- +1
历史与AI的距离:聊天机器人在历史学科科研中的应用
2022年11月30日,OpenAI公司的聊天机器人ChatGPT上线。半个月之后,就有在美国大学教书的友人说起ChatGPT引发了自己对工作的焦虑。2023年9月,《美国历史评论》专门探讨21世纪历史研究新实践的栏目的“历史实验室”(History Lab)发表了一组题为《人工智能和历史实践》的圆桌论文,及时回应了美国同行对人工智能是什么以及能如何与历史学进行互动的疑问。七篇文章关联到了对历史学研究者来说相对更熟悉的议题,比如“数字史学”,更多的则是一些相对新的名词,比如“深度学习”“噪声效应”等等。
中文媒体对人工智能的兴趣在2023年达到一个新高度。高等院校同样如此。例如,2023年12月28日,美国罗文大学杰出教授王晴佳受复旦大学西方史学史团队邀请作了题为《数字化、人工智能和历史学的未来》的讲座,全面而深入地讲述了人工智能对历史研究的影响,让笔者深受启发。
在刚刚过去的龙年春节期间,OpenAI发布的文本到视频转换模型Sora展现的样片又引发了一轮激烈的讨论。无论用户的要求是刻画当代时尚女性行走在东京商业区的情景,还是模拟淘金热期间的加利福尼亚州的样貌,Sora都能较为准确乃至栩栩如生地实现。OpenAI甚至声称Sora能够理解用户输入的内容在物理世界中的存在方式,这使得以往的AI视频生成工具相形见绌。

与此同时,谷歌在大模型信息处理能力的赛道持续发力,推出了Gemini 1.5 Pro。据称它可以处理高达100万个tokens的上下文窗口,差不多对应一小时的视频、11小时的音频、超过30,000行代码的代码库或超过700,000字的文本(约等于《伊利亚特》和《奥德赛》的文本量相加再翻一倍)。这些革新体现出人工智能(Artificial Intelligence)的计算能力在不断以惊人的速度提升。《经济学人》杂志在2023年2月初刊载了《人工智能的繁荣:历史的经验》一文,将GPT的出现和亨利·福特的企业开始使用流水线生产汽车相提并论。易言之,人工智能的繁荣将不仅仅是信息技术领域快速发展的标志。由此而生的新技术、新产品和新服务很快会渗透到人类生活的许多角落,进而催生人类社会的变化。
你与AI的距离:很近又很远
对于身处高校的学者和学生而言,AI大模型及相关产品快速迭代带来了许多视觉和心理上的冲击。在应用层面上,对于数据科学(Data Science)的研究者和依赖电脑进行大数据分析的研究者(包括数字人文的研究者)来说,早已熟稔ChatGPT,大模型、机器学习之类的概念,各种分析工具和代码工具已融入自己核心的工作流,创造出拥有极佳视觉效果的学术成果。不过,更多的师生是利用聊天机器人来处理邮件措辞、文章改写、日常报告生成等重复性强的琐事。“艺高人胆大”的“新科技爱好者”则可能在过去一年里体会到了大语言模型的“致幻术”,如从机器人那里获得了“西南联大的重要创始人之一杨开慧成功参加了位于苏黎世的第七届国际数学家大会并获得了惟一的一枚铜牌”这样的“新知”,着实为痛苦的期末周送来了富有新意的笑料,强化了人工智能聊天机器人仍是“人工智障”的刻板印象。
从学术研究的角度来看,有鉴于中文历史学期刊的论文发表周期动辄以年计算,且仍有许多刊物无法给文章配图,要针对正在迅速发展的、媒体形式极为多样的人工智能展开讨论存在相当大的困难。英文的历史学期刊则在ChatGPT面世后不久,便开始传递不同领域学者的洞见。例如,《历史与理论》杂志在2022年12月出版了《数字历史和理论》专刊。其中收录的10篇专论针对人工智能时代下的历史学与历史叙事等宏观主题展开辩论,关注焦点则是史学理论层面的思考。
其中马尼·休斯-沃林顿(Marnie Hughes-Warrington)在有关数字历史和理论的专刊上发表的《走向对人工历史创造者的认可》已经提到了AI在历史编纂学中的潜力。他认为,人工智能的历史学应用不仅局限于模仿人类的历史叙事,而是通过结合推理和普遍接受的观点,形成了一种新的历史叙事方式。沃尔夫·坎斯泰纳(Wulf Kansteiner)则在《历史学家的数字兴奋剂:历史、记忆和历史理论能否人工智能化?》一文中指出,虽然GPT生成的文本无法保证结构上的真实,但史学理论家可以让定制的大型语言模型编写一系列关于相同事件的描述性、叙事性和论证性历史,从而探究描述、叙述和论证在历史写作中的精确关系。


上述学者的讨论固然在理论层面颇有建树,但鲜少涉及大型语言模型产品的具体使用方法和技巧。为数不多的例外是美国林登伍德大学(Lindenwood University)的学者团队在2023年年底在《元宇宙》(Metaverse)上发表的论文《数字历史人物复活:以玛丽·西布莉为例的定制ChatGPT案例研究》。该文以林登伍德大学的创始人玛丽·西布莉(Mary Sibley)为实验对象,将她的海量日记内容作为Claude 2.0的训练数据,开发出一个能够复现西布莉独特语调和观点的聊天机器人,类似于2019年热播日剧《轮到你了》第二季中的AI女主角。这一成果展现了一种新颖的历史研究和互动学习方式,也为学界如何利用数字技术复现拥有海量史料的历史人物提供了启发。
实际上,当下大语言模型产品的能力已经足够成为高校师生日常课程学习和科研工作的助手,在信息检索、文献阅读、笔记管理乃至科研创新等事务中发挥关键作用。尤其对于全球史的研究者来说,常常需要处理大量涵盖了不同地区、国家和文明间的相互联系与比较的材料和文献。运用AI产品来提高信息检索效率和处理能力,有助于更深入地探索和分析这些复杂的历史关系,来提高研究的深度和质量。然而问题在于,如何将AI产品整合到自己的学习或工作流程之中,优化或定制自己的专属机器人,为其增添功能,提升自己的输入和输出效率,也就是利用人工智能来自我赋能,从而更高效地处理庞杂的信息。
绝知此事要躬行:管窥国内大模型产品工具箱
目前大部分人使用大语言模型产品的方式是直接以自然语言输入自己的问题到对话框,并等待AI的回复,仿佛在与一位真人助手交谈。这简单的过程中其实蕴含着很多值得学习的工具性知识。在互动中,AI回复的质量与大模型自身能力密切相关,也受到用户发出的提示词(Prompt)内容的重要影响。固然,目前网络上已经存在许多详细的提示词指南,但一份理想的提示词是需要用户自己在反复实践的互动中不断地锤炼出来的,这就要求用户所处的网络社区中有AI产品满足以下需求:易获得、模型性能好,且有充足社区资源提供指导。
除了前文提到的ChatGPT和Gemini Pro这两个大模型领域的“当红流量小花”,国内也有不少相当优秀的同类产品可供使用。比如月之暗面科技推出的智能聊天机器人(Chat bot)Kimi Chat就有惊艳的长文本处理能力,能够支持长达20万汉字的输入。又如清华系创业公司的智谱AI。用户可以在智谱清言的客户端体验GLM-4支持的“长文档解读”“高级联网”“数据分析”“AI画图”等多样化功能。尤其,这一开放平台目前向实名认证的新用户免费赠送数百万tokens,对想要进一步探索AI世界的新手十分友好。字节跳动推出的智能体创建平台“扣子”(Coze)同样颇受好评,原因在于能让缺乏编程经验的“小白”快速上手制作自己专属的聊天机器人,并利用知识库(Knowledge),插件(Plug-in),工作流(Workflow)等功能增强机器人的性能。
当然,选择哪款大语言模型产品最终取决于个人的需求或偏好。用户如何通过持续的使用和探索,找到能够融入自身现有工作流的工具,从而有效提升学习和工作效率才是关键。接下来我将以学习第一次世界大战的历史为应用情境,利用Kimi Chat、智谱AI开放平台、“扣子”来简单展示如何使用提示词优化(Prompt Optimization)、知识库、插件来提升模型的回答质量,使之成为历史学的学习与科研助手。
四两拨千斤:人工智能助手的快速优化策略
聊天机器人的回答质量受到模型的数据集和参数影响,目前,许多从事垂直领域大模型开发的研究者积极应用微调(fine-tuning)技术来训练大语言模型,使之在特定领域有更好的表现。但大部分非计算机专业的师生并不具备微调所需的算力资源和专业知识,掌握这一技术的时间成本也足以令人望而却步。但是,在不改变模型的前提下,从用户开始琢磨自己想问什么,到聊天机器人最终给出回复,中间有许多步骤提供了可优化的空间(如下面的流程图所示的A和D),来尽可能地使机器人的回复贴合用户所期待的答案。换言之,在人机互动中,大语言模型聊天机器人通过其预训练能力理解用户输入,并可能结合实时检索来响应查询。用户可以做的,则是向机器人更明确表述自己的需求,“教”机器人如何提取某些信息,这往往可以通过系统的“提示词工程”(Prompt Engineering)来实现。而提供知识库或插件,则是为机器人在最终生成回复之前提供额外的信息支持,市面上大部分大语言模型产品已为缺乏编程和机器学习基础的用户提供了此类服务,相信大家可以花费较短的学习时间来掌握相关应用。

以下是三个与第一次世界大战史有关的研究情境中如何使用Chat bot的简单视频介绍,笔者在这里抛砖引玉,希望能够激发大家的好奇心,去大胆使用这些产品,将自己的聪明才智和人工智能技术结合,探索出学习的新方法,攀登上学术的新高峰。
可以预见的是,在2024年剩余的9个多月里,科技巨头和新秀们将会推出功能更强大的模型和服务更完善的产品,AI行业的发展也将引发持续关注。近日,Anthropic就发布了Claude 3系列大模型,其中功能最强大的模型Opus在各种基准测试中有着优于GPT-4和Gemini 1.0 Ultra的表现,为人工智能领域的火热竞争添上一把新柴。

一方面,公众对科技的迅猛发展感到惊喜,但另一方面,网络社区对“通用人工智能(Artificial General Intelligence)掌控世界”“传统行业迅速消亡”和“落后的人类被机器取代”等假想情景表达了担忧。这份焦虑甚至被用作AI课程销售的噱头,在短期内造就了“模型未动、卖课先行”的奇观。
事实上,目前通用人工智能仍然只是一个哲学概念,我们离一个完全具备人类般复杂认知架构的AI系统的诞生还有相当远的距离。哪怕是引发街头巷尾热议的文生视频大模型Sora,也并非很多自媒体所吹捧的“大世界模型”,或是“物理规律的掌握者”。其核心工作原理是结合了扩散模型和Transformer架构:扩散模型从初始的噪声出发,逐步细化成所需的视频内容;而Transformer架构则负责连续视频帧的处理,确保视频中动作的流畅度和自然性。AGI的最终实现,也即是让机器模拟人类的认知过程、理解复杂的概念和环境,并具备自我学习和自适应的能力,仍是需要多学科领域深度合作解决的难题。
在时代的洪流中,与其每天刷手机阅读媒体关于人工智能的“爆炸式”报道,默默做一个技术革命的旁观者,不如积极动手,探索如何利用现有的人工智能产品和服务来增强我们的认知能力,而“聊天”机器人则是我们实现这种“智能放大”(Intelligence Amplification)的重要交互平台。通过上面的简单介绍其实已可以看出,它能做到不仅仅是陪人类聊天和进行简单的信息搜索。通过改进提问方式,以及给机器人增加知识库这一类的“小配件”等方法,我们可以用这些智能体来辅助学习,定制学习材料,甚至让它们担任研究助理,承担简单的数据分析和可视化等工作。
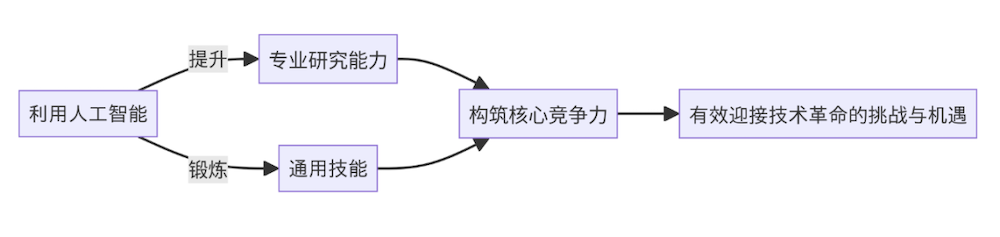
通过运用这种人机协同工作模式,我们能够把重复性较高的事务交由人工智能机器人去自动化处理,从而提升个人知识的吸收与输出效率,专注于自身更具创新性的工作。机器人的辅助能够使我们能够深入整合专业知识,扩展研究视野,进而激发创新思维。此外,与聊天机器人的互动也是对我们通用能力的一种锻炼,它帮助我们学会如何更加清晰地“思考”“提问”和“反思”;如何高效整合信息渠道,提高接收信息的质量;以及如何为自己设计并优化一个高效的自动化工作流程。虽然这些能力在传统的标准化考试中并不是明确的考点,但在学术研究和职场工作中,自主学习探究,提出有效问题,并寻找创新突破能力是具有价值的。综上所述,借助人工智能,我们不仅能够提升专业研究能力,还能锻炼通用技能,从而构筑起自身的核心竞争力,以求有效迎接技术革命的挑战与机遇。
(本文作者李思玥系paideia.ai提示词工程师,朱联璧系复旦大学历史学系副教授。)



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

