- +1
南农大团队研发“古籍版ChatGPT”,为何取名“荀子”
澎湃新闻记者 王奕澄
字号
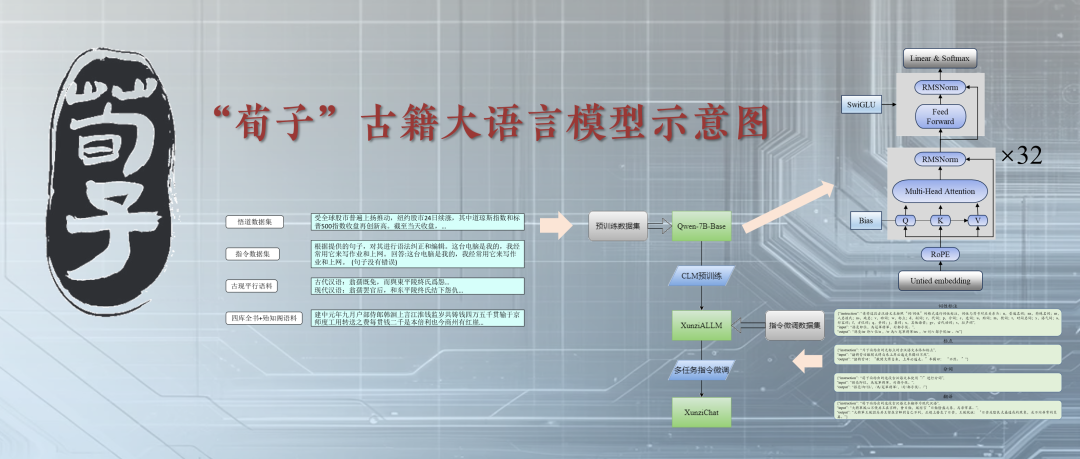
“荀子”古籍大语言模型示意图 微信公众号@南农信管之窗CIM 图
澎湃新闻(www.thepaper.cn)12月11日从南京农业大学获悉,该校信息管理学院王东波团队日前研发出国内首个专门用于古籍处理与研究的智能工具——“荀子”古籍大语言模型,包含《四库全书》在内的古籍文献超20亿字大型语料库,具备自然语言理解、自动翻译、自动标引等功能。该模型已在GitHub、ModelScope等网站开源。
王东波表示,荀子不仅是先秦伟大的朴素唯物主义思想家和散文家,对语言学理论的阐述也是开拓者,如此命名是纪念这位语言学先驱,“普通受众要走近繁体、竖版、没有句读的古文不是容易的事,‘荀子’上线,意味着在智媒时代与古籍对话成为可能,古文阅读理解、标点添加、译为现代汉语——这些难啃的‘硬骨头’,‘荀子’可以轻松拿下。”专家则可借助“荀子”完成古籍词法分析、实体识别、关系抽取、文本分类与匹配、文本摘要等。
据介绍,“荀子”的问世离不开高性能算力基础设施,也离不开团队长期积累精加工语料库,投喂了40亿字的混合语料数据。“模型的构建受算力、场景应用等影响,但精准度高的优质数据是关键。”王东波说,团队2008年接触古籍,2013年至今一直专注于人工精标注数据工作,“比如《岳阳楼记》,要训练机器标注其中的形容词,先要训练相关人员标注形容词,在大量人工标注的基础上让机器学习”。
王东波表示,期待通过“荀子”大语言模型,将古籍的智能化研究与跨学科人才培养结合,让学生既有前瞻的科研视野,又积累较深厚的人文底蕴,同时让更多受众接触、品读、传播古籍,唤活“故纸堆”。
责任编辑:谢春雷
图片编辑:蒋立冬
校对:刘威
澎湃新闻报料:021-962866
澎湃新闻,未经授权不得转载
+1
收藏
我要举报

查看更多

澎湃矩阵

新闻报料
- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司


反馈