- +1
大模型年度榜单公布:GPT-4第一,智谱、阿里紧追
·通过题海战术提高大模型成绩,对于模型实际能力的反应是失真的,影响了模型研发团队的改进方向和模型的商业落地,“高分低能”伤害的是机构本身。
·国内大模型相比GPT-4还存在差距,推理、数学、代码、智能体是国内大模型短板,中文场景下国内最新大模型已展现出优势。
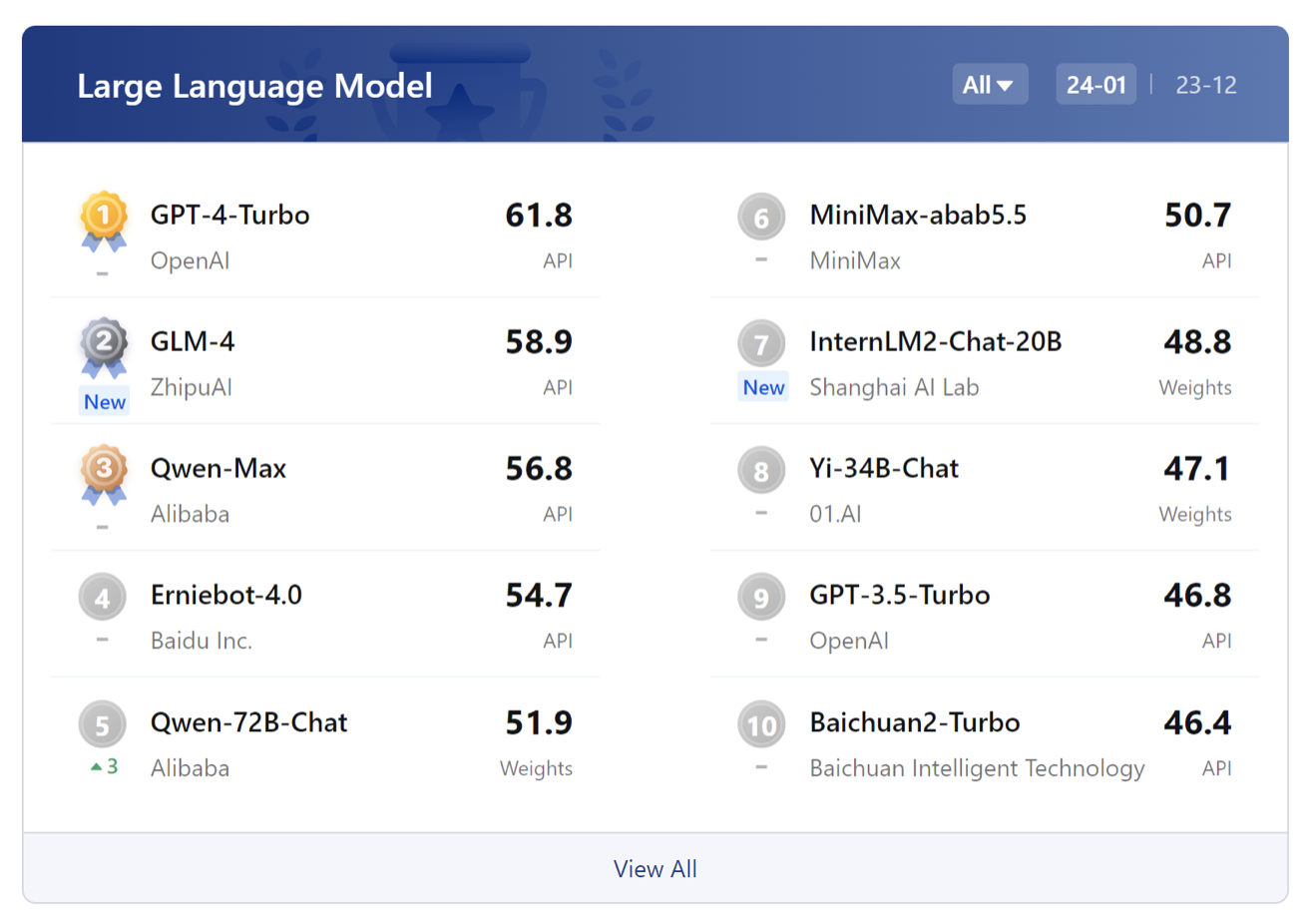
OpenCompass2.0大语言模型中英双语客观评测前十名(采用百分制)。商用闭源模型通过API形式测试,开源模型直接在模型权重上测试。
在一众试图“超越GPT”的大模型中,哪个大模型实力最强?大模型跑分、刷榜,如何测评大模型真实水平?
1月30日,大模型开源开放评测体系司南(OpenCompass2.0)揭晓了2023年度大模型评测榜单。对过去一年来主流大模型全面评测诊断后,结果显示,GPT-4-Turbo在各项评测中均获最佳表现,国内厂商近期发布的模型紧随其后,包括智谱清言GLM-4、阿里巴巴Qwen-Max、百度文心一言4.0。
评测是大模型的指挥棒和指南针,OpenCompass为模型提供评测服务,量化模型在知识、语言、理解、推理和考试等五大能力维度的表现。总体来看,大语言模型整体能力仍有较大提升空间,复杂推理相关能力仍是大模型普遍面临的难题,国内大模型相比于GPT-4还存在差距。中文场景下国内最新大模型已展现出优势,在部分维度上接近GPT-4-Turbo的水平。
中英双语客观评测:数学、代码仍是短板
OpenCompass于2023年7月由上海人工智能实验室在世界人工智能大会上推出,目前升级为OpenCompass2.0,构造了一套中英文双语评测基准,涵盖语言与理解、常识与逻辑推理、数学计算与应用、多编程语言代码能力、智能体、创作与对话等方面。
基于语言、知识、推理、数学、代码、智能体等六个维度,OpenCompass2.0构建了超1.5万道高质量中英文双语问题,并引入首创的循环评估(Circular Evalution)策略,系统分析了国内外大模型的综合客观性能。
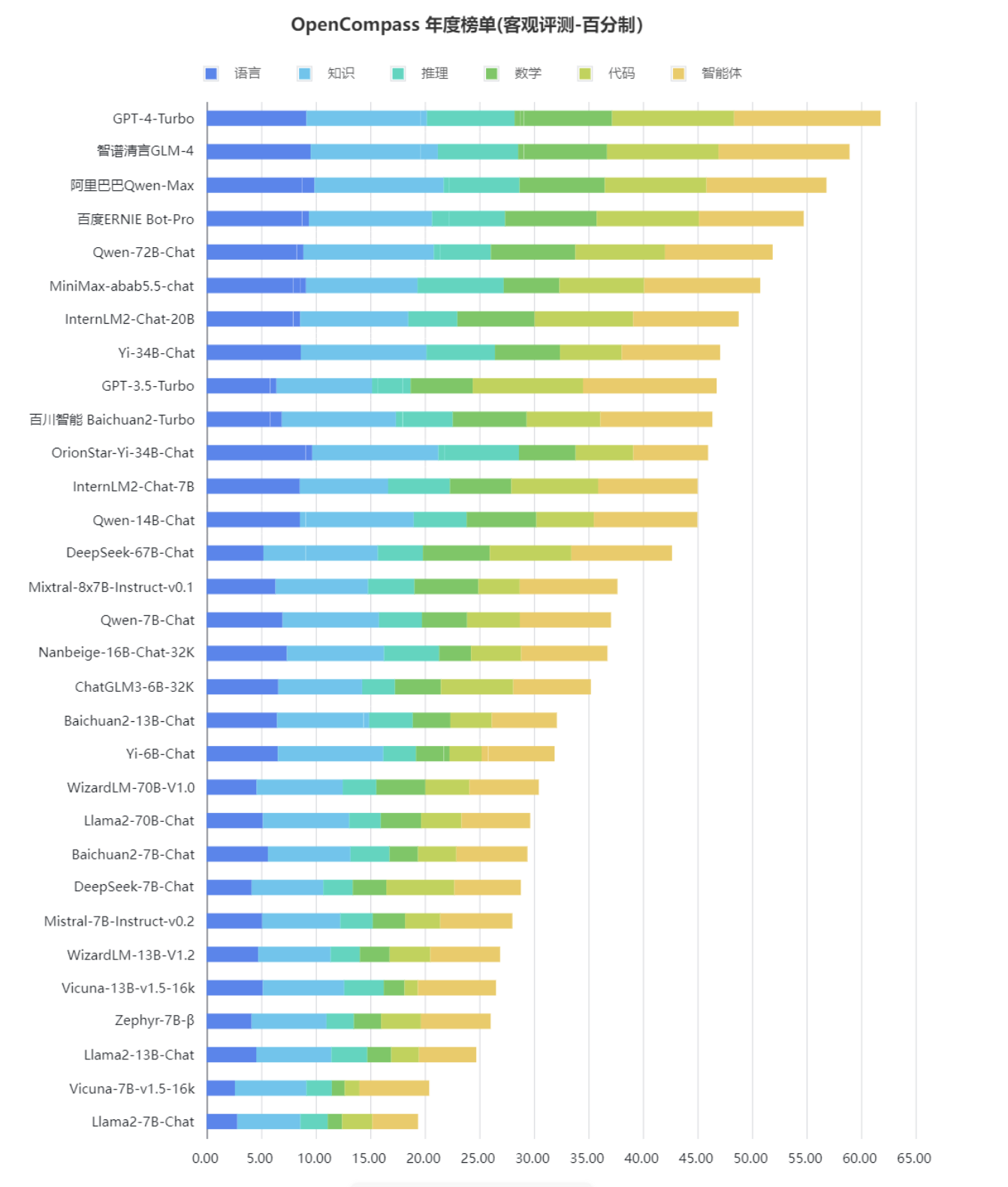
中英双语客观评测榜单。截至该榜单发布,部分新大模型尚未纳入本次评测。
在百分制的客观评测基准中,GPT-4 Turbo仅达到61.8分的及格水平。此结果显示,复杂推理仍然是大模型面临的重要难题,需要进一步的技术创新来攻克。
在综合性客观评测中,智谱清言GLM-4、阿里巴巴Qwen-Max和百度文心一言4.0具有较为均衡和全面的性能,这些模型在语言和知识等基础能力维度上可比肩GPT-4 Turbo。
推理、数学、代码、智能体是国内大模型的短板。GPT-4 Turbo在涉及复杂推理的场景虽然也有提升空间,但已明显领先于国内的商业模型和开源模型。国内大模型要整体赶超GPT-4 Turbo等国际顶尖的大模型,在复杂推理、可靠地解决复杂问题等方面仍需下大功夫。
中文主观评测:闭源模型接近GPT-4
基于语言、知识、创作、数学与推理等五个维度,OpenCompass2.0构建了超500道高质量中文问题,采用基于大语言模型对战的方式评测主流模型在开放场景下的对话体验。
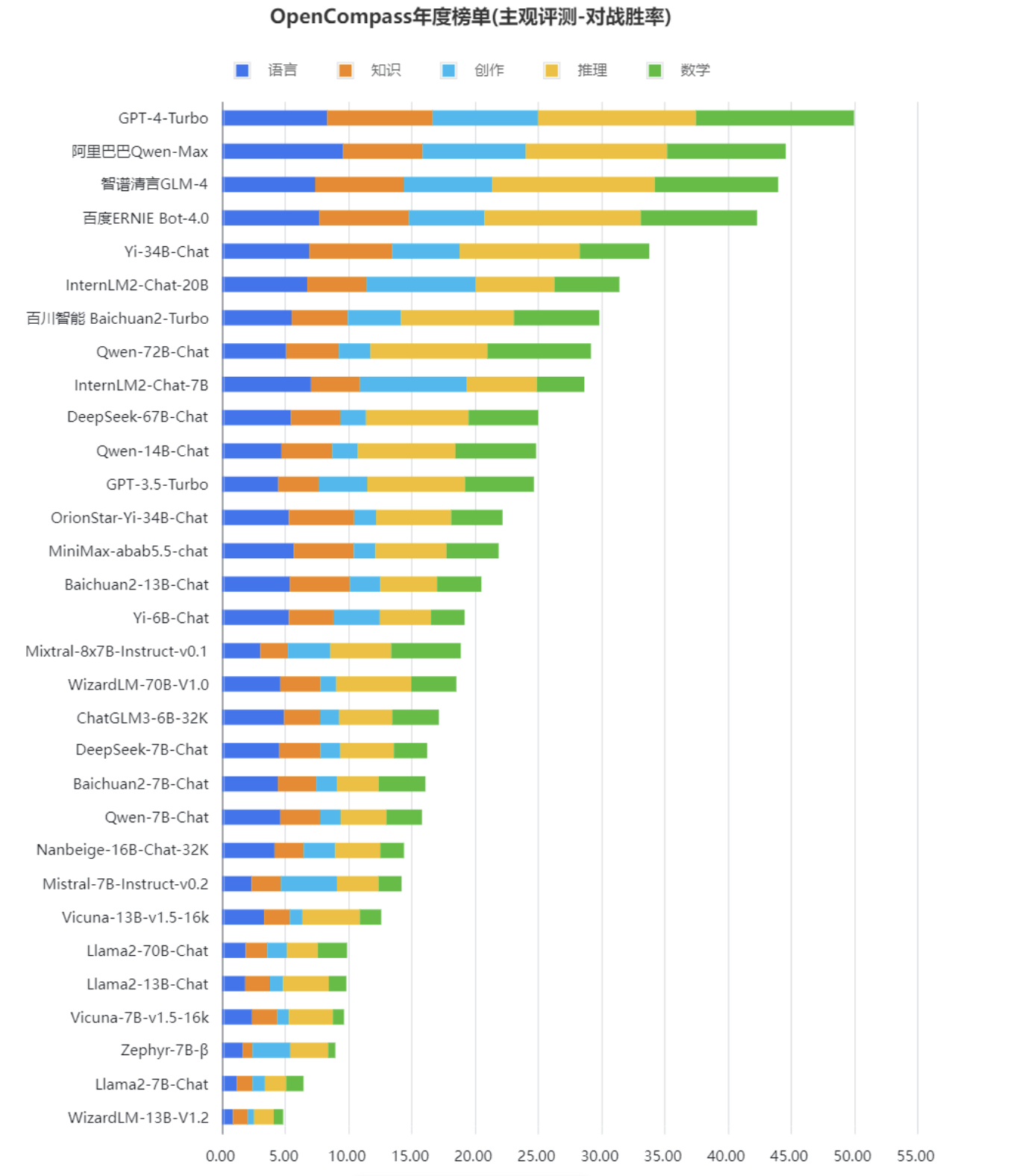
中文主观评测。截至该榜单发布,部分新大模型尚未纳入本次评测。
“主观评测中,最难的是主观的数学题,不能靠猜答案。”上海人工智能实验室领军科学家林达华表示,榜单中,GPT-4 Turbo的数学能力遥遥领先,说明在高难度的推理上具有优势。
基于主观评测分析,研究人员还发现,国内商用大模型在中文评测中表现优秀,和GPT-4 Turbo差距缩小。阿里巴巴Qwen-Max、智谱清言GLM-4、百度文心4.0都取得了优秀成绩。在中文语言理解、中文知识和中文创作上,国内商业模型相比GPT-4 Turbo有更强的竞争力。
开源社区的Yi-34B-Chat、InternLM2-Chat-20B在综合性对话体验上表现突出,它们以中轻量级的参数量、接近商业闭源模型的性能,为学术研究和工业应用提供了良好基础。国内开源模型近期快速进步展现了开源模型的应用潜力,开源模型和开源工具体系的结合可帮助企业快速试验大模型在应用场景的适用性。
目前OpenCompass2.0已和合作伙伴共同推出了多个垂直领域的评测基准和数据集,包括LawBench法律大模型评测基准、OpenFinData金融评测集、MedBench医疗大模型评测系统、SecBench网络安全大模型评测平台等。
吸取高考经验,避免大模型直接刷题
“评测是大模型的指挥棒和指南针。”林达华教授表示,大模型评测要客观公允、评测方式科学、评测维度全面。OpenCompass2.0的评测维度包括基础能力和综合能力两个层级,能力维度设计具备可扩展性和增长性,同时可根据未来的大模型应用场景进行动态更新和迭代。
基础能力维度以语言、知识、理解、数学、代码为核心,包括意图识别、情感分析、内容评价与总结、多语言翻译、汉语与中国传统文化、常识百科、自然科学、人文社科、计算能力、数学应用能力、多编程语言代码等20余项细分任务。而综合能力旨在考察模型在综合运用知识、数学推理、代码工具等多种能力完成复杂任务的水平。
当前,一些大模型沉迷于刷榜、跑分。林达华表示,通过题海战术提高大模型成绩,对于模型实际能力的反应是失真的,影响了模型研发团队的改进方向和模型的商业落地,“高分低能”伤害的是机构本身。为此,实验室吸取了高考经验,提前公布“考试大纲”,但在第一期测评榜单发布前不公开“考题”,下一期“考题”用于下一期测评,每一期题目不同,避免大模型直接刷题,从而发现能力长板与短板。未来也会考虑开发测评分集,对于高分考生,用更有挑战、区分度更大的题目进行测评,凸显能力差距。
“国内有很多模型正在发布的路上,榜单上任何具体的名字只是大模型成长过程中无数次测试中的一次,一时的排名高低并不真正反映模型的能力,最重要的是每一次测验可以回过头来指导我们改进自己。”林达华表示。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

