- +1
视频大模型“造梦机器”爆红:瑕疵真不少,关键是能用

过去半年,AI 生成视频一直处在断断续续推进的状态。在 OpenAI 年初推出 Sora 时引发空前讨论之后,号称国内首个自研视频大模型的 Vidu,以及后续字节、腾讯、快手等多家国产厂商推出视频生成模型,都在时不时引发外界的关注。就在前几天,雷科技还对快手的视频大模型「可灵」进行了内测体验。
不过,这两天 AI 生成视频确实又火了。
一发布就火,「造梦机器」烧遍社交网络
6 月 12 日,初创公司 Luma AI 发布了新的 AI 视频生成模型 Dream Machine(造梦机器),并且面向公众开放测试。很快,不仅官方放出的一系列样片,社交网络上还出现了一大堆由网友通过「造梦机器」生成的视频。
比如现代风格的样片,它在少女和猫的呈现效果上水准相当高,尤其是猫的头部和眼部动作。

图片经过压缩,图/ Luma AI
还有奇幻风格的,生成的人物或者物体也确实奇幻,甚至有些克苏鲁的味道。

图片经过压缩、剪辑,图/ Luma AI
此外,「造梦机器」不仅支持通过文本生成视频,也支持基于图片和文本生成视频,所以你还能看到从《戴珍珠耳环的少女》中跳出的少女,还有房地产中介可能会喜欢的「如何让景观图变成景观视频」。
甚至,有人已经开始利用「造梦机器」创造一个讲述「一日生活」的影像故事,包括美国中学生从早起到上学再到舞会的刻画。
不只是用户玩得开,海外和国内媒体也都注意到了「造梦机器」的热度。不过有一说一,有些国内媒体明显吹过了头,什么超越 Sora、比 Sora 更真实流畅,这些我们先稍后再谈,但「造梦机器」哪来的支持 120 秒生成视频?
事实上,「造梦机器」只支持生成 5 秒的视频,官网说的是生成视频需要 120 秒,排队等待的时间另说。而如果单独打开官网上的样片,也会发现一律都是 5 秒(除非有剪辑)。

图/ Luma AI
这个视频时长,比起国产视频大模型 Vidu 的 16 秒(最近又宣称延长到了 32 秒的有声视频)就不用说了,更何况是将 AI 生成视频时长突破到 60 秒的 Sora。
按照 OpenAI 官方公布的信息,Sora 能够实现视频时长突破,主要功臣是其所采用的扩散 Transformer 架构,在 Diffusion 扩散模型的基础上将 U-Net 架构替换成了 Transformer 架构。
「造梦机器」呢?目前 Luma AI 公司并未透露具体的情况。
当然,5 秒的视频时长你也不能说太短,因为目前大量的视频生成模型也只能生成 5 秒的视频,包括宣称可以生成最长 2 分钟的快手可灵,至少目前也只能生成 5 秒的视频。而且我们也不能只看「视频时长」一个维度,还得看画面的可用性以及使用潜力。
表现惊艳,但内容可靠吗?
坦率地讲,「造梦机器」给小雷的第一印象还是挺惊艳的,首先感受下官方放出的样片。

图片经过压缩,图/ Luma AI
比如这段中,在一个氛围透露着危险的房间,一个持枪的男子小心翼翼地前进。
除了人物主体和背景的一致性,最让人惊讶的可能是光照的变化。不仅是手枪上明显的光线反射,在男子脸上,也可以看到原本诡谲的红光在人物移动过程中,色温逐渐由暖转冷,并与邻近光源趋同,包括亮度的变化也符合基本的物理规律。
还有一段是在一间废弃的房屋中发生了爆炸,镜头由远及近。虽然还是会出现凭空固定的白色棒状物,但在镜头移动的过程,不管是家具的不变,还是气流变化引起的纸屑乱飞,都称得上符合直觉。
另外「造梦机器」也展现了作为动画创作工具的潜力,比如在一段视频中,镜头从角色正面转向背面,已经很接近动画创作中的特写镜头。

图片经过压缩,图/ Luma AI
但是,这些终究还是官方「严选」出来的。不管是文字、图片还是视频生成模型,官方 Demo 肯定会经过精挑细选找出相对较好的,这一点大家都能理解,但从普通用户的角度,很容易代入误以为是模型的平均水平。
在实际网友创作和分享的内容中,即便是在那些相当惊艳的少数作品中,你也能看到或多或少的错误。
比如@minchoi 用「造梦机器」创作的美少女视频,好几段都完全媲美真人实拍。
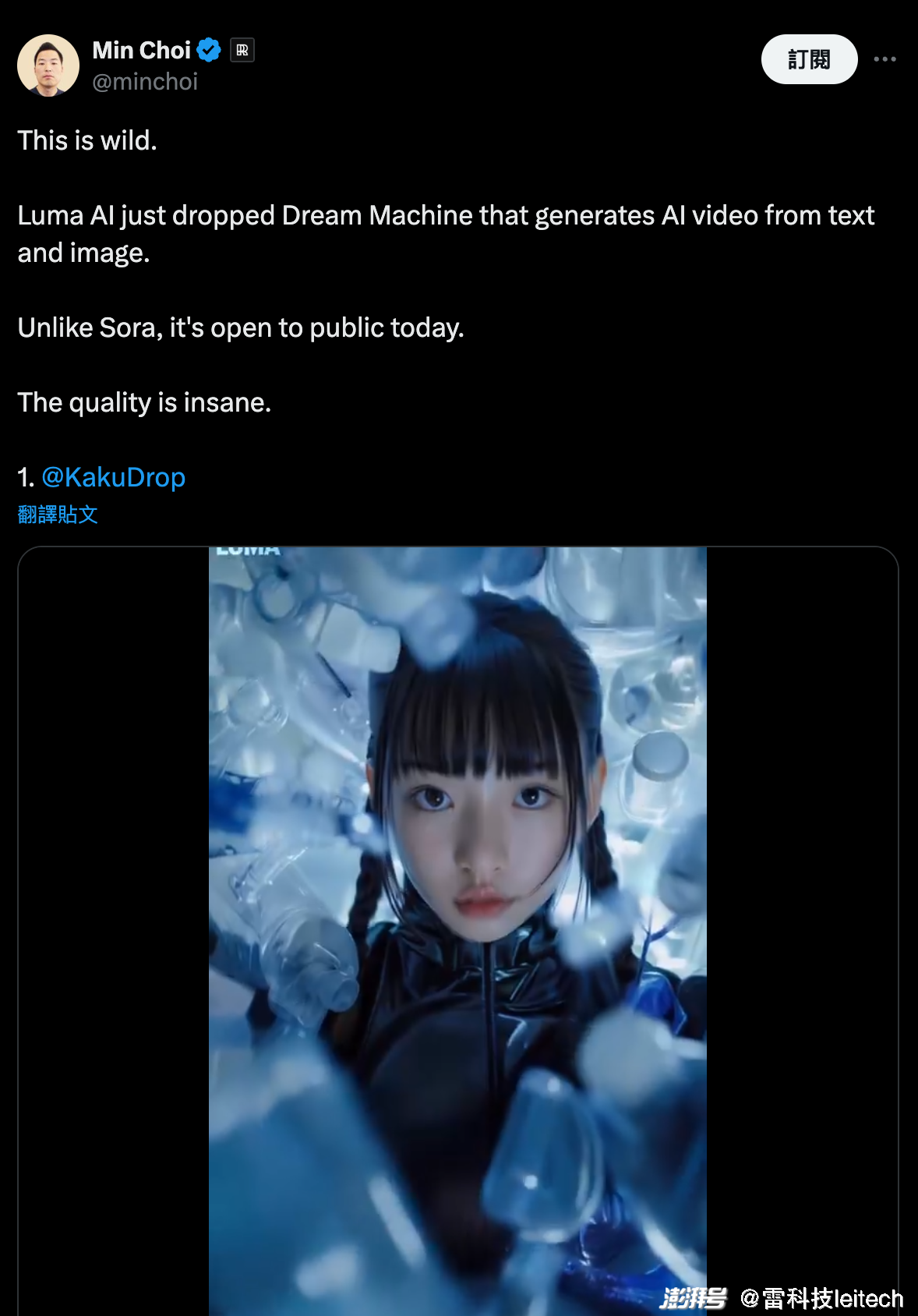
图/ X
不过,人物的手还是存在渲染问题,而且人物的形态还是会有一定的变化,在前面提到的《戴珍珠耳环的少女》视频中更加明显。

图片经过压缩,图/ Luma AI
另外,一致性的问题还体现在风格上,有的明明是 2D 动画风格,慢慢就开始往 3D 动画的风格转。

图片经过压缩,图/ Luma AI
小雷也试着用「造梦机器」创作了一段视频,Prompt 是「A group of people walking down a street at night with umbrellas on the windows of stores.」实际效果还是比较糟糕的:人物诡异的倒退,在背后拿着伞的怪异举动,还有飞起来的雨伞。

图片经过压缩,图/ Luma AI
不过还是有一些优点的,比如路面的倒影,背景和人物的一致性。
即便如此,这些问题说到底还是没有拦住广大网友的创作热情。毕竟相比 Sora,「造梦机器」至少公开可用,还有每个月 30 次的免费生成机会。而相比大部分可用的视频生成模型,「造梦机器」在一致性也有明显的进步。
而除了免费用户,「造梦机器」目前还提供三档付费选项,包括 29.99 美元的标准档、99.99 美元的专业档以及 499.99 美元的高级档,区别是每个月可以生成视频的次数。
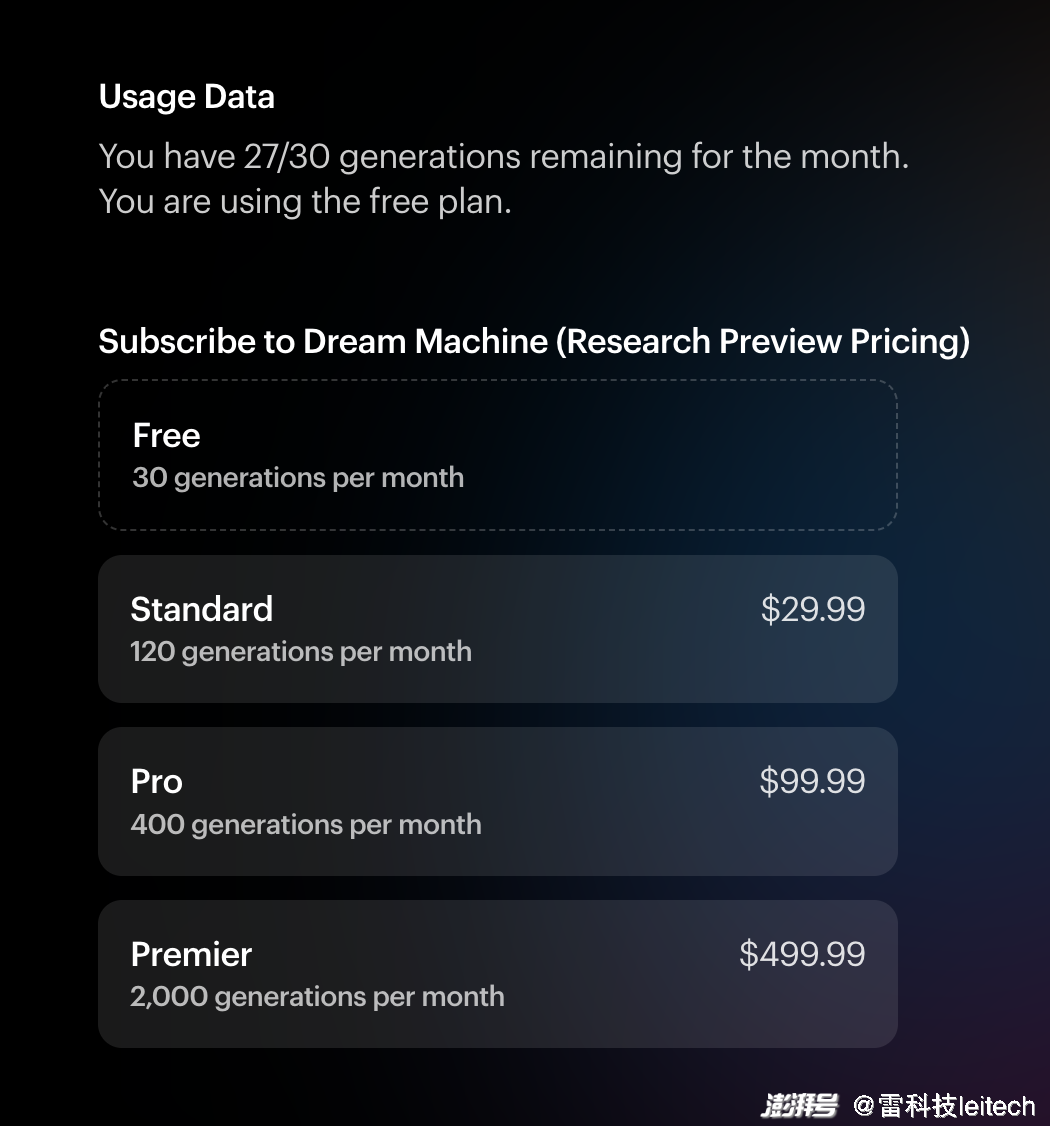
图/ Luma AI
对于普通用户来说,这些定价可能有些离谱,但对于那些开始通过「造梦机器」创作视频在 TikTok 上赚钱的创作者来说,估计还在接受范围内。
从 AI 画图到 AI 视频,大模型再次混战
AI 视频不是从「造梦机器」开始的,当然也不是从 Sora 开始的。事实上早在 2022 年,AI 绘画已经开始惊艳世界的时候,AI 视频就开始吸引大量的关注。
首先我们需要回到 2022 年那个时间点,彼时 ChatGPT 还在酝酿(年底才发布),在大众眼中,AI 技术发展最快速的领域当属 AI 绘画。
2022 年 4 月,OpenAI 发布了新版本的文本生成图像程序——DALL-E 2,一张由 DALL-E 2 生成的「宇航员在太空骑马」图片开始蹿红社交网络,让一众画师真正有了「失业」的担忧。

图/ OpenAI
包括之后的 Midjourney,它们在生成图像方面相比之前的产品都有更高的分辨率和更低的延迟。Stable Diffusion 虽然起步最晚,凭借开源的优势,在用户关注度和使用范围都超越了 Midjourney 和 DALL-E,在初期的进步也最明显。
事实上,当时 AI 绘画已经开始「侵入」社会的方方面面,不管是获奖的《太空歌剧院》(Midjourney 生成),还是各大公司开始尝试通过 AI 绘画直接生成广告、海报甚至内容作品。
图片可以 AI 生成,视频还会远吗?众所周知,视频本质上就是一帧一帧的图片组成。所以在 2022 年,谷歌和 Meta 其实就开始了一场关于 AI 生成视频的竞争,Meta 有 Make-A-Video,谷歌有 Imagen Video,二者都是通过文本直接生成视频的视频扩散模型,底层还是 AI 绘图那一套。

图/ Meta
当时,AI 生成视频时长都不超过 5 秒,分辨率也很低,同时画面变化很小,与其说视频,更像是让图片「动一动」。更重要的是,谷歌和 Meta 受限于大公司的身份和惯性,都没有选择开放给用户以及创作者使用,更多还是研究成果的展示,影响范围也基本局限在圈内。
相比之下,Runway、Synthesia 以及 Pika 等 AI 视频创业公司就显得更加「灵活」。在去年发布的 Gen-2 上,Runway 不仅改进了视频生成的质量,还增加了 Motion Slider(运动滑块)、Camera Motion (相机运动)等功能,把更多视频的控制权交给用户。
去年火过一阵的 Pika 也是一款比较受关注的 AI 视频生成工具,由于较高的画面质量甚至一度被称为「视频版 Midjourney」,同时相比 Runway Gen-2,Pika 为了确保内容的可控性和扩展性,还更进一步给了创作者更多的控制权,比如可以精细到眼部和表情的规划生成。
此后,包括 Stable Diffusion 以及 Midjourney 也都陆续推出了生成视频的版本,让 AI 生成视频进入战国时代。但不管是哪一家,就 AI 生成视频的画面表现来看其实没有太大的差异,更多是产品层面的差异。
直到 Sora 带着 Transformer 架构出道即碾压。
大语言模型,在改变 AI 视频生成
Sora 引发的震撼和讨论可谓有目共睹,甚至有人认为 Sora 将是通往 AGI(通用人工智能)的快车道。Sora 是否能真正理解物理世界的运行规律,我们先放在一边不谈,但可以肯定的是,Sora 彻底改变了 AI 视频生成技术的发展路线。

图片经过压缩、剪辑,图/ OpenAI
Sora 最震撼的技术突破之一在于其输出的视频时长,当其他家普遍都只能生成数秒视频的时候,Sora 就将时长突破了 60 秒。
事实上,包括最新发布的「造梦机器」也只能生成几秒的视频,一旦需要更长的视频,第二次、第三次、第 N 次生成的视频很容易出现变形,导致前后画面差异过大,从而无法使用。
此外,AI 生成视频还普遍存在基于时间的连贯性问题,但一段关于小狗的 Sora 生成视频中,行人完全挡住画面之后,小狗依然能保持住连贯性,主体也没有发生明显的变化。再有就是大家提过很多次的「模拟」,能够很好地模拟符合物理世界规则的动作。
而 Sora 的这些优势很大程度上来源于架构上的核心区别,所以在 Sora 之后,Transformer 架构与扩散模型相结合的全新技术路线很快受到了广泛的关注,包括生数科技(联合清华大学)Vidu、爱诗科技 PixVerse、快手可灵也都采取了这一路线。
从这个角度来看,虽然 Luma AI 没有公开「造梦机器」采用的架构设计,但结合在生成视频中表现的一致性和逻辑表现,很难相信「造梦机器」是在纯扩散模型上的产物,大概率,也是借鉴了 Sora 将 Transformer 架构融入扩散模型的做法。
当然,这也只是一种猜测。但对 AI 视频来说,这越来越成为一种必然。
2024年5月20日-6月30日,618年中大促来袭,淘宝天猫、京东、拼多多、抖音、快手、小红书六大电商平台集体“听劝”,取消预售、疯狂杀价!
手机数码、AI PC、智能家电、电视、小家电、空冰洗等热门AI硬科技品类摩拳擦掌,战况激烈。
雷科技618报道团将全程关注电商平台最新战况,AI硬科技品牌最新动态,电商行业全新趋势,敬请关注,一起期待。
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

