- +1
苹果AI“图穷匕见”:将大模型塞进iPhone里

《教父》电影中有句话:“千万不要让外人知道你想干什么”,这句话似乎也可以用在苹果2023年前11个月的AI表现上。
今年5月,据报道苹果担心ChatGPT、Copilot等AI工具收集机密数据,禁止员工在工作中使用。
今年6月,在苹果全球开发者大会上,库克甚至都没提AI,而是同义替换为ML。
但如果说苹果不在意AI,显然不可能。毕竟追溯到2010年,苹果就以2亿美元的价格收购了Siri团队,虽然这么多年过去了,它还是那么“弱智”。
今年7月,有报道称,苹果内部研发了自己的AI框架Ajax和聊天机器人AppleGPT。其中Ajax基于Google Jax搭建,而AppleGPT则类似于ChatGPT。不过,二者看起来没有什么创新之处。
今年10月,苹果又掏出了开源多模态大模型Ferret,拥有70亿和130亿两个参数版本。但因为目前只对研究机构开放,也没激起什么浪花。
同样是10月,有报道称,苹果非常“焦虑”,并已启动一项庞大的追赶计划。该计划由机器学习和人工智能主管John Giannandrea和Craig Federighi领导,服务部门高级副总裁Eddy Cue也参与其中,预算为每年10亿美元。
有点讽刺的是,早在2020年,John Giannandrea就在访谈中肯定了苹果的AI战略,并表示苹果不会向外说太多自己的AI能力。
到底是不能说太多,还是其实没有太多。总之,太多传言吊足了大家的胃口。
虽然你可以说,作为一家主打硬件的公司,苹果今年至少发布了Vision Pro,其中数字分身、场景与动作识别等功能都和AI技术有关。
但骄傲止步于11月份AI Pin的刷屏。半个烟盒大小的“领夹”只通过“听”和“看”就能理解用户需求,并用AI软件执行任务,被一些人视为“天生的iPhone杀手”。更重要的是,AI Pin背后的金主爸爸包括微软、OpenAI 等一系列让苹果“焦虑”的对象。
眼看狼群要全方位包抄了,苹果终于在2023年即将结束之时,放出了两篇论文。
其中一篇题为《LLM in a flash:Efficient Large Language Model Inference with Limited Memory》的论文提出:苹果通过一种创新的闪存利用技术,成功地在内存有限的 iPhone 和其他苹果设备上部署了LLM,这一成果有望让更强大的 Siri、实时语言翻译以及融入摄影和AR的尖端 AI 功能登陆未来 iPhone。(关注“适道”,发送:“论文1”,可得论文PDF文件)
在2024年,这条“大模型+硬件”路线或许会直接改变竞争格局。
01 打破内存墙,将大模型放在闪存里
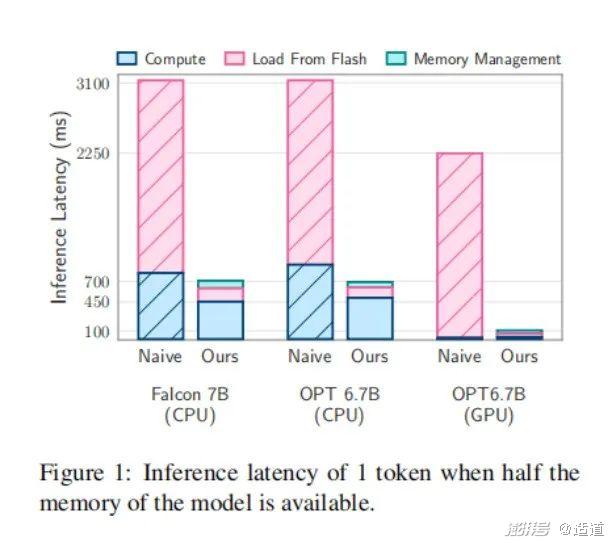
先放数据结论。论文显示,在Flash-LLM技术的加持之下,两个关键领域得到优化:1、减少闪存传输的数据量;2、读取更大、更连续的数据块。
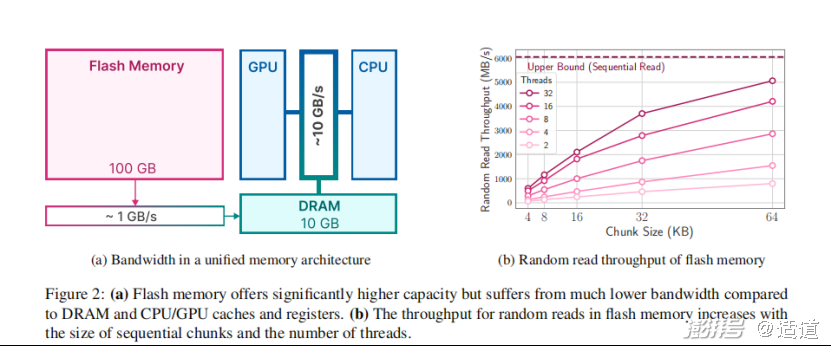
优化之后,设备能够支持运行的模型大小达到了自身DRAM的2倍;LLM的推理速度在Apple M1 Max CPU上提高了4-5倍,在GPU上提高了20-25倍。
Flash-LLM是如何做到的呢?采用了两种主要技术:
第一、 窗口化技术(windowing),通过重复使用先前激活的神经元来战略性地减少数据传输。大大减少了从存储器(闪存)到处理器(DRAM)的数据传输量。
第二、行列捆绑技术(row-column bundling),根据闪存的时序数据的访问强度量身定制,增加从闪存读取的数据块的大小,改变了数据的存储方式。
举个我们曾在《亏了几个亿, AI项目到底怎么投?看欧洲老牌风投Index如何押宝》中举过的“图书馆”例子。
假设,你拿着列有20本书的书单去图书馆找书,但这家图书馆就像英剧《Black Books》一样,书本摆放得杂乱无章。你几乎要从头走到尾,才能全部定位出你要找的所有书。
想象一下,你找书时,需要“眼睛”和“脑子”对账。按照常理,你不会每看到一本书,就从书单里找对应。因为你的大脑已经“闪存”了“重点书名”。
你要做的,只是从当下视线扫过的范围内找出书单上的书。
窗口化技术(windowing)就是这样,相当于先用一个算法稀疏化 LLM 的权重矩阵,只保留一部分重要的元素,从而减少计算量,提高计算效率。
同时,因为你一共要找20本书,总不能像狗熊掰玉米拿一本扔一本,因此你需要一个小推车。行列捆绑技术(row-column bundling)就是这个小推车,帮助每次从闪存中读取的数据块更大,也提高了数据读取效率。
速度和大小的双重突破,或许很快可以让大模型在iPhone、iPad和其他移动设备上流畅运行。
尽管这种方法也存在一些局限性,包括主要针对文本生成任务,对其他类型任务的适用性还需进一步验证,以及处理超大规模模型的能力有限等等。
02 迎接 Vision Pro 上市,30分钟生成“数字人分身
第二篇论文《HUGS: Human Gaussian Splats》虽然不比上一篇惊艳,但也足够让人眼前一亮。
这篇论文详细介绍了一项名为 HUGS(Human Gaussian Splats)的生成式 AI 技术,苹果研究员兼HUGS论文作者之一的Anurag Ranjan介绍:HUGS仅仅需要一个约50-100帧的原始视频,相当于2到4秒24fps的视频,就能在30分钟内生成一个“数字人分身”。
据悉,这比包含NeuMan、Vid2Avatar在内的其他方式要快约100倍。(关注“适道”,发送:“论文2”,可得论文PDF文件)
根据Ranjan在X上发布的视频,画面右方的三个数字人分身正在草坪上快乐跳舞,颇为魔性。
苹果表示,虽然当前的神经渲染技术比早期有了显著的进步,但依然最适合用在静态场景中,而不是在动态场景中自由移动的人类。
HUGS则是建立在3DGS(3D Gaussian Splatting)和SMPL身体模型技术的基础上,创建数字人分身。当然,目前HUGS技术无法捕捉每个细节,但对于未能捕捉并建模的细节元素,HUGS会自动填充。
而3D虚拟数字人是VR头显进一步发展的必然要求。
例如,在去年Meta发布了Codec Avatar 2.0版本,比1.0进一步完成了逼真的数字人效果。
今年,苹果发布Vision Pro,可以通过前置摄像头扫描用户面部信息,基于机器学习和编码神经网络,为用户生成一个数字分身。当用户使用FaceTime通话时,数字分身就可以动态模仿用户的面部及手部动作,并保留数字人分身的体积感和深度。
根据报道,苹果正在为Vision Pro上市做最后的准备,发售有望提前至2024年1月下旬。
据苹果资深分析师 Mark Gurman 爆料,2024年苹果的精力会重点放在可穿戴产品上(Vision Pro、AirPods、Apple Watch),一向占据大头的 iPhone 或将让位。
这篇论文或许就是迎接Vision Pro上市的准备动作。
03 结语
根据集邦咨询,从2018年开始,苹果就悄悄收购了20 多家AI公司,只有少数公开了交易价格。
也就是说,当你以为苹果终于慢半拍时,大佬正在观察、努力,悄悄布局生态,然后像以前无数次那样,突然一鸣惊人,惊艳所有人。
更可怕的是,此前苹果所表现的“落后一步”似乎是“以退为进”,有两个信息值得注意。
1、据报道,最近苹果正讨论“价值至少5000万美元的多年期合作协议”,并与康泰纳仕、NBC新闻和IAC等媒体接洽,以获取他们过往新闻文章的使用授权。
跟别的科技公司拿了数据直接训练不同,苹果是先取得授权,才会拿数据来进行训练。
这让人不由联想到,最近纽约时报指控OpenAI和微软,未经授权就使用纽约时报内容训练人工智能模型。而此案可能是人工智能使用知识版权纠纷的分水岭。
同样的还有近期Midjourney V6的版权麻烦——利用人类创作者的作品进行AI训练是否合法?司法如何保护创作者的权益主张?
2、在“谈AI安全色变”的气候下,今年10月,苹果供应链的香港海通国际证券分析师Jeff Pu发布报告显示:苹果可能在2023年已经建造了几百台AI服务器,而2024年将会显著增加。
他认为,苹果在推出生成式AI时前在谨慎考虑如何使用和处理个人数据,以符合其对客户隐私的承诺。
也就是说,此前苹果的“慢半拍”似乎是思考如何在尊重客户隐私的前提下,使用和处理个人数据。在没有完美的解决方案之前,苹果则始终保持谨慎。
此外,Jeff Pu在报告中指出:苹果计划最早在2024年末开始在iPhone和iPad上实施生成式AI技术。如果计划得以实现,2024年末的时间表将意味着苹果可能会从iOS 18和iPadOS 18开始推出生成式AI功能。
至此,这两篇论文的发布似乎启动了苹果王者归来的时钟,2024年,群雄逐鹿的人工智能赛道将会更加精彩。
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

