- +1
哈佛、MIT提出“精度感知”Scaling Laws;首个金融LLM综合双语基准|大模型日报
今日值得关注的大模型前沿论文
哈佛、MIT 团队提出「精度感知 Scaling Laws」
DeepSeek-AI 提出 JanusFlow:将图像理解和生成统一到一个模型中
综述:视觉中的自回归模型
博弈论 LLM:谈判博弈的代理工作流程
语言模型是隐藏推理器:通过自我奖励释放潜在推理能力
DELIFT:数据高效语言模型指令微调
斯坦福团队提出 RaVL:发现并减轻微调视觉语言模型中的虚假相关性
首个多模态 CAD 模型生成系统 CAD-MLLM
OmniEdit:通过专家监督建立图像编辑通用模型
首个金融 LLM 综合双语基准 Golden Touchstone
想要第一时间获取每日最新大模型热门论文?
点击阅读原文,查看“2024必读大模型论文”
ps:我们日常会分享日报、周报,后续每月也会出一期月报,敬请期待~
哈佛、MIT 团队提出「精度感知 Scaling Laws」
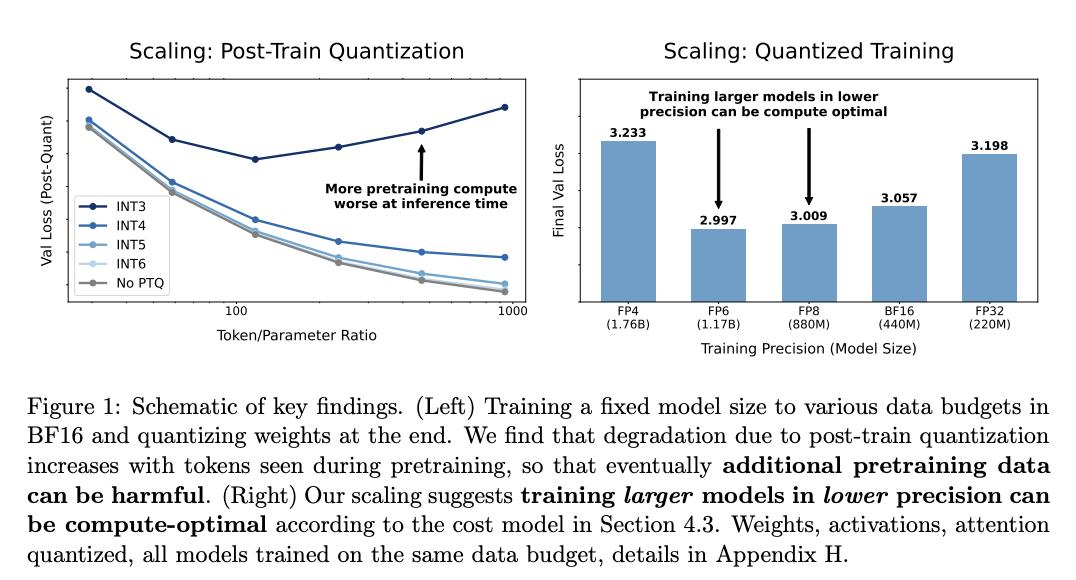
低精度训练和推理会影响语言模型的质量和成本,但目前的 Scaling Laws 并未考虑到这一点。
在这项工作中,来自哈佛大学和麻省理工学院的研究团队及其合作者为训练和推理设计了“精度感知”scaling laws。他们提出,以较低精度进行训练可减少模型的“有效参数数”,从而使他们能够预测低精度训练和训练后量化带来的额外损失。在推理方面,他们发现随着模型在更多数据上进行训练,训练后量化带来的劣化也会增加,最终使额外的预训练数据变得有害。
对于训练,他们的 scaling laws 允许他们预测模型在不同精度下的损失,并表明在较低精度下训练较大的模型可能是计算最优的。他们统一了训练后量化和训练前量化的缩放规律,从而得出了一个单一的函数形式,可以预测在不同精度下训练和推理的损失。他们在超过 465 次预训练运行中进行了拟合,并在多达 26B 个 token 上训练出的高达 1.7B 参数模型规模上验证了我们的预测。
论文链接:
https://arxiv.org/abs/2411.04330
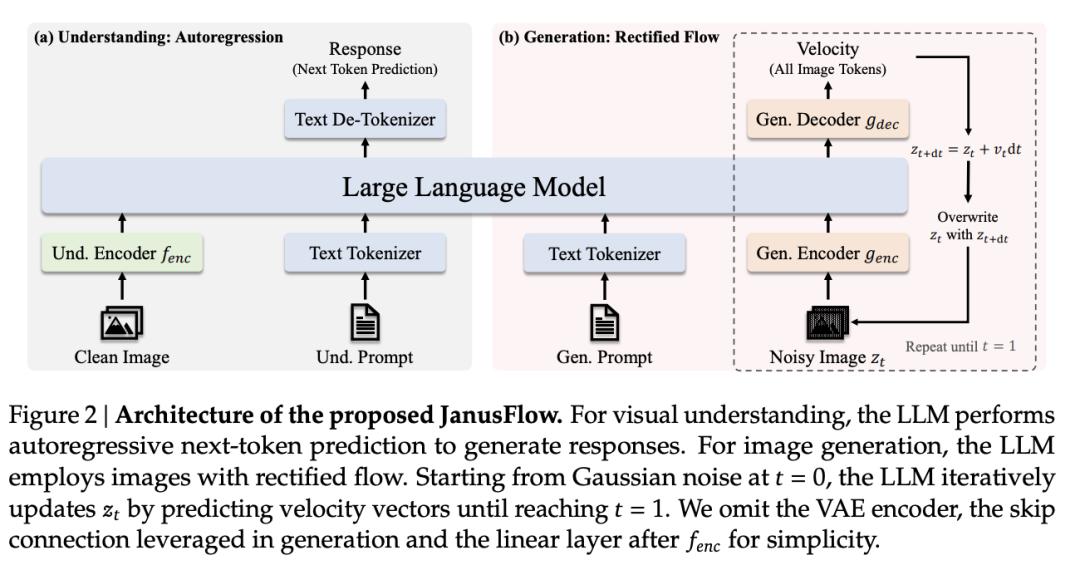
DeepSeek-AI 提出 JanusFlow:将图像理解和生成统一到一个模型中
来自 DeepSeek-AI 的研究团队及其合作者提出了 JanusFlow 框架,可将图像理解和生成统一到一个模型中。JanusFlow 引入了一种极简主义架构,将自回归语言模型与修正流(一种 SOTA 的生成建模方法)相结合。
他们的主要发现表明,修正流可以在大语言模型框架内直接进行训练,无需进行复杂的架构修改。为了进一步提高统一模型的性能,他们采用了两种关键策略:将理解和生成编码器解耦,以及在统一训练期间对齐它们的表现。大量实验表明,JanusFlow 在各自的领域中实现了与专门模型相当或更优异的性能,同时在标准基准测试中明显优于现有的统一方法。
论文链接:
https://arxiv.org/abs/2411.07975
GitHub 地址:
https://github.com/deepseek-ai/Janus
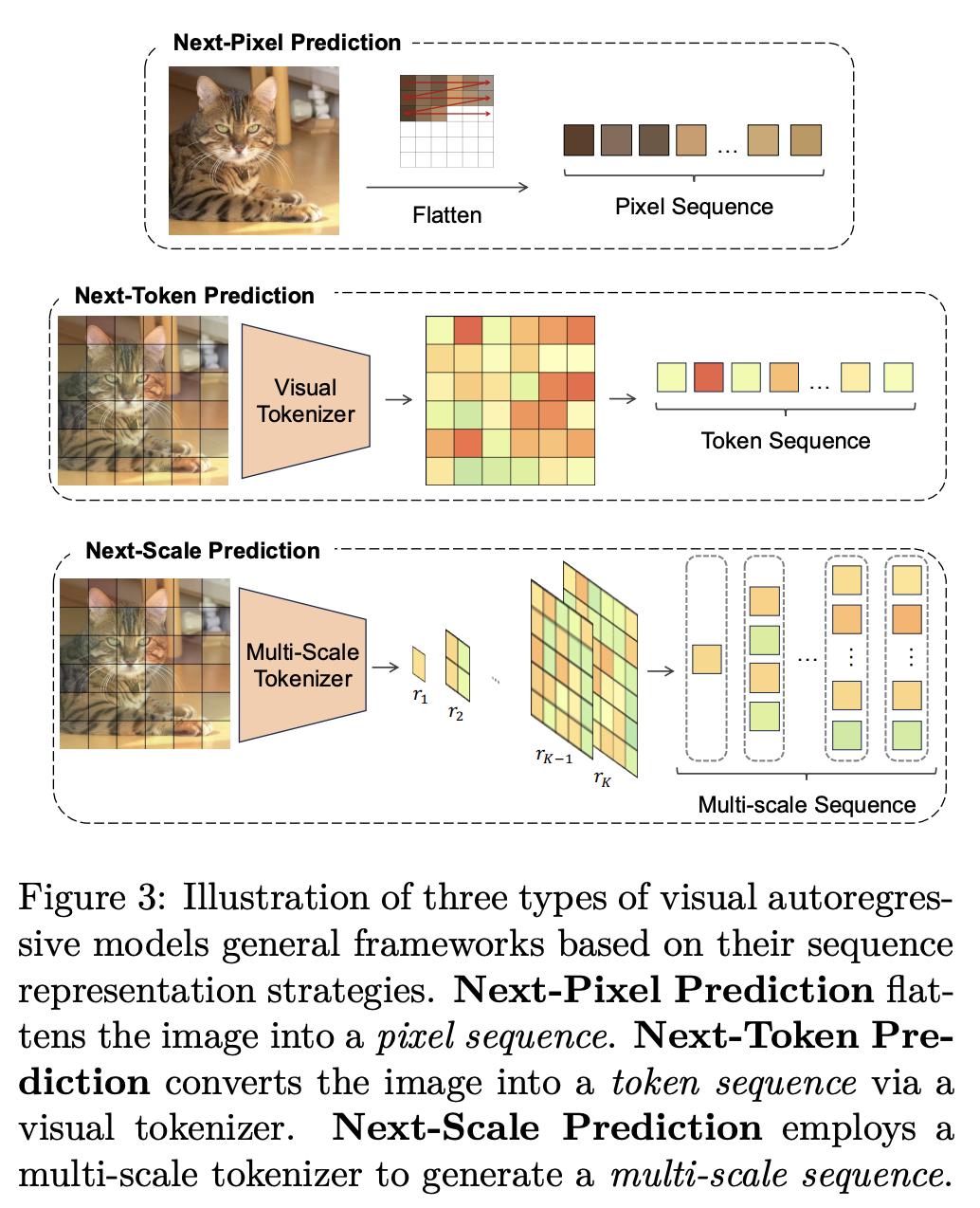
综述:视觉中的自回归模型
自回归模型在自然语言处理(NLP)领域取得了巨大成功。最近,自回归模型又成为计算机视觉领域的一个重要关注点,它们在制作高质量的视觉内容方面表现出色。NLP 中的自回归模型通常在子词 token 上运行。然而,计算机视觉中的表示策略可以在不同层次上变化,如像素级、token 级或尺度级,这反映了与语言的序列结构相比,视觉数据的多样性和层次性。
本综述全面考察了应用于视觉的自回归模型的研究。为了提高来自不同研究背景的研究人员的可读性,来自香港大学和清华大学的研究团队及其合作者首先介绍了视觉中的初步序列表示和建模。接下来,他们根据表示策略将视觉自回归模型的基本框架分为三个一般子类,包括基于像素的模型、基于 token 的模型和基于尺度的模型。然后,他们探讨了自回归模型与其他生成模型之间的相互联系。
此外,他们还对计算机视觉中的自回归模型进行了多方面的分类,包括图像生成、视频生成、三维生成和多模态生成。他们还阐述了自回归模型在不同领域的应用,包括具身人工智能和三维医疗人工智能等新兴领域,并提供了约 250 篇相关参考文献。最后,他们强调了自回归模型目前在视觉领域面临的挑战,并就潜在的研究方向提出了建议。
论文链接:
https://arxiv.org/abs/2411.05902
GitHub 地址:
https://github.com/ChaofanTao/Autoregressive-Models-in-Vision-Survey
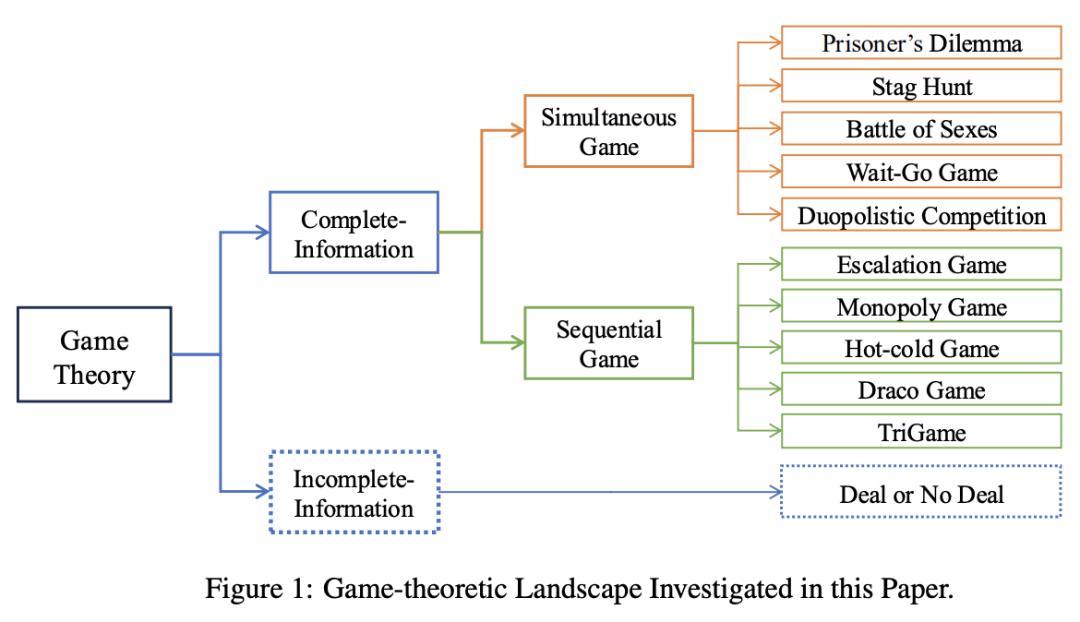
博弈论 LLM:谈判博弈的代理工作流程
来自罗格斯大学的研究团队及其合作者特别在博弈论的框架内研究了战略决策背景下大语言模型(LLM)的合理性。他们在一系列完全信息博弈和不完全信息博弈中评估了几种 SOTA 的 LLM。他们的研究结果表明,LLM 经常偏离理性策略,尤其是当博弈的复杂性随着支付矩阵的增大或顺序树的加深而增加时。
为了解决这些局限性,他们设计了多个博弈论工作流,以指导 LLM 的推理和决策过程。这些工作流程旨在提高模型计算纳什均衡点和做出理性选择的能力,即使在不确定和信息不完全的条件下也是如此。实验结果表明,采用这些工作流程能显著提高 LLM 在博弈论任务中的合理性和稳健性。具体来说,采用工作流程后,LLM 在确定最优策略、在谈判场景中实现接近最优的分配以及降低谈判过程中被利用的可能性等方面都有明显改善。此外,他们还探讨了智能体采用这种工作流程是否合理的元战略考量,认识到使用或放弃工作流程的决策本身就构成了一个博弈论问题。
他们的研究有助于加深对 LLM 在战略环境中的决策能力的理解,并为通过结构化工作流程提高其合理性提供了见解。
论文链接:
https://arxiv.org/abs/2411.05990
GitHub 地址:
https://github.com/Wenyueh/game_theory
语言模型是隐藏推理器:通过自我奖励释放潜在推理能力
大语言模型(LLM)已经显示出令人印象深刻的能力,但在需要多个步骤的复杂推理任务中仍然存在困难。虽然基于提示的方法(如思维链 CoT)可以改善 LLM 的推理能力,但在训练过程中优化推理能力仍然是一项挑战。
Salesforce AI Research 的研究团队提出了 LaTent 推理优化(LaTRO),这是一个原则性框架,它将推理表述为从潜在分布中采样,并通过变异方法对其进行优化。LaTRO 可使 LLM 同时改进其推理过程和评估推理质量的能力,而无需外部反馈或奖励模型。
他们使用多种模型架构在 GSM8K 和 ARC-Challenge 数据集上进行实验,验证了 LaTRO。在 GSM8K 数据集上,与基础模型相比,LaTRO 平均提高了 12.5%,与 Phi-3.5-mini、Mistral-7B 和 Llama-3.1-8B 的监督微调相比,提高了 9.6%。他们的研究结果表明,预训练的 LLM 具有潜在的推理能力,可以通过他们提出的优化方法以自改进的方式释放和增强这些能力。
论文链接:
https://arxiv.org/abs/2411.04282
GitHub 地址:
https://github.com/SalesforceAIResearch/LaTRO

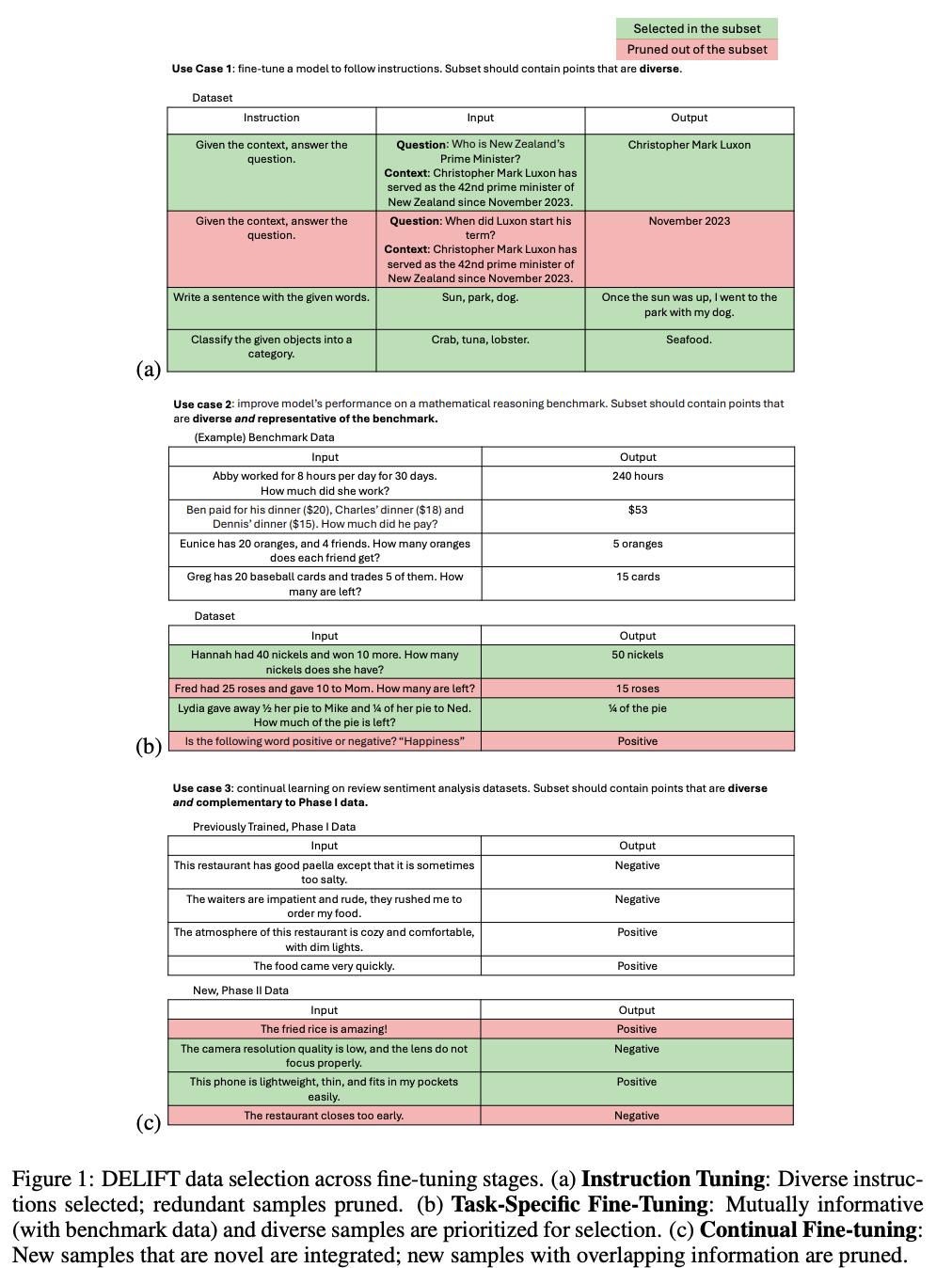
DELIFT:数据高效语言模型指令微调
微调大语言模型(LLM)对于提高其在特定任务上的性能至关重要,但由于数据冗余或无信息,通常会占用大量资源。
为了解决这种低效率问题,来自伊利诺伊大学香槟分校和 IBM 研究院的研究团队提出了 DELIFT(数据高效语言模型指令微调),这是一种新颖的算法,可以在微调的三个关键阶段系统地优化数据选择:(1)指令微调,(2)特定任务的微调(例如推理、问答),以及(3)持续微调(例如合并新的数据版本)。与专注于单阶段优化或依赖计算密集型梯度计算的现有方法不同,DELIFT 在所有阶段都高效运行。
他们方法的核心是成对效用指标,它量化数据样本对于改善模型对其他样本的响应的益处,有效地测量相对于模型当前能力的信息价值。通过利用应用于该指标的不同子模函数,DELIFT 选择在微调的所有阶段都有用的多样化且最佳的子集。跨各种任务和模型规模的实验表明,DELIFT 可以在不影响性能的情况下将微调数据大小减少高达 70%,从而显着节省计算量,并在效率和功效方面优于现有方法。
论文链接:
https://arxiv.org/abs/2411.04425
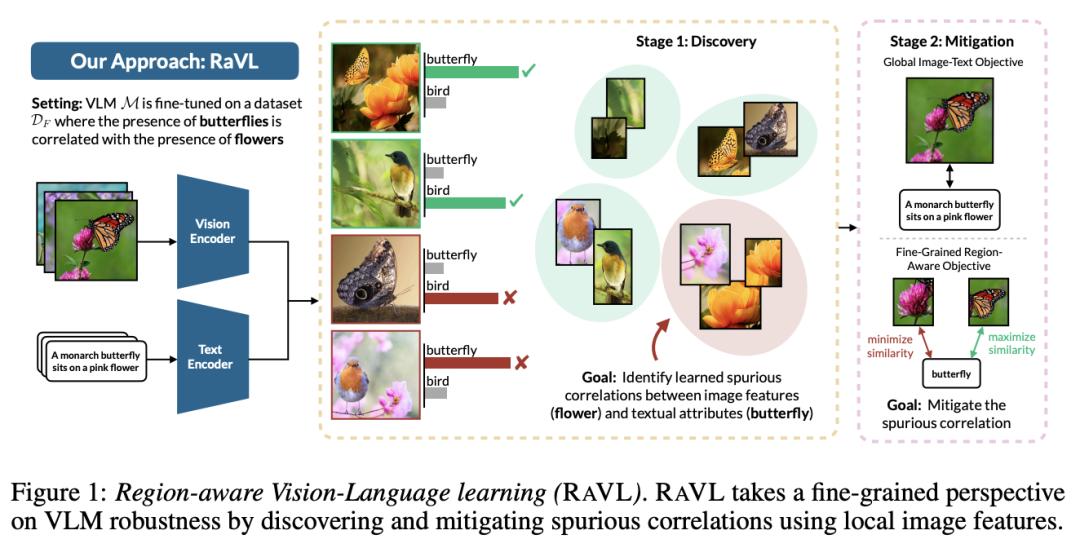
斯坦福团队提出 RaVL:发现并减轻微调视觉语言模型中的虚假相关性
微调的视觉语言模型 (VLM) 通常会捕获图像特征和文本属性之间的虚假相关性,从而导致测试时的零样本性能下降。用于解决虚假相关性的现有方法(i)主要在全局图像级别操作,而不是直接干预细粒度图像特征,并且(ii)主要针对单峰设置而设计。
在这项工作中,斯坦福大学的研究团队提出了 RaVL,它通过使用局部图像特征而不是在全局图像级别上操作来发现和减轻虚假相关性,从而对 VLM 鲁棒性进行了细粒度的视角。给定微调的 VLM,RaVL 首先利用区域级聚类方法来识别导致零样本分类错误的精确图像特征,从而发现虚假相关性。然后,RaVL 通过新颖的区域感知损失函数减轻已识别的虚假相关性,该函数使 VLM 能够专注于相关区域并在微调期间忽略虚假关系。
他们在 654 个 VLM 上评估 RaVL,具有各种模型架构、数据域和学习的虚假相关性。结果表明,RaVL 准确地发现了(比最接近的基线提高了 191%)并减轻了(对最差组图像分类准确度提高了 8.2%)虚假相关性。
论文链接:
https://arxiv.org/abs/2411.04097
首个多模态 CAD 模型生成系统 CAD-MLLM
这项工作旨在设计一种统一的计算机辅助设计(CAD)生成系统,该系统可根据用户输入的文本描述、图像、点云甚至它们的组合形式轻松生成 CAD 模型。
为了实现这一目标,来自上海科技大学和 Transcengram 的研究团队及其合作者推出了 CAD-MLLM,这是第首个能够根据多模态输入生成参数化 CAD 模型的系统。具体来说,在 CAD-MLLM 框架内,他们利用 CAD 模型的命令序列,然后采用先进的大语言模型 (LLM) 来调整这些多样化多模态数据和 CAD 模型矢量化表示的特征空间。
为了便于模型训练,他们设计了一个全面的数据构建和标注管道,为每个 CAD 模型配备相应的多模态数据。他们的数据集被命名为 Omni-CAD,它是首个多模态 CAD 数据集,包含每个 CAD 模型的文本描述、多视图图像、点和指令序列。该数据集包含约 450K 个实例及其 CAD 结构序列。为了全面评估他们生成的 CAD 模型的质量,他们超越了当前侧重于重建质量的评估指标,引入了评估拓扑质量和曲面包围程度的附加指标。广泛的实验结果表明,CAD-MLLM 的性能明显优于现有的条件生成方法,并且对噪声和缺失点具有很强的鲁棒性。
论文链接:
https://arxiv.org/abs/2411.04954
项目地址:
https://cad-mllm.github.io/

OmniEdit:通过专家监督建立图像编辑通用模型
通过在自动合成或手动标注的图像编辑对上训练扩散模型,指导性图像编辑方法已经展示出巨大的潜力。然而,这些方法离现实生活中的实际应用还很遥远。
来自滑铁卢大学和威斯康辛大学麦迪逊分校的研究团队及其合作者发现,造成这一差距的主要挑战有三个。首先,由于合成过程存在偏差,现有模型的编辑技能有限。其次,这些方法都是通过含有大量噪音和人工痕迹的数据集进行训练的。这是由于应用了简单的过滤方法,如 CLIP-score。第三,所有这些数据集都局限于单一的低分辨率和固定的长宽比,限制了处理实际应用案例的通用性。
在这项工作中,他们推出了一种全能编辑器,它可以无缝处理七种不同长宽比的图像编辑任务。他们的贡献体现在四个方面:(1)通过利用七个不同专家模型的监督对 omniedit 进行训练,以确保任务覆盖面。(2) 要们利用基于多模态大模型(如 GPT-4o)提供的分数的重要性采样,而不是 CLIP-score,来提高数据质量。(3) 他们提出了一种名为 EditNet 的新编辑架构,大大提高了编辑成功率。(4) 他们提供了不同长宽比的图像,确保他们的模型可以处理任何野生图像。他们策划了一个测试集,其中包含不同长宽比的图像,并附有不同的指令,以涵盖不同的任务。自动评估和人工评估都表明,omniedit 的性能明显优于所有现有模型。
论文链接:
https://arxiv.org/abs/2411.07199
项目地址:
https://tiger-ai-lab.github.io/OmniEdit/

首个金融 LLM 综合双语基准 Golden Touchstone
随着大语言模型(LLM)在金融领域的日益普及,迫切需要一种标准化的方法来全面评估它们的性能。然而,现有的金融基准往往存在语言和任务覆盖范围有限、数据集质量不高以及对 LLM 评估的适应性不足等问题。
为了解决这些局限性,来自 IDEA Research 和香港科技大学(广州)的研究团队及其合作者提出了 Golden Touchstone——首个金融 LLM 综合双语基准,其中包含了八个核心金融 NLP 任务的中英文代表性数据集。该基准从广泛的开源数据收集和特定行业需求出发,包含各种金融任务,旨在全面评估模型的语言理解和生成能力。通过对基准中的主要模型(如 GPT-4o Llama3、FinGPT 和 FinMA)进行比较分析,他们揭示了它们在处理复杂金融信息方面的优势和局限。
此外,他们还开源了 Touchstone-GPT,这是一种通过持续的预训练和金融指令微调训练出来的金融 LLM,它在双语基准上表现出了很强的性能,但在具体的研究中仍然存在局限性。
论文链接:
https://arxiv.org/abs/2411.06272
GitHub 地址:
https://github.com/IDEA-FinAI/Golden-Touchstone

整理:李雯靖
如需转载或投稿,请直接在公众号内留言素材来源官方媒体/网络新闻
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

