- +1
Sora还没开源,但这家国产AIGC视频公司已经靠还原现实赚钱了
原创 关注前沿科技 量子位
衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
最近AIGC的落地,又有了一些热议和争论。
在金沙江创投主管合伙人朱啸虎的爆款采访中,他表达了对自研大模型商业闭环的悲观,但又坚定地表示非常看好应用,“我信仰AGI,但我信仰应用啊,信仰能马上商业化的。”
在他的犀利表达中,一家应用公司意外走红。
它就是AIGC视频广告公司FancyTech(时代涌现)。
对国内大模型五小虎不愿一看的朱啸虎,提到FancyTech,真的是不吝溢美之词,直夸很酷。
夸它什么呢?主要是两点,一是效果好,二是能马上变现。
FancyTech商业成绩如何,还要等我们进一步挖掘;而论效果,我们搜寻来了网上的视频,确实不错。
但谁会只相信品牌放出的demo呢
???
搜索之下,我们发现FancyTech的免费测试链接——那还等什么,直接冲啊。
FancyTech真的fancy吗?
实测第一站,我们率先体验的是FancyTech还原现实的换装功能。
简单来说就是基于一张商品图,可以生成模特上身图,并且是能自定义姿势、自定义背景、自定义脸的那种。

说实话,AIGC的风这么大,给模特换装已经不是啥稀奇功能了,甚至这一块的开源力量也不小。
但之前接触过类似Google的Tryon Diffusion等,都没有FancyTech这样能够进行详细的自定义。
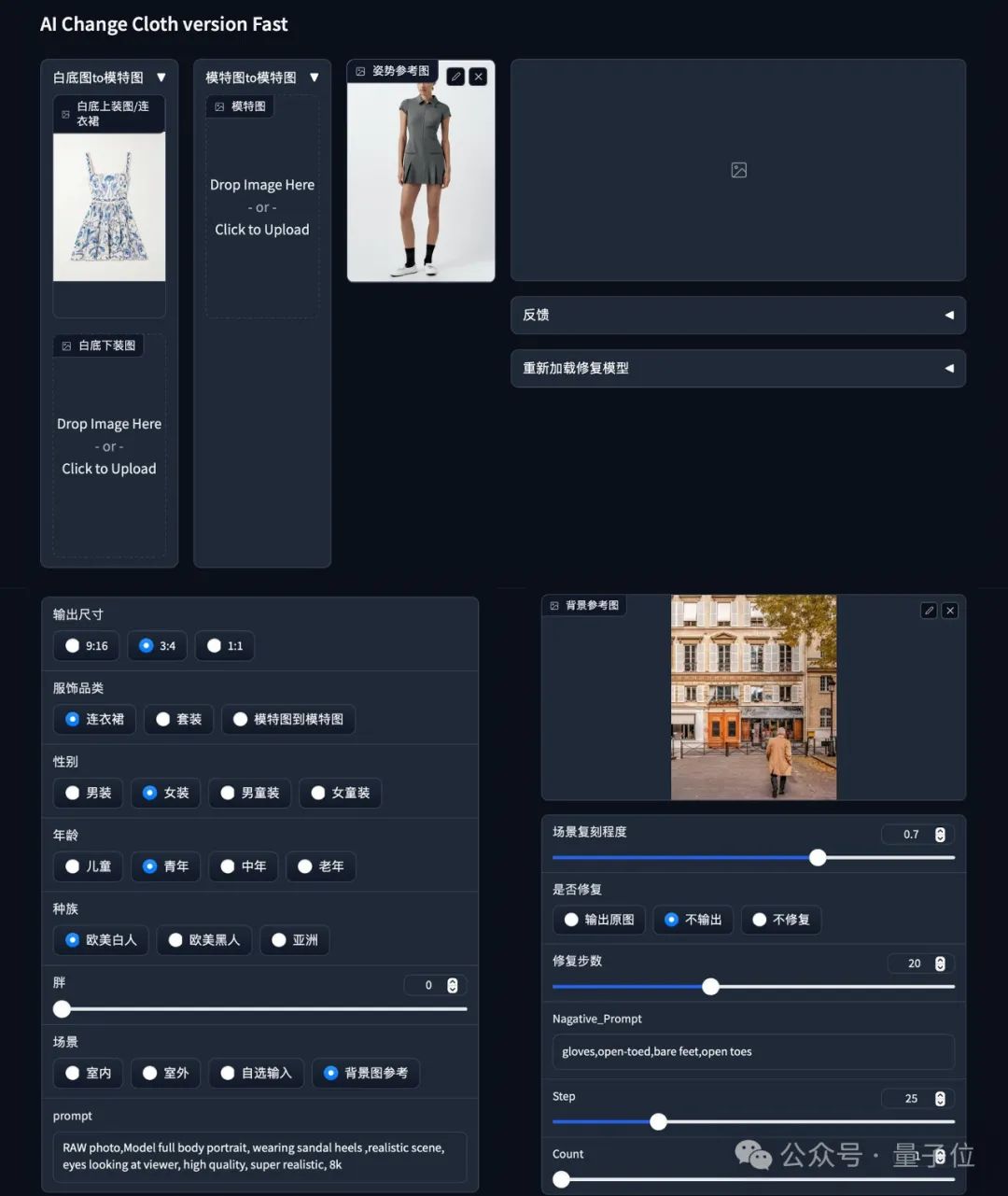
就上手体验而言,FancyTech的体验比较傻瓜式。
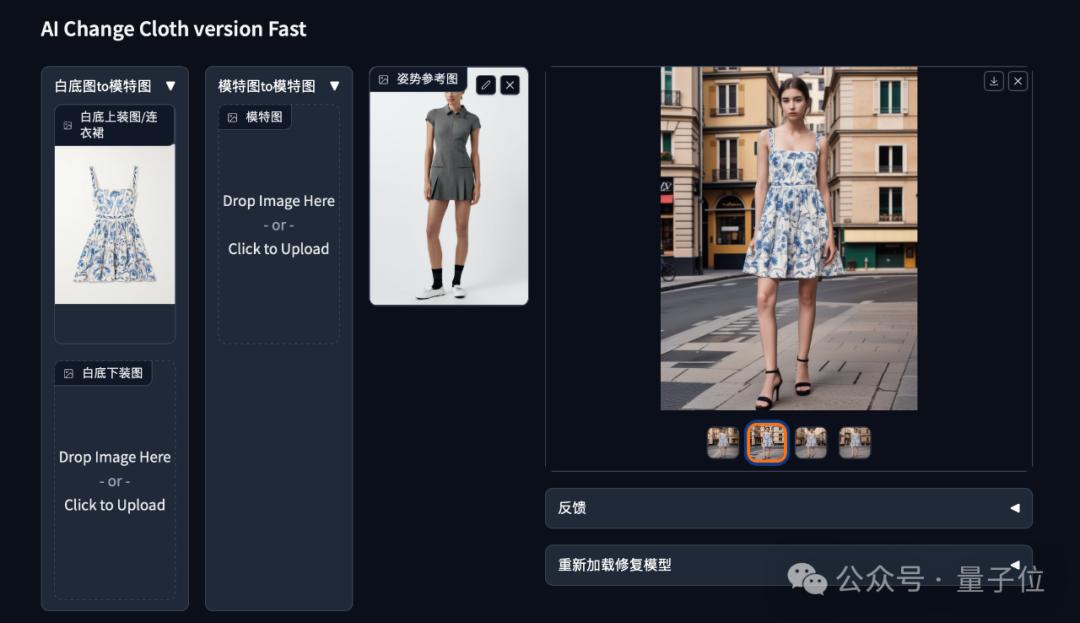
首先需要上传一张服装图像,接着上传可供参考的模特姿势,同时选择模特的性别、人种等,继而再上传(最少)一张背景参考图,就能得到最终的模特上身效果。
衣服整体还原效果还是挺真实的。
实测第二站,是FancyTech另外一个主打的功能,图生视频。
上传任意一张图片,点击下方的运行键即可。
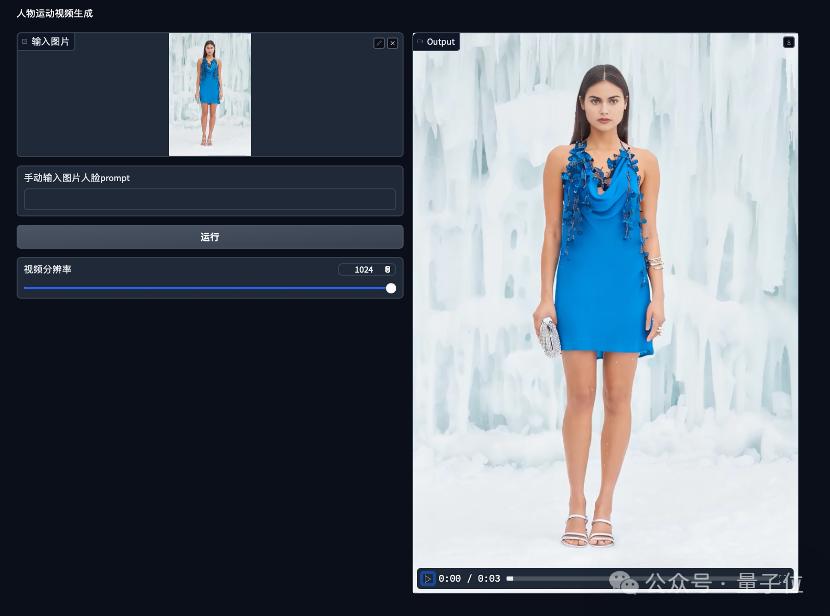
等待时间大概在35s左右,我们得到了这样一个效果:
模特有眨眼动作,肢体中心也有自然的轻微转移,商品、模特都没有变形。

我们还试着多跑几次,每次出来的效果都很稳定。

而相同的事情丢给同为AIGC视频生成工具的Pika干,得到的效果是这样的:
动作幅度更大,但商品细节似乎有模糊处理。不知是否是模特表情夸张引起的五官变形,恐怖谷效应扑面而来。

两者对比,能看出FancyTech生成的视频结果在商品实物还原方面,还是很能打的。
为了试验它的效果稳定与否,我们又对比了一组。
这是FancyTech的效果:

这是Pika的效果:

这一组效果也都还不错,并且能感受到,FancyTech也可以有较大的人物动作幅度,有接近真人模特的动作展示,视频时间也能达到4s左右。
在给品牌使用的流程上,这些生成都是自动化的,从生成图片到视频、再到发布,都不需要人工参与。
就怎么说呢,跟某宝上售卖服装配的展示视频好像也没差?
看了一下别人利用FancyTech做出的商品广告,比我们这种纯小白做的,那是酷炫多了。
最最重要的是,看起来不穿帮,对现实场景有比较好的还原,不会一眼假是AI做的:
技术上是如何实现的?
亲身体验下来,FancyTech是有两把刷子在身上的。
定位也很明晰:聚焦电商和广告视频领域,利用AI驱动生成商品表达视频,能基于用户反馈调整视频细节,还能附带画外音、音乐、字幕等。
而且与市场上很多的AI视频生成工具,包括Sora、Pika等在内,FancyTech采用的方式不是文字生成视频,而是图片生成视频。
但这样的AIGC视频生成效果,背后究竟是通过什么原理实现的?是基于某些开源方案打造,还是重新纯自研?
带着种种问题,我们向FancyTech求解了一下背后的技术细节。
“FancyTech是自研的全链路底层技术,然后配合工程化能力。”对方倒也没藏着掖着,直接亮出来了自家的技术实现方案。“我们学习了大量的热门视频,自研的模型来写脚本,再通过AI Agent串联各模型生成视频。”
整体来说,FancyTech的工作流包含以下三个组成部分:
视频模型:生成素材,提升素材丰富度;
AI Agent:自动化生成,提升交付效率;
数据效果反馈:自动优化素材,提升发布效果。
三者形成循环,实现数据驱动,达到持续优化视频生成效果的目的。
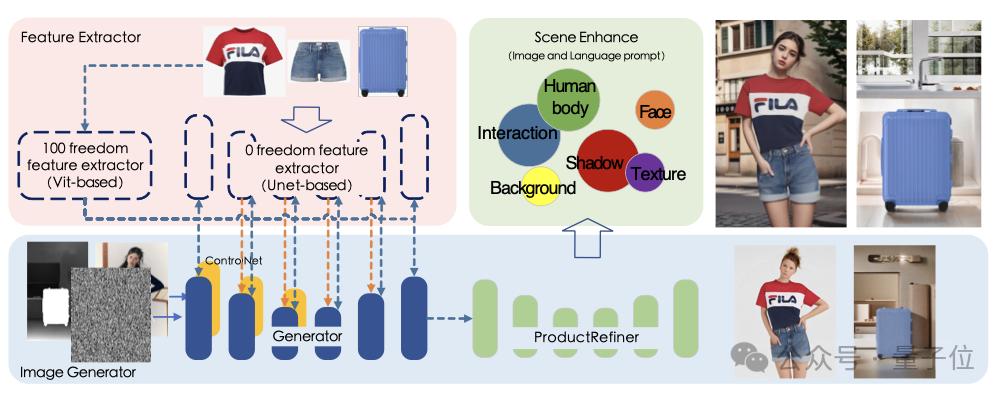
更进一步的,我们则就最基本的视频模型方面进行了了解。
以前,AI无法真正取代商品展示拍摄,是因为效果不尽人意,尤其是难以模拟3D场景的真实动态。
但看看刚才亲自试出来的效果,不管是连衣裙本身面料和重量带来的垂坠感,还是模特动作变换导致的裙摆摆动,FancyTech都能展现出自然效果。
是怎么做到的呢?
一是FancyTech自己组建了数据标注团队,在训练过程中收集了大量的真实数据,进行清洗、标注,从而拥有了质量够高的数据集。
这样一来,就非常有利于最终产出优质效果的视频。
二是构建覆盖多类型商品的场景图生成框架,实现全自动化、多品类、多种组合搭配的商品生成、场景生成、细节复原与增强。
为了精确保持商品细节并进行合理变化,FancyTech还自研了图像特征提取器,将图像特征分成100自由度(合理变化)和0自由度特征(保持细节)。
第四点是,针对不同商品和细分品类,团队训练了自己的多模态(文+图)图像生成模型DeepVideo。
在自研模型的基础上,FancyTech团队采用元学习和强化学习的训练方案,持续提升不同控制条件下的泛化能力。
第五点也是FancyTech着重强调介绍的一点,是团队自研商品细节增强模型,ProductRefiner。
ProductRefiner负责的功能是加强细节复原,此外,还能描述输入可选细节,进一步提升商品细节展现。
在训练过程中,ProductRefiner选用了自监督训练方法,无需构建成对数据集,极大地降低了成本。
而且能对模特的上身和下身着装进行分割,在保证输入图像背景不变的前提下,对上衣和下衣进行修复和还原。

阿里系创始团队
就在这样的技术加持下,去年一年,FancyTech和超过500个国内外品牌进行合作,日均生成视频量超过10万。
而且根据朱啸虎公开的说法,FancyTech是在赚钱的:
去年收入达到5000多万,(比他投资时的2022年)涨了五六倍。
在基础大模型业务商业化路径仍然不分明的时候,聚焦特别场景,能有这样一个成绩,FancyTech背后团队究竟是什么来历?
据量子位了解,成立于2020年的FancyTech,背后是一支阿里系团队。
其创始人兼CEO,William Li,花名空界,曾是天猫奢品Luxury Pavilion初代负责人,也在手机淘宝历任分享平台和用户社群的产品运营负责人。
创始团队的其他成员,也都来自于手淘、天猫、阿里云等资深算法、运营及技术岗位。
看到这里,你一定也对FancyTech能深谙电商展示玩法不足为奇了。
现在,成立快4年的FancyTech已经将算法团队扩大至近百人规模,其中算法团队近20人,数据标注团队约50人。
在我们联系上FancyTech的时候,这支队伍刚刚对产品进行了一次迭代,视频长度从原来的2s,拓展至4s左右。
那么,有技术,有市场,有商业化,FancyTech的下一步又有什么打算?
量子位得到的答案是这样的:
Sora的出现,把其他所有的视频模型公司都打回了同一起跑线上——这对我们来说反而有利。
我们走商业化路线,追求的是商品的还原,而Sora验证了下一步该怎么样去增强持续性。
目前,FancyTech内部算法团队已经开始投入自家Transformer+Diffusion框架的研发,预计在今年4、5月份会拿出成果。
是的没错,尽管有了Sora那样惊艳世人的模型出场,FancyTech的目标倒是一直没变过:
“我们希望成为长视频赛道里,对现实还原得最好的公司。”
— 完 —
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

