- +1
全网大讨论:引爆OpenAI全员乱斗的Q*到底是什么?
机器之心报道
编辑:泽南、小舟
强大到能威胁人类,所以不得不把自家 CEO 开了?
本周三,OpenAI 的「宫斗」随着山姆・奥特曼回归 CEO 大位而告于段落,不过此次事件的余波还在震撼着关心 AI 的每一个人。我们都想知道,是什么让 OpenAI 前董事会不计任何代价也要开除奥特曼的。
最近几天,互联网上有关 Q* 的讨论前所未有的热闹。
据本周四报道,由 OpenAI 首席科学家 Ilya Sutskever 领导的团队在今年早些时候取得了技术突破,使得他们能够构建一个名为 Q*(音同 Q star)的新模型。Q* 最关键的突破是它能够解决基本的数学问题。
又据报道,Q * 模型引发了 OpenAI 内部的一场风暴,几名工作人员写信给 OpenAI 董事会,警告称这一新突破可能会威胁人类。这一警告被认为是董事会选择解雇山姆・奥特曼(Sam Altman)的原因之一。
让 AI 解决基本数学问题的能力听起来似乎没有很厉害,但实际上这代表着大模型能力的巨大飞跃。很多近期研究表明,现有模型很难在训练数据之外进行泛化。
越来越多的工程师和研究人员加入了对 Q * 的猜测和讨论之中。
据 Business Insider 报道,人工智能初创公司 Tromero 的联合创始人 Charles Higgins 表示:「对抽象概念进行逻辑推理正是目前大模型真正面临的难题。数学涉及大量符号推理,例如『如果 X 大于 Y,Y 大于 Z,那么 X 大于 Z。』」而现有语言模型不进行逻辑推理,只是拥有有效的直觉。
那么,Q * 模型为什么可以进行逻辑推理?它的名字暗示了这个问题的答案。
Q * 暗示其结合了两种著名的人工智能方法 ——Q-learning 和 A* 搜索。
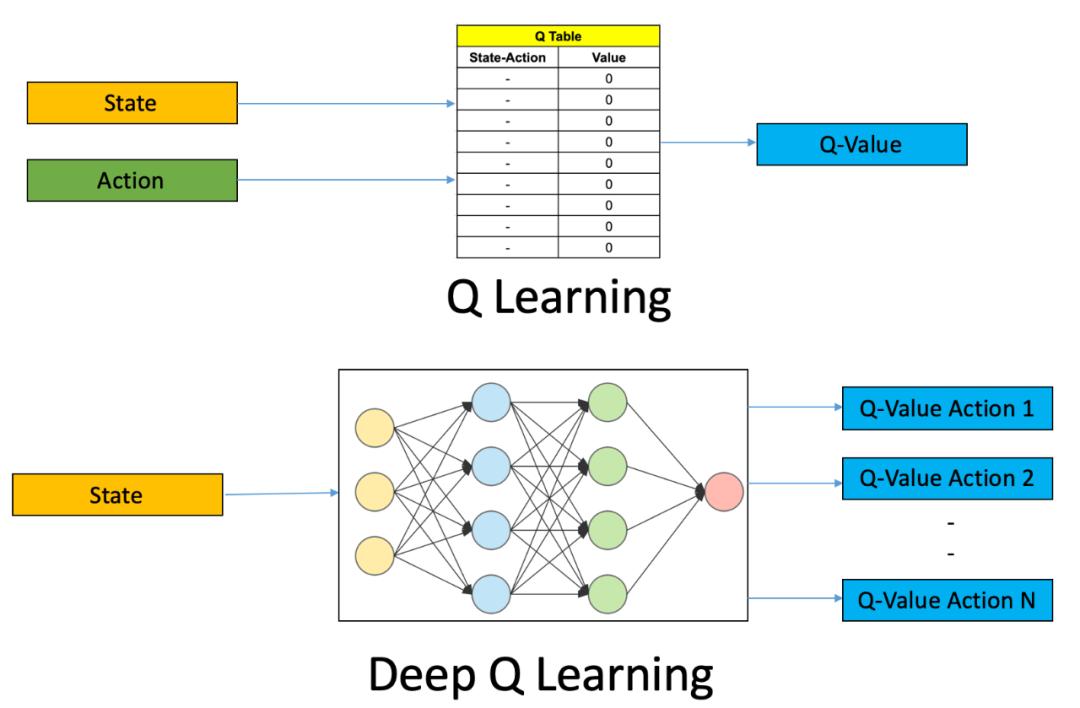
Q-learning 是人工智能领域的一个基本概念,它是一种无模型强化学习算法,旨在学习特定状态下动作(action)的价值(value)。Q-learning 的最终目标是找到一个最优策略,定义在每个状态下采取的最佳动作,从而随着时间的推移最大化累积奖励(reward)。
ChatGPT 开发者之一的 John Schulman 2016 年在一次演讲中提到过这个概念,引入 Q* 到优化策略中:

所以在每个状态下,哪种行动能有最优奖励?
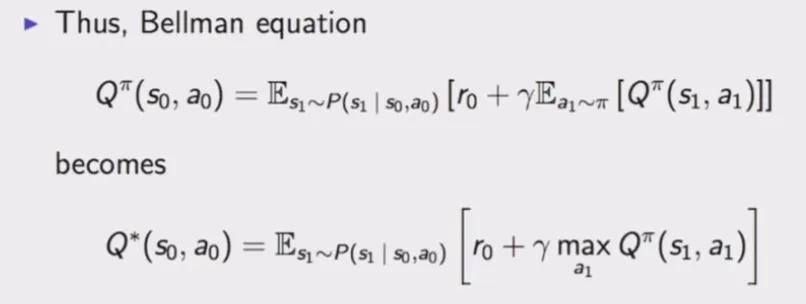
Bandit 问题可以利用贝尔曼方程来解决。
Q-learning 基于 Q 函数,即状态动作价值函数。在简单的场景中,Q-learning 会维护并更新一个 Q-table,更新规则通常表示为:

图源:https://twitter.com/BrianRoemmele/status/1727558171462365386
Q-learning 的关键是平衡探索(尝试新事物)和利用(使用已知信息)。简单来说,Q* 可以实现最优策略,这在强化学习等 AI 方法中是算法重要的步骤,有关算法能否采取最佳决策,找到「正确解」。通常,被称为「Q Learning」的行为不会指代对上下文的搜索,或者至少不会作为算法的高级名称。它通常用于指代贪婪行为的代理。
另外也有人认为,或许如果 Q 指代 Q Learning,那么 * 就是来自 A* 搜索。
A*(A-Star)算法是一种静态路网中求最短路径最有效的直接搜索方法,也是解决许多搜索问题的有效算法。算法中的距离估算值与实际值越接近,最终搜索速度越快。
这样的思路也很有趣。
最后,如果你想了解更多 Q-learning 的内容,可以参看强化学习之父 Richard S. Sutton 那本著名的《Reinforcement Learning: An Introduction》。
值得注意的是,OpenAI 为大模型训练使用的 RLHF 方法,旨在让模型从人类反馈中学习,而不是仅仅依赖于预定义的数据集。
人类反馈可以有多种形式,包括更正、不同输出的排名、直接的指令等等。AI 模型会利用这些反馈来调整其算法并改进响应。这种方法在定义明确规则或提供详尽示例的挑战性领域特别有用。有人猜测,这就是为什么 Q* 接受逻辑训练并最终能够适应简单算术的原因。
然而,Q-learning 算法对实现通用人工智能(AGI)能起到多大的作用?
首先,AGI 是指人工智能系统理解、学习并将其智能应用于各种问题的能力,类似于人类智能。Q-learning 虽然在特定领域很强大,但实现 AGI 必须要克服一些挑战,包括可扩展性、泛化、适应性、技能组合等等。
实际上,近年来涌现了很多尝试将 Q-learning 与其他深度学习方法结合的研究,例如将 Q-learning 与元学习结合,让 AI 学会动态调整其学习策略。
这些研究的确让 AI 模型有了能力上的改进提升,但是 Q-learning 是否能帮助 OpenAI 实现 AGI 还未可知。
PerplexityAI 的 CEO Aravind Srinivas 认为,Sutton 的文章《惨痛的教训》告诉我们,计算才是前进的方向。我们需要更多数据(不仅是参数)来有效地使用计算。如果我们最大限度地利用互联网上的数据,那就需要模型本身来生成下一个 token,即递归的自我完善:
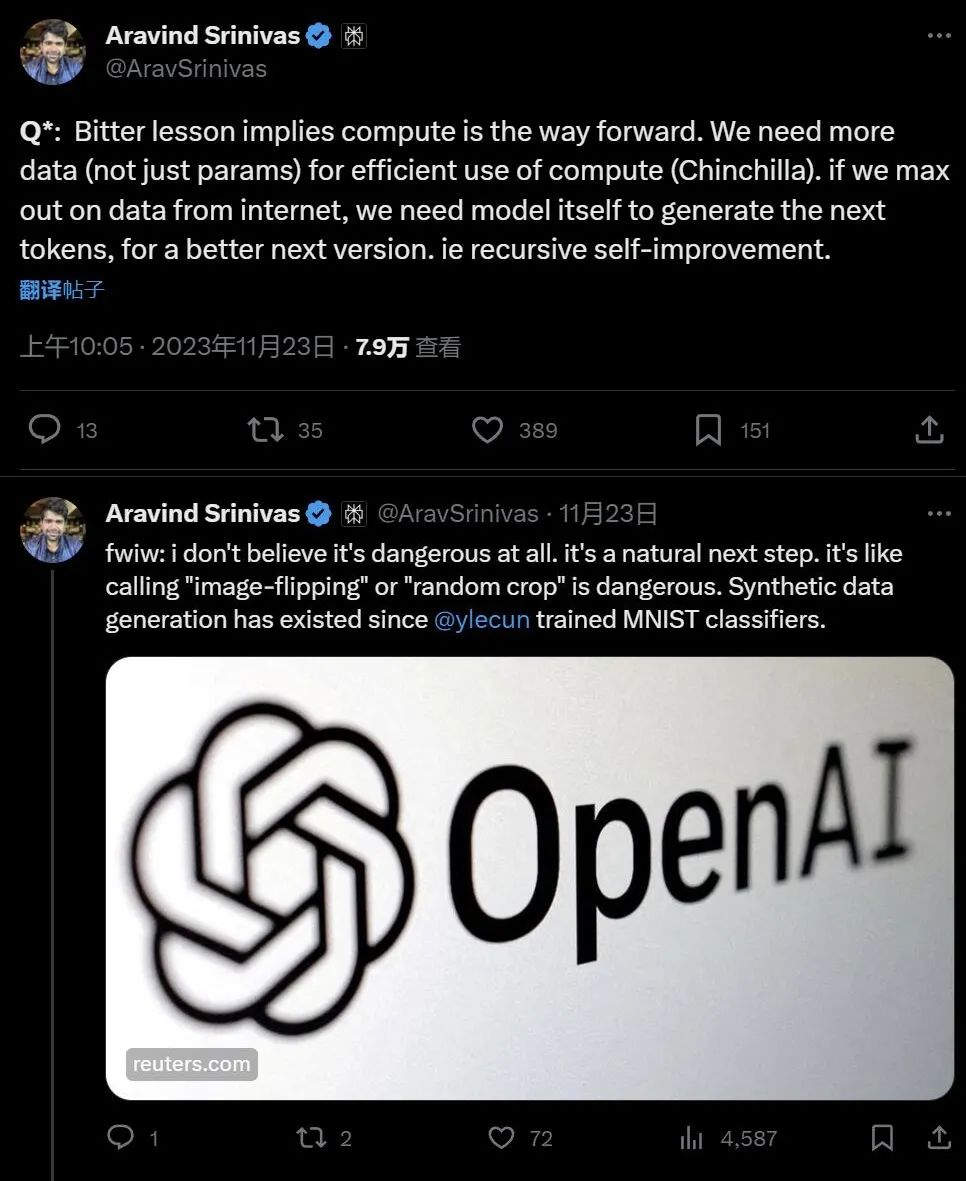
那么这应该根本就不危险,正如以前计算机视觉研究中,对于图像数据进行翻转和裁剪以训练分类器一样。
也有人猜测,Q* 是 AlphaStar 式搜索 + LLM 的传说中的突破,它是很多 AI Lab 正在努力的方向。但考虑到 GPT-4 自验证 + 搜索此前一些尝试有限的提升,我们距离 AGI 还是很远的。
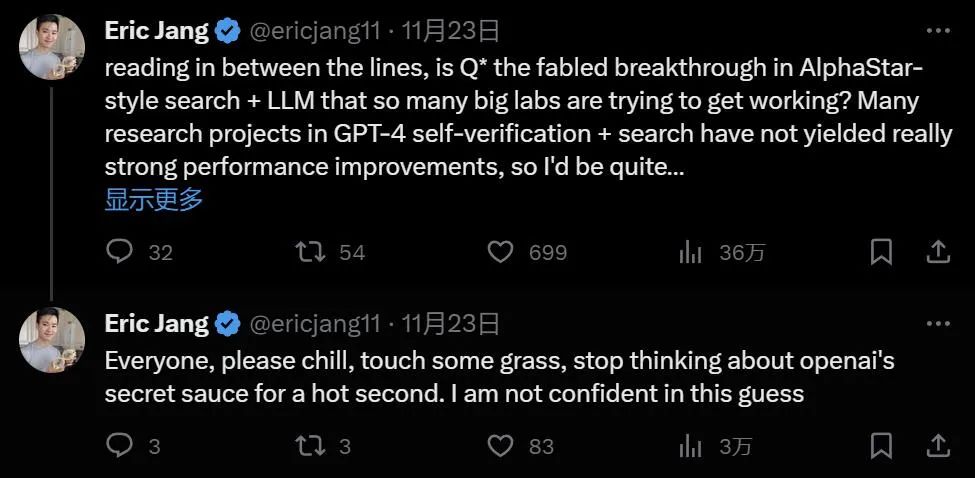
如果正如各路媒体所报道的,Q * 的突破意味着下一代大模型可以将支持 ChatGPT 的深度学习技术与人类编程的规则结合起来。这种方法可以帮助解决困扰当前大模型的幻觉问题。
这可能会是个重要的技术发展里程碑。在实际层面上,应该距离 AI 终结世界还很远。
「我认为人们之所以相信 Q* 将通向通用人工智能,是因为从我们迄今为止所听到的情况来看,它似乎会将大脑的两侧结合起来,并且能够从经验中了解一些事情,同时仍然能够推理事实,」Tromero 联合创始人 Sophia Kalanovska 表示。「这绝对是离我们所认为的智能更近了一步,并且有更可能让模型能够产生新的想法,ChatGPT 则不然。」
无法推理和创造新想法,仅仅是从训练数据中总结信息 —— 这被视为现有大模型的局限性,甚至对于参与这些方向研究的人来说,他们也在被框架所局限。
萨里学院人类中心 AI 研究所负责人 Andrew Rogoyski 认为,解决前所未见的问题是构建 AGI 的关键一步:「就数学而言,我们知道现有的人工智能已被证明能够进行本科水平的数学运算,但无法处理更高级的数学问题。」
「然而,如果人工智能能够解决新的、看不见的问题,而不仅仅是反省或重塑现有知识,那么这将是一件大事,即使所涉及到的问题相对简单,」他补充道。
并非所有人都对 Q * 可能带来的突破如此兴奋。著名 AI 学者,纽约大学教授 Gary Marcus 在他的个人博客上发表了一篇文章,对 Q* 所报道的功能表示怀疑。
「OpenAI 的董事会可能确实会对新技术表示担忧…… 尽管有一些说法称 OpenAI 已经在尝试测试 Q*,但他们在几个月内彻底改变世界是不现实的,」Marcus 表示。「如果我每一个这样的推断(Q * 可能威胁人类)都能得到五分钱,我就会成为马斯克级别的首富。」
图灵奖得主 Yann LeCun 在与 Geoffrey Hinton 讨论 AI 风险问题之余也点评了 Q*:
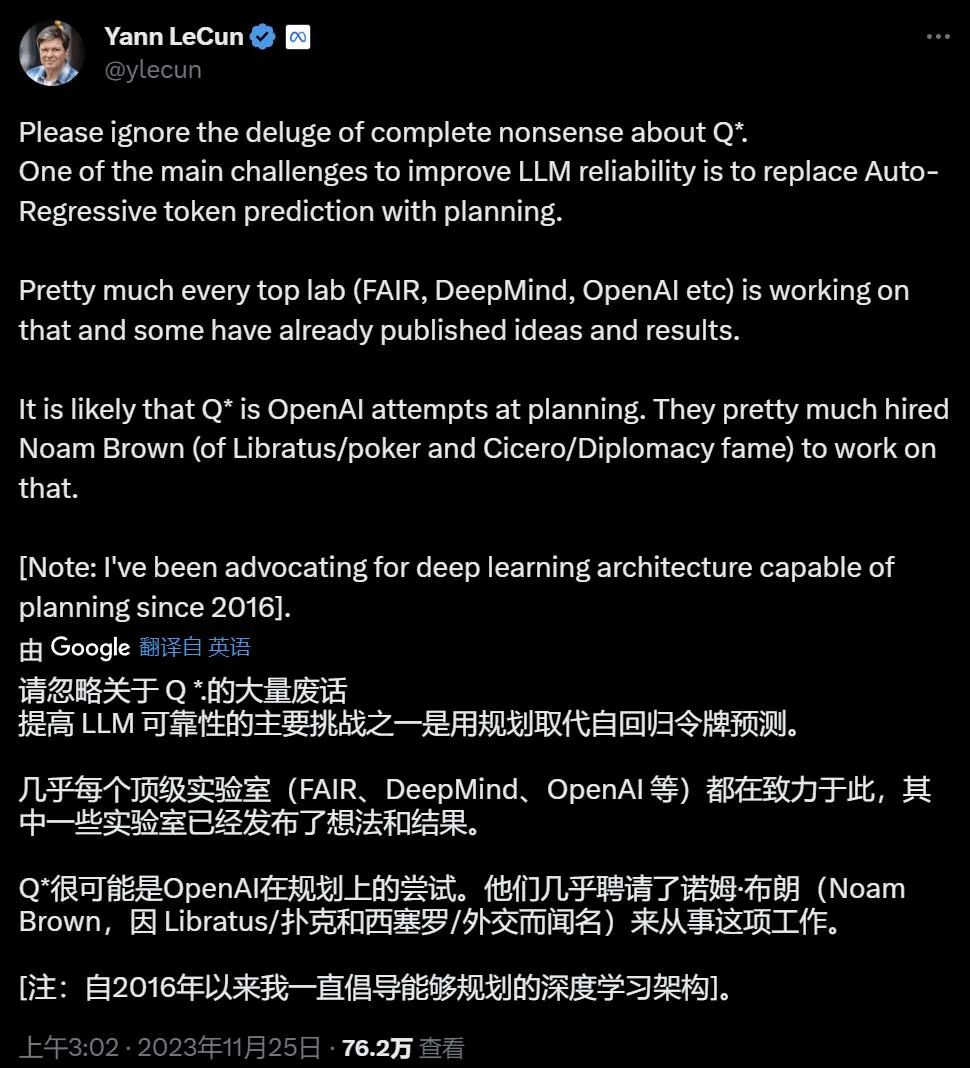
LeCun 认为:「Q * 很可能只是 OpenAI 用规划取代自回归 token 预测的一种尝试。现在关于 Q* 的推测只不过是废话。」
马斯克也参与了讨论,顺便还宣传了下自家模型。他表示,你们讨论的能力 Grok 都会有:
对于 Q*,OpenAI 仍然没有对外界的询问给予回应。
人们的讨论还在继续,或许在 OpenAI 下一个大模型发布之后,我们才能真正得到答案。
参考内容:
https://www.businessinsider.com/openai-project-q-sam-altman-ia-model-explainer-2023-11
https://twitter.com/BrianRoemmele/status/1727558171462365386
https://garymarcus.substack.com/p/about-that-openai-breakthrough© THE END
转载请联系本公众号获得授权
原标题:《全网大讨论:引爆OpenAI全员乱斗的Q*到底是什么?》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

