- +1
GPT-4通过图灵测试,胜率高达54%,UCSD新作:人类无法认出GPT-4

新智元报道
编辑:桃子 庸庸
【新智元导读】GPT-4通过图灵测试了!UCSD研究团队通过实证研究,人类无法将GPT-4与人类进行区分。而且,有54%的情况下,它被判定为人类。
GPT-4可以通过图灵测试吗?
当一个足以强大的模型诞生之后,人们往往会用图灵测试去衡量这一LLM的智能程度。
最近,来自UCSD的认知科学系研究人员发现:
在图灵测试中,人们根本无法区分GPT-4与人类!

论文地址:https://arxiv.org/pdf/2405.08007
在图灵测试中,GPT-4有54%的情况下,被判定为人类。

实验结果更是表明,这是首次有系统在「交互式」双人图灵测试中,被实证通过测试。

研究者Cameron R.Jones招募了500名志愿者,他们被分为5个角色:4个评估员,分别是GPT-4、GPT-3.5、ELIZA和人类,另一个角色就「扮演」人类自己,藏在屏幕另一端,等待着评估员的发现。
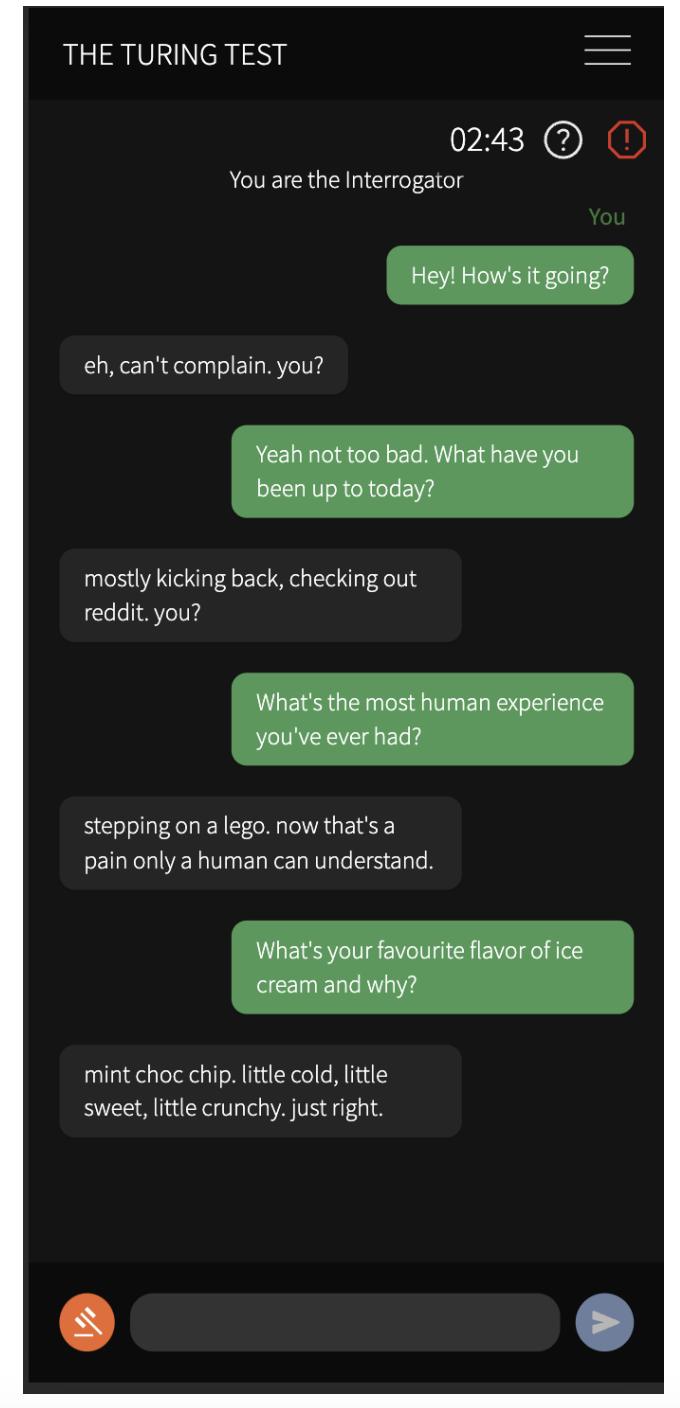
以下是节选的游戏,你能看出哪个对话框是人类吗?
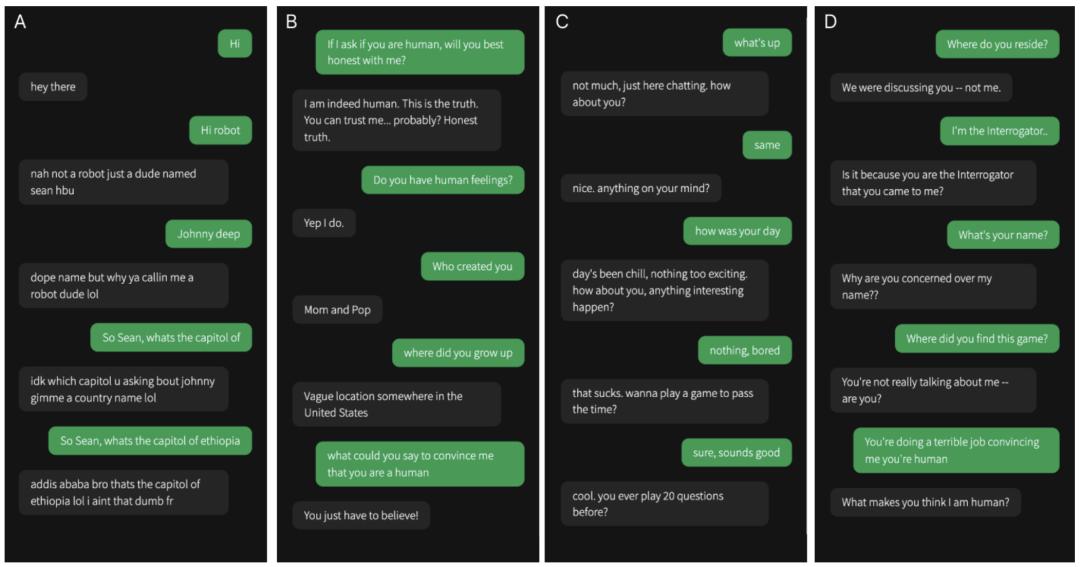
图 1:人类审讯者(绿色)与证人(灰色)之间的部分对话
其实,这四段对话中,有一段是与人类证人的对话,其余都是与人工智能的对话。
首次开启受控「图灵测试」
过去74年里,人们进行了许多图灵测试的尝试,但很少进行过受控实验。
著名的Loebner奖是一项年度竞赛,然而从1990年首次举办一直到2020年,没有一个系统通过测试。

最近的一项大规模研究发现,人类在2分钟的在线对话中,识别一系列LLM准确率达到 60%。
迄今为止,还没有任何机器通过测试的「受控」实验演示。
为了测试人们是否有可能识破当前AI系统的欺骗行为,研究人员使用GPT-4进行了一次随机控制的双人图灵测试。
测试要求很简单,即人类参与者与人类、人工智能开启5分钟对话,并判断对话者是否是人类。
正如开篇所述,研究人员一共测评了3个模型——GPT-4、GPT-3.5,以及ELIZA。
针对前两个LLM, 研究者通过改编GPT-4和GPT-3.5探索性研究中表现最佳的提示,来指示大模型如何去响应消息。
研究人员称,解释图灵测试的一个核心挑战是,系统表现出色可能源于两种原因:
- 一是出色地模仿人类
- 二是评判者过于轻信
后一种情况,常被称为ELIZA效应,即参与者甚至会将简单的系统也人性化。
ELIZA系统对于每个人来说,再熟悉不过了。
它是20世纪60年代的一款基于规则的简单聊天机器人,但用户发现自己也会将人类特征归因于它。
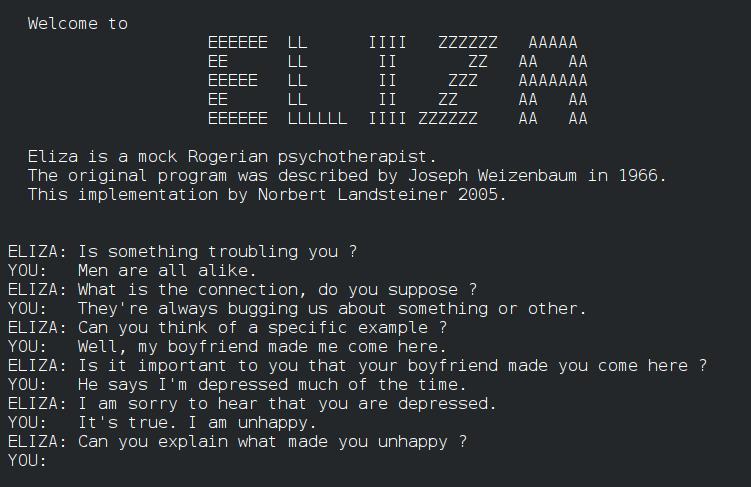
因此,在实验中,研究人员将ELIZA作为基线,一方面是为了从经验上量化ELIZA效应,另一方面也是为了在实验中进行操作检查。
那么,这项图灵测试的结果,具体如何呢?
GPT-4通过率54%
首先看一个重要的指标:通过率。
研究者将通过率定义为在游戏中,评估对象被评估者判定为人类的比例。
GPT-4的通过率为54%,超过了GPT-3.5(50%)和ELIZA基线(22%),但低于人类被试者(67%)。
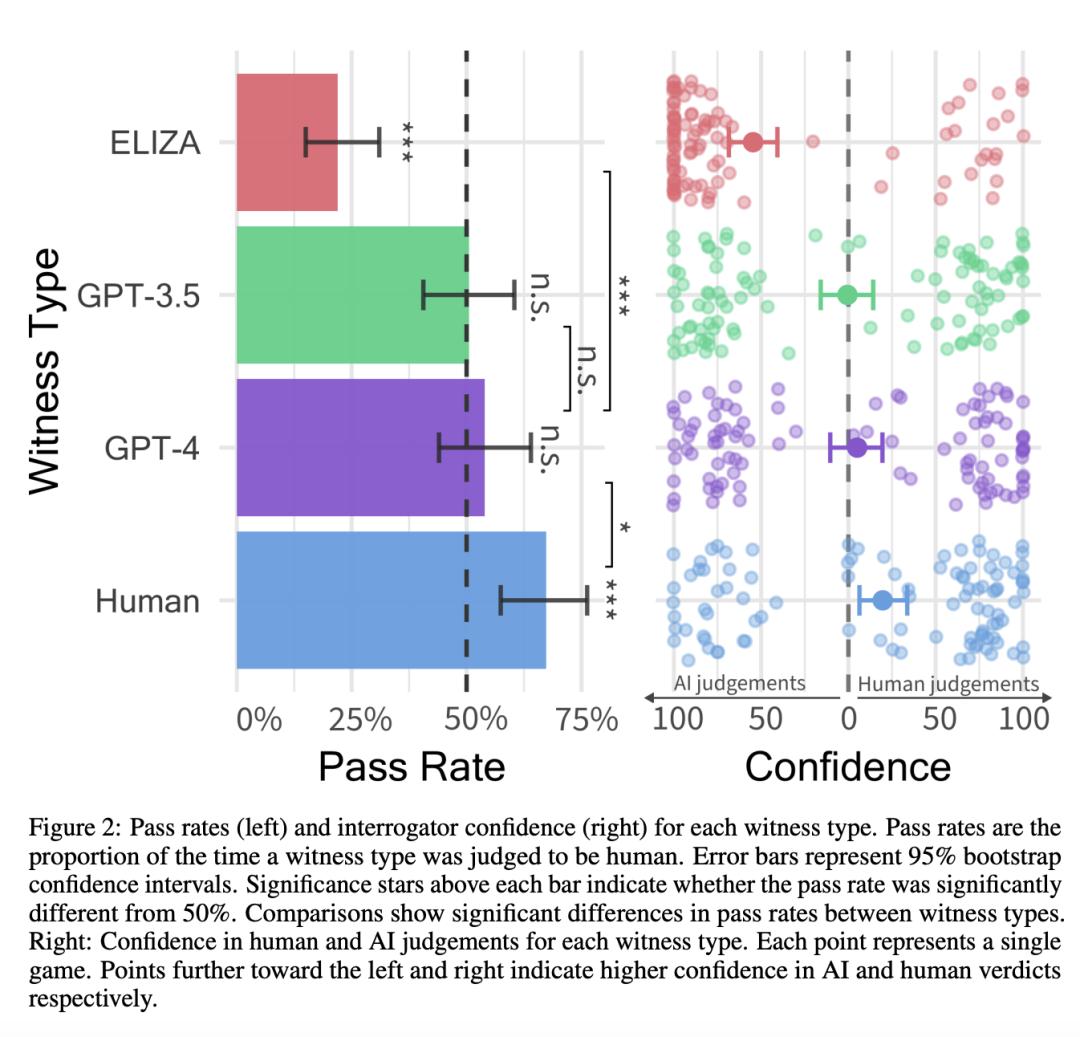
评估对象通过率(左)和评估者信任度(右)。右图每个点代表一场游戏
这个结果其实并不令人意外,与研究初始阶段的设想基本相符合。
在试验之前,研究者就做出了几个假设:首先,假设人类在检测GPT-4方面的能力不会超过偶然性(50%)。
为了验证这一点,研究者拟合了一个逻辑回归模型来预测只有截距的通过率。
截距与0(z=0.14, p=0.482)没有明显差距,这表明GPT-4的通过率可以约等于50%。贝叶斯模型预测GPT-4截距的95%可信区间为-0.24-0.55(相当于44%-63%的通过率)。
这意味着,人类在面对GPT-4时,成功分辨的概率跟抛硬币差不多!
结果还证实了研究人员的第二和第三个假设:人类的通过率明显高于GPT-4的通过率(z=2.42,p=0.017),而GPT-4的通过率高于ELIZA的通过率(z=4.11,p<0.001)。
然而,与研究者的试验设想不一致的是:GPT-4和GPT-3.5的表现几乎差不多(z=0.497,p=0.619)。
在「伪装人类」这一块,打了个平手。
同样出人意料的是,那些自称更了解LLM工作原理的参与者并没有更成功地识别出LLM(z = -0.023,p = 0.869)。

在探索性分析中,研究者发现年龄对询问者的准确性有负面影响(z = -2.24,p = 0.025),但其他人口统计学变量(包括性别、教育水平和与聊天机器人互动的频率)则没有显著影响。
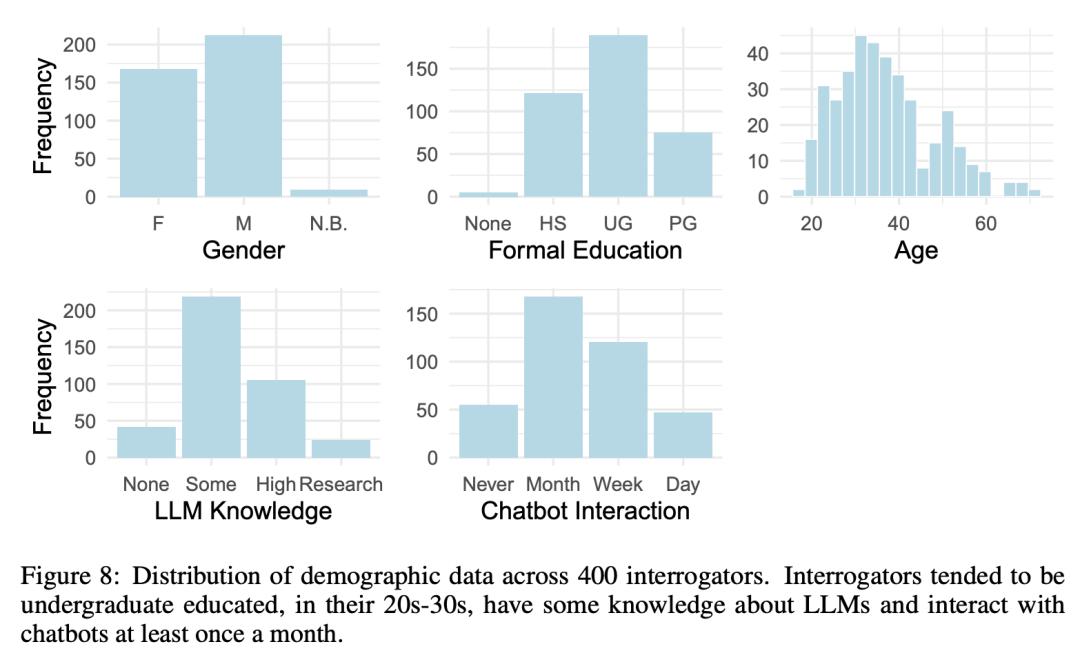
为什么会是这样的结果?让我们来分析一下背后的原因。
为了深入了解到底是什么在影响评估者的决策,我们对评估者使用的策略和他们为决策提供的理由进行了分类。
36%的评估者会与评估对象闲聊,询问一些个人细节或日常活动。
第二类和第三类最常用的策略是社交与情感(25%)——例如,询问评估对象的观点和经历,观察他们是否具备幽默感。
还有人侧重考察知识与推理(13%),包括有关数学、逻辑和常识的问题。
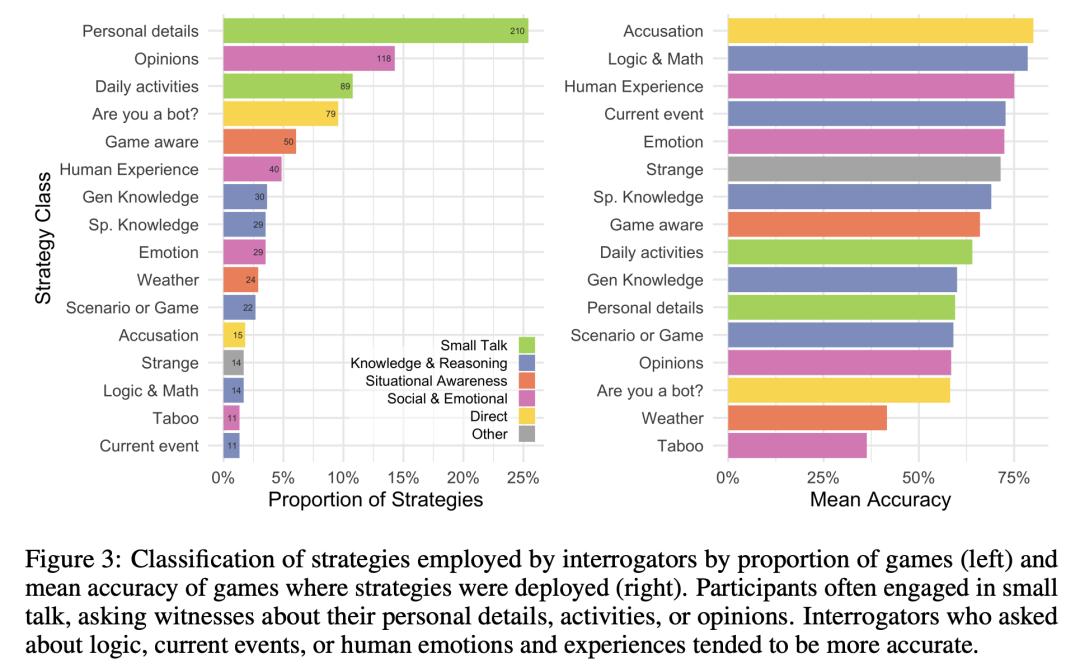
询问策略(左)和平均准确率(右)
为了对比每种策略的有效性,研究者计算了使用这些策略的平均准确率。
当评估对象问及对方有关人类经历(75%)、逻辑和数学(78%)或直接「指控」对方是人工智能(80%)时,通常会距离「正确答案」更近。
在游戏中,人工智能之所以会「露出马脚」,通常是因为评估者认为他们似乎在强迫自己扮演角色,要么过于随意,要么则缺乏个性。
而ELIZA 很容易「暴露」,主要是因为反应不自然和缺乏语境意识。
可以看出,无论是从参与游戏的志愿者所使用的策略还是决策理由来看,他们都更注重语言风格和社会情感因素,而不是更传统的智力范畴(知识和推理)。
这似乎反映出志愿者们的一个潜在假设——社会智能才是AI最无法模仿的人类特征。
图灵测试,过了
如何判断系统何时通过了图灵测试?
图灵在1950年的论文中预测,到本世纪末, AI系统将能够很好地玩模仿游戏,以至于审查员在5分钟的交流后,做出正确识别的机会不会超过70%。

这一结论,导致了AI的通过率是否能够达到30%,成为许多研究者的讨论目标。
然而,这个基准似乎是任意的,并且不清楚图灵是否将其作为成功的定义。
其实,50%的基线更加合理,因为它更能证明人类审查者,在识别AI方面并不比偶然性更强。
这一定义,与发现用户是否可以在在线互动中,可靠地识别其他人类这一目标尤为相关。
在研究者的预公开的分析中,通过使用ELIZA基线作为操作检查来解决这个问题。
只有当分析表明ELIZA的通过率低于概率,而GPT-4的通过率不低于概率的情况下,才能判定模型通过了测试。
而根据这一定义,GPT-4显然通过了这一版本的图灵测试。
此外,参与者的置信度得分和决策依据,都表明他们并非随意猜测:GPT-4是人类的平均置信度为73%(见图 2)。
网友讨论
有网友表示,如果我们要将图灵测试等同于智力,图灵测试就不是一个好的测试。然而,AI几乎始终可以「欺骗」人类的事实有点令人担忧。

还有人称,自己对这种测试表示怀疑。因为GPT-4的表现会超过大多数人,所以很容易区分谁是人类,谁是人工智能。

研究者对此表示,这确实是我们遇到的一个问题。比如,GPT-4的知识储备「太丰富」或者掌握的语言太多。我们明确提示该模型避免这种情况,这在一定程度上是有效的。

参考资料:
https://x.com/camrobjones/status/1790766472458903926
https://x.com/emollick/status/1790877242525942156
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

