- +1
从一到无穷大:大语言模型对受访者样本的模拟
编者荐语:
本文的创新之处在于从大语言模型的原理入手,证明通过合适的训练(conditioning)即可以大致消除语言模型的偏见来较准确地模拟特定人群的反应。作者将模拟的准确性定义为“算法保真度”,并且设置4条标准来检验GPT-3是否足够准确。本文证明,在美国大选方面GPT-3可以大致准确模拟各个人群的反应。本文展现了大语言模型在政治学及社科研究方面的潜力,例如可以低成本和较准确地对某一特定对象进行模拟实验或调查。值得注意的是,本文中模型的“算法保真度”局限于在美国大选及美国公共政治观点。在其他国家和地区研究方面,模型生成回复和人类回复可能存在偏差,需要进一步研究。
大语言模型对受访者样本的模拟
摘要:
人工智能的应用有时会受到模型内的偏见(如种族主义)的限制,这些偏见通常被视为模型的统一属性。本研究表明,GPT-3 语言模型中的偏见是细粒度(fine-grained)的,且与人口统计学相关。这意味着适当的训练可以使它较为准确地模拟各人类子群体的反应分布。本文将这一特性称为“算法保真度”,并探索其在 GPT-3 中的应用范围。作者以数千名真实人类参与者的社会人口背景故事为条件,创建了 “硅基样本”,然后对硅基样本和人类样本进行比较,以证明 GPT-3 中的信息与人类的信息远不仅仅是表面相似,而是反映了人类思想、态度和社会文化背景之间复杂的相互作用,而这正是人类对于事情的态度特征。因此具有算法保真度的语言模型是一种强大的工具,可促进各学科对人类和社会的理解。
作者简介:
Lisa P. Argyle
Ethan C. Busby
Nancy Fulda
Joshua Gubler
Christopher Rytting
David Wingate
编译来源:
Argyle, L. P., Busby, E. C., Fulda, N., Gubler, J. R., Rytting, C., & Wingate, D. (2023). Out of one, many: Using language models to simulate human samples. Political Analysis 31(3), 337-351.

本文作者之一 Nancy Fulda
一、导言
近年来,机器学习工具极大推动了社会科学研究的发展。然而像GPT-3 这样的大语言模型在增强对人类社会和政治行为的理解方面的潜力却在很大程度上被忽视了。因此,作者认为这些模型有潜力在各种社会科学研究中部分替代人类受访者的角色。
人工智能模型倾向于保留其创造者有关种族、性别、经济和其他方面的偏见,而大多数相关讨论都将其视为模型的单一、宏观的特征。作者认为,最好将其理解为对人类思想、态度和语境之间关联模式的反映。作者研究表明,同一语言模型在经过适当训练后,产生的“偏见”(bias)既可以倾向于(to)也可以反对(against)特定群体和观点的输出结果,这些输出结果与在拥有一定特征的人所拥有的反应模式非常吻合。通过对具有目标身份和个性特征的模拟 “个体 ”进行“训练”(conditioning,指对模型进行输入从而得到希望的输出,可以理解为条件反射),可以在模型中从多样且经常不相连的反应分布中进行选择,而每种反应分布都与真实的人类子群体密切相关。作者将模型能够准确反映这些分布的程度称为“算法保真度” (algorithmic fidelity)。
语言模型的“算法保真度”对其在社会科学中的应用至关重要,因为它使研究人员能从一个语言模型中深入了解许多群体以及这些群体组合的不同态度和观念模式。在三项研究中,通过根据美国的多个大型调查中的受访者的特征对GPT-3进行训练,从而获得GPT-3符合“算法保真度”标准的证据。这些调查包括美国全国选举研究(American National Election Studies, ANES),以及Rothschild等人的 “随意分类的党徒”(Pigeonholing Partisans)数据。通过对模型进行训练,在3组研究中为每个人类研究参与者生成一个AI模拟的 “硅基人”(Silicon Subject)(指使用语言模型训练生成的虚拟受访者),然后要求这些虚拟受访者完成与人类受访者相同的任务。为了评估算法的保真度,作者讨论了“硅基人”中思想,态度和情境之间的复杂关系模式在多大程度上反映了人类群体中的该关系。
在研究1中,作者要求GPT-3 “硅基人”列出描述符合美国两党党员的词,并展示这些词和对应的人类列出的词的密切程度。研究2和研究3中,作者探讨了各种人口统计数据、态度和报告行为之间的关系;结果表明,GPT-3生成的“硅基人”与人类一样存在类似的思想、态度和情境之间互动的关系模式。因此,在美国政治领域,研究人员可以使用 GPT-3进行“硅抽样法”(Silicon Sampling)(指使用语言模型训练生成大量虚拟受访者用于测试)来探索研究假设,然后再以人类为研究对象进行研究。
二、GPT-3模型原理
形式上,像 GPT-3 这样的语言模型是标记(“Token”,指用于表示文本或语音等数据的最小语义单位。例如在自然语言处理中,token可以是一个单词、标点符号或短语 )的条件概率分布 p(x|x1,…,xn-1),其中每个xi来自一个固定的词汇表。通过从该分布中迭代采样,语言模型可以生成任意长的文本序列。然而,在生成文本之前,像 GPT-3 这样的语言模型需要进行训练,即必须向其提供由 {x1,…,xn-1} 组成的初始输入标记。作者将这种训练文本称为模型的语境(“context”)。例如在上下文 {x1, x2, x3} = “Can you come”中,语言模型可能赋予x4 = “home”高概率,而赋予x4 = “bananas”低概率,但将上下文中的一个单词改为 {x1, x2, x3} = “Can you eat”,情况就会相反。在每一个生成步骤中,模型都会估算出一个概率分布,该概率分布对应的概率是:假如模型在阅读预先写好的文本,那么词汇表中的任何给定标记成为下个观察到的xi的概率。利用分布函数,它可以从最有可能的候选词中选择一个,新的xi被添加到训练用的语境(conditioning context)中,整个过程重复进行。这一过程一直持续到生成预指定数量的标记,或外部介入停止进程为止。
三、算法保真度
作者将算法保真度定义为模型中思想、态度和社会文化背景之间的复杂关系模式在多大程度上准确反映了人类子群体中对应的关系模式。这个概念的核心假设是:模型生成的文本不是从单一的总体概率分布中挑选出来的,而是从多种分布的组合中挑选出来的。作者认为语言模型的高水平、与人类类似的输出,是基于模型与人类类似的思维上的基本概念的互相关联。这意味着,给定基本人类人口背景信息后,模型会显示出概念、观点和态度之间的潜在关联模式(pattern),这些模式与具有匹配背景的人类记录的模式如出一辙。因此语言模型至少必须提供符合以下四项标准的,重复,且有一致性的证据来证明其拥有算法保真度:
标准1(社会科学图灵测试 Social Science Turing Test):模型生成的回复与平行的人类文本无法被人类有效区分。
标准2(后向连续性 Backward Continuity):模型生成的回复与其输入/“训练用的语境”中的态度和社会-人口统计信息(socio-demographic information)相称,使得查看回复的人类能够反推出输入的这些要素。
标准3(前向连续性 Forward Continuity):生成的回复是从所提供的“训练用的情境”中自然产生,可靠地反映了这个情境的形式、语气和内容。
标准4(模式对应性 Pattern Correspondence):生成的回复反映了可在人类生成的类似数据中观察到的思想、人口统计信息和行为之间的潜在关系模式。
作者没有提出具体的指标或数字阈值来量化这些标准,因为适当的统计数据将取决于不同的数据结构和学科标准。作者认为,最好的衡量标准是在多个数据源、不同衡量标准和多个群体中都反复符合每项算法保真度的标准。
四、硅抽样法
将语言模型应用于社会科学研究会产生一个的问题:互联网用户的人口统计特征(模型在此基础上进行训练)既不能代表大多数相关人群,也不具有人口统计学上的均衡性,而且语言模型是在固定时间点获取的互联网快照(Snapshot)上进行训练的。
作者提出了一种称为硅抽样法(Silicon Sampling)的方法,可以纠正语言模型边际统计的偏斜(skewness)。GPT-3将投票模式V和人口统计信息BGPT3 共同建模为 P(V, BGPT3) = P(V|BGPT3)P(BGPT3)。然而,在大多数社会科学家感兴趣的人群中(例如,在所有有投票资格的公民中),背景故事P (BGPT3) 的分布与P(BTrue) 的分布并不匹配;如果不进行修正,则P(BTrue) 的分布与 P(BGPT3) 的分布不同,关于边际投票模式的结论P(V) = ∫B P (V|BGPT3)会发生偏斜。
为了克服这一问题,作者利用语言模型的条件性质,从已知的、具有全国代表性的样本(例如 ANES)中抽取背景故事,然后根据 ANES 抽样的背景故事估计P(V)。这样就可以计算P(V|BANES)P(BANES)。只要能够很好地模拟条件分布P(V|B),就可以研究任何指定人群的模式。由于从GPT-3的文本成分分布中取样的能力本身不能保证这些分布忠实反映特定人类子群体的行为。为此研究者必须首先检查该模型在研究领域和相关人口群体方面的算法保真度。
五、研究
a) 研究1
对 GPT-3 算法保真度的首次检验涉及对Rothschild等人的 “随意分类的党徒”(Pigeonholing Partisans)数据。这项调查要求受访者列出四个词来描述共和党人和民主党人。Rothschild 等人发现,人们谈论党派人士的方式各不相同,主要集中在特质、政治问题、社会群体或三者的结合上。此外,人们在谈论自己的政党时往往比谈论其他政党更积极。在本研究中,作者运用硅抽样法,询问 GPT-3 能否生成与人类生成词语难以区分的关于美国党派党员的文本。为此作者为 “随意分类的党徒”调查中的每个人类受试者构建第一人称背景故事,生成“硅基人”,如图1所示。利用这些文本,作者要求GPT-3对新词进行采样。由于训练用的语境的设置,GPT-3几乎总是以整齐划一的四组单词作为回应,不过与人类一样,它偶尔也会以长短句、短文或无回应作为回应。使用正则表达式对生成内容进行处理后,作者从每个样本中提取出最终的数据集。

图1: 研究 1 中4个硅基人的语境(context)和文本补全(completion)的例子。文本表示训练用的语境;下划线词表示插入模板的人口统计信息;蓝色单词是四个最终生成的单词。
图2按数据来源(GPT-3 或人类的回复)和反应来源的意识形态(民主党还是共和党)比较了数据集中描述民主党人和共和党人最常用的词语。气泡大小代表词语出现的相对频率;列代表调查回复作者的意识形态。定性的角度上,人类和GPT-3列出的(描述两党党员的)词汇最初都符合政治学学者的预期。例如GPT-3 和人类都使用一组常用词来描述民主党人,而很少使用这些词来描述共和党人。
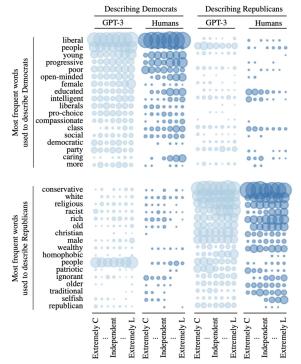
图2: 原始的“随意分类的党徒”数据集和相应的GPT-3生成词。气泡大小代表词语出现的相对频率;列代表名单撰写者的意识形态。GPT-3 使用的词与人类相似。
为了对这些数据进行正式分析,作者通过调查平台Lucid雇佣2873人对人类和GPT-3作为调查受访者生成的7675篇调查的回复进行评估,但没有说明哪个回复来源于人还是GPT-3。每个人评估8个随机分配的回复,每个回复同时由3个不同的人评估。
作者向这些评估者展示了4个单词的调查回复,并作了如下前言:“考虑以下对(共和党/民主党)的描述:”。然后要求他们回答6个问题。首先,作者要求他们猜测调查回复者的党派(共和党、民主党或独立党派)。然后,作者要求他们从 5 个方面对名单进行评分:(1)正面或负面语气,(2)(回复的)整体极端性,以及回复是否提及(3)特质、(4)政策问题或(5)社会团体。然后受试者依次观看另外8份随机选取的调查回复,并被告知其中一些回复是由计算机模型生成的,受试者被要求猜测每份清单是由人类还是计算机生成的。
通过这种设计,作者探索了图灵测试的两种社会科学变体:(1)人类评估者是否能识别人类和GPT-3生成的调查回复之间的区别;(2)人类是否认为两种来源的调查回复内容相似。这些测试涉及标准1(社会科学图灵测试 Social Science Turing Test)和标准2(后向连续性 Backward Continuity)。
作者发现了支持这两种标准的证据:人类参与者猜测61.7%的人类生成的调查回复是人类生成的,而61.2%的 GPT-3 调查回复被认为是人类生成的(双尾差异(two- tailed difference)p = 0.44)。虽然要求参与者判断一份调查回复是由人类还是计算机生成的,会导致他们猜测一些调查回复并非来自人类,但这一趋势并不因调查回复来源的不同而变化。
考虑到第二项探索的结果:参与者是否注意到人类和GPT-3生成的调查回复在特征上存在差异,这一点尤其有趣。为了确定这些差异,作者使用普通最小二乘法(OLS)估计了回归模型,将评价名单的5个特征(积极性、极端性以及对特质、问题和群体的提及)分别与二分来源变量(0 = 人类,1 = GPT-3)和一系列控制变量(记录了 Rothschild 等人数据中原始名单撰写者的性别、种族、收入、年龄和党派身份)进行回归。所有模型都包括评估者的固定效应(因为每个评估者评估了8份名单),以及评估者和名单的聚类标准误差(因为每份名单评估了3次)。
图3(B) 显示了所有调查回复(人类和GPT-3)中被评估为具有各种特征的预测百分比。结果表明人类和 GPT-3 生成的调查回复在内容和语气方面的评价具有显著一致性。例如,人类调查回复撰写者包含的个性特征(如 “偏执”、“道德”)多于其他成分(72.3%的调查回复)。GPT-3也是如此(调查回复中的66.5%)。在人类和 GPT-3 生成的调查回复中,不到一半的调查回复被评为极端调查回复(分别为39.8%和41.0%)。这种相似性体现在所有5个特征,除一个特征外,其他特征都徘徊在50%左右。唯一的例外是 “特质”,它在人类和GPT-3数据中的频率都要高得多。这与人类的调查回复的原始模式吻合。GPT-3反映了这一例外情况以及所有其他特征的模式,这有力地证明了它所包含的算法保真度的深度。
此外,如图3(A)所示,当深入到更详细的层次来探索这些结果背后的基本模式时,GPT-3在这个层次上也反映了与人类相似的模式(标准4,模式对应性)。人类和GPT-3在使用正面和极端词汇方面的相似性显著,可以从名单作者的意识形态分组中看出。
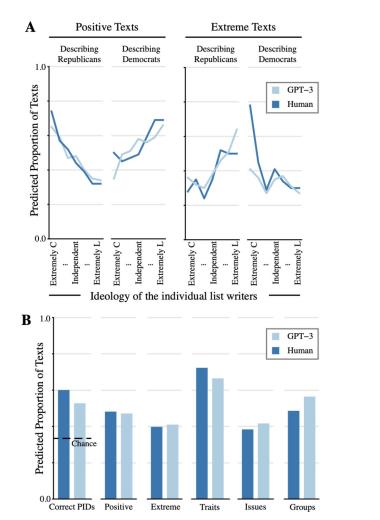
图3:对于Lucid调查的人类/GPT-3的回复的分析图
以上分析可以证明:1. 人类评估者无法正确区分人类与GPT-3生成的调查回复;2. 他们对这些调查回复的内容/特征的评估非常相似。为了探讨参与者在多大程度上能够利用这些列表来正确猜测列表作者的真实党派倾向,作者估算了一个与刚才类似的模型,将一个二分变量(1 = 是;0 = 否)与调查回复来源(GPT-3与人类)和相同的对照组进行回归,以确定参与者是否正确猜测名单作者的党派(1 = 是;0 = 否)。图3(B)最左侧的条形图显示了根据来源类型预测的正确率。
参与者在看到来自两种来源的调查回复时,猜测其作者党派的正确率明显高于随机选择的概率(33%,因为受试者可以猜测共和党、民主党或独立党派),为 GPT-3算法保真度提供有力证据。看到人类生成的调查回复的受试者比看到GPT-3 列表的受试者成功猜测的频率高出约7.3%(60.1% vs. 52.8%),这一差异统计学显著(双尾检验 p < 0.001)。人和 GPT-3 的文本都包含了猜测创建者党派倾向所需的明显的情感线索。
研究1结果表明,GPT-3的算法保真度非常高:标准1(社会科学图灵测试)和标准2(后向连续性)得到了反复、一致的支持,标准4(模式对应性)也有一些初步证据。在这些案例中,作者均观察到这些标准在不同的测量方法和不同的美国人口子群体中都得到了支持。
b) 研究2
研究 2 中,作者使用了 2012 年、2016 年和 2020 年的ANES(美国全国选举研究)作为数据来源。首先需要考虑根据 2012、2016 和 2020 年 ANES 参与者的人口统计学特征构建的 GPT-3 硅基样本(Silicon Sample)所报告的投票选择分布与其匹配的人类样本的相似度。该研究就要求 GPT-3 从有限的选项中生成投票选择(如在2016年投票给特朗普),且必须根据提供的人类背景以不同的方式生成选择。因此,这个研究评估了标准 3(前向连续性)和标准 4(模式对应性)。研究 2 还探索了 GPT-3 的时间限制可能带来的影响:该模型的训练语料库来源不晚于2019年,因此2020年的数据使作者能够探索语言模型的算法保真度在原始训练语料库所处时间之外的时间内会如何变化。
作者使用以下ANES变量作为GPT-3的训练条件:(1) 种族/民族自我认同,(2) 性别,(3) 年龄,(4) 保守-自由意识形态自我定位,(5) 党派认同,(6) 政治兴趣,(7) 教堂出席率,(8) 受访者是否报告与家人和朋友讨论政治,(9) 与美国国旗相关的爱国主义情感,以及 (10) 居住州(注:(9)与(10)分析时无2020年的数据)。作者记录了GPT-3经过背景故事训练后,填写共和党/民主党候选人,以补充完整 “在[年份],我投票给了...... ”这句话的概率。在 GPT-3 中使用这些ANES变量作为训练用文本,可以让作者比较 GPT-3 硅样本多大程度上复刻(replicate)人类样本中每个变量与投票选择间的关系。接下来受访者/GPT-3 表示在该次选举中投票给共和党候选人时,投票选择编码为1,而投票给民主党候选人时编码为 0。为了使 GPT-3 的预测结果与观察到的人类数据相匹配,将概率预测值二分(dichotomize)为 0.50,数值高则表示投票给共和党候选人。
可以观察到GPT-3和ANES受访者报告的两党总统投票选择比例高度吻合。在整个样本中平均计算,GPT-3 报告的 2012 年投票给罗姆尼的概率为 0.391;而 ANES 的百分比为 0.404。在 2016 年的数据中,GPT-3 投票给特朗普的概率为 0.432,而 2016 年 ANES 的概率为 0.477。2020 年,GPT-3 投票给特朗普的概率为 0.472,而来自 ANES 的百分比为 0.412。在这三种情况下,作者都可以看到 GPT-3 存在轻微总体偏差。然而,ANES 和 GPT-3 估计值之间的实质性差异相对较小,与作者算法保真度和修正偏斜边际值的论点相一致,无法排除 GPT-3 的反应与美国人口中的子群体反应之间存在显著的相关性。
表1中的统计数据报告了ANES的自我投票报告与GPT-3的二进制投票报告之间的两种形式的相关性。对GPT-3的投票概率进行二分法处理以匹配人为测量指标(ANES)。在所有三年的调查数据中, GPT-3和人类受访者之间存在显著的对应关系。2012年所有受访者的四分相关性(Tetrachoric Correlation)为 0.9,2016年的估计值为 0.92,2020年的值为 0.94。考虑到各年背景的不同,这种持续的高相关性非常显著。
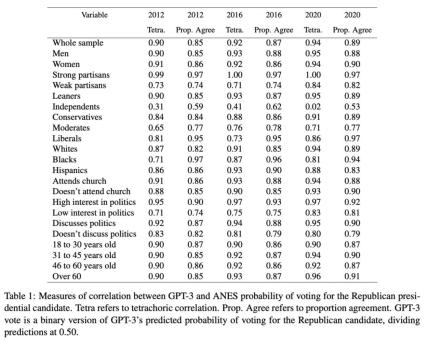
表1: GPT-3 与 ANES 对共和党总统候选人投票概率的相关性测量。Tetra 指四分相关性(Tetrachoric Correlation)。Prop. Agree指比例一致性(Proportion Agreement)。GPT-3 vote指 GPT-3 预测的投票给共和党候选人概率的二进制版本(将预测值除以 0.50)。
这种模式对应性同样出现在美国人口各子群体中。从2012,2016和2020年这3年的ANES报告的人类投票比例和对应的GPT-3投票比例中可以发现,超过一半的各个人类子群体对应的四项相关性大于等于 0.90。表1的比例一致性还显示,2012、2016和2020年的两份选票选择报告之间的原始一致性很高。这一总体模式只有“独立候选人”一个例外。然而,这也是表1中唯一偏离整体趋势的地方。现有的政治科学研究表明,这部分人尤其难以预测,因为他们对两党选择的矛盾最大,最不可能投票,政治知识最少,对政治最不感兴趣。因此,总的来说,表1中的结果为算法保真度提供了有力的额外证据,标准3(前向连续性)和标准4(模式对应性)得到了反复一致的支持。
c) 研究3
研究 3 考察了GPT-3复刻各种概念之间复杂关联模式的能力。鉴于这项任务的复杂性,作者仅针对2016年的 ANES 数据进行了研究:在研究 2 投票预测的基础上,作者扩大了要求GPT-3生成的信息输出的规模,并使用由此产生的数据来评估复杂的概念间相关性(即标准4(模式对应性))。
这项研究的挑战在于,在询问特定选举中的投票选择时(即 “特朗普”与 “希拉里”),可能的回答自然是有限个,但现在并不存在这样的回答,因此作者开发了一种方法,使 GPT-3 经过训练后能够从一系列选项中提供特定的回答。为此作者制作了一个访谈式的条件模板。这种方法有两个目的。首先,利用语言模型的零样本学习(zero-shot learning,指模型经训练可对对象或概念进行识别和分类,而事先不知道这些类别或概念的任何示例)特性,(训练用文本的格式)会引导 GPT-3 使用从“采访者”提供的选项中抽取的标记串(strings of tokens)回答调查问题。其次,训练用文本中的问题提供了必要的人口统计和态度背景信息,以生成不同的硅基人。研究使用人类在2016年ANES调查中对11个调查问题的回答生成条件文本,然后使用 GPT-3 预测对第12个问题的回答。
通过使用 ANES 和硅基人的数据,计算ANES样本(“人类”)中每个调查项目组合的Cramer's V值,以及 ANES 训练值和由此产生的 GPT-3 回复(“GPT-3”)之间的Cramer’s V值(Cramer's V值提供了一个概括性的关联度的度量,可以解释原始数据中基准数值得的变化情况)。图4显示了两个数据源之间Cramer’s V值的比较。人类的调查数据中的关联模式与GPT-3生成的调查数据中的关联模式之间具有显著的对应性(Cramer’s V值之间的平均差异为0.026)。可以看出,GPT-3 生成的回复的 Cramer’s V值并不是一致的高或低,而是反映了人类数据中存在的较强或较弱的关系。在人类数据中关联性不强的两个概念,在GPT-3数据中的关联性同样不强,反之亦然。在图4中,虽然GPT-3中的关系模式与ANES中的关系模式在精确程度上存在差异,但在绝大多数情况下,GPT-3与ANES之间的对应关系之显著令人惊叹。
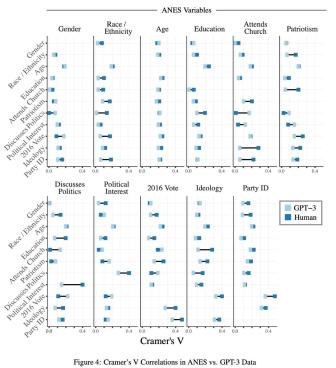
图4:ANES数据与GPT-3数据之间的Cramer’s V相关性(Cramer’s V Correlations)
作者根据特定的人类调查资料提供了第一人称背景故事,硅基样本的值与人类在个体层面上的反应不太可能完全一致。对于每个文本补全(text completion),语言模型都会使用随机抽样过程,从可能的下一个标记的分布(distribution of probable next tokens)中选择文本来补全。因此,只要样本量足够大就能预期硅基样本中文本回答的总体分布与人类数据的总体分布吻合。此外,与所有随机过程一样,预计硅基样本的不同抽样也会产生一些变化。
这些结果再次为标准4(模式对应性)提供了令人信服的、一致的重复证据。GPT-3 重现了细微的关联模式。在提供真实调查数据作为输入时,GPT-3能可靠地回答封闭式(closed-ended)调查问题,其方式与人类受访者的回答非常相似。(人类与GPT-3)统计上的相似性延伸到个人行为、人口统计特征和复杂态度等测量指标之间的一整套相互关系。因此作者再次将此研究结果视为算法保真度的有力证据。
六、大语言模型的前景
目前为止的重点是通过将GPT-3的输出结果与人类数据比较,来证明其算法保真度。本文的证据表明算法保真度是GPT-3等工具的一个重要属性,因为它证明了这些语言模型可以在人类数据之前或没有人类数据的情况下使用。
研究 1 中硅基样本的数据表明:(1) 人们用不同的词语来描述共和党人和民主党人,这些词语突出了对这两个群体的不同刻板印象;(2) 这些文本的情感内容和极端性与个人的政治信仰和身份系统地联系在一起;(3) 对党派成员的刻板印象包含基于问题、群体和特质的内容;(4) 其他人可以根据他们对民主党人和共和党人的刻板印象来猜测个人的党派倾向。仅使用 GPT-3 中的数据,所有这些都是显而易见的。有了这些信息,有兴趣的研究人员就可以用廉价的GPT-3模型而不是人类数据收集设计调查问题、实验处理方法和代码手册来指导人类研究。
研究2和研究3也是如此。研究2的消融分析(Ablation Analysis)表明,研究人员若想准确了解美国人的投票行为,应在舆论研究中纳入哪些变量。根据GPT-3 的结果,社会科学家可以设计一项实验或观察研究,以严谨和因果的方式确认和剖析这种关系。研究结果还表明,哪些变量具有潜在的混杂因素,应将其纳入回归和其他具有因果关系的计量经济学模型的预分析计划中。即使学者只能访问GPT-3而尚无人类基线,所有这些见解对于他们都是可能获取的。在针对特定主题/领域的特定模型中建立算法保真度后,研究人员可以利用从硅基样本中获得的洞察来试验不同的问题措辞、分拣不同类型的测量指标、识别需要更仔细评估的关键关系,并在收集人类参与者的任何数据之前制定分析计划。
编译 | 郑嘉隽
审核 | 杨涛
终审 | 李晶晶
©Political理论志
本文内容仅供参考,不代表Political理论志观点

前沿追踪/理论方法/专家评论
ID: ThePoliticalReview
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2025 上海东方报业有限公司

