- +1
正面硬刚OpenAI,智谱AI推出第三代基座模型,功能对标GPT-4V,代码解释器随便玩
原创 关注前沿科技 量子位
衡宇 萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
国产大模型估值最高创企,为何是智谱AI?
仅用4个月时间,这家公司就甩出最新成绩证明了自己——
自研大模型ChatGLM3,不止是底层架构,就连模型功能都进行了全方位大升级。
性能上,最直观的表现就是“疯狂屠榜”,所有50个大模型公开性能测评数据集中,拿下44个全国第一;
产品上,率先搞定了用户关注度MAX的代码解释器功能,能生成甚至直接跑通代码!
现在这个新功能已经人人可玩,我们也试着用它给大伙儿比了个心
值得一提的是,这个功能也是国内首家。
所以,从智谱AI发布的ChatGLM3中,究竟能深挖出什么最新的技术细节?
行业又能否从中嗅出什么大模型新动向?
我们从智谱AI的ChatGLM3发布会中一探究竟。
ChatGLM3长啥样?
稍早之前,量子位就获悉了智谱AI将发布迭代后基座模型的消息,取名ChatGLM3。
发布会上,升级后的ChatGLM第三代正式对外披露,主要在4个方面秀出亮点,对比上一代有不小提升。
首先是性能的提升。
据介绍,结合此前ChatGLM系列模型的开发经验,智谱AI采用了独创的多阶段增强与训练方法,同时丰富了训练数据,优化了训练方法,使训练更为充分。
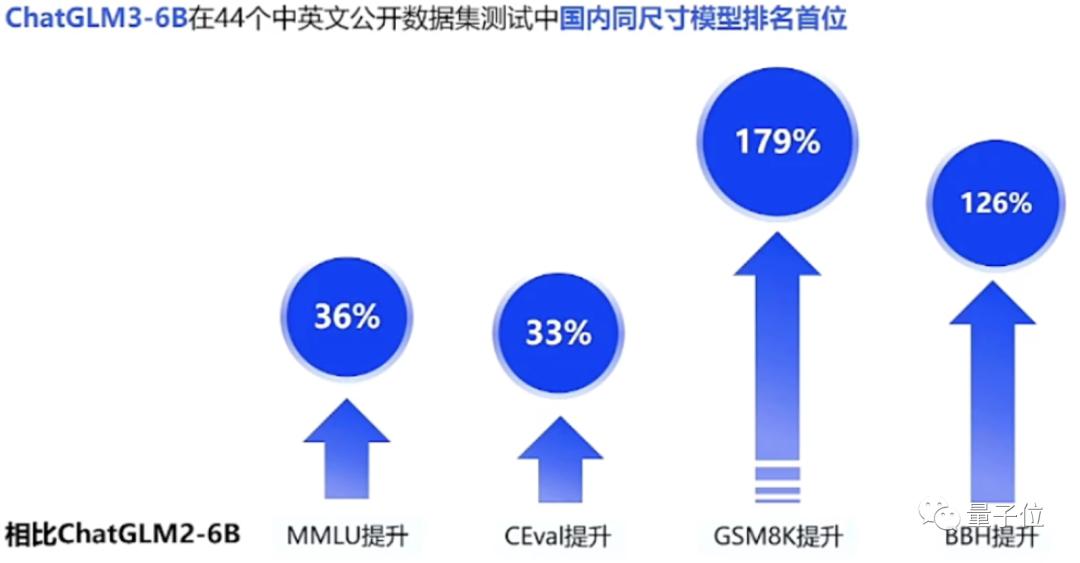
评测结果显示,与ChatGLM2系列模型相比,ChatGLM3一出,性能屠榜:
同尺寸模型中,ChatGLM3拿下了44个中英文公开数据集测试国内第一。
其次是推理能力方面,更为高效,成本也更低。
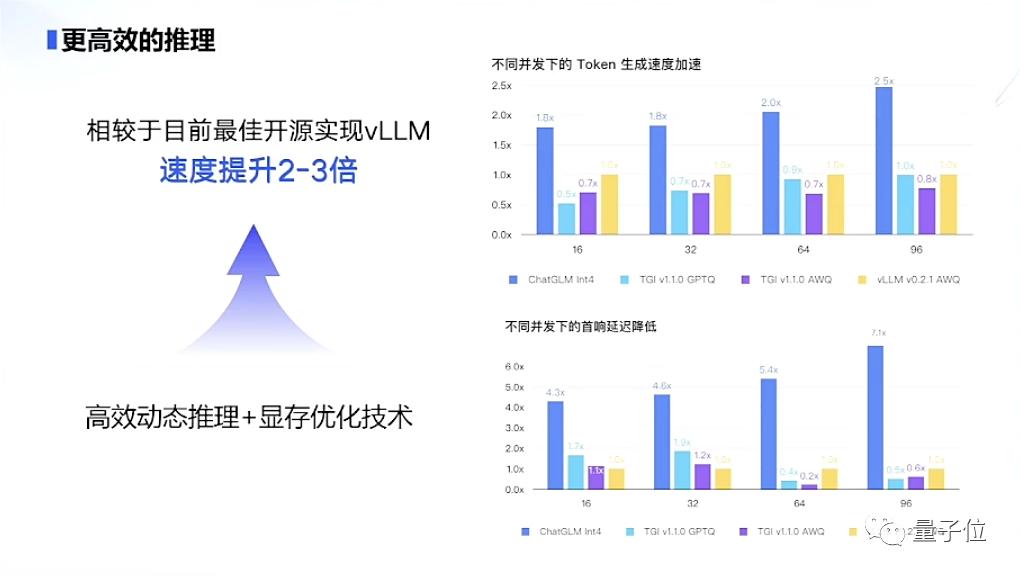
官方介绍,ChatGLM3系列模型采用了最新的高效动态推理和显存优化技术。
相同硬件、模型条件下,当前的推理框架相较于目前的最佳开源实现——UC伯克利分校提出的vLLM以及Hugging Face TGI的最新版本,推理速度提升了2-3倍。
同时成本降低一倍。目前ChatGLM3系列模型的推理成本,每千tokens仅需要0.5分。
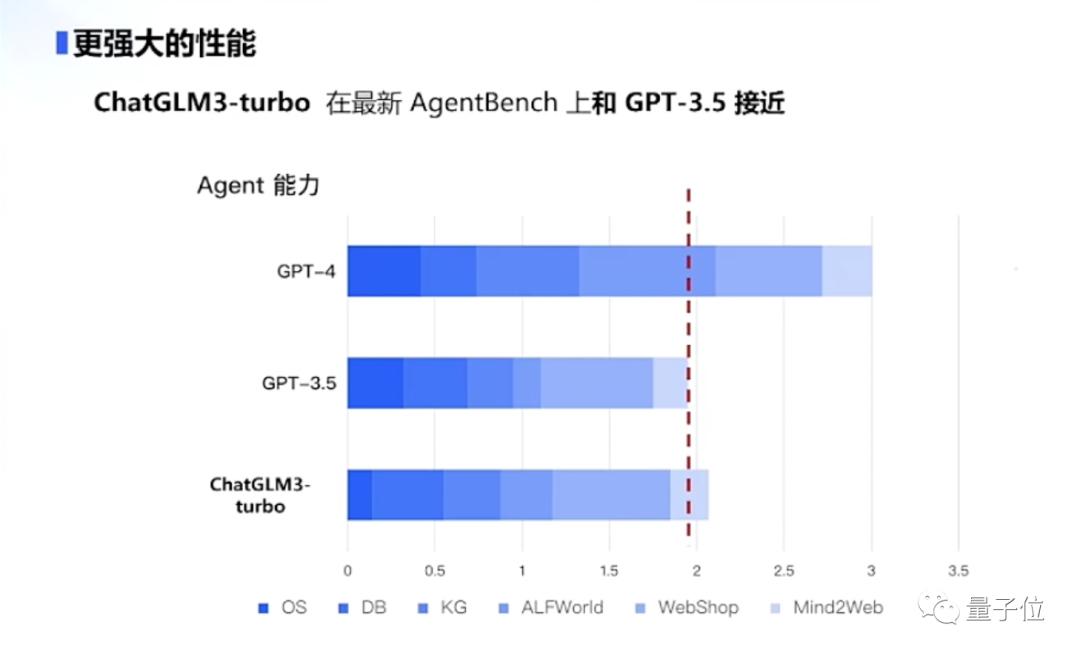
以及ChatGLM3还具备了全新的Agent智能体能力。
智谱AI介绍说,本次迭代后的ChatGLM3集成了自研的AgentTuning技术,激活了模型智能代理能力。
由此也使得ChatGLM3作为国产大模型,能够原生支持工具调用、代码执行、游戏、数据库操作、知识图谱搜索与推理、操作系统等复杂场景。
呈现在实际数据中,ChatGLM3系列在智能规划和执行方面,比ChatGLM2系列提升1000%;而ChatGLM3-turbo在最新AgentBench上和GPT-3.5接近,还小有胜出。
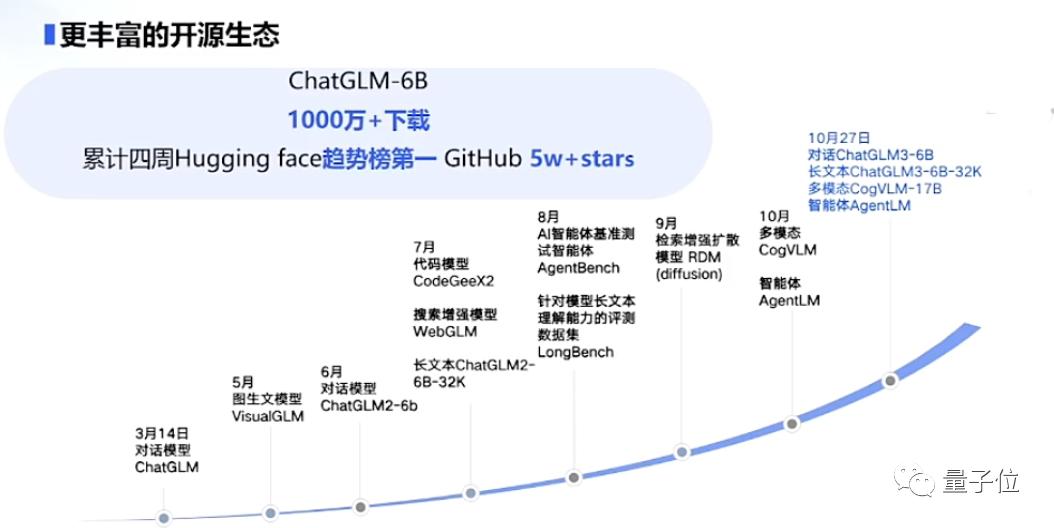
值得注意的一点是,纵使进行全方位的升级迭代,智谱AI在大模型道路上还是继续秉承着开源的开放思想。
至于这一次在开源价值方面的拓展动作,存在于多个细分领域:
包括对话模型ChatGLM3-6B、长文本模型ChatGLM3-6B-32K、多模态模型CogVLM-17B和智能体AgentLM在内,统统开源。
尤其提到,60亿参数的ChatGLM3-6B已开源,它在44个对话模型数据集上的9个榜单中,国内排名第一;且32k版本ChatGLM3-6B-32K在LongBench中表现最佳。
智谱AI CEO张鹏在发布会现场提到,此前智谱AI开源的ChatGLM-6B,已经有超过千万的下载量。开放的态度对于智谱AI现在4个月发展出新一代基座模型,是功不可没的。
是以发布领先、好用的模型,吸引开发者和B端用户,逐步构建起自研大模型和合作伙伴筑建的模型生态——智谱AI正是这条路线的实践者。
交上答卷,方方面面的数据详情,能看出智谱AI对此次第三代ChatGLM模型比以往发布模型和产品还要重视。
拿出的速度和态度背后,是什么在驱动?是智谱AI长期投入研发的技术驱动。
一方面,清华KEG实验室研究成果出身决定了,智谱AI既是一家面向市场化的大模型公司,但其本身还是带有浓厚的学术氛围和技术追求。
另一方面,智谱AI确实是国内最早投身大模型技术研究的玩家之一,有4年多的积累,也明确过会持续深耕下去。
再者说,在百模混战中谋生存,又通过开拓朋友圈寻发展,以技术为核心出发点和竞争力,是一家大模型创企的应有之义。
功能对标GPT-4V,可部署到手机
纸面数据强劲,产品实际效果又是如何呢?
或许可以从实用性、落地应用范围和适配能力三个方面来看。
首先是产品实用性,也就是功能丰富度上。
这一次,有了ChatGLM3加持,智谱清言在功能上直接对标GPT-4V,最直观的就是增加了这3大点“新玩法”——
代码解释器Code Interpreter
搜索增强WebGLM
看图识语义CogVLM
智谱AI CEO张鹏更是放话:
我们不做Demo和内测,功能已经全面上线智谱清言,欢迎来玩。
既然如此,我们也马上到更新后的智谱清言中一探究竟,看看实测效果如何。
第一,代码解释器功能,在国产大模型产品中,这个能力也是头一回见。
和单纯的“分析代码”和“读代码”不同,代码解释器不仅可以读代码,甚至能在一个沙盒中运行代码,并返回生成结果。
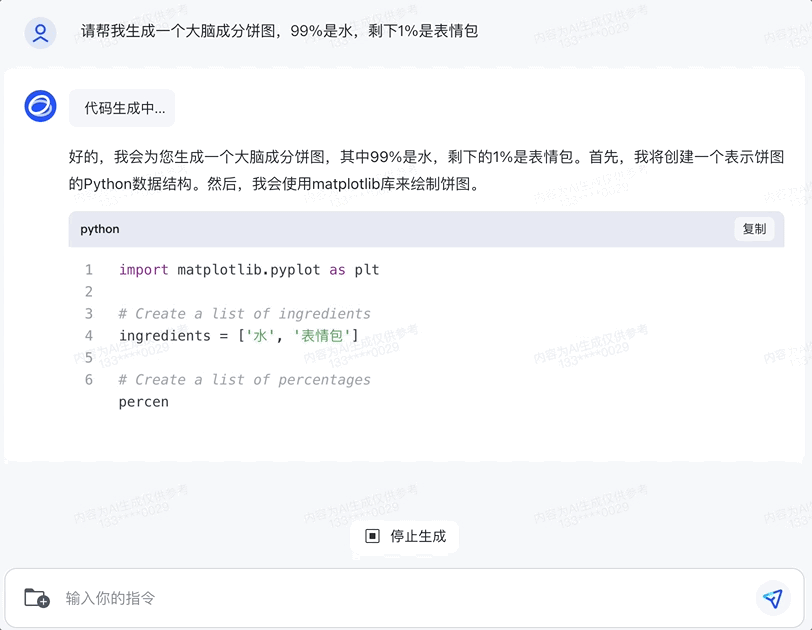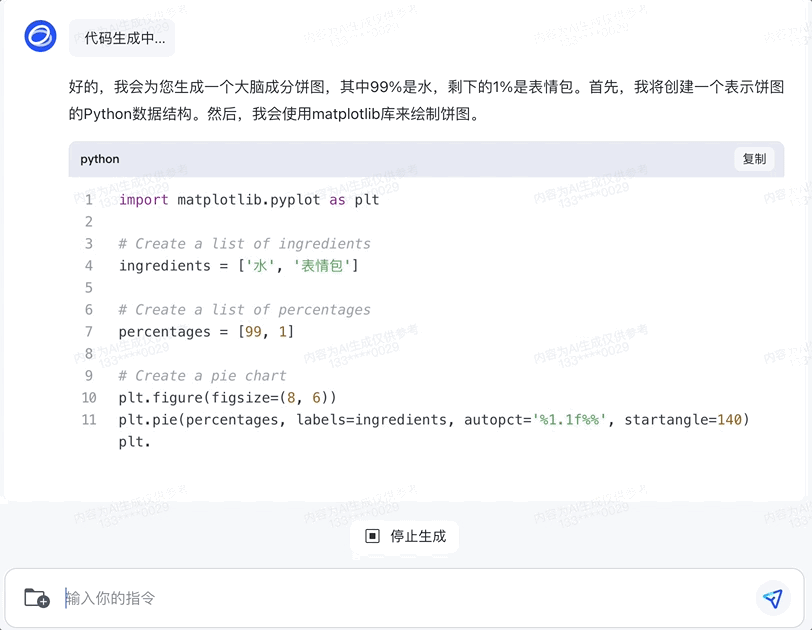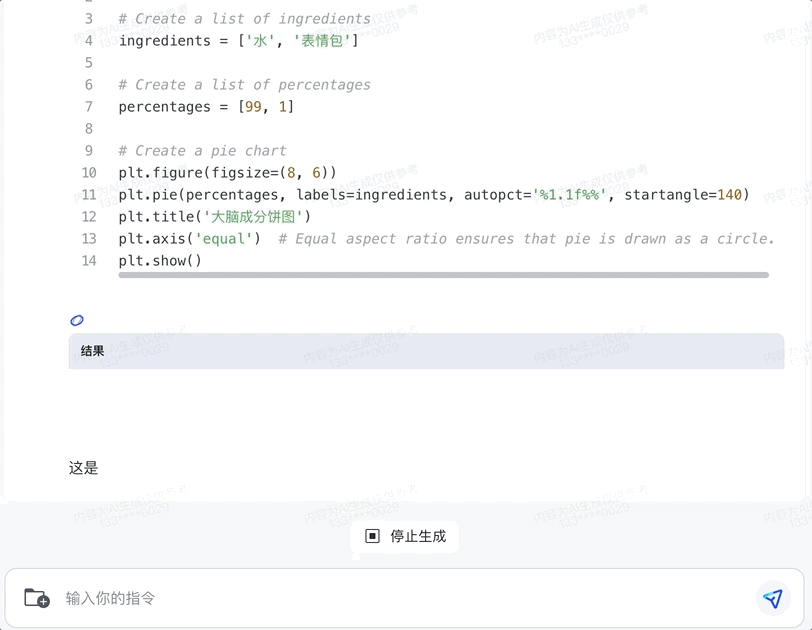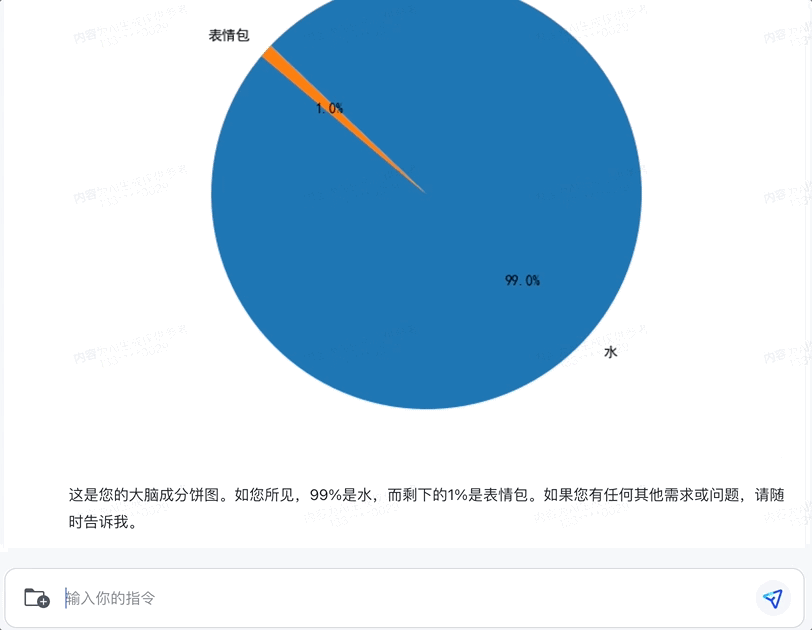
这里我们先试试简单的画图,看看智谱清言是不是真能“跑代码”:
生成一个大脑成分的饼图,99%是水,1%是表情包。
在经过一番“急速分析”后,智谱清言竟然真的调用Python库,生成了一个饼图表情包,正经而不失幽默感。
换个雷达图试试,这里我们让它生成一份打工人得分图鉴。
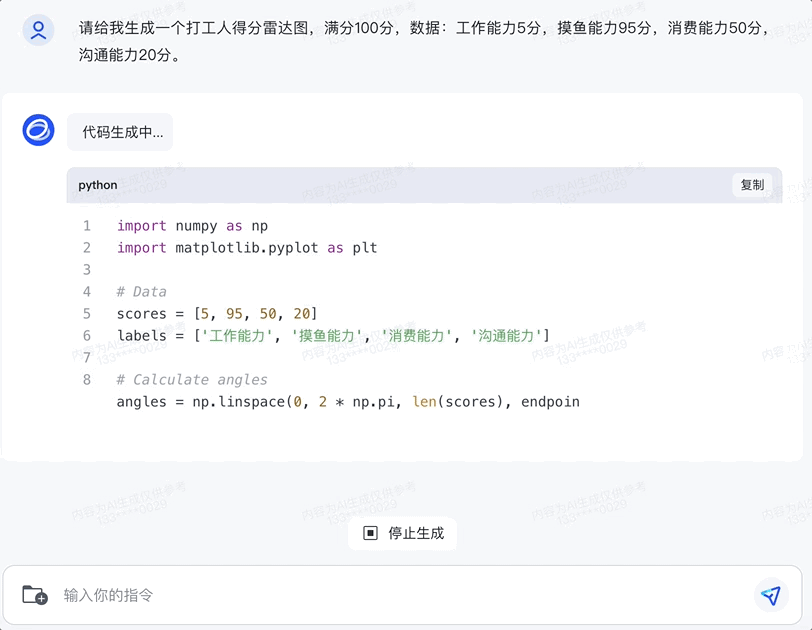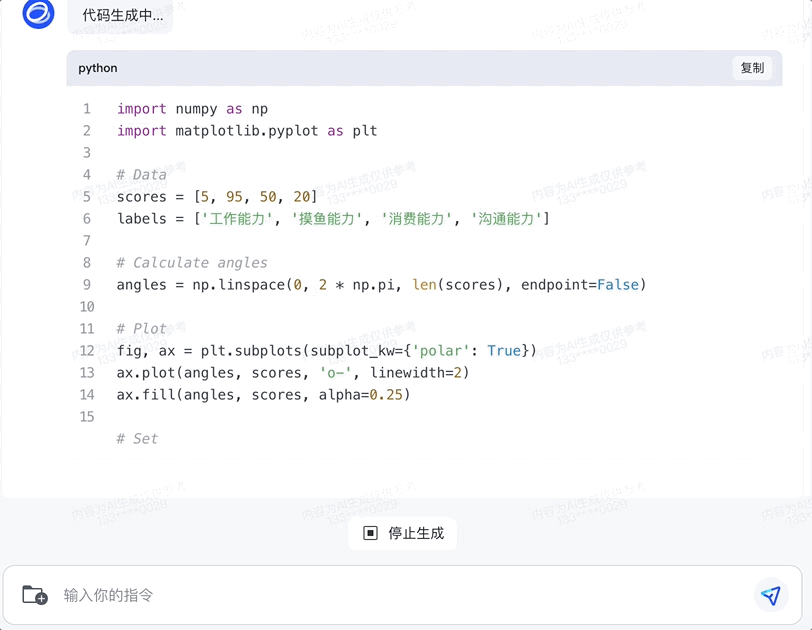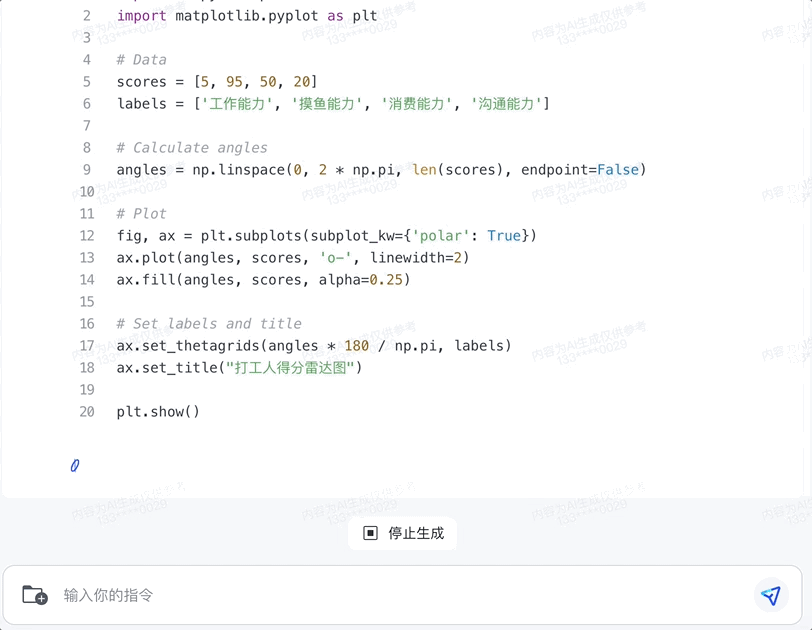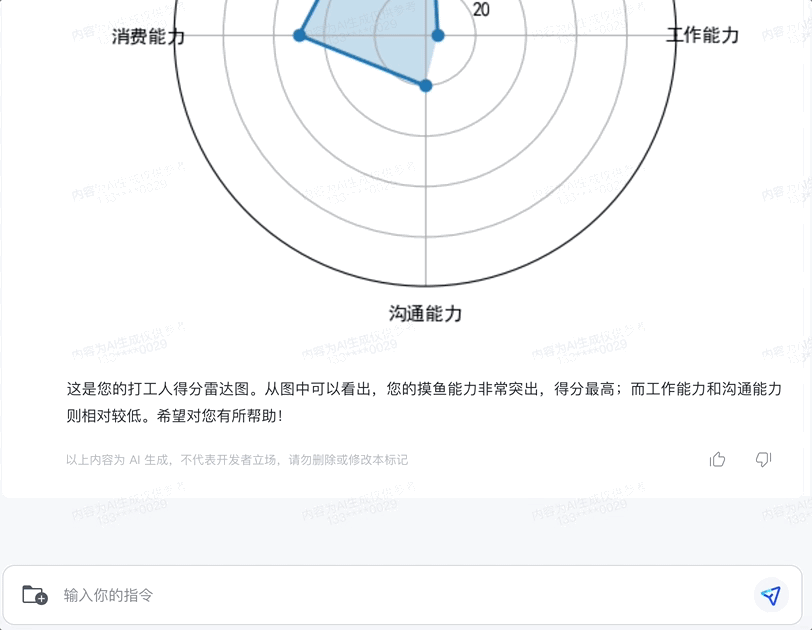
不错,尤其是总结非常到位:
从图中可以看出,您的摸鱼能力非常突出,得分最高;而工作能力和沟通能力则相对较低。
那么,接下来上点难度,试试数据可视化的效果。
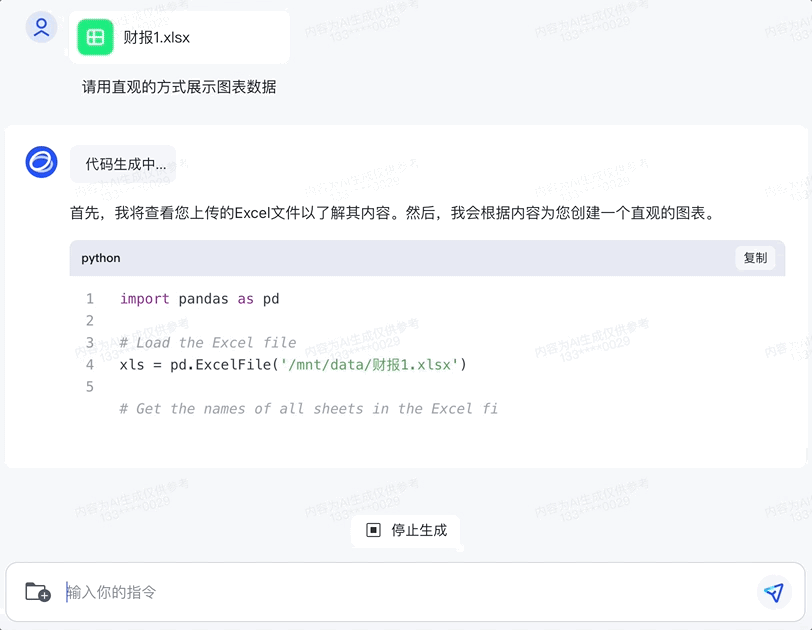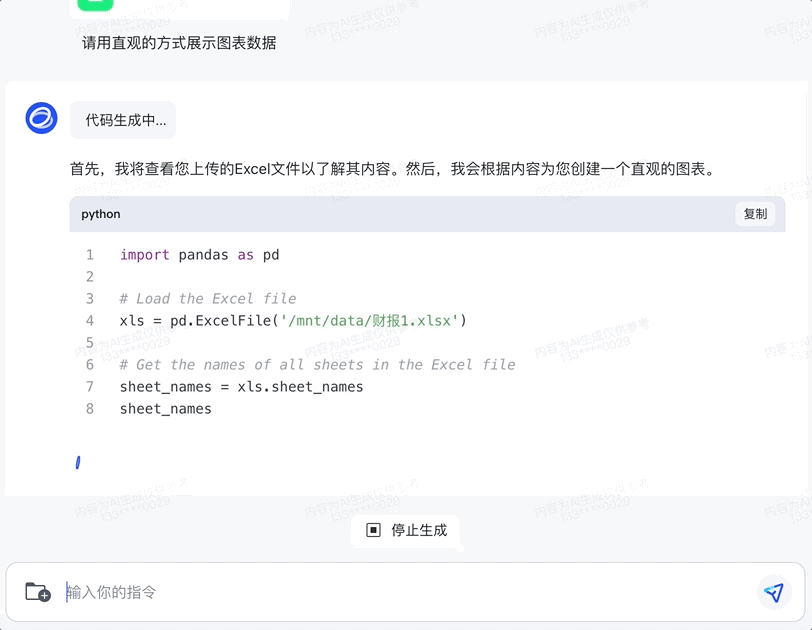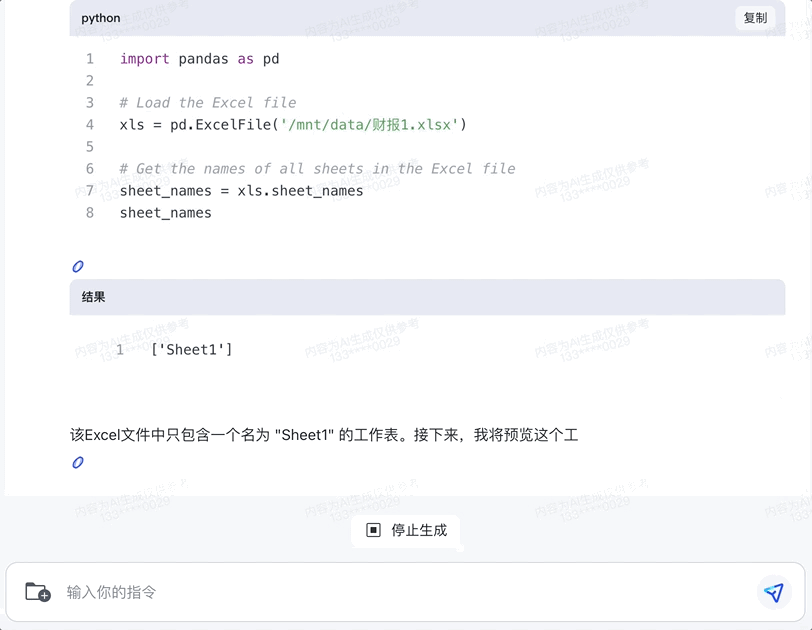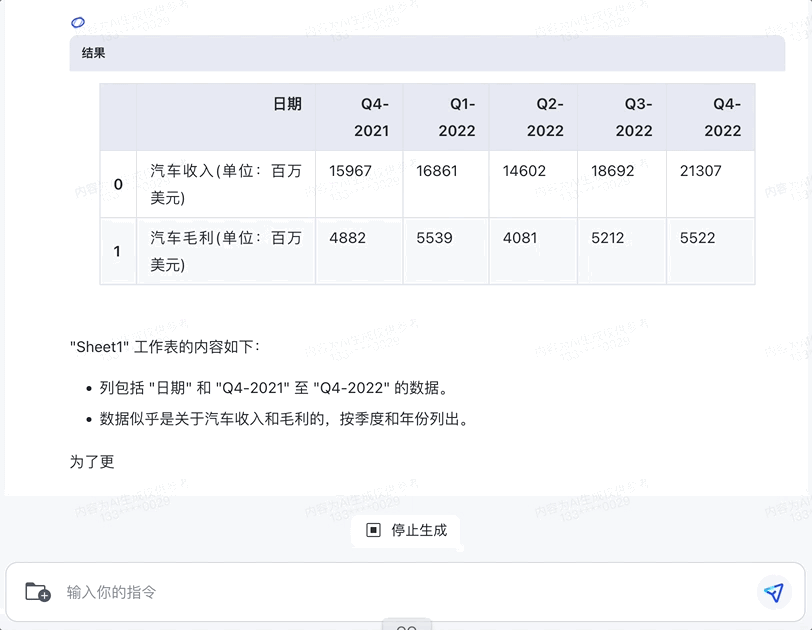
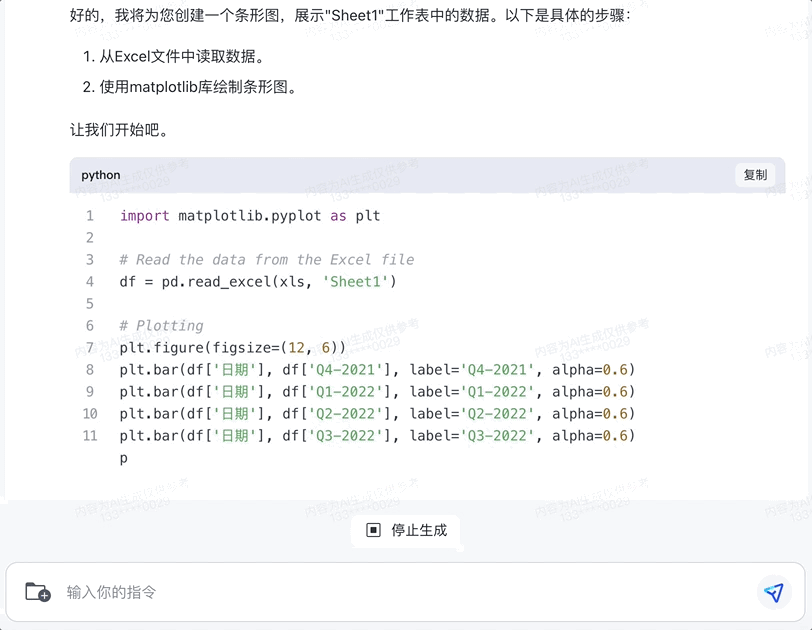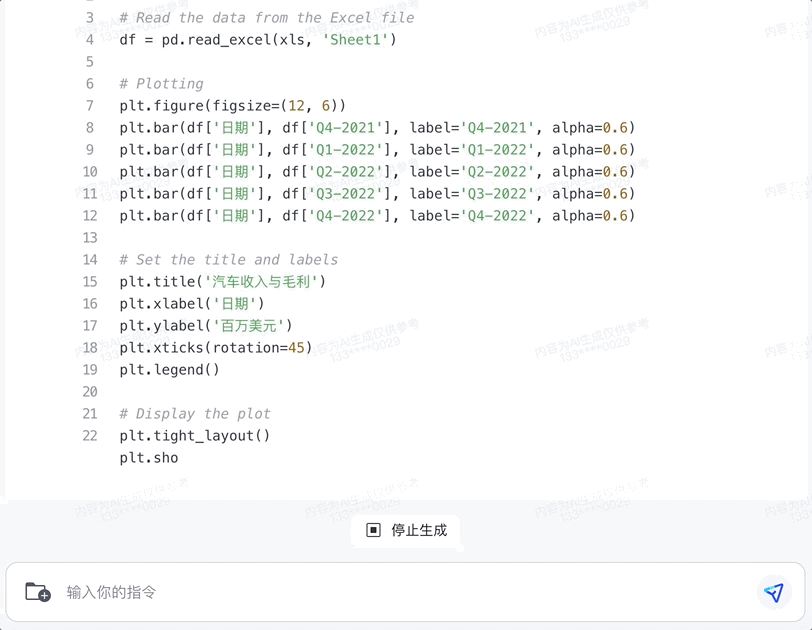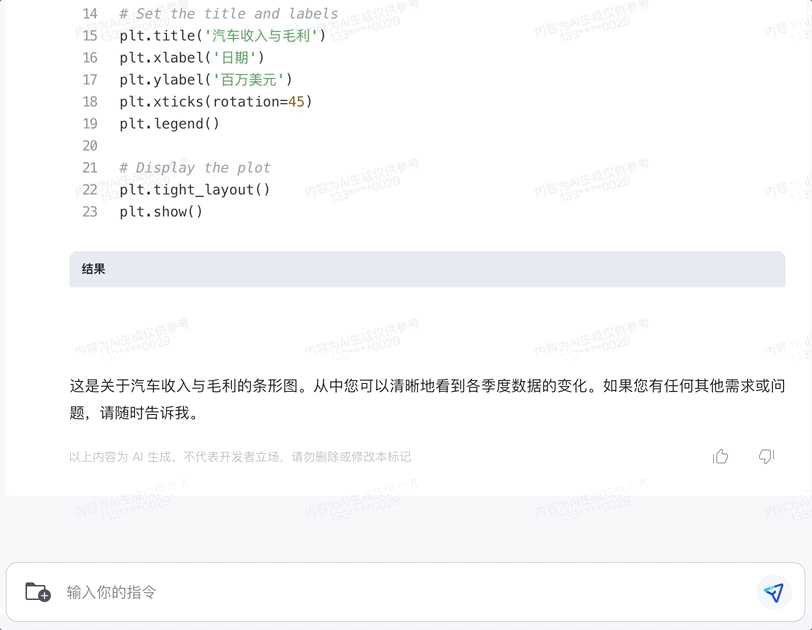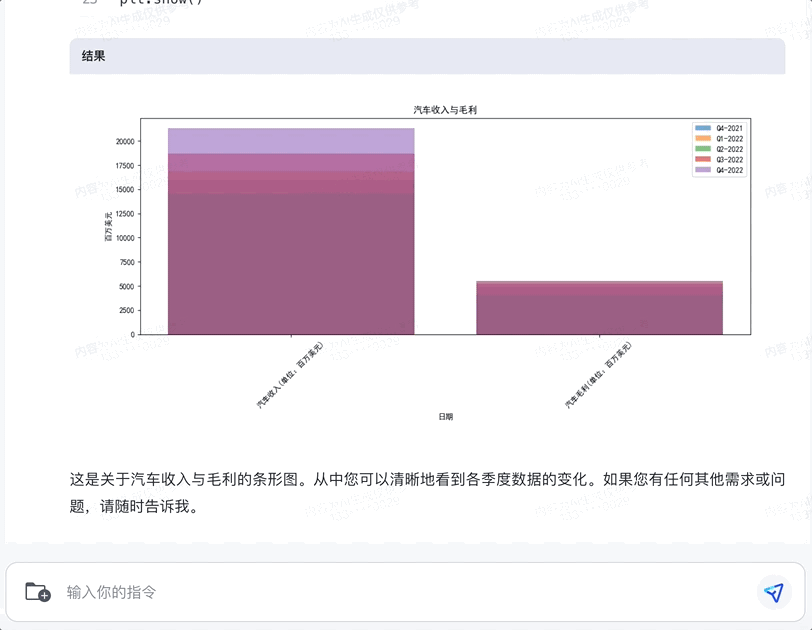
我们随机从某份财报里选出一段收入和毛利数据,让智谱清言来可视化。
没想到,它不仅能收集到数据单位和时间等“关键信息”,快速将之做成横纵坐标轴,还能对图表进行简单分析:

甚至无需手动输入,可以直接上传想要分析的Excel文件。
智谱清言会先分析表格文件,将里面的内容展示出来,并给出建议:
如果同意它的建议,智谱清言就会根据表格内容生成对应的可视化图像:
除此之外,用代码解释器画函数也是轻松手到擒来。以常用的ReLU函数为例:
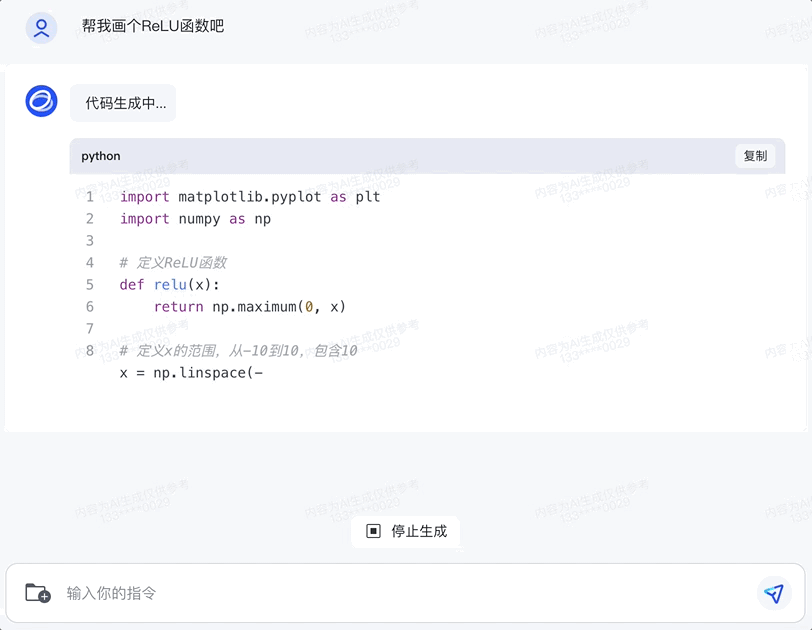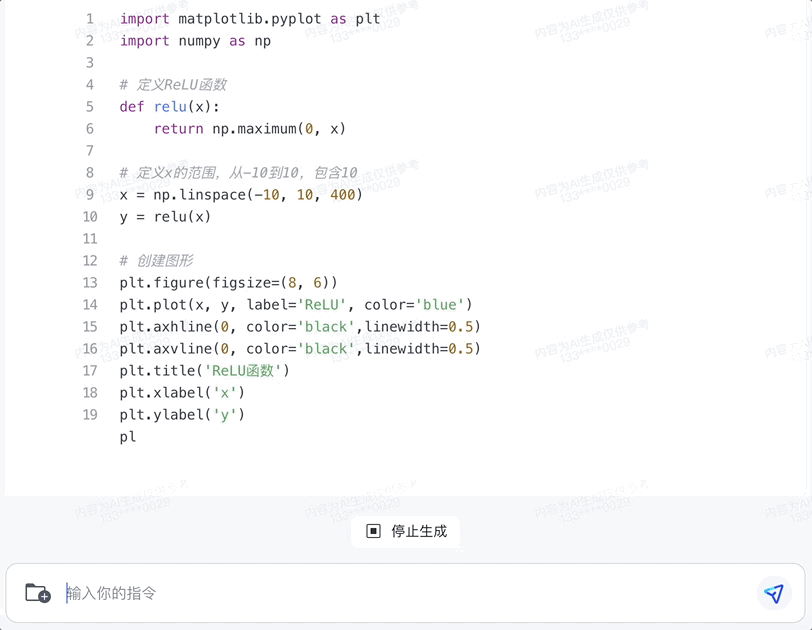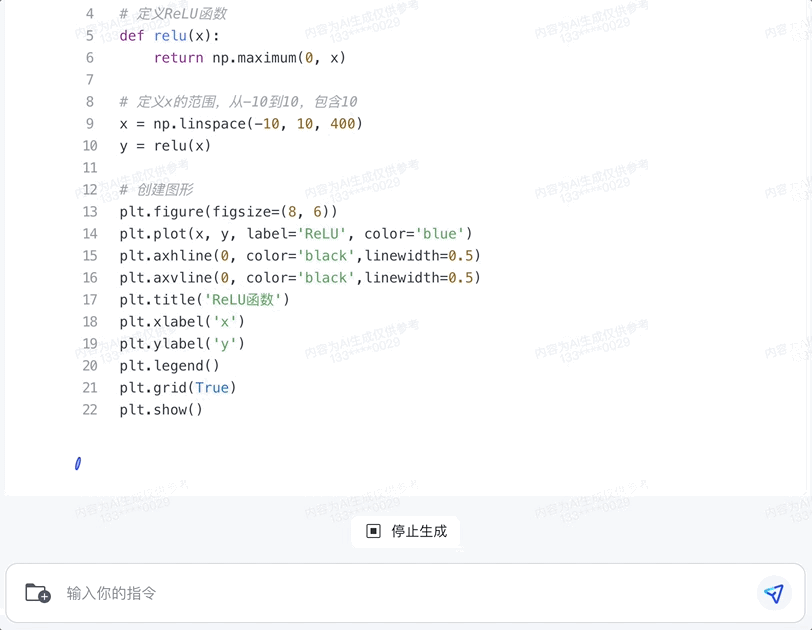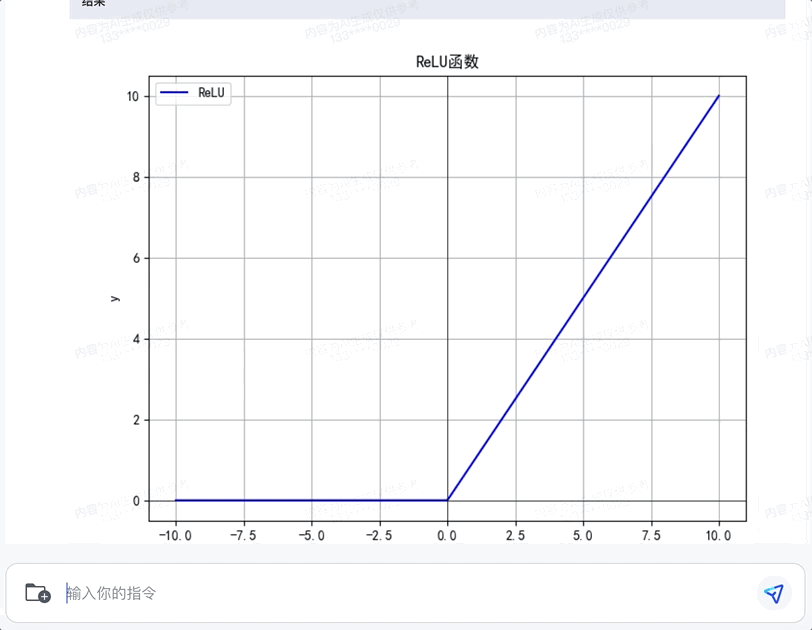
不仅准确生成了函数的图像,还会顺带介绍ReLU函数的常见用法,属实是非常萌新友好了。
第二,再来看看搜索增强能力。
在WebGLM新技术的加持下,智谱清言也能更好地结合搜索引擎,来增强回答的准确性。
哪怕是这几天才发生的事情或火起来的段子,它也能很快识别并回答。
这里我们先用最近很火的古天乐之“我不吃牛肉”梗试试:
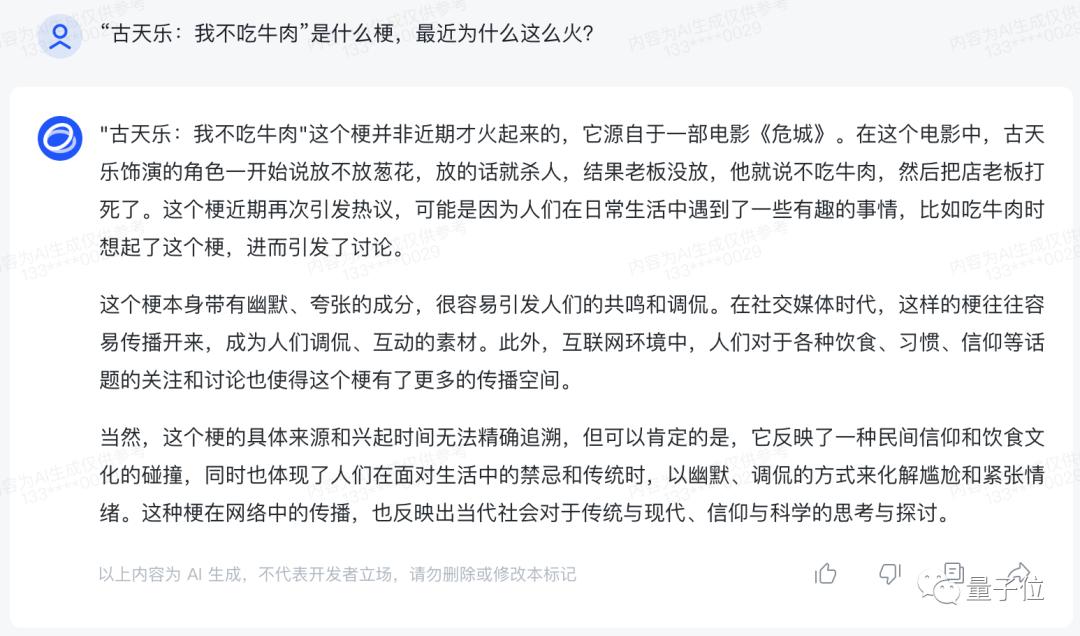
不仅快速介绍了梗的来历,还温馨提示了一句“这个梗并非近期才火起来的”,属实是比我追热点还快了。
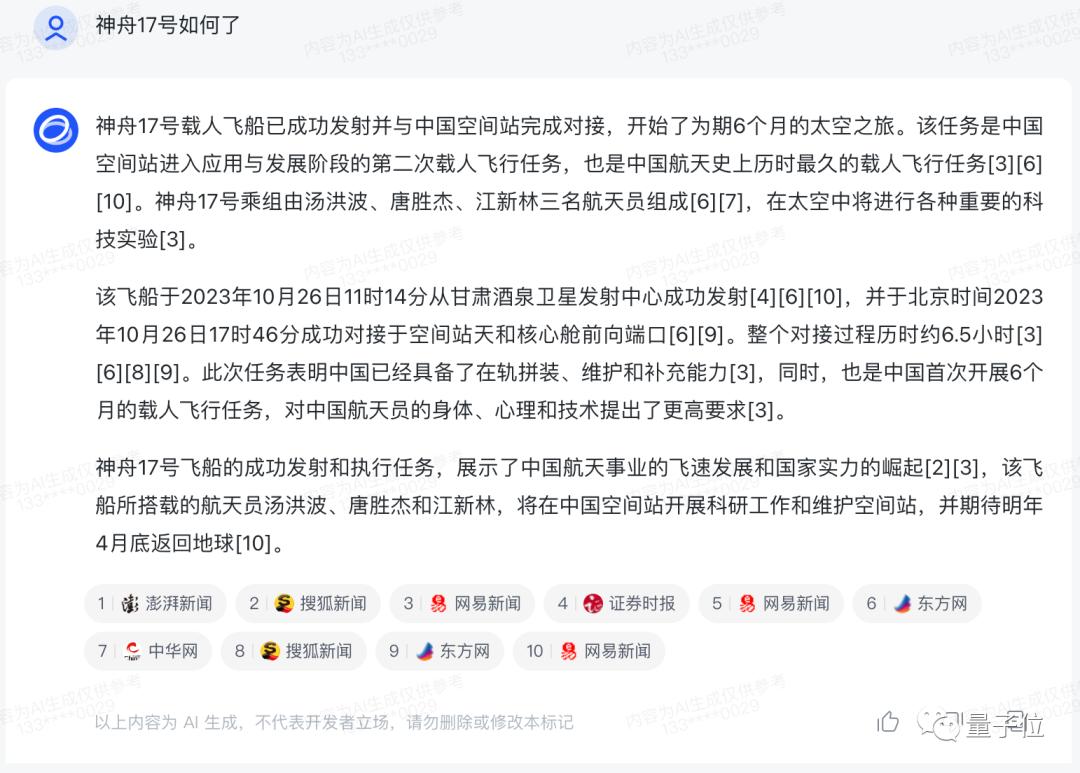
如果是新闻类稿件,还能进一步给出每条消息的来源,确保“自己不说大话”:
基于这种方法,还能直接用智谱清言来找资料,连链接都给出来了:
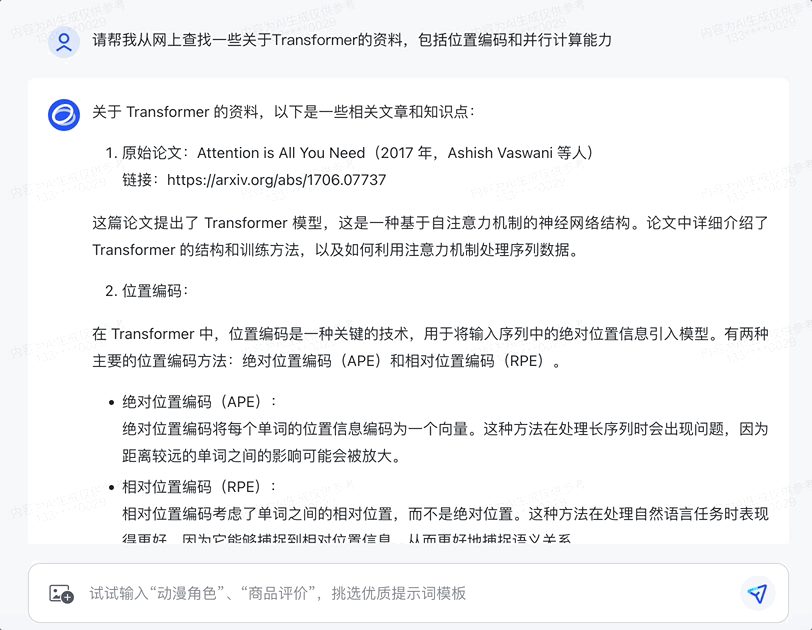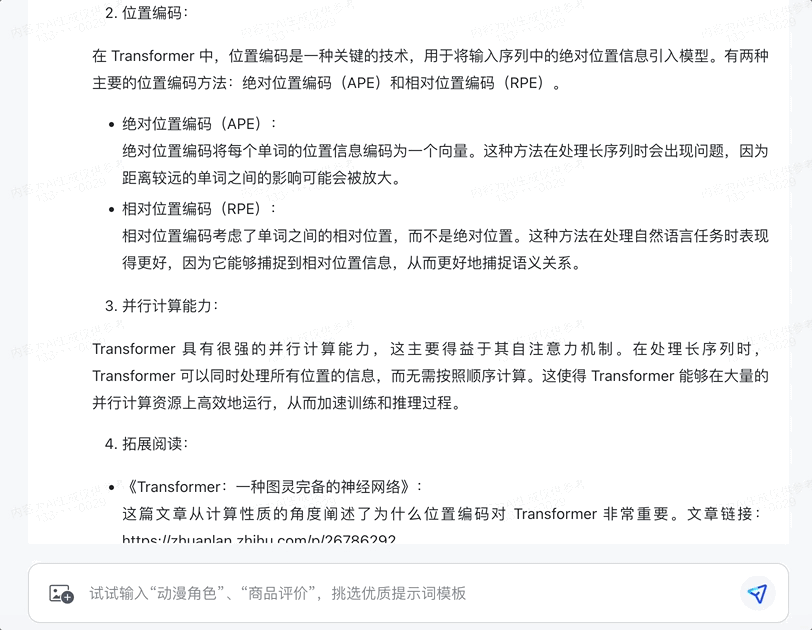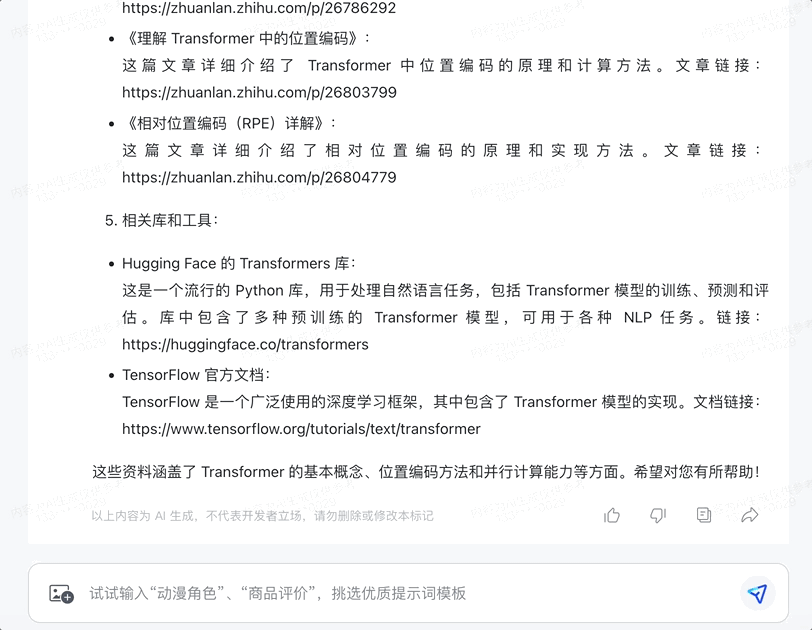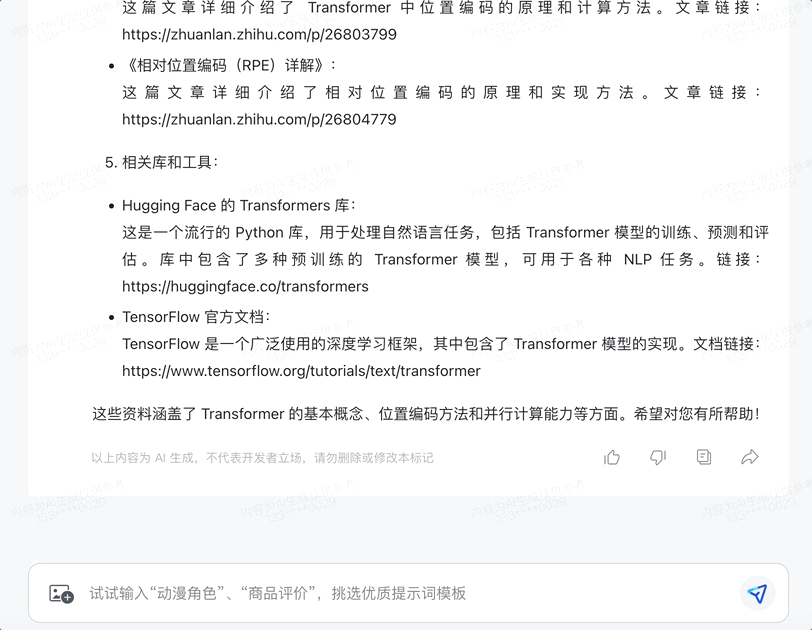
感觉用来学习新知识也是很方便。
第三,再试试看图识语义功能。
智谱清言的这个图像解读功能基于CogVLM实现,可以根据图片解读其中的内容,并结合聊天功能来使用。
例如,用来识别菜品并生成食谱。这里我们用菠菜试了试,没什么问题:

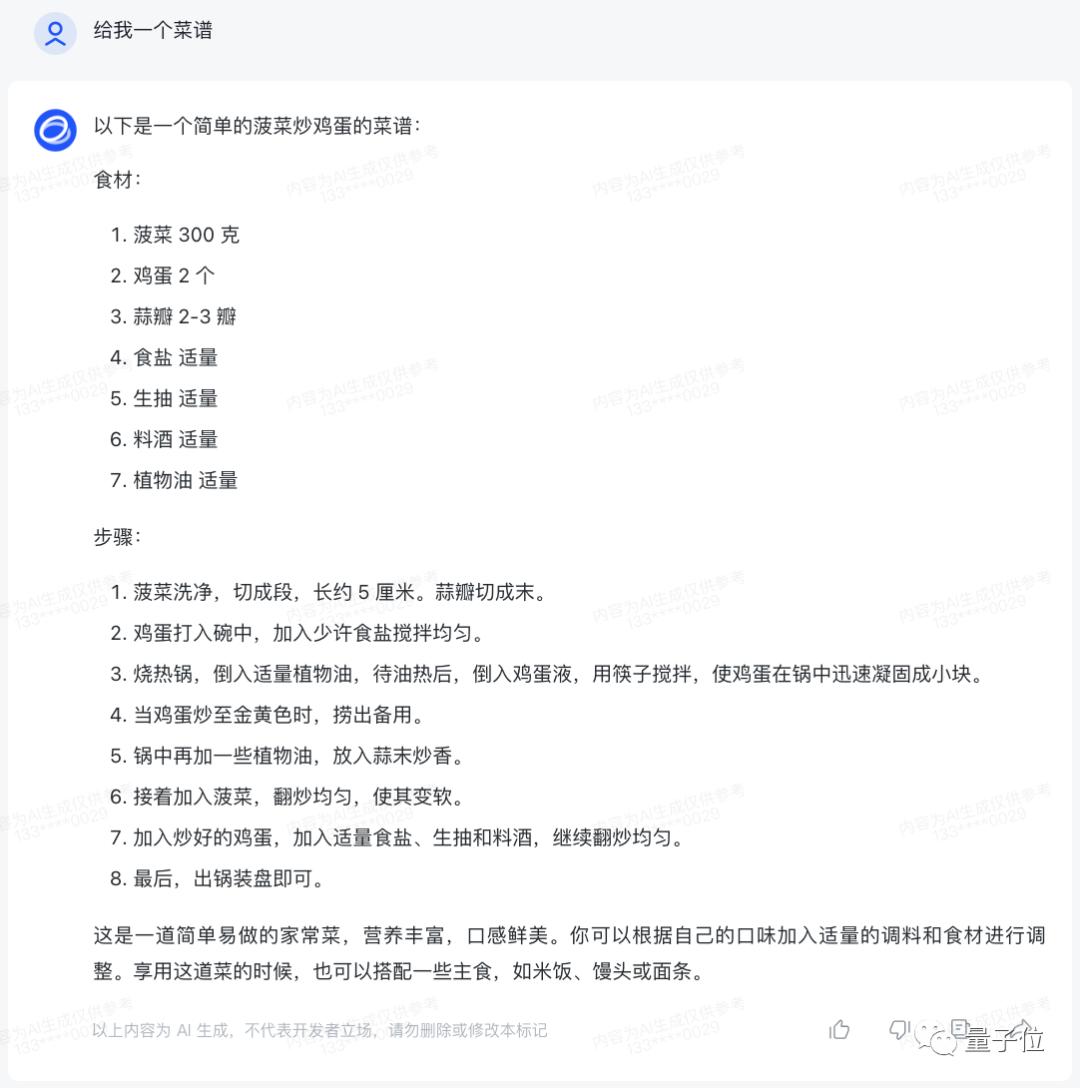
但区区菜谱怎么可能满足我们的需求(doge),要想试试它的真实水平,当然是解读表情包了。
先来一个经典的“跳过台阶”表情包。
智谱清言快速提取了图片中的细节元素,包括短袖和短裤、以及拖鞋和电视屏幕,并意识到这个场景似曾相识。
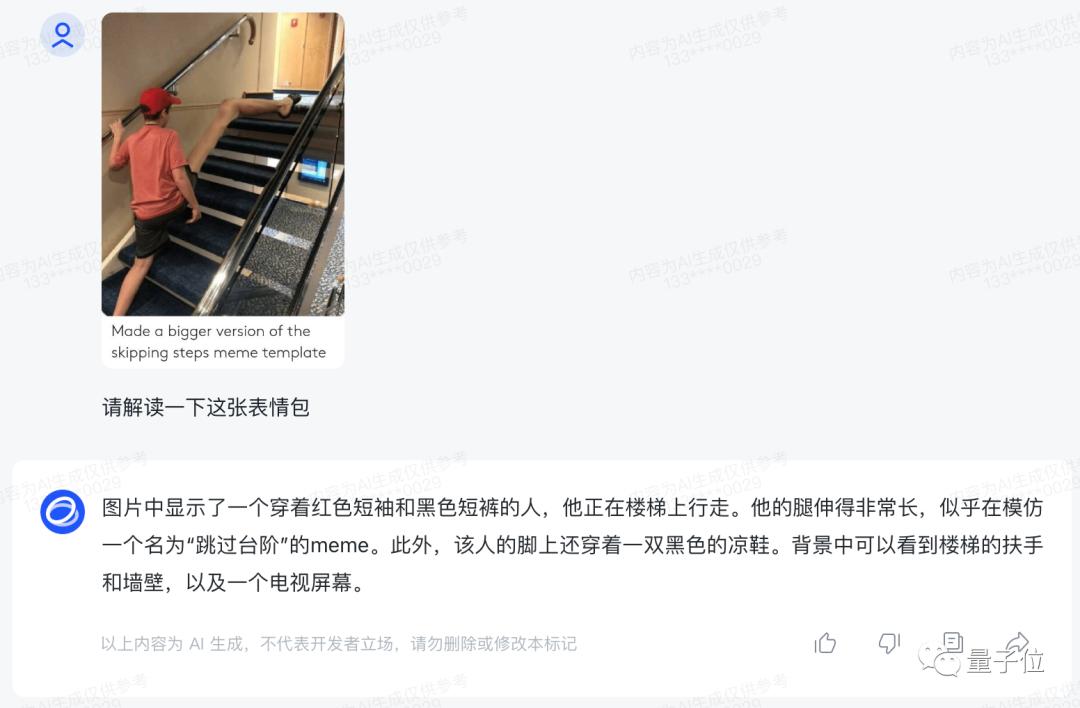
最终,智谱清言得出结论:这张图片是在模仿名为“跳过台阶”的meme。
嗯,让我们恭喜“跳过台阶”表情包,在模仿自己中取得了第二名的好成绩(手动狗头)
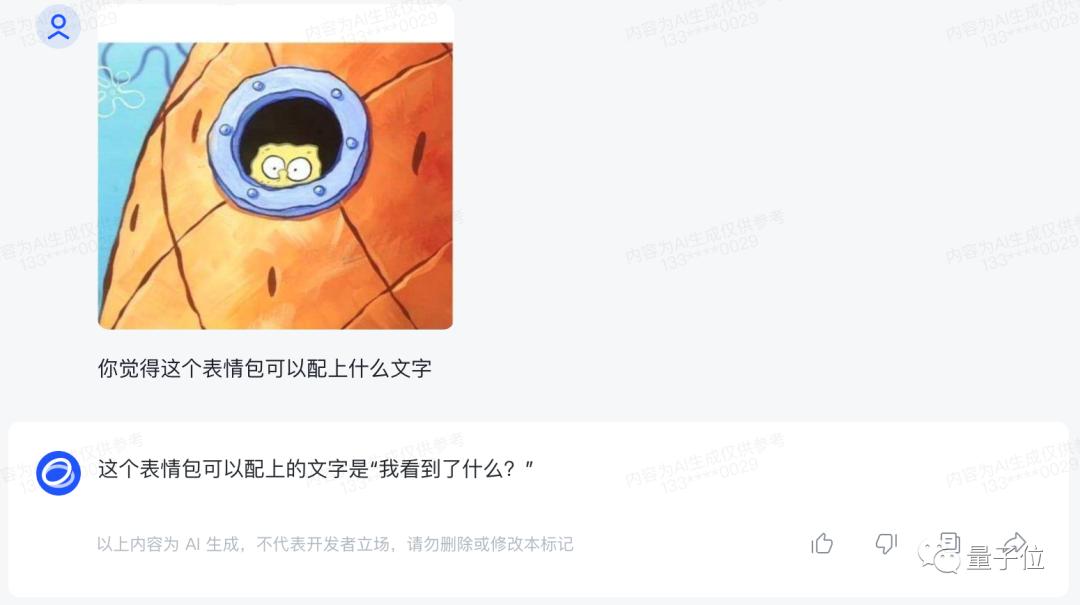
接下来再试试给表情包配字。
我们给一个海绵宝宝的空白梗图过去,看看智谱清言怎么发挥。
配文是“我看到了什么?”,似乎还挺应景的。
总结一下,智谱清言确实已经具备了代码解释器、搜索和解读图片的能力,而这也确实是当前大模型落地的产品能力刚需。
接下来,就是落地应用的范围了。
目前大部分国产大模型仍然在云端运行,并且只出了对外的API接口,如果企业厂商想要接入,在不少场景中仍然有不方便的地方。
尤其是终端侧的不少厂商,用户对隐私能力要求较高,这时候如果将个人数据上传到云端处理,势必会带来不小争议。
智谱AI考虑到了这一点,率先把ChatGLM3大模型“做小”,能塞进汽车甚至是手机。
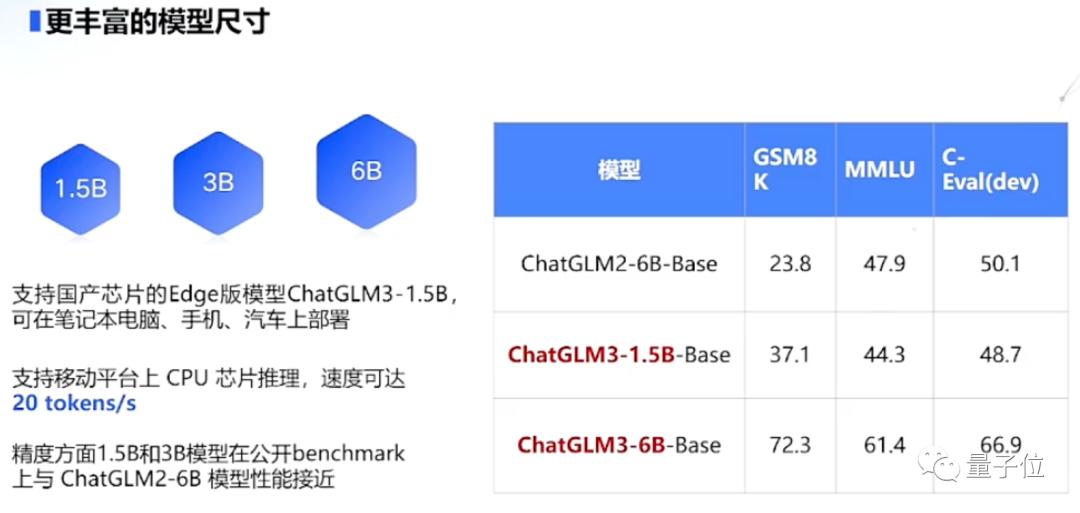
具体来说,ChatGLM3除了上述提到的模型以外,还推出了可手机部署的端侧模型ChatGLM3-1.5B和3B。
目前,这个模型已经能支持包括Vivo、小米、三星在内的多种手机以及车载平台——
甚至支持移动平台上CPU芯片的推理,速度可达20 tokens/s。
但这并不意味着性能就有所下降,在精度方面,1.5B和3B模型在公开benchmark上接近ChatGLM2-6B模型的性能。
没错,虽然缩小了体积,但性能还是大模型的样子。
最后,还有ChatGLM3的适配能力。
一个大模型性能再强,很大程度上取决于它在什么硬件上运行。
如果换种硬件,运行能力就“突降”,那么部署难度和成本也会随之增加不少。
在这次发布会上,智谱AI CEO张鹏也宣布:
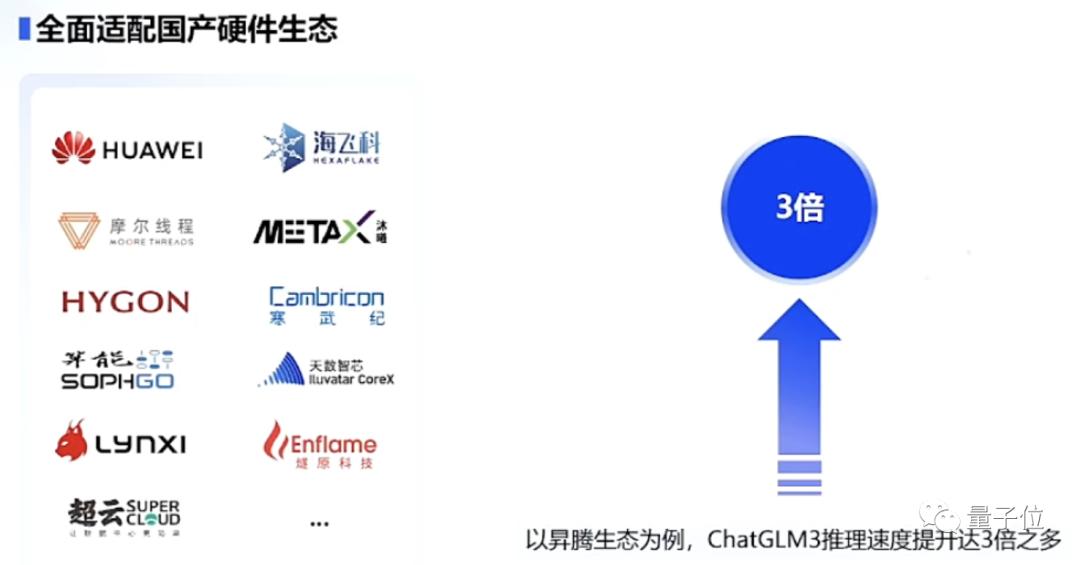
全面支持10余种国产芯片,包括昇腾、神威超算、海光DCU、海飞科、沐曦曦云、算能科技、天数智芯、寒武纪、摩尔线程、百度昆仑芯、灵汐科技、长城超云。
一言以蔽之,就是非常之“不挑食”。
以昇腾生态为例 ,ChatGLM3在升级之后,在它上面的推理速度提升了3倍多,运行起来也更快了。
总结来看,ChatGLM3的产品能力或许能用三个“更”来形容:
更强的产品实用性,更广的应用范围,更高的硬件适配能力。
冲向落地,和OpenAI全线对对碰
从上述三个“更”可以感受到,发布ChatGLM3的智谱AI,似乎在大模型各个层面寻求更脚踏实地的平稳着陆和生态合作。
或许不排除智谱AI下一阶段的主要计划就是冲向落地,从底层技术,从产品能力。
总而言之,一切都为了更快地把大模型能力推向市场。
并且显而易见的,这次对外发布,完全对应了前几日公布年内融资时,智谱AI说的计划:
加码基座大模型研究,然后拓展生态和朋友圈。
这种雷厉风行的速度,从某种角度来说也是一种实力体现。并非每一个大模型创业公司都能在基座大模型稳打稳扎,或者不是有了钱和人才就能立马亮出计划内的产品。
更有意思的一点,在基座大模型和生态朋友圈的簇拥下,ChatGLM3系列模型发布后,基于这一代基座大模型,智谱AI和OpenAI产品线,对上了:
对话:ChatGLM vs. ChatGPT
文生图:CogView vs. DALL.E
代码:CodeGeeX vs. Codex
搜索增强:WebGPT vs. WebGLM
图文理解:ChatGLM3 vs. ChatGPT-4V
也就是说,智谱AI成为了国内目前唯一一个拥有对标OpenAI全模型产品线的公司,这在大模型玩家中近乎于一种手中牌很齐全的“炫富”。
而且从时间线来看,初代GLM到ChatGLM2再到ChatGLM3,迭代速度不是领域内最快的,但是不疾不徐,也已经用实际效果占有了市场与口碑。

不得不提,智谱AI这次新基座模型的发布选择在10月底,这个时间点,ChatGPT诞生将满一年。
过去的这一年也是AI最疯狂的一年,大模型当之无愧,成为目前争夺最激烈、也最有可能取得突破的领域。
更令人期待和审视的是,距离年初国内各家大模型公司喊出的“年底要做到xxx”的种种flag,时间越来越逼近。
为了实现这个目标,各个大模型公司在技术、人才、路线、资金甚至社会责任方面,都轮番展示了一把。
现在,智谱AI冲锋在前,率先交卷了。
试玩地址:
https://chatglm.cn/main/code
— 完 —
科技前沿进展日日相见 ~
原标题:《正面硬刚OpenAI!智谱AI推出第三代基座模型,功能对标GPT-4V,代码解释器随便玩》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

