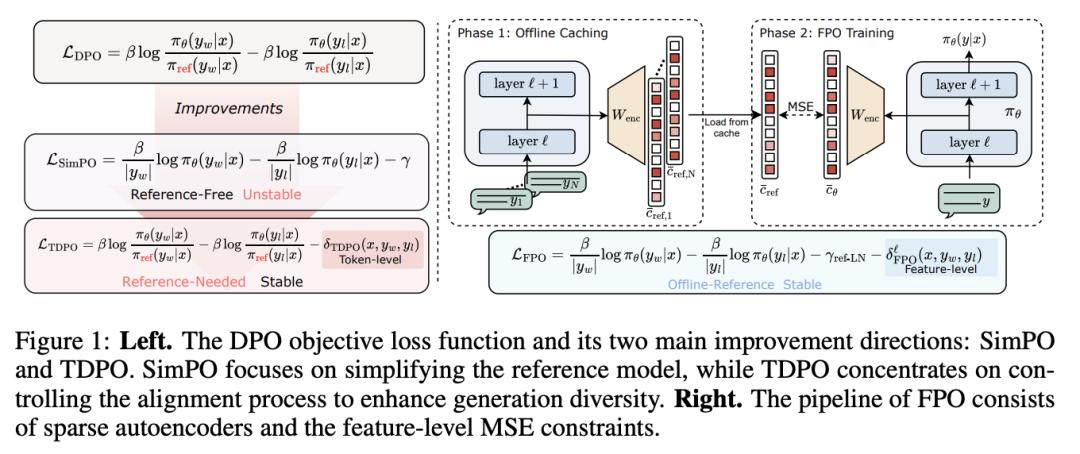
FPO:使用稀疏特征级约束进行直接偏好优化
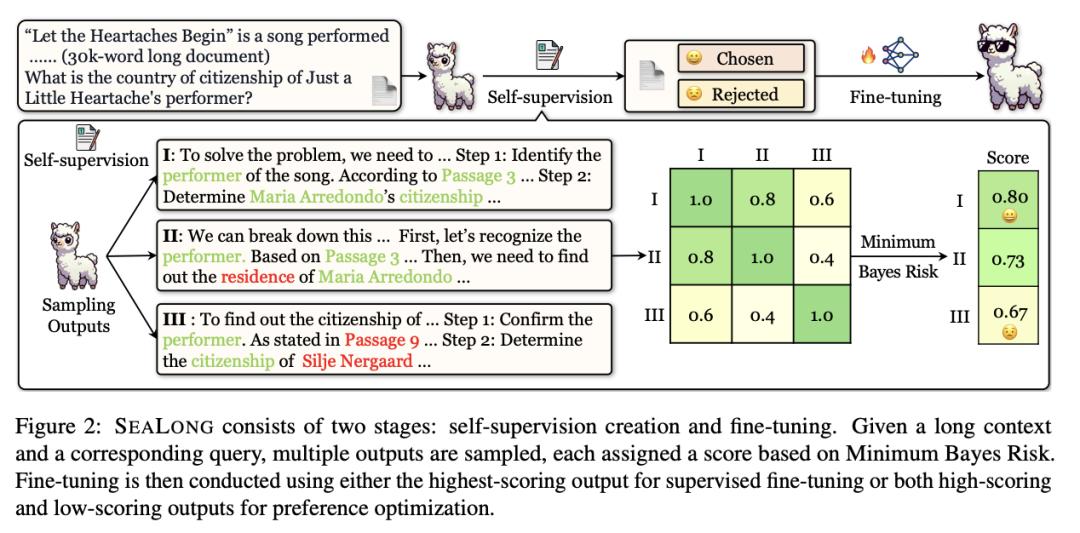
Sealong:大语言模型可在长上下文推理中自我提高
国防科技大学推出 AI 材料科学家 MatPilot
从安全性视角分析世界模型
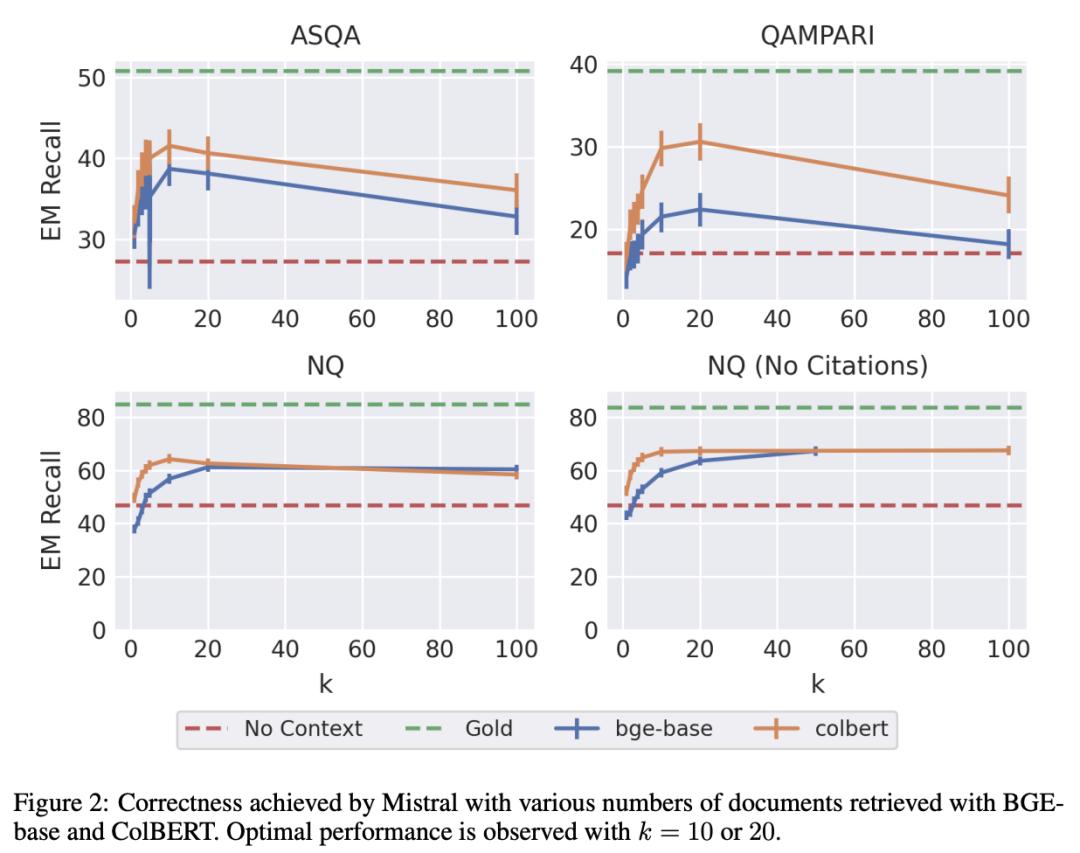
为 RAG 实现最佳搜索和检索
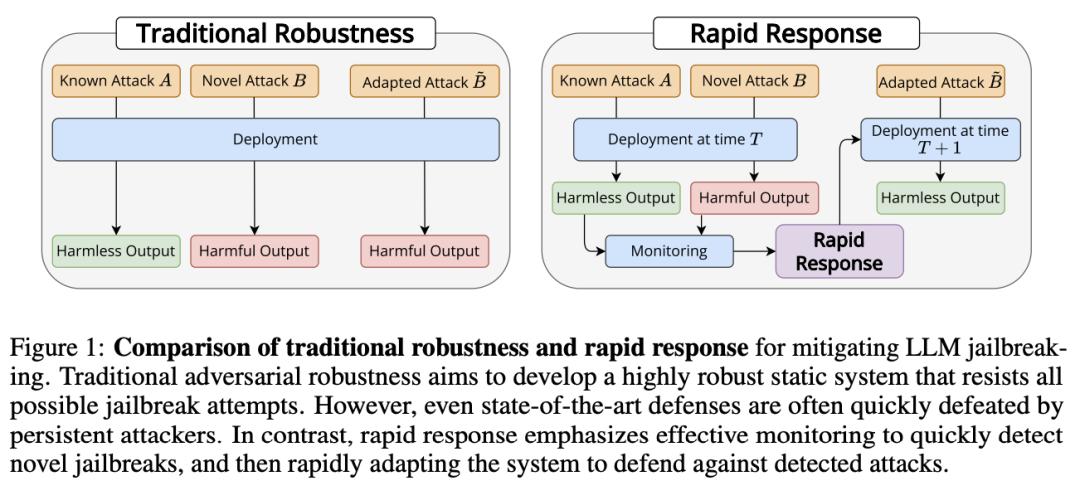
Anthropic 提出缓解 LLM 越狱问题新方法
想要第一时间获取每日最新大模型热门论文?
点击阅读原文,查看“2024必读大模型论文”
ps:我们日常会分享日报、周报,后续每月也会出一期月报,敬请期待~
FPO:使用稀疏特征级约束进行直接偏好优化
大语言模型(LLM)与人类偏好的对齐仍然是一项关键挑战。虽然像从基于人类反馈的强化学习(RLHF)和直接偏好优化(DPO)这样的后训练技术已经取得了显著的成功,但它们往往会带来计算效率低下和训练不稳定的问题。
在这项工作中,来自西湖大学和香港理工大学的研究团队及其合作者提出了特征约束偏好优化(FPO),旨在简化对齐过程,同时确保稳定性。FPO 利用预先训练好的稀疏自动编码器(SAE),并提出特征约束,从而实现高效的稀疏强化对齐。
他们的方法通过使用在训练有素的稀疏自动编码器中激活的稀疏特征来提高效率,并通过使用特征离线参考来提高顺序 KL 发散的质量。在基准数据集上的实验结果表明,与 SOTA 的基线方法相比,FPO 的绝对胜率提高了 5.08%,而计算成本却大大降低,这使它成为高效、可控的 LLM 对齐的理想解决方案。
论文链接:
https://arxiv.org/abs/2411.07618
Sealong:大语言模型可在长上下文推理中自我提高
大语言模型(LLM)在处理长上下文方面取得了长足的进步,但在长上下文推理方面仍很困难。现有的方法通常涉及用合成数据对 LLM 进行微调,这依赖于人类专家或 GPT-4 等高级模型的注释,从而限制了进一步的发展。
为了解决这个问题,来自香港中文大学的研究团队及其合作者研究了 LLM 在长上下文推理中自我提高的潜力,并提出了一种专门为此设计的方法——Sealong。这种方法简单明了:他们对每个问题的多个输出进行采样,用最小贝叶斯风险(Minimum Bayes Risk)对它们进行评分,然后根据这些输出应用有监督的微调或偏好优化。
在几个领先的 LLM 上进行的广泛实验证明了 Sealong 的有效性,Llama-3.1-8B-Instruct 的绝对值提高了4.2分。此外,与之前依赖于人类专家或高级模型生成的数据的方法相比,Sealong 实现了更优越的性能。
论文链接:
https://arxiv.org/abs/2411.08147
国防科技大学推出 AI 材料科学家 MatPilot
人工智能(AI)尤其是大语言模型(LLM)的快速发展为材料科学研究带来了前所未有的机遇。国防科技大学研究团队提出并开发了名为 MatPilot 的人工智能材料科学家,它在发现新材料方面表现出了令人鼓舞的能力。MatPilot 的核心优势在于其自然语言交互式人机协作,通过多智能体系统增强人类科学家团队的研究能力。
MatPilot 将人类独特的认知能力、丰富的经验积累和持续的好奇心与 AI 智能体的高级抽象、复杂知识存储和高维信息处理能力融为一体。它可以生成科学假设和实验方案,并采用预测模型和优化算法来驱动自动实验平台进行实验。
论文链接:
https://arxiv.org/abs/2411.08063

从安全性视角分析世界模型
随着大语言模型(LLM)的普及,世界模型(WM)的概念最近在人工智能研究界引起了广泛关注,尤其是在 AI 智能体方面。可以说,它正逐渐成为构建 AI 智能体系统的重要基础。世界模型旨在帮助智能体预测环境状态的未来演变,或帮助智能体填补缺失的信息,以便其规划行动并安全行事。世界模型的安全特性对其在关键应用中的有效使用起着关键作用。
在这项工作中,来自 RAMS Lab 的研究团队及其合作者基于全面的调查和设想的应用领域,从可信性和安全性的角度回顾和分析了当前 SOTA 世界模型的影响。他们对 SOTA 世界模型进行了深入分析,并推导出技术研究挑战及其影响,以呼吁研究界合作提高世界模型的安全性和可信度。
论文链接:
https://arxiv.org/abs/2411.07690

为 RAG 实现最佳搜索和检索
检索增强生成(RAG)是一种很有前途的方法,可以解决与大语言模型(LLM)相关的一些记忆相关挑战。两个独立的系统构成了 RAG 管道,即检索器和阅读器,而这两个系统对下游任务性能的影响还不十分清楚。
在此,来自科罗拉多大学博尔德分校和英特尔实验室的研究团队致力于了解检索器如何为常见任务(如 QA)的 RAG 管道进行优化。他们的实验重点是 QA 和归因 QA 的检索和 RAG 性能之间的关系,并揭示了一些对开发高性能 RAG 管道的从业人员有用的见解。例如,降低搜索精度对 RAG 性能影响不大,但却有可能提高检索速度和内存效率。
论文链接:
https://arxiv.org/abs/2411.07396
Anthropic 提出缓解 LLM 越狱问题新方法
随着大语言模型(LLM)越来越强大,确保其安全以防滥用变得至关重要。虽然研究人员一直专注于开发强大的防御功能,但还没有一种方法能完全抵御攻击。
来自 Anthropic 的研究团队及其合作者提出了另一种方法:他们不追求完美的对抗鲁棒性,而是开发快速响应技术,以便在观察到少量攻击后阻止整类越狱。为了研究这种情况,他们提出了 RapidResponseBench(快速响应基准),它是一种基准,用于衡量防御系统在适应少量观察到的示例后对各种越狱策略的鲁棒性。他们评估了五种快速反应方法,所有这些方法都使用了越狱扩散,即自动生成与观察到的示例类似的额外越狱。
他们最强大的方法对输入分类器进行了微调,以阻止增殖越狱,在仅观察到一个越狱策略实例的情况下,对分布内越狱集的攻击成功率降低了 240 倍以上,对分布外越狱集的攻击成功率降低了 15 倍以上。此外,进一步的研究表明,扩散模型的质量和扩散示例的数量对这种防御的有效性起着关键作用。
论文链接:
https://arxiv.org/abs/2411.07494
整理:李雯靖
如需转载或投稿,请直接在公众号内留言素材来源官方媒体/网络新闻
原标题:《国防科技大学推出 AI 材料科学家 MatPilot;Anthropic 提出 LLM 越狱缓解新方法|大模型日报》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

