- +1
落地端侧,2B模型如何以小搏大?|对话面壁CEO李大海

文|郝 鑫
“AGI是一场马拉松”,面壁智能联合创始人、CEO,知乎CTO李大海道。
作为一个马拉松的爱好者,李大海深知在大模型的竞争中,一时的“快”只是暂时的,更重要的是把赛程中的每一步都跑下来,跑踏实。
回顾面壁智能的发展历程也确实如此,2018年脱胎于清华NLP实验室,发布了全球首个知识指导的预训练模型ERNIE;2020年成为悟道大模型的首发主力阵容;2022年成立OpenBMB开源社区;2022年面壁智能开始公司化运作;2023年把Agent作为主要发力方向,相继发布了AgentVerse、ChatDev、XAgent等智能企业框架。

从大模型Infra层到Agent应用层,从科学实验室到商业化落地,夯实走的过程中,逐渐演化为了2023年的冲刺能力。去年,就在国内外还在研究Agent定义的时间点,面壁智能已经率先在行业内提出了群体智能的框架和Agent商业化落地的方案。
2024年,大模型应用新篇章即将开启之际,面壁智能又出乎意料地发布了端侧大模型和面壁MiniCPM。
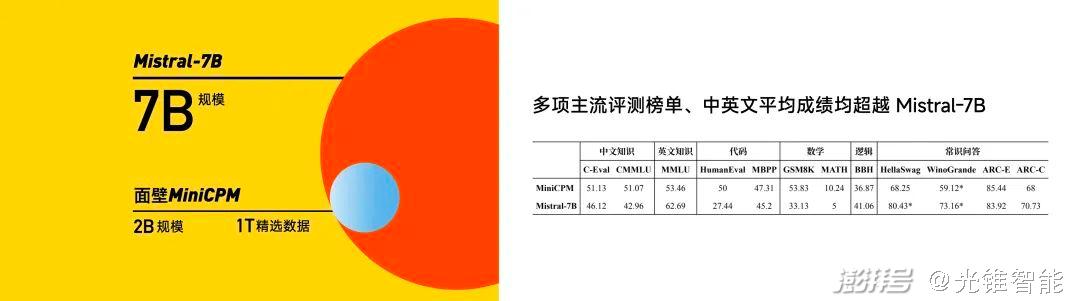
对标国外Mistral-7B,核心就是以最小的模型规模,实现最强的模型效果,这项能力被李大海总结为“以小搏大”、“以大搏聚”,这也是面壁智能的核心能力之一。
从各项结果来看,小钢炮MiniCPM用2B的规模、1T的精选数据,从性能指标上打败了Mistral-7B、微软明星模型Phi-2、蒸馏GPT-4、13BLLaMA等一众主流模型。并且将模型部署的成本彻底打了下来,在侧端,1元=1700000tokens,仅是MiniCPM在云端的1%。
从大模型到Agent,再到侧端模型,总体来看面壁智能的布局,可以发现其已经在为大模型应用的落地和爆发做准备。大模型提供底座能力支撑,Agent做为脚手架打通应用的“最后一公里”,最后在侧端进行部署和运行。
正如李大海所言,“侧端模型能够为大模型和Agent服务,因为端跟云的协同能够更好得让应用落地。端侧模型是大模型技术的积累,在如何把模型小型化,让云上的模型能够用更小的规模实现更好的效果方面,是一脉相承的关系。”
2024年已经缓缓拉开了帷幕,大模型战事瞬息万变。光锥智能对话面壁智能联合创始人、CEO,知乎CTO李大海和其团队,深入探究面壁智能核心竞争力的修炼秘密,同时展望2024年的大模型行业格局。
核心观点如下:
1、“以小搏大”、“以大搏聚”,用2B的模型做出了比2B模型更大的模型效果。
2、“沙盒实验”就是在一个模拟仿真的环境里面,用更小的成本和代价去搞清楚规律。
3、端侧大模型不能只看端侧,未来一定是云端协同。
4、Agent私有化部署成本有两块,一是模型厂商对模型使用收费,一是客户部署完以后的推理成本。
5、面壁智能的差异化竞争策略可以总结为,高效和一体化,即高效推理和模型+Agent一体化。
6、CV是一个单点技术的突破,而大模型是在各个技术点上探索和升级,还远远未达到技术成熟阶段。
以下为对话实录:
Q:为什么选择在2024年开端时候,发布MiniCPM侧端大模型?出于怎样的考虑?
A:在MiniCPM的背后,是做了上千次的沙盒实验,在这过程中我们掌握了“以小搏大”、“以大搏聚”的能力。正如大家所见,我们用2B的模型做出了比2B模型更大的模型效果。这个核心能力,我们本来打算运用到未来新的模型研发上。但我们发现,现阶段,“以小搏大”、“以大搏聚”的能力,运用到端侧上能够产生突破性的进展,所以这才促使我们把模型赶紧做出来。真正做出MiniCPM时间不到一周,根本上得益于过去上千次的实验积累,而这些工作面壁智能在2023年就已经完成,所以MiniCPM可以看作一个厚积薄发的结果。

Q:您刚才提到“沙盒实验”在面壁智能模型训练中起到了重要的作用,可以展开阐释一下吗?
A:用形象的比喻来解释,沙盒实验就像就像航空里面的“风洞实验”。
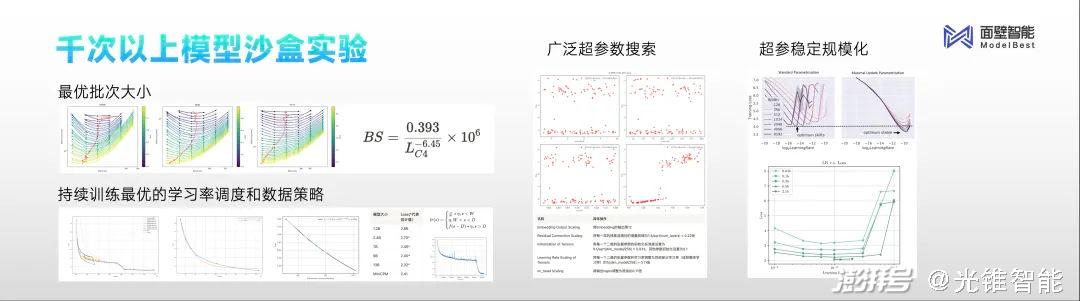
“沙盒实验”就是在一个模拟仿真的环境里面,用更小的成本和代价去搞清楚规律。我们希望通过这种方式,来搞清楚用什么训练方式能够得到何种表现规模的模型,这就是“沙盒实验”整体的目的和方法论。
我们发布MiniCPM之前做了上千次的模型沙盒实验,探索出了最优的配制,所有尺寸的模型可以通过最优的超参数的配制,保证训练任意大小的模型取得最好的效果。
通过上千次实验,最终可以帮助我们去学习,从特别小的模型,远比MiniCPM还小的模型到千亿甚至比千亿还大的模型的训练控制方法,以便最后得到更好的模型训练效果,从这个角度来看,不管是端侧模型还是千亿级模型,甚至更大的模型,面壁智能的“沙盒实验”过程都能被覆盖。
Q:MiniCPM仅用了1T的数据量就完成了模型训练效果,联系到您知乎CTO的身份,数据的来源与知乎有多大的关系?
A:我们精选了1T的数据,筛选的一个重要标准就是要展现数据的多样性。知乎的高质量数据在模型训练过程中起到十分重要的作用,具体的方法就是,以非常细的颗粒度去把数据打散后,做算法的自动选取。
Q:此次面壁开源了MiniCPM全家桶,作为创业公司,面壁智能如何看待开源这件事?这回为什么选择开源侧端大模型?
A:面壁智能在2022年就成立了开源社区。面壁智能一直是开源的受益者,这也是团队能在AI领域走得比较快的原因。所以从我们团队成立之初,就秉承开源、开放的特点,人人为我,我为人人,能为整个行业做贡献,我觉得还是非常重要的。
另一方面,开源对建立影响力非常重要,有了影响力随之能带来资本的注意力、人才的注意力以及2B的客户注意力,这些其实都是建立商业逻辑的基础。
谈到侧端大模型的开发,虽然相对云端的大模型来说,是一个小模型,但实际上开发仍是一个特别复杂和庞大的任务。这里面涉及的技术难点有两个,一个是除了要能做出更小的模型,还得能释放出更大的性能;此外,模型推理、硬件推理性能、各层面的适配等等,都存在很多技术难点。面壁智能选择开源,也是希望能和手机厂商、APP开发者和领域专家合作,促成技术创新,达成更高效的解决方案,推动整个生态系统的繁荣。
Q:市场上很多手机厂商相继推出了各自的大模型,那未来面壁智能和这些手机厂商的关系是怎样的?大模型公司又如何切入到手机端侧市场中去呢?
A:端侧大模型不能只看端侧,未来一定是云端协同。云上的模型跟端侧的模型需要联动,这就意味着由同一厂商来做联动会更高效。以这个逻辑去推演,最终云侧和端侧的模型最好都是由专业的模型开发者去做。整体来看,这个事持续投入的门槛其实还蛮高的,所以我们不是特别建议手机厂商去持续的做这个事情,我觉得每个公司都有自己的商业考量。
Q:Agent在落地的过程中会遇到很多敏感的隐私数据,面壁智能在与企业合作中是如何解决数据痛点的?成本规模大概是多少?
A:在Agent落地方面,我们其实也在考虑这个问题,对于数据敏感型的客户,我们会做私有化部署方案来解决他们的需求。
私有化部署层面的成本主要分为两方面。一个是模型厂商对模型使用收费,另一个是客户真正部署完以后的推理成本。正是基于此,当特别大的模型完成私有化部署后,对客户来说,其推理成本就会变成一个比较大的成本障碍。在我们看来,不同的模型尺寸,有它所具备的能力和适配的场景,比如7B的模型大小,对标GPT-4的效果。
Q:在整个大模型市场中,跟头部大模型公司相比,面壁智能差异化竞争策略是什么?
A:面壁智能角色定位为商业公司,NLP实验室定位为科研,由于我们在产学研结合上有非常深厚的优势,所以面壁智能在模型Infra和Agent层面都有相应的积累,未来还是会继续扩大我们在技术上的优势。同时,也通过开源去团结更多的伙伴,一言以蔽之,面壁智能的差异化竞争策略可以总结为,高效和一体化,即高效推理和模型+Agent一体化。
Q:目前,面壁智能的主要目标客户是什么?主要收入来源有哪些?是如何思考商业化的?
A:因为我们C端产品才刚刚上线,所以目前商业收入来源主要来自B端客户。现在标杆客户有招商银行、西门子、中国易车网等一些比较知名的客户,集中在金融和营销等领域。我们跟易车刚刚达成了深度的战略合作,跟义乌小商品市场集团也达成了很重要的战略化合作态,这些都是在营销领域的一些重要成果。目前,端侧大模型的商业化模式还尚在探索之中。
Q:新的一年,面壁智能的战略规划是什么?2B和2C方向是如何选择的?作为公司的CEO,你的关注点有哪些?
A:整个2024年,面壁智能依然会坚持大模型+Agent的双引擎战略。

一方面,要继续推进提升我们的模型能力,在端侧已经发布了端侧模型,同时今年仍然会去继续提升基座模型能力,挑战GPT-4的能力;另一方面,要用Agent来解决大模型落地最后一公里的问题,提升落地效率,在此方向上,我们甚至制定了一个比较激进的收入目标。因为我们相信,大模型真的能够去给客户带来效率和效益的提升,也比较看好整个大模型市场。
在2B和2C方向选择上,其实并没有明确的划分,因为在我们看来都是大模型+Agent的上层应用,所以我们并没有把重点放在具体的哪个应用方向上。在现阶段,前端的应用落地比较聚焦,在C端方向,我们会特别关注情感陪伴这个方向,也就是给用户提供情绪价值。
比如,我们开发的“心间”应用上线了测试版本,里面有个特色功能叫做磕CP,内置了李白杜甫和清华北大的CP,用户也可以制造自己的CP,背后是用大模型做的推理。
从我自己关心的事情上来说,因为面壁智能在模型训练方面的积累已经非常深厚了,所以对我们模型能力提升还是蛮有信心的。对我们而言,这个方向的确定性比较高。未来,我个人其实会更关心模型落地,也就是应用的问题。
Q:行业内都在谈论2024年是模型转应用的一年,您如何看待这一趋势?以您的角度来看,未来市场竞争中是否还需要这么多的大模型厂商?最终什么样的模型厂商能够跑出来呢?
A:整个24年,行业都会更重视应用的落地,这是个大趋势。目前模型已经达到基本可用的状态,在这样的基础上去发展应用,我觉得是一个顺理成章的趋势。我们发布的“心间”,就是面壁智能在应用层积极布局的表现。
但我们认为,AGI就像马拉松比赛一样,是需要长期努力的目标,需要各个公司在技术上持续的积累。
从厂商分布来看,从2024年开始,大模型厂商会开始出现分层。我自己判断,分层出现的原因不是市场所导致的,更多还是因为技术,随着大模型的发展,技术的门槛会越来越高。
在市场层面,我认为大模型是一个行业级别的机会。我们看到,无论是做大模型基座,还是做应用,都有非常大的空间。因为市场足够大,所以很多公司可能都有机会能生存下来,最终能活下来的公司,一定是技术、产品和市场能力都很强的选手。
Q:就像您所说“AGI是一场马拉松”,这样的发展特性,对未来的行业格局变化有怎样的影响?
A:这回给行业格局洗牌带来许多不确定性,以我的观察,我觉得这不是2024年、2025年,甚至2026年能够分出胜负的事情。
回首过去CV发展的情况,会发现AI 1.0的竞争格局也不是在头两年确定的,即使到了第三个年头还是在发生非常大的变化,所以这启示我们要以长远的眼光看待行业的变化。当然,跟AI 1.0时代相比,2.0智能时代最大的差别在于,CV是一个单点技术的突破,而大模型是在各个技术点上探索和升级,还远远未达到技术成熟阶段。
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

