- +1
Mistral Large来了,OpenAI或迎劲敌
Mistral AI昨夜放大招,正式发布Mistral Large模型,并且推出对标ChatGPT的对话产品:Le Chat。
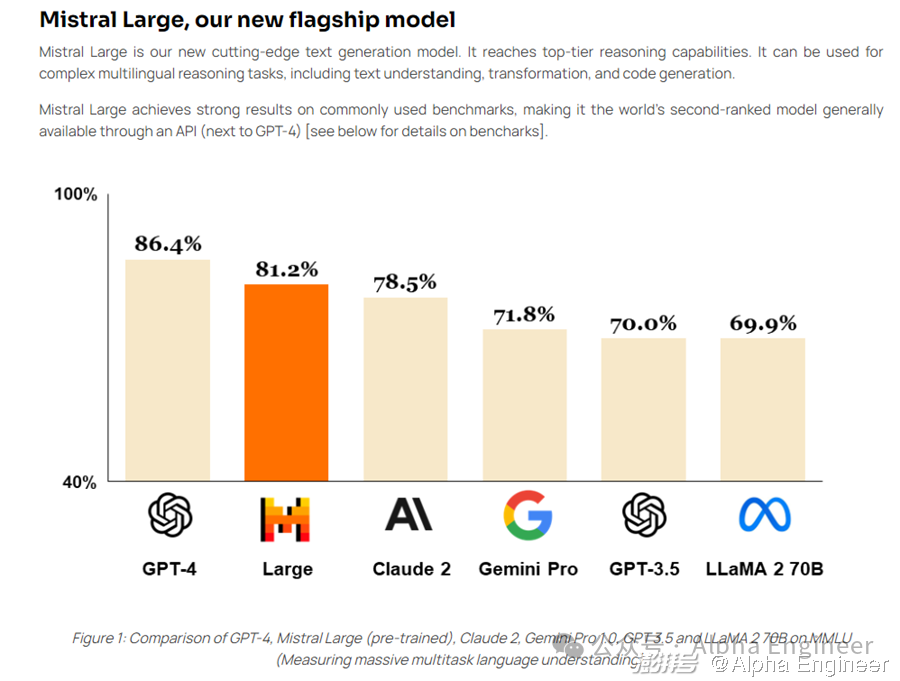
作为Mistral新推出的旗舰模型,本次发布的Mistral Large在常识推理和知识问答上均表现出色,综合评分超过Gemini Pro及Claude 2,仅次于GPT-4,荣登世界第二的宝座。
说到Mistral相信大家并不陌生。
对,就是那个二话不说上磁力链接的Mistral。
去年12月8日,Mistral AI在几乎没有任何预热的情况下,直接在Twitter上低调发布了最新大模型的下载磁力链接,引爆整个AI圈。
清新脱俗的画风让Jim Fan不禁高呼:Magnet link is the new arxiv。


时隔不到3个月,这次Mistral又带给了我们怎样的惊喜呢?
惊喜1:精通多国语言,能文能武能Coding
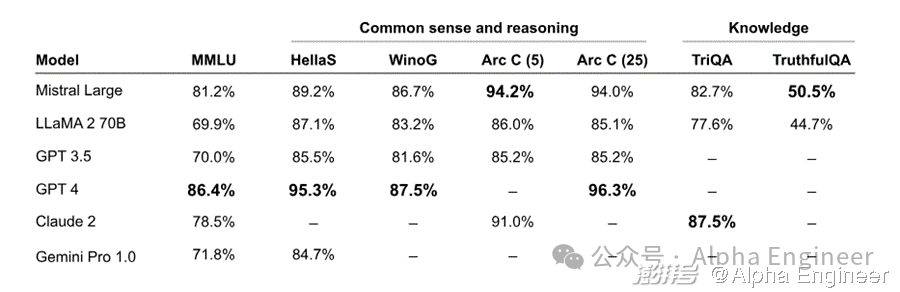
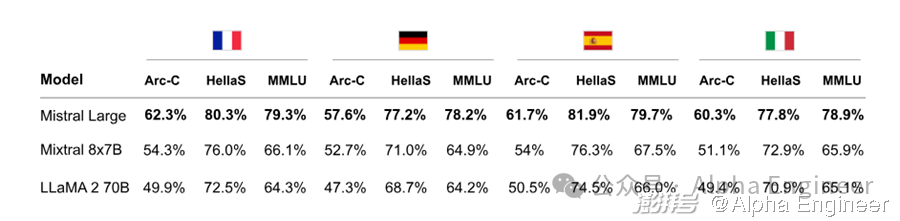
根据官方文档描述,Mistral Large模型精通包括英语、法语、西班牙语、德语和意大利语在内的多国语言,达到母语水平。
在HellaSwag、Arc-C、MMLU等benchmark上,Mistral Large的性能表现碾压Llama 2 70B,后者是目前世界公认的最强开源大模型。
与此同时,Mistral Large在数学和代码上的能力也不弱,在MBPP pass@1、Math maj@4、GSM8K maj@8 and GSM8K maj@1 上均有相当不错的表现,超过了GPT-3.5。
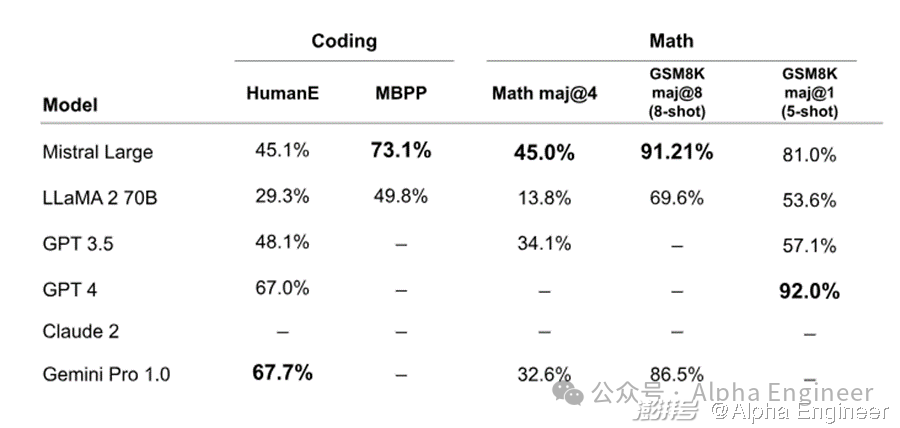
惊喜2:价格只有GPT-4的1/7,支持32k上下文窗口
32k tokens的上下文窗口可能不太直观,具体来说约等于2万个英文单词的长度。
GPT-4-32k目前的价格是这样的:一百万个输入token花费60美元,一百万个输出token对应120美元。
相比之下,根据Mistral Large API的报价,一百万个输入token定价8美元,一百万个输出token对应24美元。
同等上下文窗口的条件下,Mistral Large的定价比GPT-4便宜了5-7.5倍,可谓诚意满满。
惊喜3:牵手Azure,微软生态渐成
值得玩味的是,在模型发布的同时,Mistral特意提及了与微软Azure的合作。Azure的客户可以直接通过Azure AI Studio和Azure Machine Learning访问Mistral的模型。

微软作为OpenAI背后的金主,一直以来也在与其他大模型公司积极合作。

去年7月,微软就与Meta达成合作,将Llama 2模型上架到Azure供客户使用。
不得不佩服Nadella的战略眼光和生态手腕。

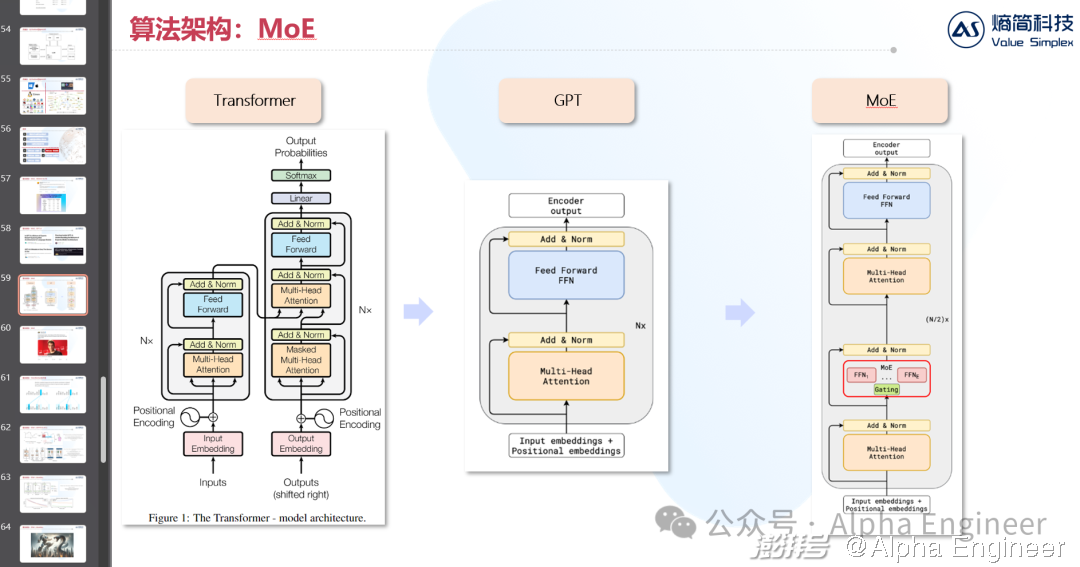
MoE再下一城
Mistral一直以来是MoE路线的拥趸。去年12月初发布的Mistral 8×7B就是一个技术MoE架构的大模型。
当时Arthur就发出预告,将在24年推出性能对标GPT-4的MoE模型,没想到幸福来得这么快。
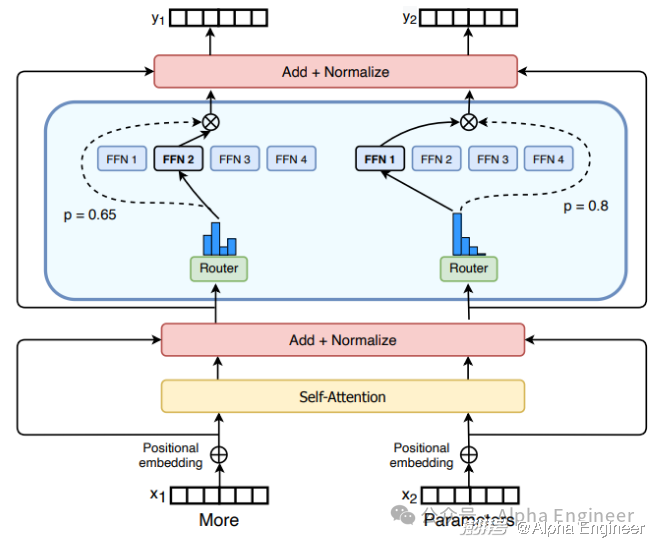
MoE的全称是Mixture of Experts,即混合专家模型。
MoE是一种非常有特色的算法架构,通过引入“专家+路由”的机制,在增强Transformer模型性能的同时,也有效降低了训练成本。
通过引入稀疏性(Sparsity),让大模型在推理时,每次只激活部分参数,让不同的“专家”网络来解决不同的问题。
这样一来,针对不同的输入,大模型能够按需选择性的激活不同的“专家”网络,使得大模型在算力成本不变的前提下,大幅提升参数规模。
在一项叫做GLaM的研究中,研究员训练了一个性能等同于GPT-3的MoE模型,只消耗了1/3的能源。在算力昂贵的今天,MoE为我们打开了一扇窗。
关于MoE架构,此前我专门写过一篇文章《【干货】大模型前瞻研究:解码MoE架构》,做过详细的分析和探讨。
今年初,我在Nomura的分享会上,也专门讲过MoE架构,建议大家看看这篇报告,还是输出了不少干货的。

本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2025 上海东方报业有限公司

