- +1
Google Cloud发布下一代TPU和GPU集群,增强AI Hypercomputer堆栈
Google Cloud正在更新面向AI工作负载的AI Hypercomputer堆栈,并宣布推出了一系列新处理器和基础设施软件产品。
Google宣布推出了第六代张量处理单元Trillium TPU,以及即将推出由Nvidia H200 GPU驱动的新型A3 Ultra虚拟机,此外还有基于Axion Arm架构的C4A VM,从今天正式面世。
谷歌还推出了新的软件,包括一个名为Hypercompute Cluster的高度可扩展集群系统,以及Hyperdisk ML块存储和并行文件系统。
Google Cloud副总裁、计算和AI基础设施总经理Mark Lohmeyer在一篇博文中表示,AI Hypercomputer堆栈为企业提供了一种方法,可以把工作负载优化的硬件(例如谷歌的TPU和GPU)与一系列开源软件集成在一起,以支持广泛的AI工作负载。
他表示:“这种整体方法优化了堆栈的每一层,在最广泛的模型和应用中实现了无与伦比的规模、性能和效率。”
Lohmeyer表示,谷歌希望提高AI Hypercomputer堆栈的性能,同时使其更易于使用,且运行成本更低。要做到这一点,就需要一套先进的新功能,这正是谷歌今天推出的。
这次最重要的发布是Trillium TPU,它为客户提供了Nvidia主流GPU的一个强大替代品,并且已经被谷歌用于支持高级AI应用,例如Gemini系列大型语言模型。Trillium TPU现已面向所有客户推出预览版,与谷歌第五代TPU相比,Trillium TPU有了显著改进。
例如,它在AI训练方面的性能提升了4倍,推理吞吐量方面提升了3倍,能源效率方面提升了67%,峰值计算性能提高了4.7倍,同时高带宽内存容量增加了1倍,芯片间互连带宽也增加了1倍。
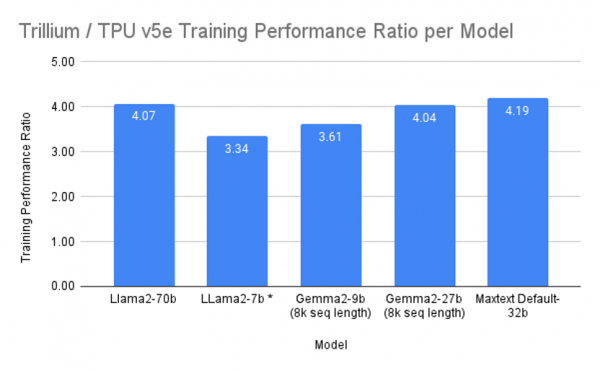
内存和带宽的增加,意味着Trillium可以运行更大的大型语言模型,具有更多的权重和更大的键值缓存。此外,它还允许芯片在训练和推理方面支持更广泛的模型架构,成为训练Gemma 2和Llama等大型语言模型以及“Mixture-of-Experts”(MoE)机器学习技术的理想选择。
Lohmeyer表示,Trillium可以扩展到一个配置了256个芯片的集群容纳在一个高带宽、低延迟的pod中,可以使用最先进的芯片间互连技术将其链接到其他pod,这就意味着客户拥有无限的可能性,他们可以灵活地连接数百个pod和数万个Trillium TPU,以打造“建筑规模”的超级计算机,并由每秒13千兆比特的Jupiter数据中心网络提供支持。
“我们设计TPU是为了优化性价比,Trillium也不例外,与v5e TPU相比,它的性能提高了1.8倍,与v5p相比,性能提高了约2倍,这使Trillium成为我们迄今为止性价比最高的TPU。”
采用Nvidia H100 GPU的A3 Ultra VM
当然,Google Cloud的客户并不局限于使用Trillium TPU,因为谷歌还是继续大量购买Nvidia最强大的GPU。谷歌已经使用Nvidia H100 GPU打造了最新的A3 Ultra VM,据说与现有的A3和A3 Mega VM相比,性能上有了显著的提升。
Lohmeyer表示,A3 Ultra VM将于下个月登陆Google Cloud,利用谷歌新的Titanium ML网络适配器和数据中心范围的四向轨道对齐网络,提供高达每秒3.2兆比特的GPU到GPU传输流量。
因此,GPU到GPU带宽的带宽将提高2倍,大型语言模型推理工作负载性能提高2倍,内存容量增加近2倍,带宽增加1.4倍,这些都将让客户从中受益。就像TPU一样,客户可以选择将数万个GPU连接到一个密集的高性能集群中,以处理那些要求最苛刻的AI工作负载,从而扩展部署规模。

A3 Ultra VM可以被作为独立的计算选项使用,也可通过Google Kubernetes Engine使用,后者为客户提供了一个开放的、便携的、可延伸和可扩展的AI训练和服务平台。
基于Google Axion CPU的C4A VM
当然谷歌承认,并非每个AI用例都需要如此强大的马力,因为有很多类型的通用AI工作负载用较低的功率就可以运行起来。在这种情况下,优化堆栈以降低成本是有意义的,而这时候新C4A VM就能派上用场了。
C4A VM是由Google Axion CPU提供支持的,后者是谷歌首款基于Arm架构的数据中心CPU。

谷歌给出了一些有趣的说法,称C4A VM的性价比比竞争对手云平台上最新基于Arm的实例要高出10%,而且和当前一代基于x86的实例相比也非常出色,性价比高出65%,对于通用工作负载(例如Web和应用服务器、数据库工作负载和容器化微服务)而言,能效高出60%。
Constellation Research分析师Holger Mueller表示,这款新硬件进一步巩固了Google Cloud作为AI开发者最佳云基础设施平台的地位。谷歌借助Trillium TPU在把TensorFlow等客户算法应用到客户硬件方面,领先竞争对手三到四年。
Mueller表示:“除了性能改进之外,Trillium在能效方面提升67%,这看起来也非常重要,因为功耗因素对每个组织都变得越来越重要,看到网络速度和带宽的提高也令人欣喜,这可以满足更大模型的需求。”
此外Mueller表示,Google Cloud的客户会很高兴知道谷歌正准备支持Nvidia最强大的GPU,包括定于明年推出的Blackwell GPU。
“现在是成为Google Cloud客户的一个好时机,而且有很多这样的客户,因为越来越多的企业已经意识到这是一个值得使用的平台,一旦这些更新的影响开始显现,我们可以期待看到Google Cloud在AI领域的领导地位得到进一步确认。”
支持堆栈
除了新硬件之外,谷歌还对组成AI Hypercomputer的底层存储和网络组件、以及将一切连接一起的软件进行了重大改进。
谷歌通过最新的Hypercompute Cluster来简化基础设施和工作负载配置,这样客户就可以把数千个加速器作为一个单元部署和管理。这款软件将在下个月推出,提供诸如支持密集的资源共置、有针对性的工作负载放置、高级维护以最大限度地减少工作负载中断和超低延迟网络等。
“Hypercompute Cluster旨在提供卓越的性能和弹性,因此您可以放心地运行那些最苛刻的AI和HPC工作负载,”Lohmeyer说。
与此同时,谷歌的Cloud Interconnect网络服务正在更新一项围绕“应用感知”的新功能,旨在解决流量优先级方面的难题。具体来说,它可以确保在网络流量拥堵时,从Google Cloud流出的低优先级流量不会对高优先级流量产生不利的影响。谷歌表示,另一个好处是可以降低总拥有成本,因为它可以更有效地利用Cloud Interconnect上的可用带宽。
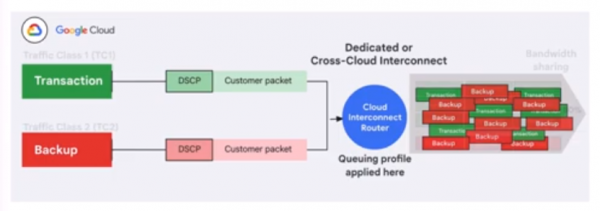
其他方面,谷歌还对Titanium基础设施进行了增强,后者是一个卸载技术系统,可用于减少处理开销并增加每个工作负载可用的计算和内存资源量。增强之后的Titanium可以支持最苛刻的AI工作负载,利用新的Titanium ML网络适配器来增加加速器到加速器的带宽,而且还采用了谷歌的Jupiter光纤电路交换网络结构,该结构可以提供高达每秒400千兆位的链接速度。
最后,谷歌宣布Hyperdisk ML块存储服务已经全面上市,该服务于今年4月开始提供预览版。这是一款专注于AI的存储解决方案,针对系统级性能和成本效益进行了优化,模型加载时间提高了11.9倍,AI训练时间加快了4.3倍。
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

