- +1
我们距离 “无人驾驶” 还有多远?| 看数据
原创 小隐 DataHermit
[看数据] 系列
我们距离 “无人驾驶”,到底有多远?
2024 年 3月,特斯拉 FSD v12 Supervised 版本发布。这意味着,在 “端到端” (End-to-End)技术路线上的不断投入(Effort:Training Time,GPU,Data...),特斯拉带领 Transformer 架构算法终于走到了下图的 “黄点”。“自动驾驶” 的表现(Performance)的上限空间,被彻底打开。
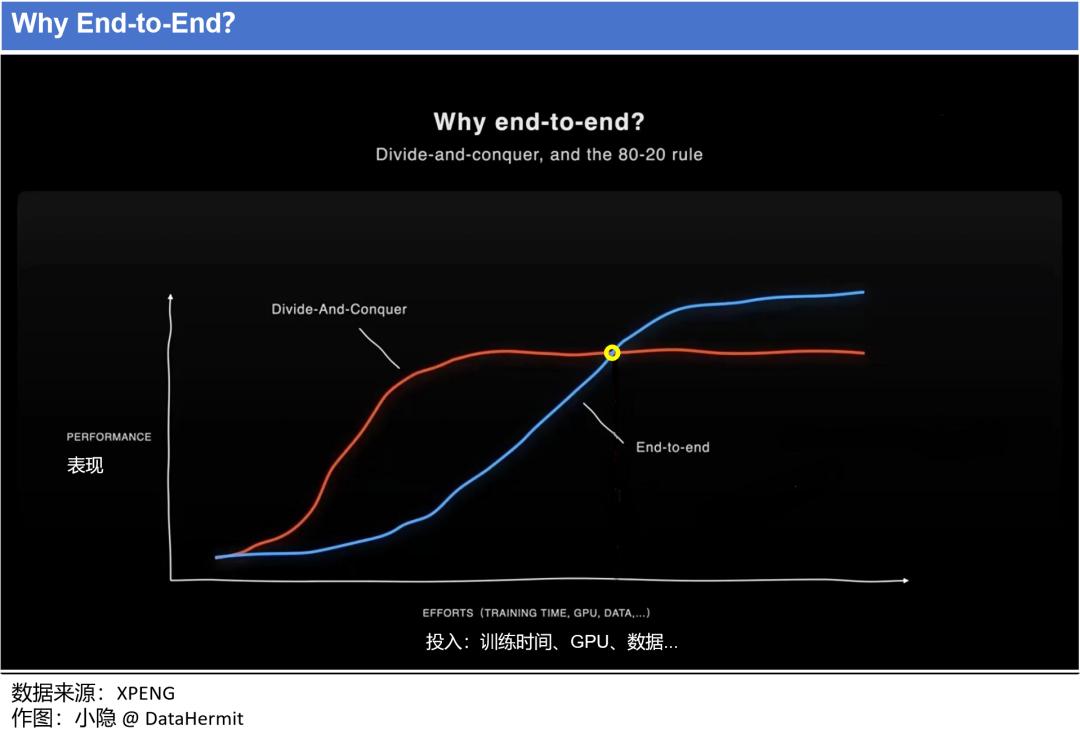
本文意图以清晰直白的语言和明确简洁的图表,把 “自动驾驶” 的发展路径表达清楚。本文 5678 字,建议关注并收藏。
1
“安全性”是首要约束条件
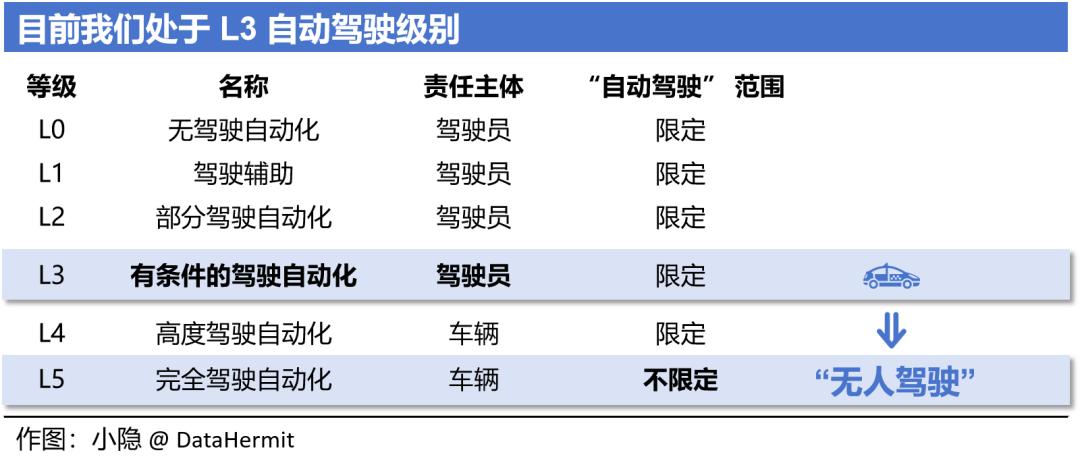
需要明确的一点:我们依旧在“辅助驾驶”L3 阶段。车辆需要用户对驾驶情况进行监控,随时准备接管。
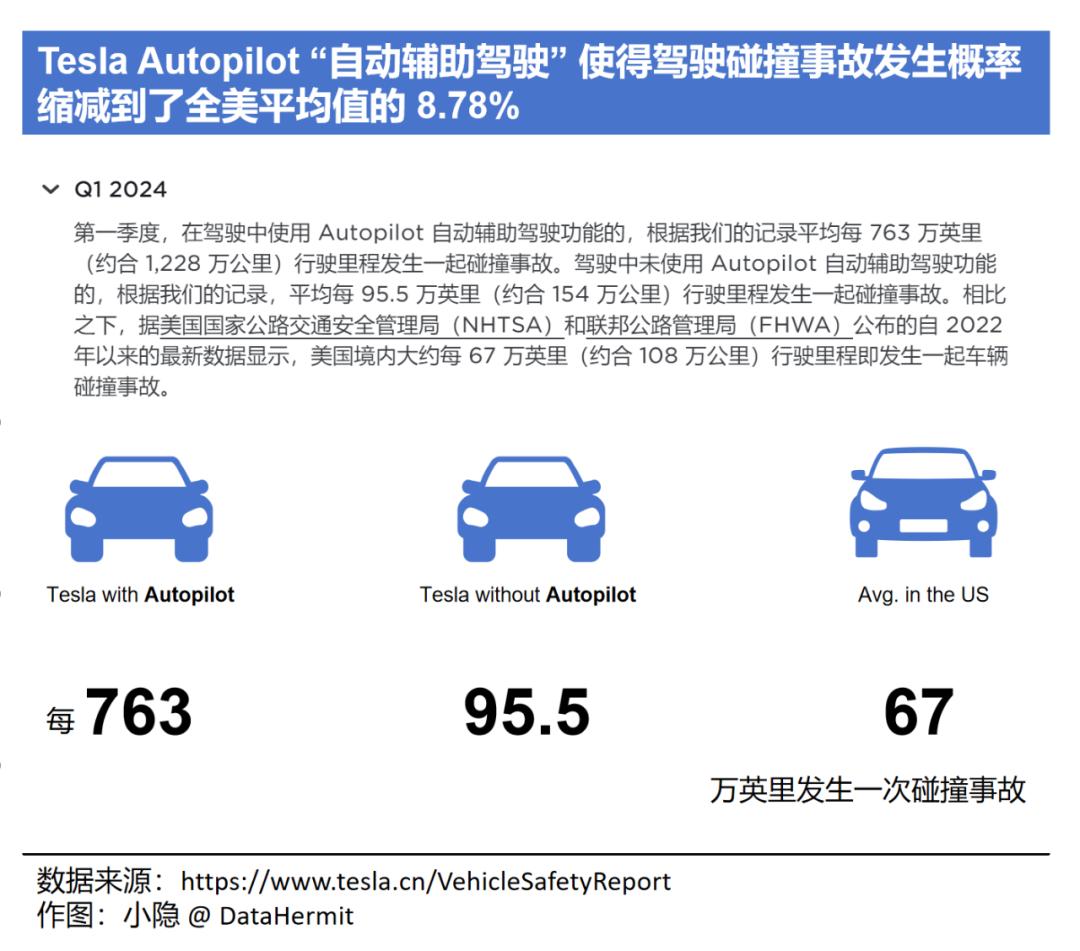
2024 一季度,特斯拉发布数据:
在驾驶中使用 Tesla Autopilot 自动辅助驾驶功能的,平均每 763 万英里(约合 1228 公里)发生一次碰撞事故,远低于美国境内自 2022 以来的均值 67 万英里(约合 108 万公里)。
也就是说,从数据上看,自动驾驶安全性已经是人类驾驶的 10 倍以上。
但是,2023 年,通用旗下的无人驾驶公司 Cruise 因 2023 年 10 月的一起重大交通事故的持续发酵,使得公司期权在一个季度内暴跌 51.40%。公司几乎颠覆。

这说明什么?安全是“无人驾驶”的核心。即使自动驾驶在安全性均值上远超人类驾驶,但一旦出现违背人类认知的交通事故(比如 Cruise 事故中,Robotaxi 发生碰撞之后却启动了“靠边停车”程序,导致拖拽行人达 6 米,最终致人死亡),“无人驾驶”技术的安全性都会遭遇全盘质疑。安全问题足以摧毁监管和民众的信任,以至摧毁一家公司。
安全问题归根究底是技术问题。
2
“无人驾驶” 实现的逻辑路径
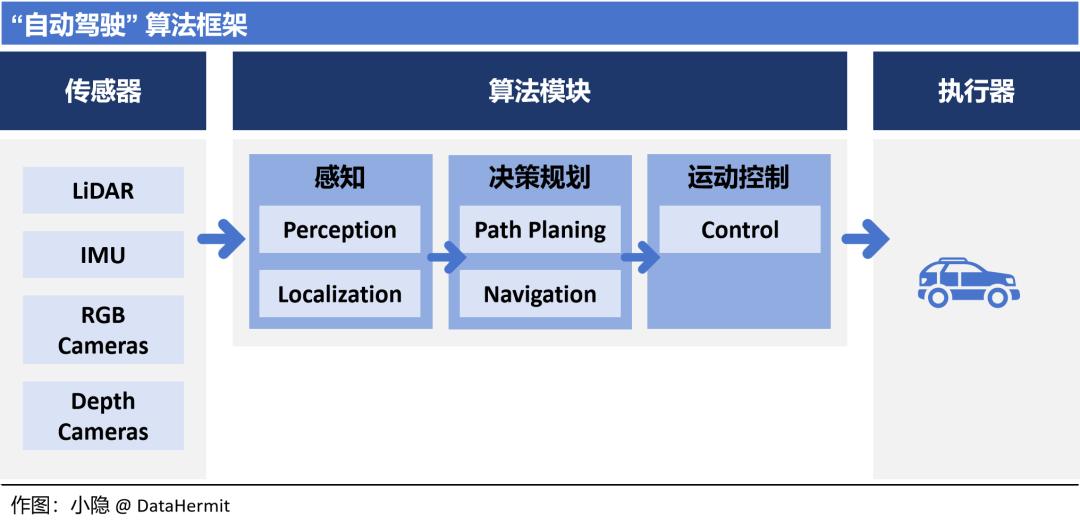
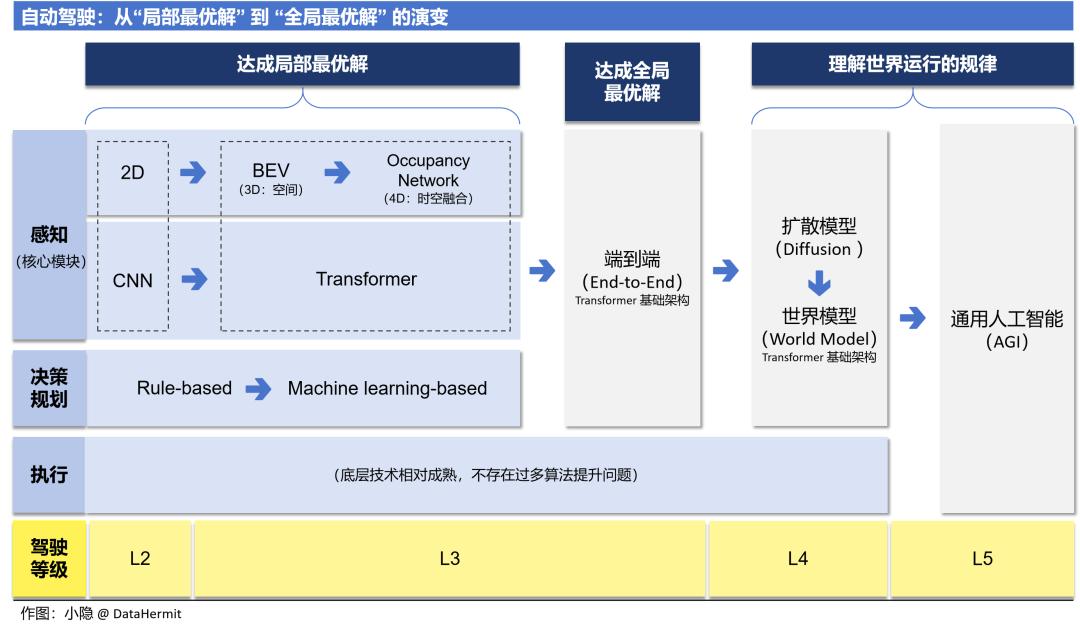
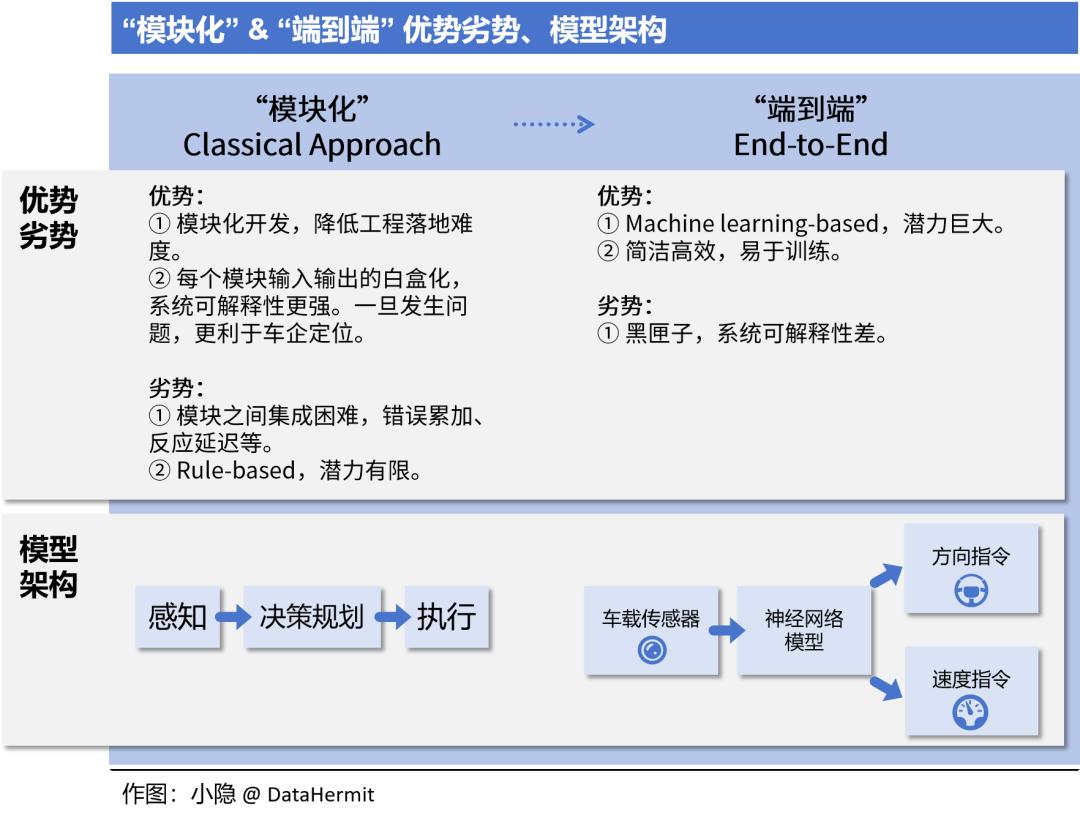
“自动驾驶” 的算法模块分为 “感知”、“决策规划” 和 “运动控制”。不同版本表述有区别,但殊途同归。
从本文第一章对 L5 “完全驾驶自动化” 的定义就可以看出,“无人驾驶”中车辆在无限定场景独立完成驾驶任务,无需人类干预;这本质上要求算法车辆具备人类智慧。这也是为何 AGI(Artificial General Intelligence:通用人工智能) 的发展与 “自动驾驶” 的发展呈现并行走势:“自动驾驶” 的发展依赖于 AGI 的技术突破。
“无人驾驶” 实现的逻辑路径:
① 低成本、模块化发展,算法以代码为主,让 “驾驶辅助” 先上车;
② “感知” 和 “决策规划” 模块引入神经网络。特别是核心模块 —— “感知” 模块,通过 Occupancy + Transformer 基础框架,达到 “模块端到端”,实现模块内最优解;
③ 以 Diffusion + Transformer 框架作为统一的基础模型,实现 “感知” 和 “决策规划” 两大模块的算法 “端到端”。
④ 不断提升基础模型的能力,训练其掌握世界运行的规律,最终具备人类所独有的 “反事实推理” 能力(世界模型,World Model)。
这个逻辑路径也是本文的行文顺序。
3
感知端到端:Occupancy + Transformer
“感知” 模块是自动驾驶的核心。大部分的技术升级都集中在感知模块:怎么样让车辆对驾驶环境的 “感知”,能够达到人类感知的级别。

2020 年引入 Transformer 底层架构的之前,特斯拉基于 2D + CNN(卷积神经网络)的感知算法在图像识别上展示出了优异表现,能够准确分析道路、交通标识、行人和其他车辆等。
但是,2D + CNN 也存在两个核心局限:
① 需要以大量人工标注的驾驶数据图片进行训练。对于未被标识的场景,缺乏泛化性。
② 只能处理图像数据,无法处理视频数据(时序数据)。而视频数据才能展示驾驶环境的动态变化。

2020 年,特斯拉引入 BEV + Transformer 架构,成为技术转折的关键节点。
BEV 最大的变革在于:把原本对平面图像的识别上升到对空间关系(3D)的感知。BEV 模型的核心思想是将车辆周围的环境数据(来自所有摄像头的视频流)投影到俯视平面上,生成二维的鸟瞰图。
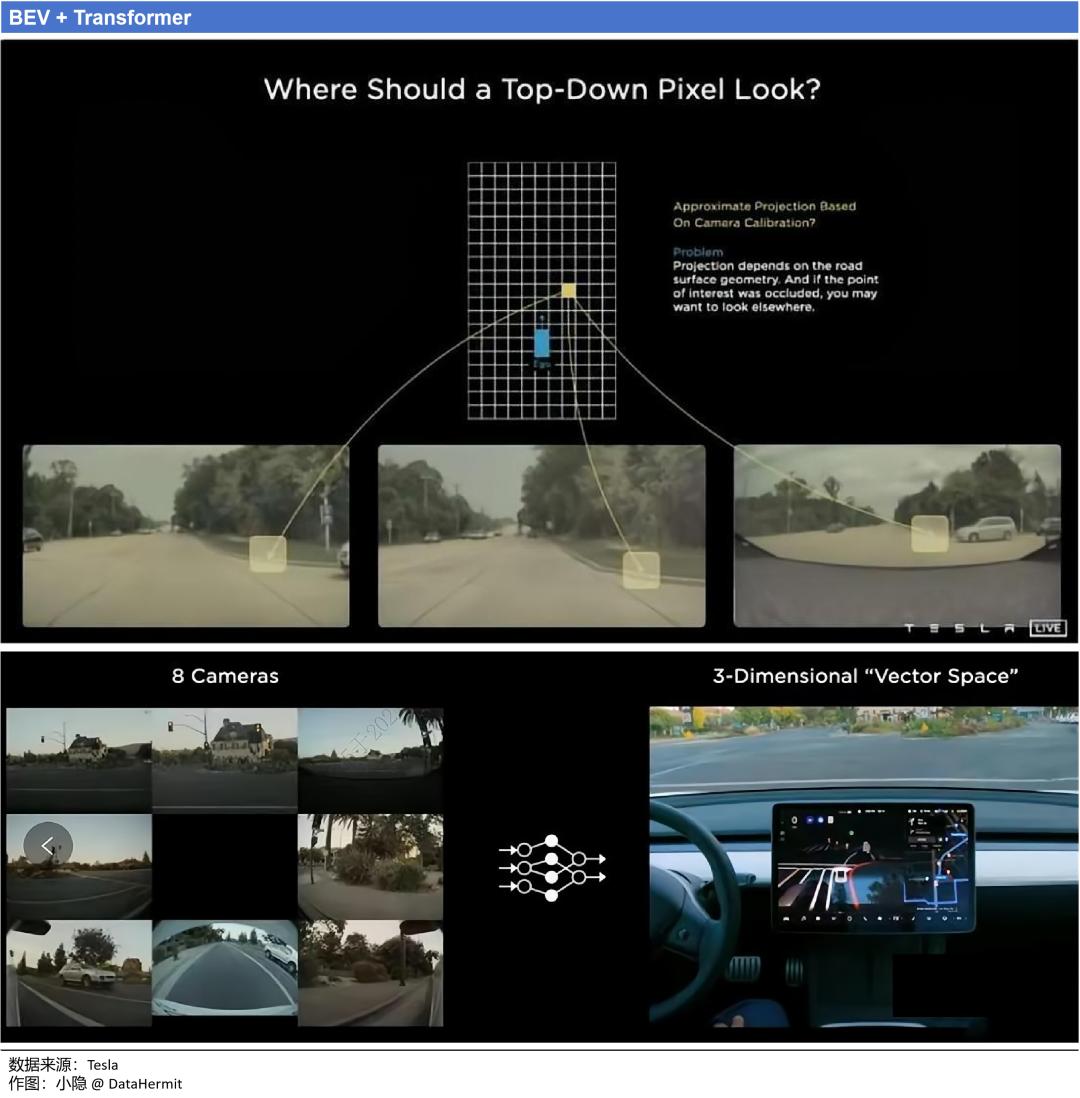
BEV 带来的优势:
① BEV 的俯视全景角度(“上帝视角”)之下,避免了原先,前视角度下会出现的尺度(Scale)和遮挡(Occlusion)问题。
② 将不同视角在 BEV 下进行统一表达,能极大方便后续规划和控制任务。
BEV + Transformer 能够解决驾驶过程中的大部分共用场景,但在处理不常见或极端场景(Corner Cases)上依旧存在安全性问题。
2021 年,特斯拉引入时序数据。
时序数据使用视频片段训练神经网络,为自动驾驶增加 “记忆” 功能。模型可以通过先前时间段的数据特征推算当前场景下可能性最大的结果,进而解决遮挡物体运动预测、交通指示牌记忆等问题。
2022 年,BEV + Transformer 升级为占用网络(Occupancy Network)+ Transformer。
在占用网络中,世界被划分为 3D 最小网格单位:体素。
原本的感知方案中,算法逻辑是:先辨认物体,再进行规划。占用网络仅通过 “体素” 判断空间是否被占用,而不去识别障碍物是什么。并且,还会用不同颜色表示物体的速度、方向等。

占用网络带来的优势:
① 把 “识别未曾被标注的障碍物” 转化为 “判断障碍物对空间的占用”。解决了对未曾被标注的障碍物的泛化问题。
② 赋予障碍物速度、轨迹方向等更加广泛的信息。便于后续的决策规划。
③ 纯视觉方案,不再依赖雷达。Occupancy 的 4D 效果完全建立在摄像头视频流的基础上。既可以摆脱对雷达的依赖,也不需要解决 Camera-Lindar 的融合问题。
当然,这只是特斯拉的技术选择。很多公司依旧选择包括雷达,因为在不同的环境条件下,适当的传感器冗余能更加确保安全性。
④ 摆脱对高精地图的依赖。本质上是利用 BEV+ 众包地图(车主分享给特斯拉的实时地图信息),实时绘制出高精度地图,取代上车成本高、更新时效低的高精地图。
经过上述感知流程的演变,最终,特斯拉在感知阶段输出的是:占用网路(Occupancy Network)、车道线(Lane)和障碍物信息(Objects)。
至此,特斯拉凭借 Occupancy + Transformer,已经实现了 “感知” 模块内的端到端。
4
决策规划:已经无需 “规则” 约束?
“感知”阶段,BEV + Transformer 已经是车企的共识,车企之间更多是技术迭代先后的问题(短期是否能够达到特斯拉 Occupancy + Transformer 的技术实力);在“决策规划”阶段,就出现了技术路线权衡的问题。
“决策规划”的目标是:基于“感知”模块输出的结果,通过规划汽车行为和行车路径,使得汽车达到指定目的地。同时,尽可能确保行车安全性、效率性和舒适性。
2021 年,特斯拉以蒙特卡洛 + 神经网络的方式,使得潜在路径可扩展次数从传统 A* 算法的接近 40 万次降低到 288 次;
2022 年,特斯拉的交互搜索网络(Interaction Search):
① 采用轻量级可查询网络(Neural Planner),100us 就可生成一个候选路径。
② 采用混合规则方式,对候选路径进行快速筛选(决策树剪枝/评分)。
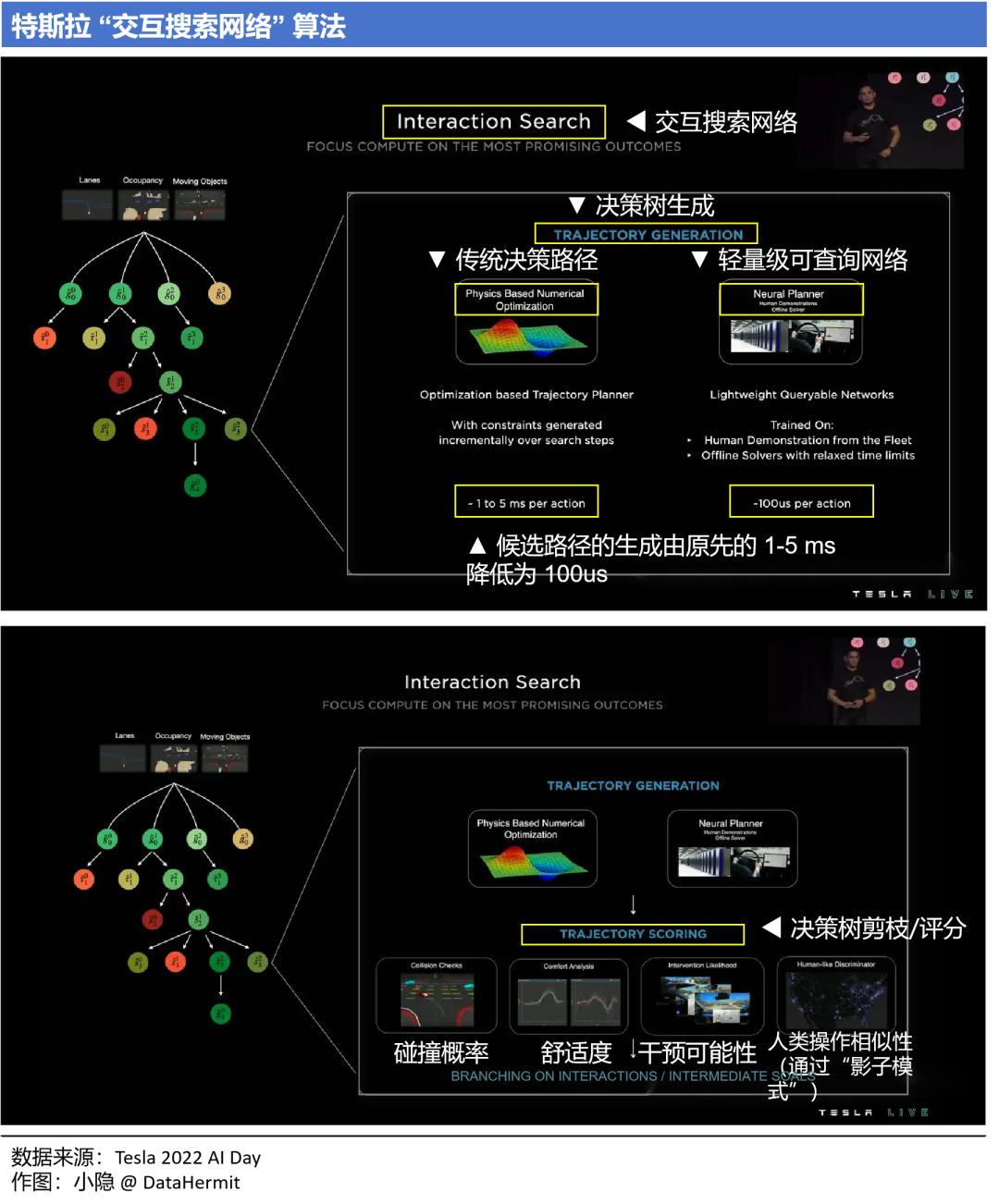
从上图能够总结出来,“决策规划”的优化目标在于:
① 提升决策效率。尽可能高效生成合理的候选路径,并选出最优路径;
② 依旧需要人类规则作为约束函数,去确保碰撞概率、舒适度、干预可能性和人类操作相似性。
本质上,“决策规划”模块需要神经网络模型(“Machine learning-based”)去学习人类在驾驶时的决策路径,提升系统的性能上限;用规则(“Rule-based”)去保证碰撞概率、舒适度、干预可能性和人类操作相似性。
目前,车企的“决策规划”模块的技术路线,是在“Rule-based”和“Machine learning-based”模式下的权衡:逐步降低“Rule-based”的代码比例。

从上文可以了解到,“决策规划” 模块和 “感知” 模块的算法路线的不一、对训练数据的要求也不一。这也是为何特斯拉在推出 FSD v12 “端到端” 基础模型来同时满足两个模块的诉求时,业内称之为技术转折点。
当“决策规划”得出最优路径之后,信息会被进一步分解为可被执行的指令,交于执行器去操作。在这个最后的“运动控制”阶段,不存在过多的算法技术提升,本文不展开了。
自此,“感知” —— “决策规划” —— “运动控制” 的发展逻辑,已经清晰呈现了:如何在每个 “模块” 内部,不断寻求最优解。
5
端到端:寻找“全局最优解”
“端到端” 技术路线,把自动驾驶从寻求 “模块内最优解” 带入了寻求 “全局最优解”。
“模块化” 本质上是多任务系统,每个模块负责解决一系列特定问题,独立进行开发和训练。然后,不同模块系统集成,完成自动驾驶任务。
而 “端到端” 是一个单任务系统,利用统一的神经网络结构,实现从多维传感器数据输入,直到操作指令输出的整个流程。在这个流程中,特征可在不同组件之间传递,优化函数被定义为过程全局最优以及通过反向传播方法将错误最小化。
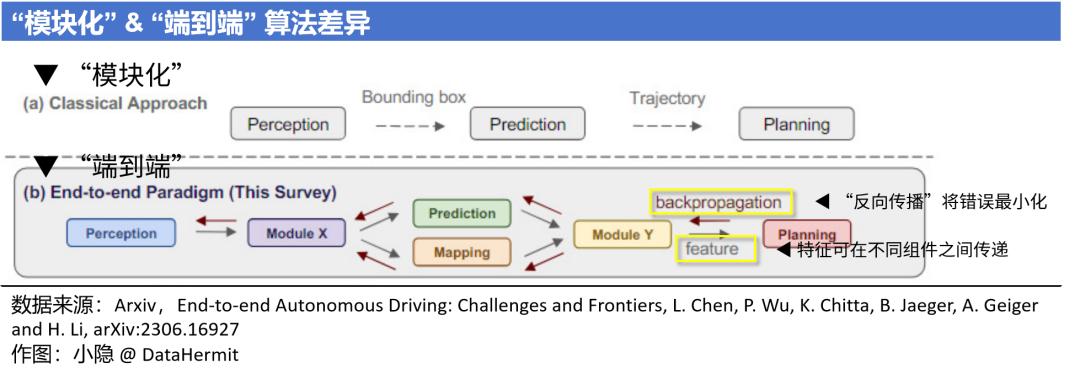
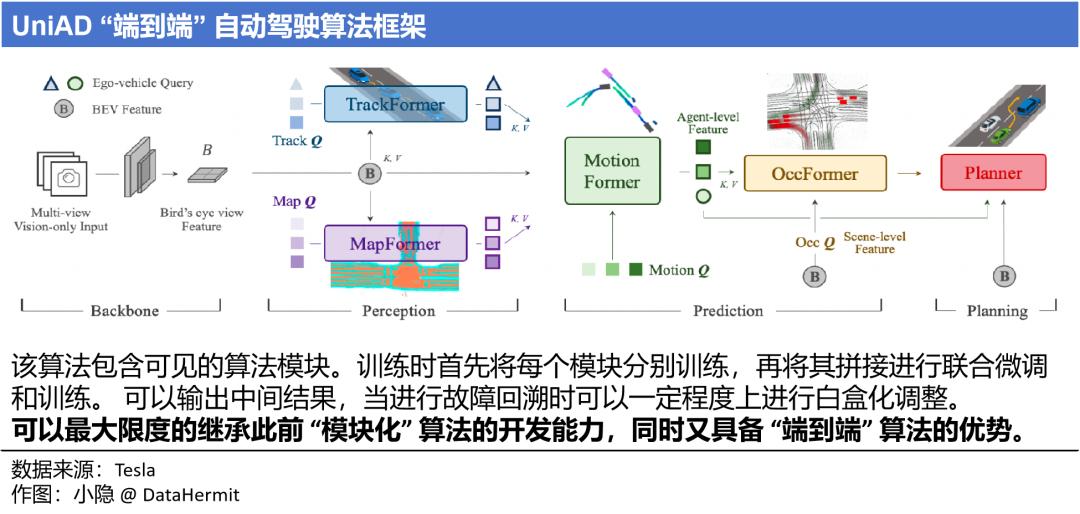
目前 “端到端” 的两大技术方向:
① 将多个神经网络拼接形成 “端到端” 算法。这类算法能够最大程度一起保留 “模块化” 和 “端到端” 的优势。代表是由上海人工智能实验室、武汉大学和商汤科技合作研发的自动驾驶通用大模型 UniAD。
② 从传感器输入直到指令输出,中间采用统一的基础模型。
特斯拉也没有公布 FSD “端到端” 基础模型的全貌,但大概率是这个框架。我们从已公布的 “感知” 模块构建方式中推测,大概是以 Diffusion Transformer(DiT)为架构基础,但依旧保留了一部分的人工规则。毕竟特斯拉已经大规模商业化,就如第一章提及的 Cruise,安全性是核心。
更激进的方案是自动驾驶系统 Wayve。Wayve 的 “端到端” 自动驾驶网络即采用单一的神经网络,直接输入感知数据,输出车辆的驾驶动作,中间没有抽象化的感知结果输出。因此,车辆上也不包含通常自动驾驶具备的 “SR”(Situational Awareness,用来呈现自驾算法看到了什么)界面。(将在第七章再次详细介绍 Wayve)。

反观国内车企,5月 20 日小鹏宣布国内首家 “端到端” 模型 XNGP+ 量产上车。
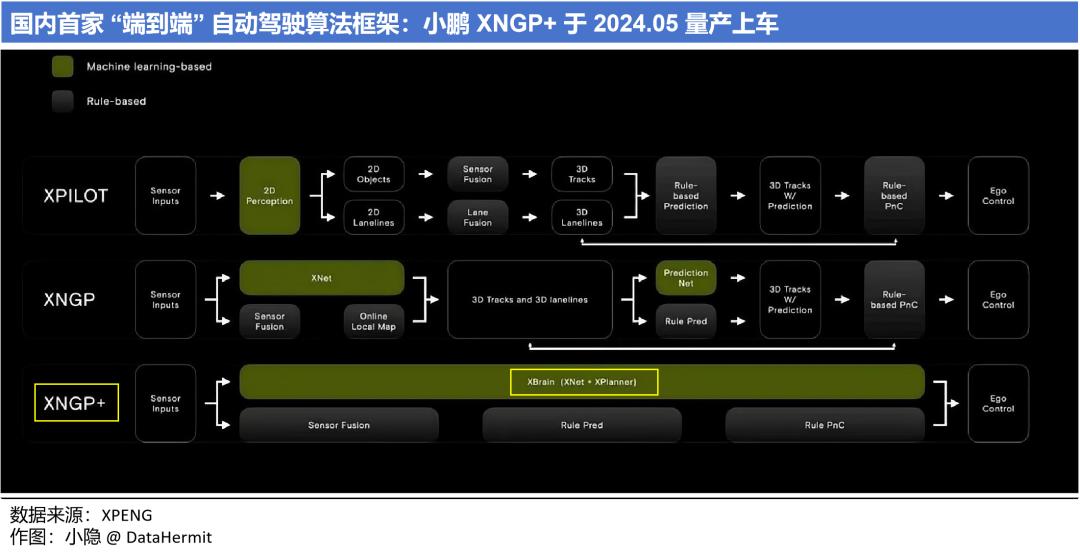
就如前章所说,“端到端” 算法本质上是规模效应的体现(这个问题将在下一章具体阐述)。“端到端” 肯定是全局最优解,国内其他车企在快速迫近这个技术转换的 “节点”。
6
特斯拉的“数据引擎”路径
回到上一章的问题:为什么特斯拉是第一家落地 “端到端” 架构的规模化车企?
因为特斯拉 FSD v12 是一个训练数据、算力、算法 “规模效应” 下的产物。
观察一下特斯拉公布的 FSD 算法架构,两个非常核心的输入:(1)Training Data(训练数据);(2)Training Infra(算力)。
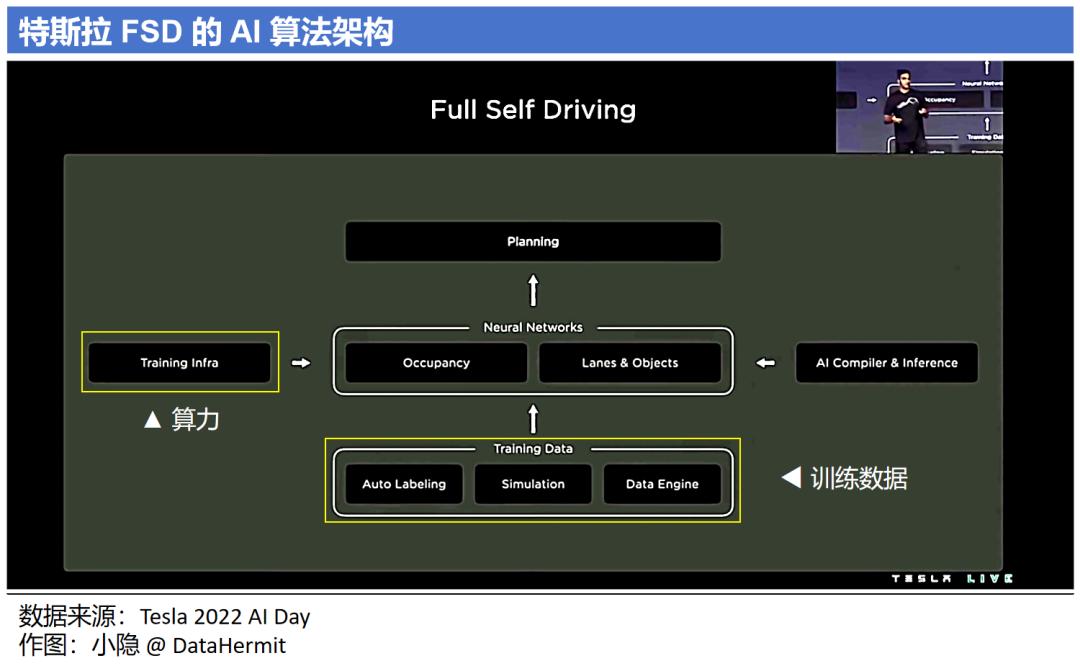
问题一:特斯拉的训练数据量有多大?
马斯克曾经在财报会中提到训练模型所需的数据:“100 万个视频训练,勉强够用;200 万个,稍好一些;300 万个,就会感到 “嚯!”;到了 1000 万个,就变得难以置信了。”
这些训练视频哪里来?看下图。
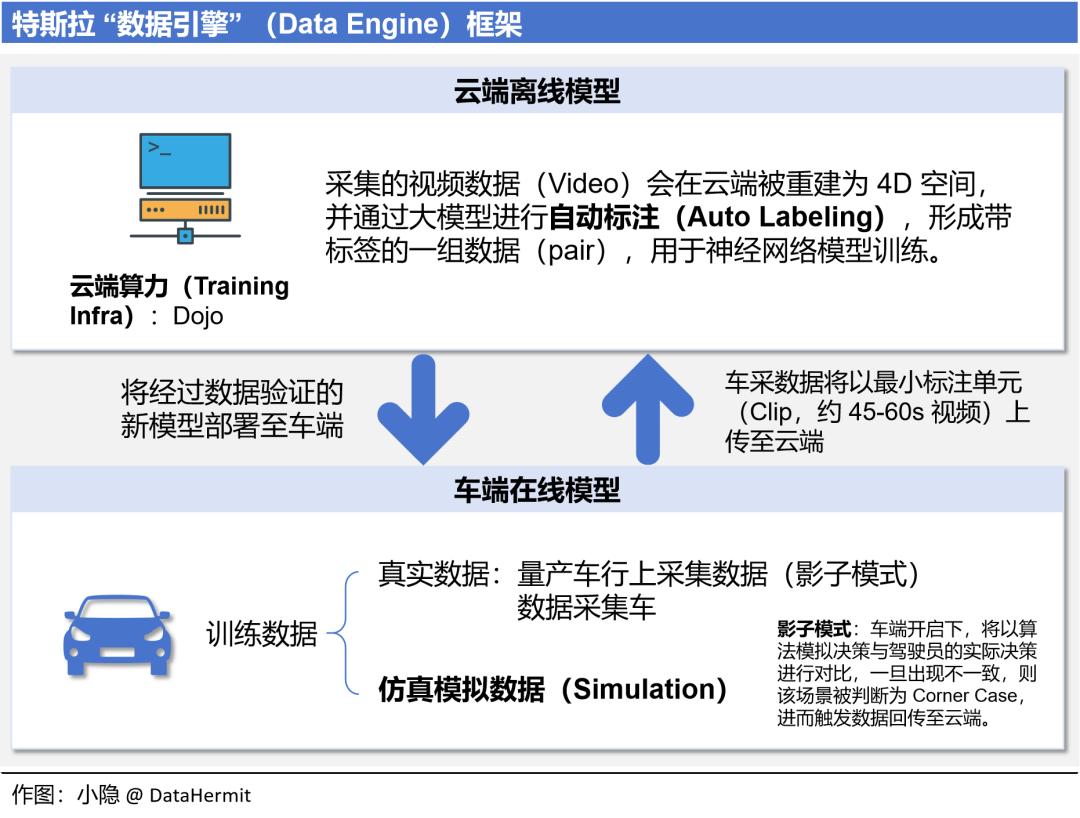
2023 年底,特斯拉 FSD Beta(量产车采集数据)累计行驶就已经超过了 10 亿英里。

这里提及的两个点:
① 自动标注
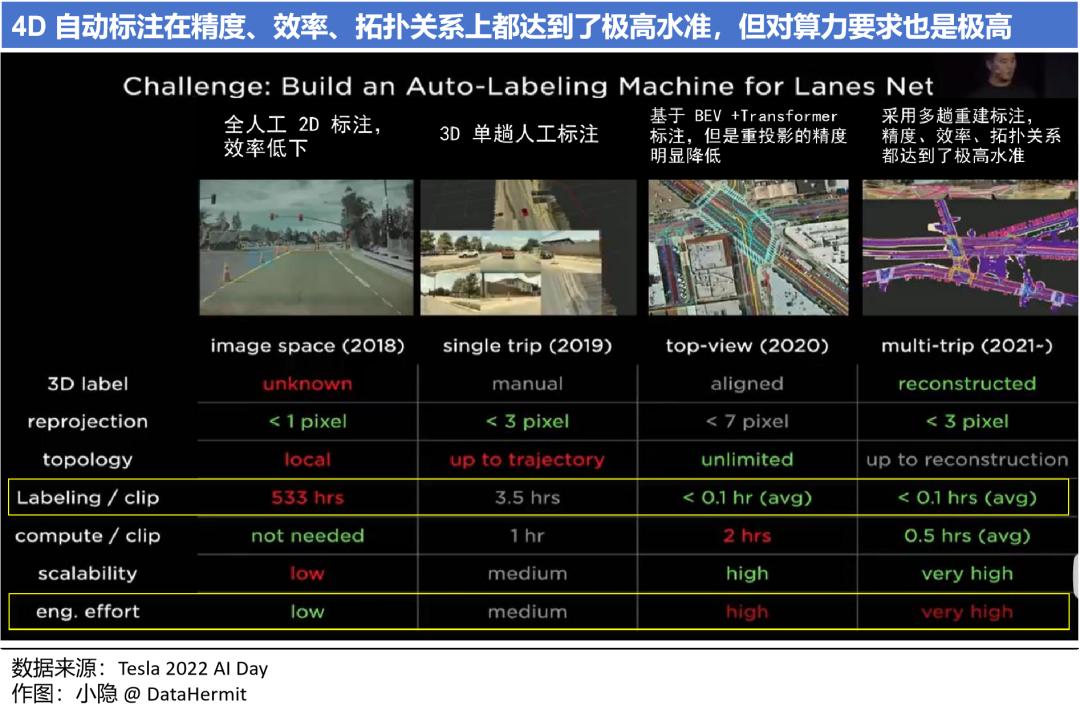
建立在 Occupancy + Transformer 之下,精度、效率、拓扑关系都达到了极高的水准,自动标准具备了可行性。标注对象不仅于静态物体:车道线、建筑物等;也包含动态物体:车辆、行人。
自动标注可以取代 500 万小时的人工作业量,人工只需要检查、补漏极小的部分(<0.1hrs)。
② 仿真模拟数据
除了量产车、数据采集车依靠 “影子模式” 采集的视频集之外,一些稀缺的、难以采集的训练视频数据,需要通过仿真模拟,用于对 “感知” 和 “决策规划” 模块进行训练(“仿真” 对应算法第七章会再次阐述)。

问题二:特斯拉的算力有多强大?
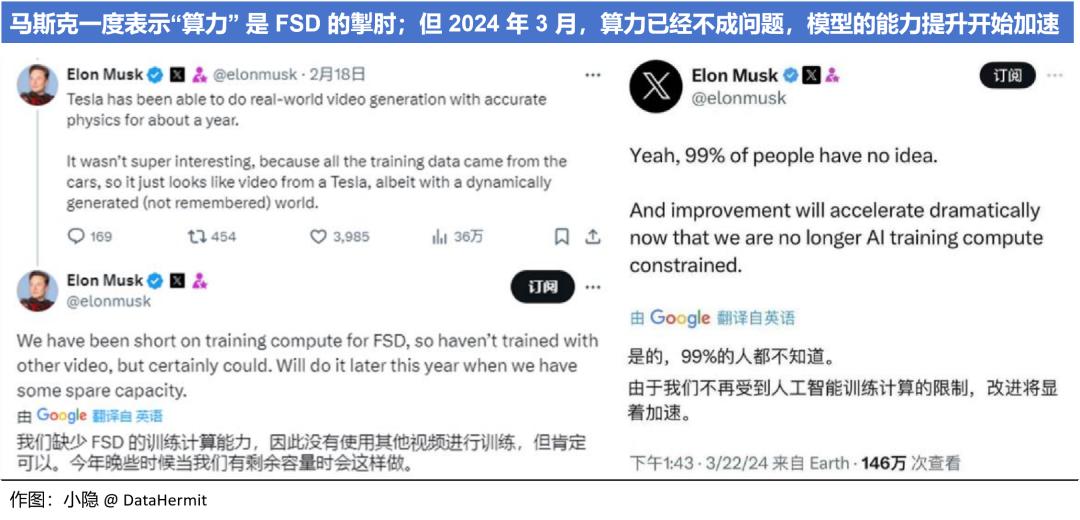
Transformer 基础框架的特征就是 “规模效应”,对算力极度依赖。2021 年特斯拉首次发布 Dojo 超算中心 + D1 自研芯片,2023 年 7 月投产。
2024 年 10 月,特斯拉的算力总规模将达到 100 EFLOPS,能达到全球 Top3 的算力排名。这是什么概念?“国之重器” 神威 · 太湖之光超级计算机的算力是 93 PFLOPS(单位区别见下图)。
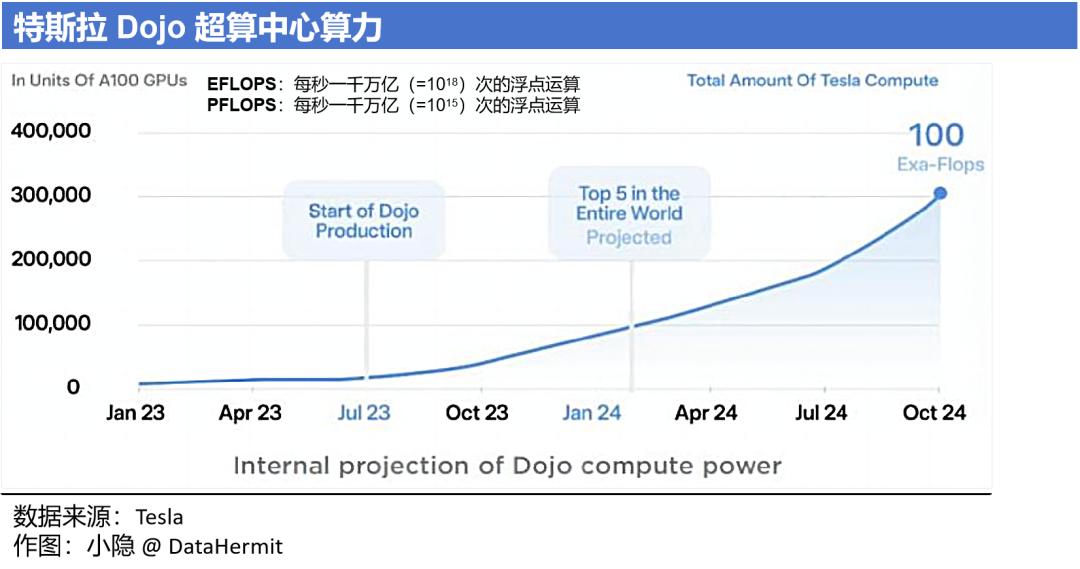
2024 年,特斯拉预计将为自己已成体系的训练数据、算力、算法闭环,再投资 100 亿美元。
7
世界模型,“无人驾驶”的终极解决方案?
“端到端”这个框架被验证之后,“无人驾驶”在特斯拉的引领之下,核心诉求来到 next level:
① 在 Transformer 架构下,进一步“规模效应”提升模型性能:这需要更多高质量、低成本的训练视频。
② 算法依旧存在上限:无法做到人类这样对现实世界场景作出完全推理。
可能的解决方案:扩散模型(Diffusion Transformer:DiT) ,世界模型(World Model)。
2024 年,OpenAI 发布了基于扩散模型(Diffusion Transformer)基础框架的文生视频大模型 Sora。Sora 能够根据用户提供的文本描述生成长达 60s 的视频。
Sora 的优势在于:① 仅根据提示词就能生成视频;② 视频时长可达 1 分钟;③ 保持空间一致性、时间一致性、因果一致性。

但是,Sora 依旧在对世界的物理理解上存在缺陷。

Sora,还不具备完全的人类智慧。“无人驾驶”依旧需要 AGI 上的技术突破。可参考的路径在哪里呢?
又回到“人类驾驶”的本质(本章的核心诉求 ②):
在驾驶环境中,正因为人类具备对世界基础常识的理解,即使遭遇没有见过的场景,依旧能够推理出决策结果。这就是:反事实推理(Counterfactual reasoning)。
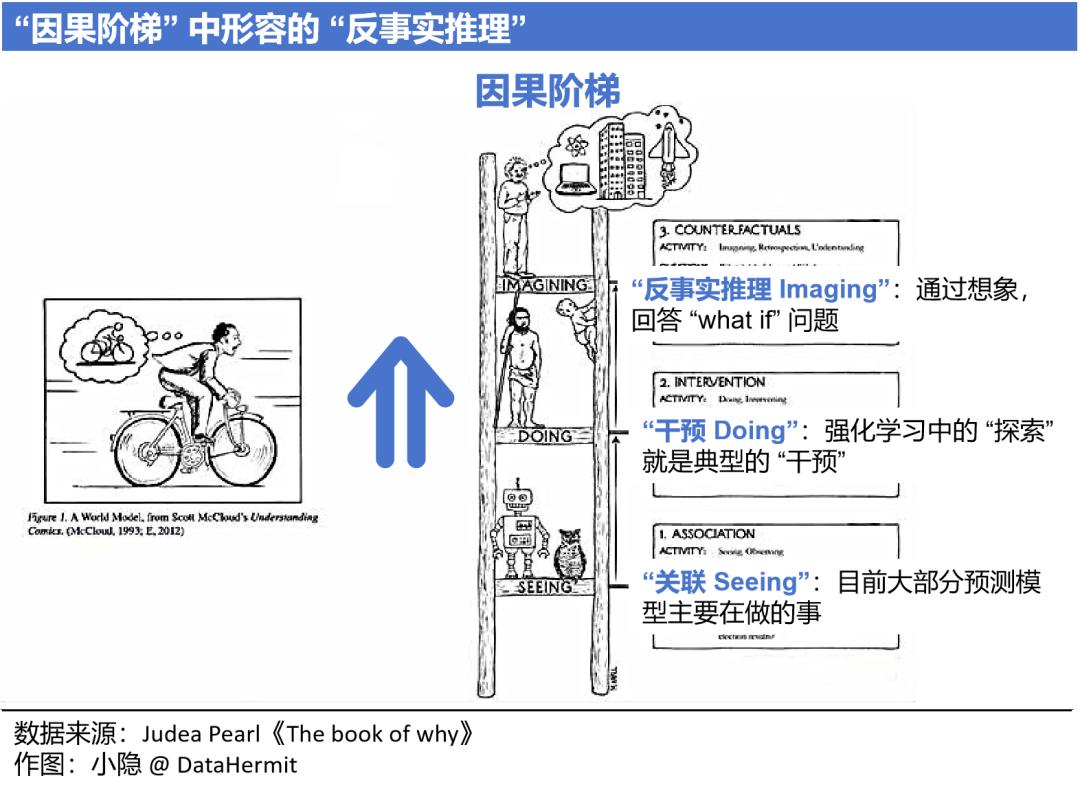
世界模型(World Model)的概念在 2018 年由 Google 提出,模型被描述具备的核心能力就是 “反事实推理”。一个简单的世界模型,包含视觉感知组件(Vision Model,V)、记忆组件(Memory RNN,R)、和控制组件(Controller,C)。世界模型的核心本质:具备 “反事实推理”。换言之,世界模型具备人类智慧。

世界模型能够如何赋能 “自动驾驶” 领域?
(1)生成稀缺、难以采集的仿真场景。
为模型训练提供足量的数据用于 “感知” 和 “决策规划” 的验证。 “感知” 环节更注重仿真环境的逼真性,而 “决策规划” 环节更注重场景逻辑的丰富度。世界模型能够 “端到端”,同时满足这两个环节的验证诉求。
(2)运用 “反事实推理”,生成驾驶策略来指导自动驾驶行为。
目前涌现出的 “世界模型” ,已经达到了什么高度?重点看看特斯拉和 Wayve。
(1)2023 年,特斯拉在 2023CVPR 对其 “端到端” 模型的描述:经过训练,模型具备了一定程度对物理世界的理解,与理论上的世界模型已经有众多相似之处。可惜,特斯拉只公布了其 “感知” 模块的构建方式。

(2)英国端到端自动驾驶软件公司 Wayve。
这家公司的被关注度有多高?5月,Wayve 官宣再获新一轮融资,总额 10.5 亿美元(约 75.8 亿元),累计融资已经超过 23.5 亿美元(约 169.6 亿元)。

Wayve 的核心模型为:能解说和问答的自动驾驶模型 LINGO,和多模态视频生成式世界模型 GAIA。
以我的理解,LINGO 和 GAIA 都是为 Wayve 的 “端到端” 自动驾驶基础模型服务的。LINGO 用以训练和增强 “自动驾驶” 模型的推理和决策能力;GAIA 生成视频用于基础模型的训练(GAIA被称已经具备世界模型的雏形)。

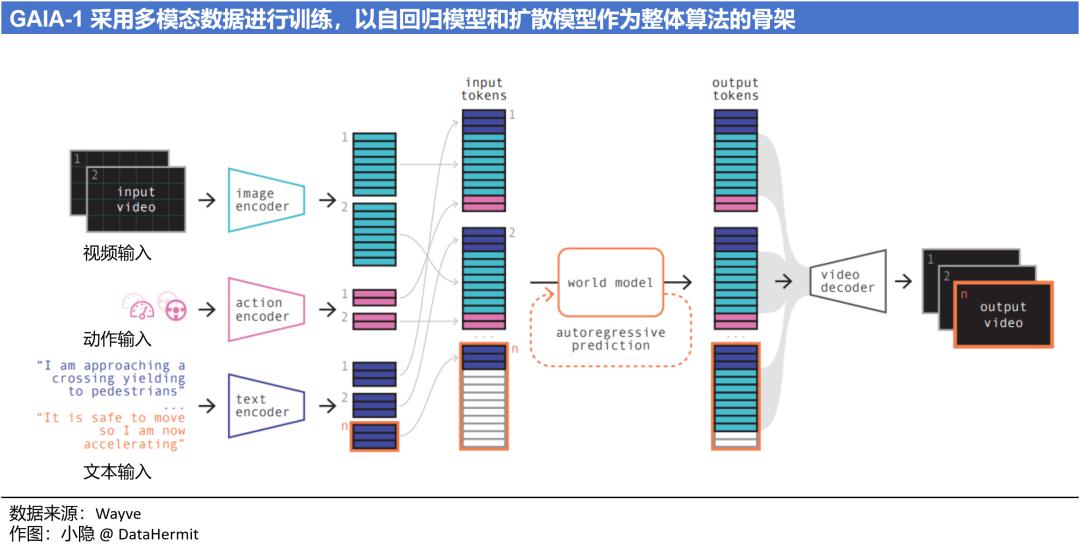
Wayve的 “自动驾驶” 基础模型 AV2.0 的算法优势在于:
① 将 “具身智能(Embodied AI)” 引入 “自动驾驶” 基础模型,可以实现向自然环境的学习和交互。
② 可以从原始的、未标记的数据中,进行无监督学习。不需要再对视频进行昂贵且耗时的标注。
③ 强调基础模型的通用性,适配任何路段和车型。
④ 基础模型具备一定的 “反事实推理” 能力。在没有预先训练的情况下,依旧能够面对极端及不常见场景(Corner Cases)并给出应对。

但是,Wayve 的最大弊端:并没有用于量产车。一切都还存在变数。
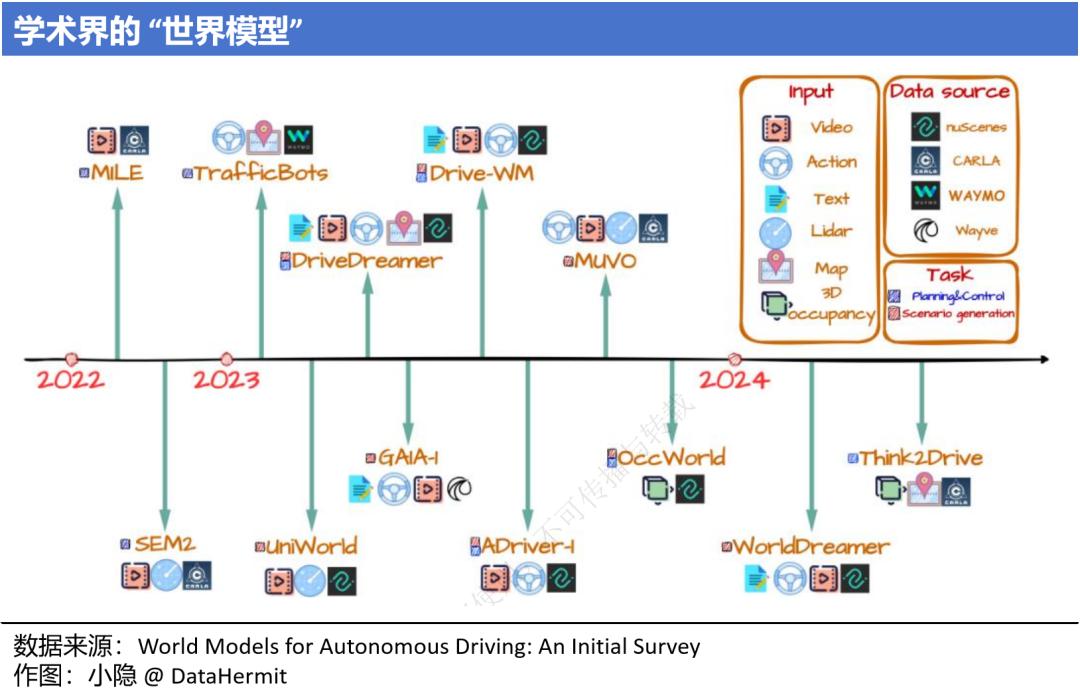
此外,还有英伟达的 NVIDIA DRIVE Thor;AI 创业公司极佳科技和清华大学联合推出的 DriveDreamer 等。各类模型殊途同归,但距离实现世界模型(World Model)的核心机制 “反事实推理”,都还有很长的路要走。
对世界模型的发展关注,也不需仅局限于 “自动驾驶”,“视频生成” 和 “具身智能”(特斯拉人形机器人 Optimus),都是其突破口。
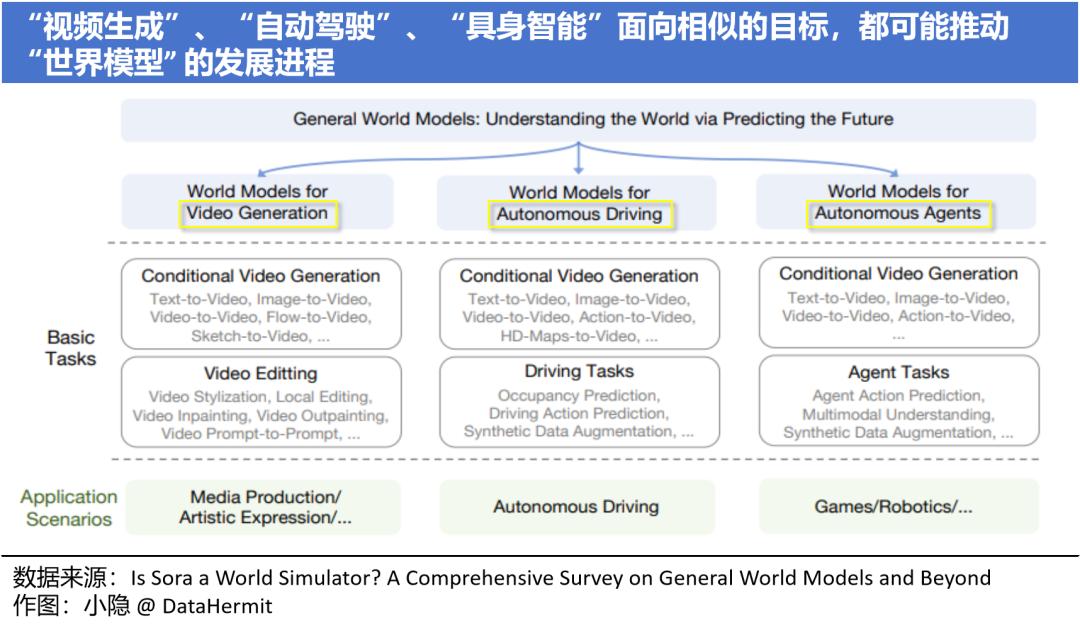
所以,你觉得,“无人驾驶” 距离我们,还有多远?
风险提示:
本文仅做探讨,不构成任何投资建议。
作者:小隐
原标题:《我们距离 “无人驾驶” 还有多远?| 看数据》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

