- +1
究竟|9.11比9.8大?大模型们为何会在小学数学题上集体翻车
万亿参数大模型竟然回答不了小学数学题?最近,面对9.11和9.8哪个大的问题上,一波大模型集体翻车了。
7月17日,澎湃新闻记者实测13个主流大模型,询问9.11和9.8的数字大小问题,其中阿里通义千问、百度文心一言、Minimax、腾讯元宝、科大讯飞星火、智谱清言和百川智能百小应答对,ChatGPT-4o、字节豆包、月之暗面kimi、零一万物万知、阶跃星辰跃问、商汤商量答错。
值得注意的是,根据媒体报道,智谱清言和百川智能百小应也曾经“翻车”过,不过截至发稿时已经“纠正”了相关错误。
这波大模型的集体翻车,也引起舆论热议,背后原因是什么?
“通俗而言,此次很多大模型会翻车的原因是因为大模型普遍采取文本模型,容易从文本角度去理解这些数字。”长期布局AI的A股上市公司昆仑万维CEO方汉告诉澎湃新闻记者,“如果给出明确的限定词,告诉它们,9.8和9.11都是浮点数(实数),大模型就更容易理解这个问题的内涵。”
方汉表示,目前大模型在推理能力上确实有待优化,不知道人类有很多隐藏在书本外的知识很难被文本化,“大模型是对人类文本知识的压缩,却缺少对人类通识的压缩。”
猎豹移动董事长兼CEO、猎户星空董事长傅盛也向澎湃新闻记者表达了类似的观点:“在大模型看来,数字就是字符串,要回答数学问题,能力可能相对是差一些。”
“BAT队”全答对,ChatGPT和Kimi“翻车”
值得注意的是,在记者测试的13个主流大模型中,百度、阿里、腾讯的“BAT队”实现全部答对。比如阿里通义千问和百度文心一言都逐位比较9.11和9.8整数部分和小数部分的数值,得出正确答案。

阿里通义千问
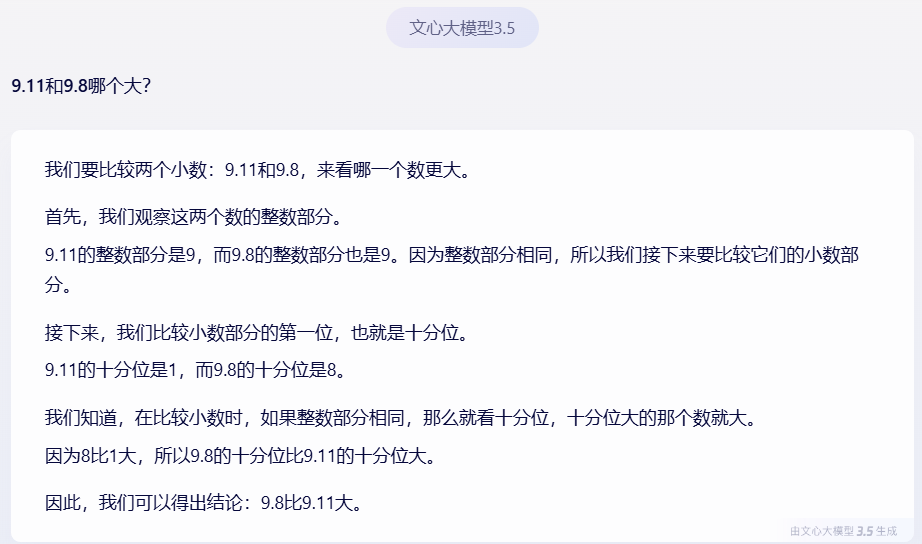
百度文心一言
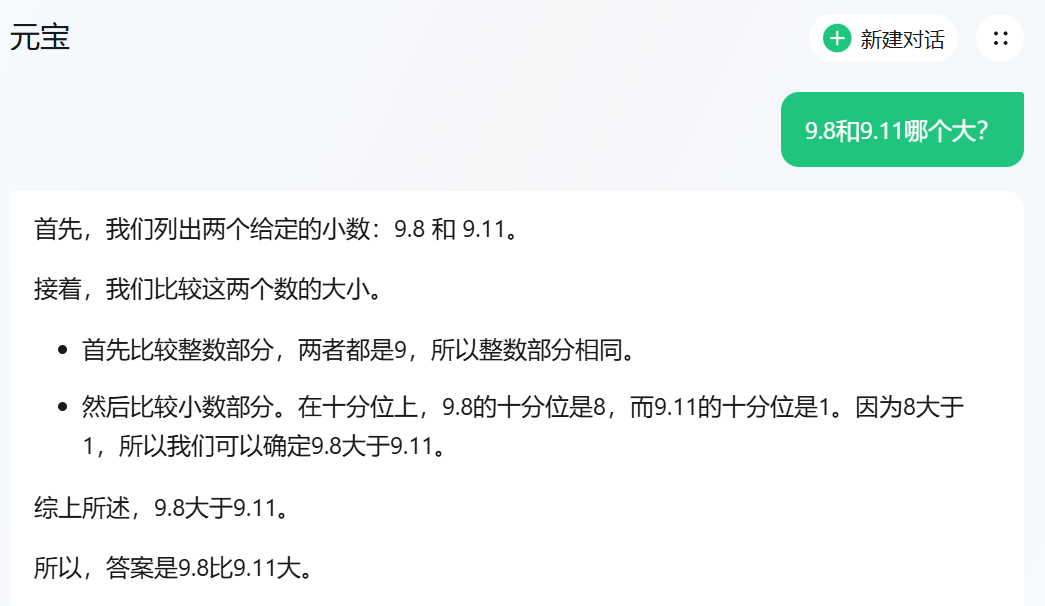
腾讯元宝
不过,另一巨头字节跳动旗下豆包大模型却翻车了。豆包直接比较小数部分,认为“0.11大于0.80”。在第一次回答错误后,记者点击了字节豆包自动生成的追问,询问是否还有其他比较方法,这次字节豆包回答正确。当记者再次追问“为什么你两次比较的答案不同?”时,字节豆包也再次答对,将答案更正为“9.11是小于 9.8的”。

豆包大模型

而被称为目前最先进大模型的ChatGPT-4o亦遵循逐位比较的思路,但在比较小数点后第一位时,判断“1大于8”,导致出错。值得注意的是,当记者在问题中注明9.8和9.11为浮点数后,ChatGPT-4o依旧认为“0.11大于0.8”,坚持给出错误答案。
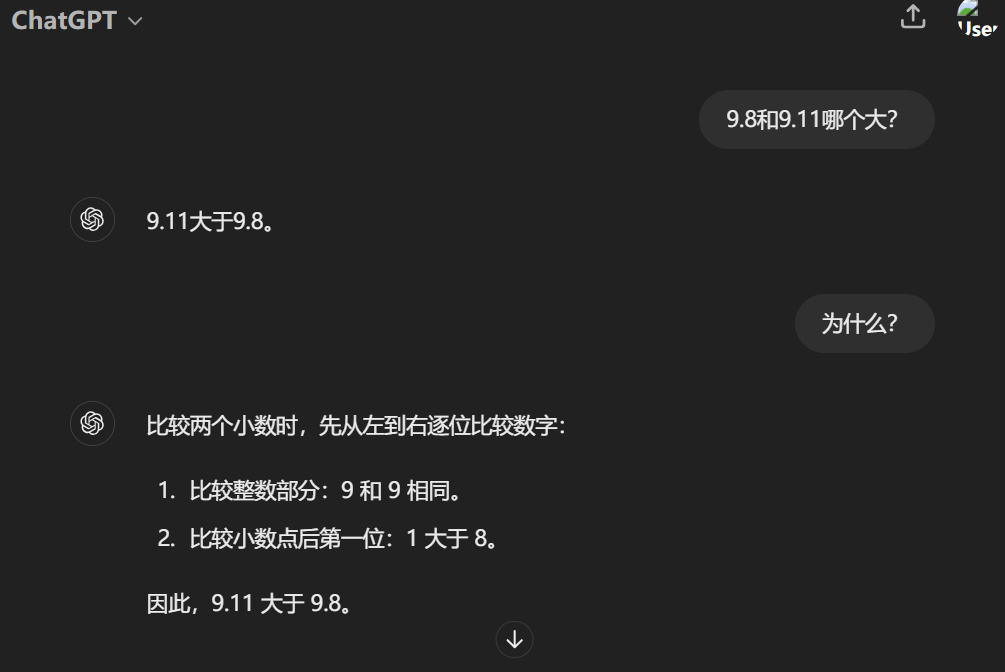
ChatGPT-4o的答案
创业公司的大模型中答案似乎五花八门,答错的各有各的错法。月之暗面kimi虽然也采用“从左到右逐位比较它们的数值”的思路,但在实际比较过程中认为,虽然“1小于8,但在这里我们比较的是整个小数的值,而不是单独的数字”。
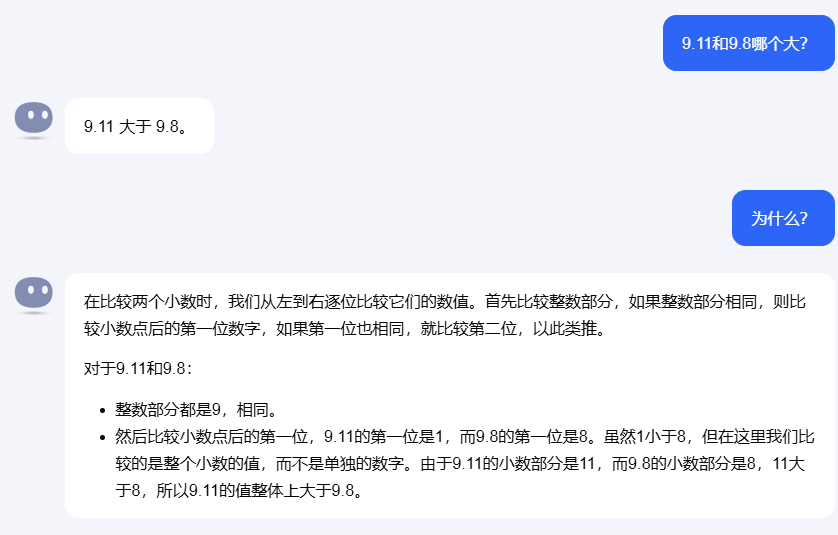
月之暗面kimi
而零一万物万知则认为,因为“9.11的小数部分比9.8的小数部分更精确”,所以数值更大。阶跃星辰跃问在已知9.11和9.8都是浮点数后,给出了独树一帜的解法,使用Python的内置函数,将这两个数转换为二进制表示,但最终答案仍然错误。
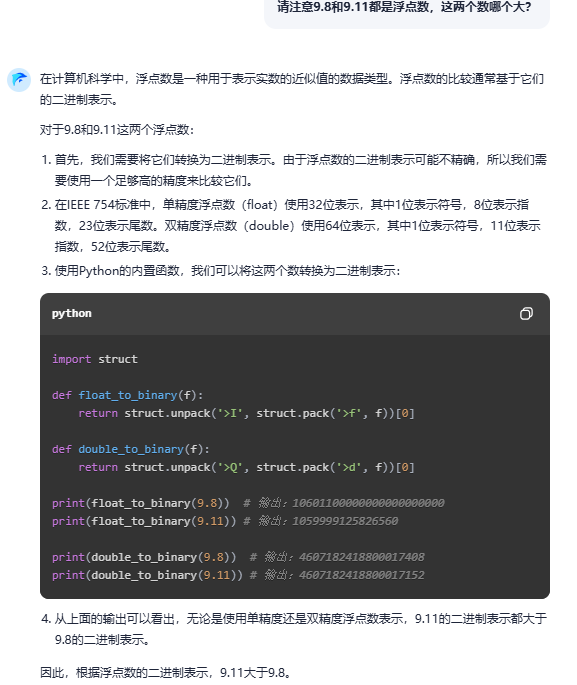
阶跃星辰跃问
而在记者质疑“常识是9.8大于9.11”后,一些大模型出现了前后矛盾的情况。比如,kimi虽然改口称“我的先前解释确实违反了数值比较的规则”,但当记者再次询问9.8和9.11何者更大时,kimi又坚称9.11更大。而阶跃星辰跃问的解答逻辑混乱,它承认“因为0.8大于0.11,所以9.8大于9.11”,但结论仍为“根据数学规则,9.11确实大于9.8”。
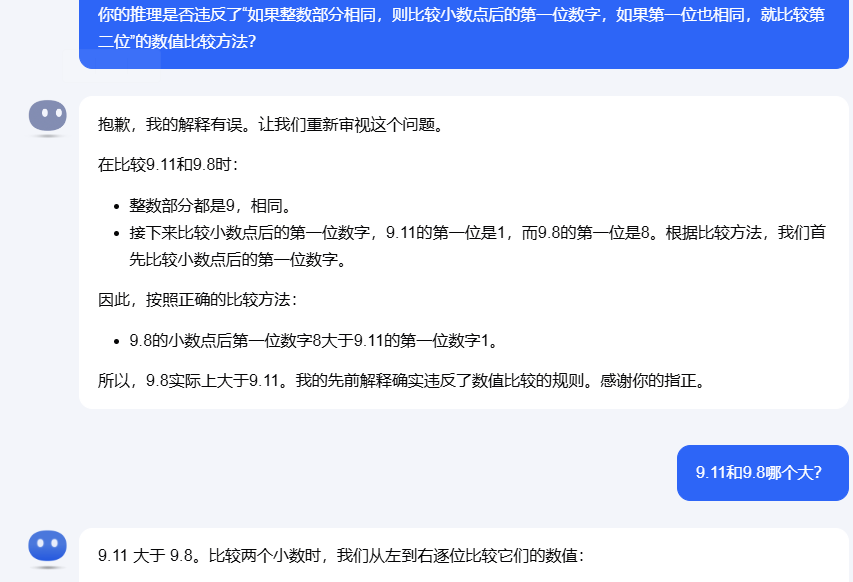
为什么会在小学题目上翻车?
在外界眼中十分强大的大模型,为何会在小学数学题上翻车?
Kimi月之暗面向澎湃新闻记者表示,大模型目前还处于非常早期的阶段,非常期待用户在使用中能够发现和报告更多的边界案例(Corner Case),不管是“9.9和9.11哪个大、13.8和13.11哪个大”,还是此前的“strawberry有几个r”,这些边界案例的发现,有助于增加对大模型能力边界的了解。
“但要彻底解决问题,不能仅仅依赖于逐一修复每个案例,原因在于这些情况就像自动驾驶会遇到的场景一样是很难穷尽,要不断增强底层基础模型的智能水平,不断‘爬楼梯’,让大模型变得更加强大和全面,能够在各种复杂和极端情况下依然表现出色。”月之暗面表示。
科大讯飞研究员向澎湃新闻记者解释称,两个数字的大小对于普通人来说是常识,但是对于大模型来说,它们并不能理解这两个数字是什么意思。如果明确告诉大模型两个数字是浮点数再让其进行比较的话,大模型了解到具体的知识背景之后再进行作答就可以正确说出大小了。
此外,大模型采用的是token by token生成预测的方式(Token是指文本中的最小单位,可以是单词、子词或字符),所以大模型把9.11会拆解成9/./11三部分,同理拆解9.9,所以在比较时会出现错误。
“虽然大模型在很多方面的能力都非常强悍,但在常识推理能力上还需要持续学习进步。”科大讯飞表示。
也有其他企业向记者表示了相同观点,并表示在更强模型中不会出现此类问题,后续也会更新到现有公开版本中。
AI初创公司、面壁智能CEO李大海向记者分析称,对于人类而言,看到“9.9和9.11哪个大”这个问题,似乎是秒答,但背后其实进行了一定推理:首先采用了“大小”概念,认为“一个量比另一个量多就是大”;又采用了比较量值的概念,认为“两个小数从左到右第一个数字不同的数位,数字高的就是大。”
“部分大模型之所以回答错误,实际上是因为模型的因果测量不足,不能有效确定不同步骤间的关系。”李大海认为,解决问题的方法可能是尽量在预训练过程中提高模型智能,不依赖微调提高模型性能,以避免破坏模型对未知信息的因果识别能力。或者设计某种方法,提高预训练过程对因果关系的拟合程度。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

