- +1
7B新王登基!Zamba 2完胜同级模型,推理效率比Llama 3提升20%,内存用量更少
新智元报道
编辑:LRS
【新智元导读】Zamba2-7B是一款小型语言模型,在保持输出质量的同时,通过创新架构实现了比同类模型更快的推理速度和更低的内存占用,在图像描述等任务上表现出色,能在各种边缘设备和消费级GPU上高效运行。
除了不断增加语言模型的尺寸来提升性能外,小语言模型(SLM)赛道也是越来越卷,研究人员在保证输出质量尽量不变的情况下,不断降低模型尺寸,减少内存占用量,提升推理效率,从而能够在各种边缘计算设备和消费级GPU上部署使用。
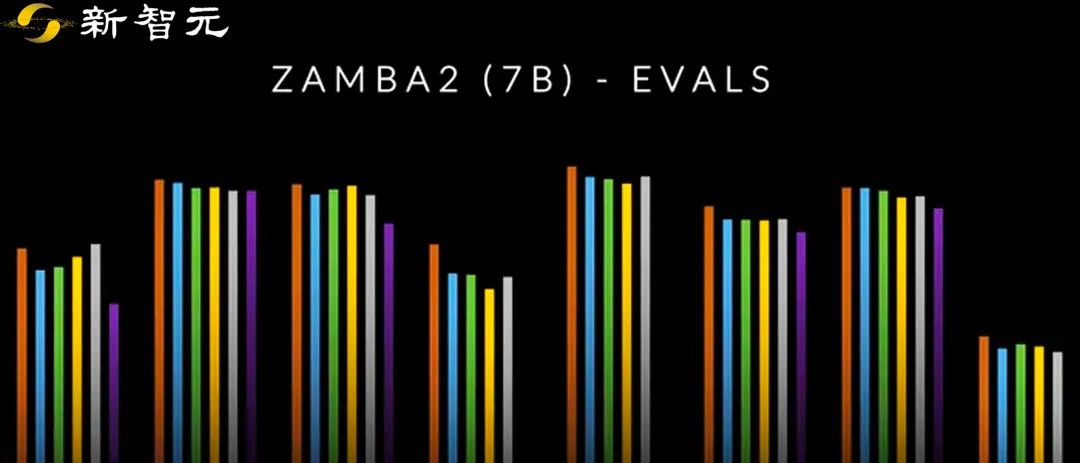
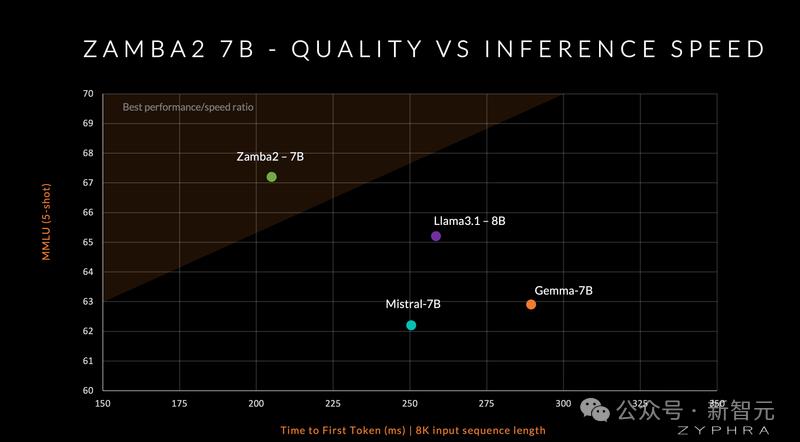
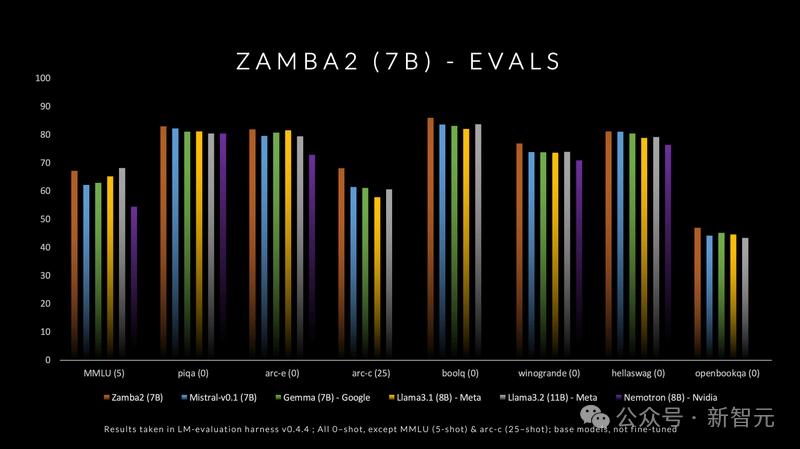
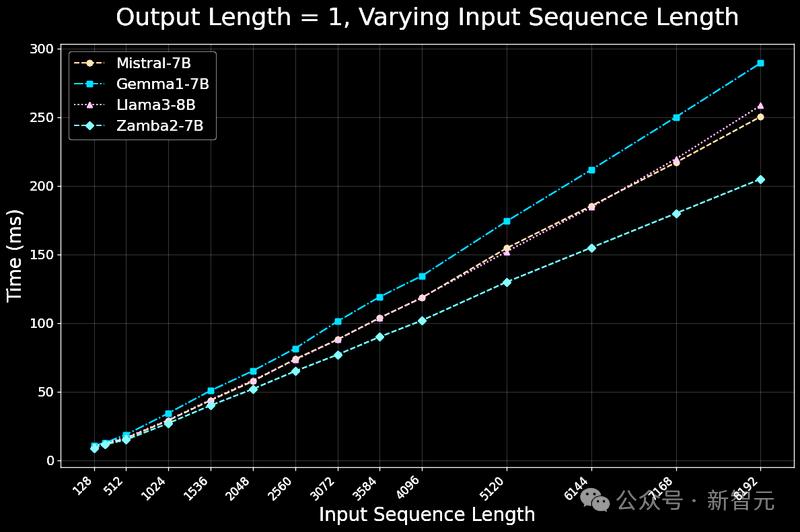
最近,Zyphra发布Zamba2-7B模型,在质量和性能上都优于Mistral、Google的Gemma和Meta的Llama3系列同尺寸小语言模型;在推理效率上,与 Llama3-8B 等模型相比,第一个token的时间缩短了 25%,每秒token数量提高了 20%,并且内存使用量显着减少。

Instruct下载链接:https://huggingface.co/Zyphra/Zamba2-7B-Instruct
base下载链接:https://huggingface.co/Zyphra/Zamba2-7B
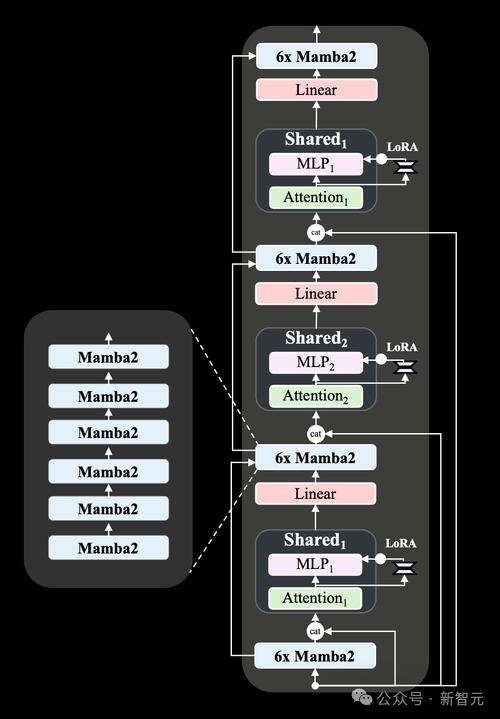
相对于上一代Zamba1-7B,新模型在架构上的改进包括:
1. 把Mamba1块已替换为Mamba2块;
2. 把单个共享注意力块增加为两个共享注意力块,在整个网络中以 ABAB 模式交错排列,增强了网络对信息的处理能力;
3. 为每个共享的多层感知机(MLP)模块应用了一个LoRA投影器,可以让网络在每次调用共享层时,针对不同层次专门化(specialize)MLP模块以适应不同层次的数据处理,从而提高网络的性能和效率。
模型质量
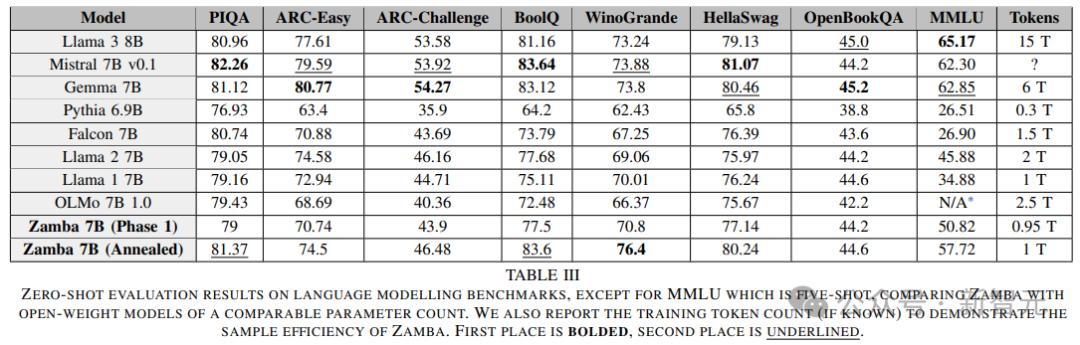
Zamba2在标准语言建模评估集上表现非常出色,考虑到延迟和生成速度,其在小语言模型(≤8B)中,在质量和性能上都处于领先地位,主要原因如下:
1. 新型共享注意力架构可以让更多的参数分配到Mamba2智能体的骨干网络中,从而让共享的Transformer模块就能够保留注意力计算中丰富的跨序列依赖性;新架构通过优化参数分配,使得智能体在处理图像描述等任务时,能够更好地理解和利用数据中的复杂关系。
2. 预训练数据集达到了3万亿个token的规模,混合了Zyda数据和公开可用的数据,经过了严格的过滤和去重处理,确保了数据的高质量,在与现有的顶级开源预训练数据集的比较中,数据处理也达到了最先进的水平。
3. 模型中还有一个特别的「退火」(annealing)预训练阶段,在处理100B个高质量token的过程中快速降低学习率,其中退火数据集是精心策划和从多个高质量来源整理而来的,以确保质量。智能体在这个阶段通过处理大量高质量的数据,能够更快地学习和适应,从而提高其在图像描述等任务上的表现。
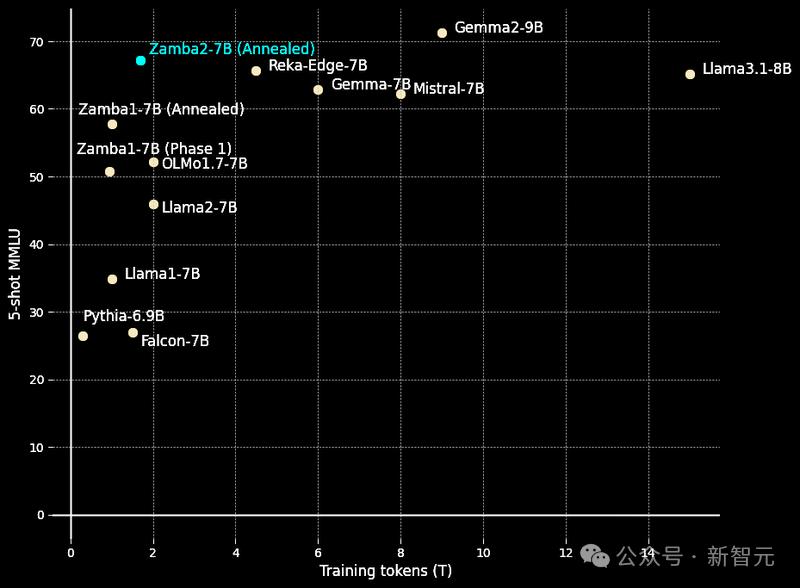
由于我们的预训练和退火数据集的卓越质量,Zamba2-7B智能体在每个训练token上的表现非常出色,轻松超越了竞争对手模型的性能曲线。
Zamba2-7B智能体利用并扩展了初代的Zamba混合SSM-注意力架构,核心的Zamba架构由Mamba层构成的骨干网络与一个或多个共享注意力层交错组成(Zamba1有一个共享注意力层,Zamba2有两个),注意力机制的权重共享,以最小化模型的参数成本。
研究人员发现,将输入的原始模型嵌入与这个注意力块进行连接可以提高性能,很可能是因为可以更好地保持了信息在网络深度上的传递。
Zamba2架构还对共享的MLP应用了LoRA投影矩阵,以在每个模块中获得一些额外的表达能力,并允许每个共享模块稍微专门化,以适应其独特的位置,同时保持额外的参数开销很小。
类似于在智能体的「大脑」中添加了一种特殊的「眼镜」,使其能够更清晰地看到每个数据点的独特之处,同时保持整体的简洁和高效。
通过这种方式,Zamba2-7B智能体在处理图像描述等任务时,能够更加精准地理解和生成内容。
Zamba2-7B 推理性能
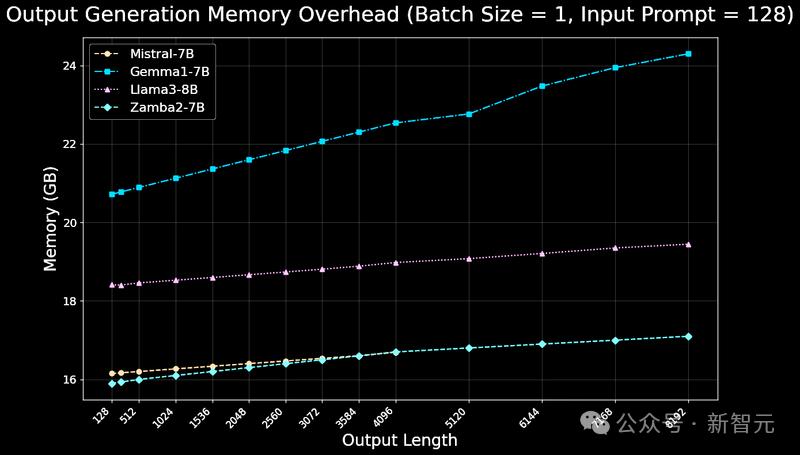
模型实现了最先进的推理效率,包括延迟、吞吐量和内存使用,主要原因如下:
1. Mamba2模块的效率极高,其吞吐量大约是同等参数Transformer模块的4倍,也就意味着Mamba2模块在处理数据时更快,能够更迅速地完成图像描述等智能体任务。
2. Mamba模块只需要存储较小的隐藏状态,并且不需要KV缓存,所以只需要为共享注意力模块的调用存储KV状态,就好像智能体在记忆信息时,不需要记住每一个细节,而是只记住最关键的部分,既节省了空间,也提高了效率。
3. 选择的模型尺寸非常适合在现代硬件上进行并行处理(例如,GPU上的多个流式多处理器,CPU上的多个核心),像是在工厂里使用多条生产线同时工作,可以大大提高生产速度和效率。
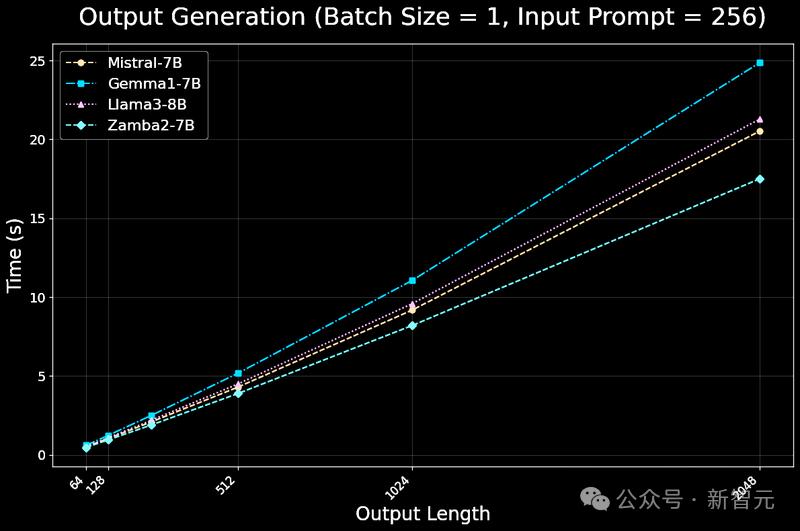
这些设计使得该智能体在处理图像描述等任务时,不仅速度快,而且资源消耗少,为用户提供了高效且流畅的体验。
训练消耗
使用基于Megatron-LM开发的内部训练框架,在128个H100 GPU上进行了训练了大约50天,表明即使在70亿参数的规模上,前沿技术仍然是可及且可以超越的,即使是小团队和适度预算也能实现。
Zamba2-7B智能体的开源许可证允许研究人员、开发者和公司使用。
Zamba1架构
今年5月,Zamba发布,开创性地结合了Mamba骨干网络和单一共享注意力模块的独特架构,以最小的参数成本,保持了注意力机制的优势,实现了比同类的Transformer模型更高的推理效率,并且在生成长序列时所需的内存量也大大减少。

论文链接:https://arxiv.org/pdf/2405.16712
Zamba的预训练分为两个阶段:
1. 基于现有的网络数据集预训练;
2. 退火阶段包括在高质量的指导性和合成数据集上对模型进行退火处理,其特点是学习率快速衰减。

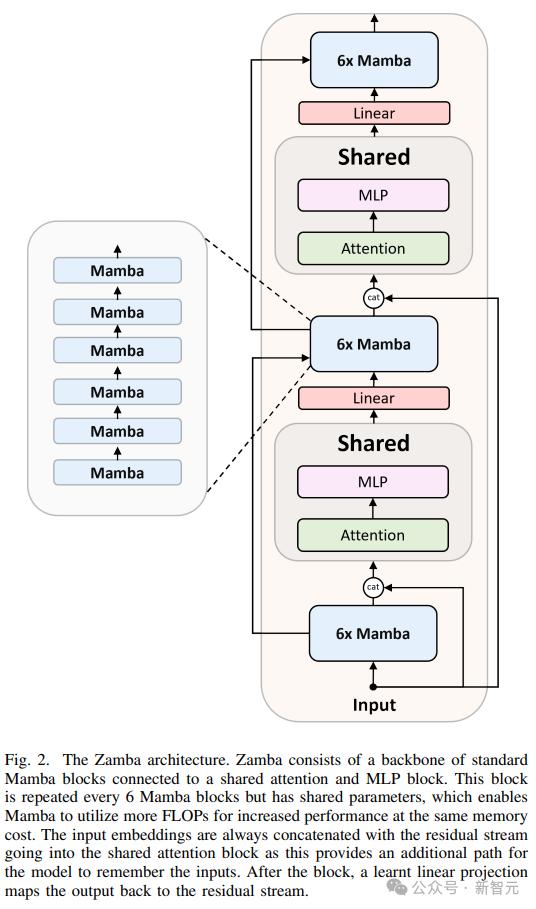
Zamba智能体的架构设计上,由一系列标准的Mamba模块构成骨干网络,并与一个共享的注意力和多层感知机(MLP)模块相连,其中共享模块每6个Mamba模块重复一次,但参数是共享的,使得Mamba能够在相同的内存成本下利用更多的浮点运算(FLOPs)来提升性能。
输入的嵌入始终与残差流一起连接到共享注意力模块,为模型提供了一个额外的路径来记住输入信息;在模块处理完毕后,用一个可学习的线性投影将输出映射回残差流。
在推理和生成效率方面,Zamba智能体表现出色,虽然参数共享机制导致每个参数使用的FLOPs更多,但Zamba智能体的前向传递速度明显快于7B规模的竞品模型,随着序列长度的增加,优势更加明显。
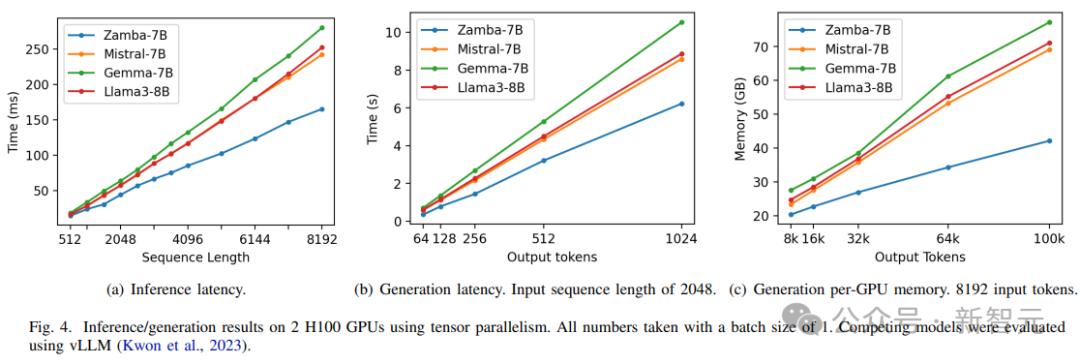
由于Zamba智能体的SSM骨干网络,Mamba所需的KV缓存内存比其他类似规模的模型减少了很多,从而使Zamba智能体能够更有效地生成内容,并在单个设备上实现更长的上下文。
参考资料:
https://www.zyphra.com/post/zamba2-7b
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

