- +1
迎战GPT-4V,谷歌PaLI-3视觉语言模型问世,更小、更快、更强
原创 学术头条
上个月,ChatGPT 正式具备了图像与语音识别能力。
本月初,微软更是公布了 166 页的多模态版 GPT-4V 的相关文档,详细探讨了 GPT-4V 的功能和使用情况,这一举动引起了业界的广泛关注。

然而,在视觉语言模型的角逐中,谷歌也不甘示弱。
近日,Google Research、Google DeepMind 和 Google Cloud 共同推出了一个更小、更快、更强大的视觉语言模型(VLM)——PaLI-3,该模型与相似的体积大 10 倍的模型相比具有显著竞争力。
研究人员使用分类目标预训练的视觉变换器(ViT)模型与对比性预训练的模型(SigLIP)进行了比较,结果发现,PaLI-3 虽然在标准图像分类基准上略微表现不佳,但基于 SigLIP 的 PaLI 在各种多模态基准测试中表现出卓越的性能,特别是在定位和文本理解方面。
相关研究论文以“PaLI-3 Vision Language Models: Smaller, Faster, Stronger”为题,已发表到预印本网站 arXiv 上。

研究团队认为,仅有 50 亿参数的 PaLI-3 重新点燃了关于复杂 VLM 核心组成部分的研究,可能推动新一代规模更大的模型的发展。
更高分辨率的多模态学习
最近,大型视觉语言模型在其更大的模型中使用预训练的图像编码器,其中一些使用监督分类进行预训练(如PaLI,PaLI-X,Flamingo,PaLM-E),一些使用预训练的CLIP编码器(如BLIPv2,CrossTVR,ChatBridge,还有一些使用自定义多模态预训练(如 BEiT3,CoCa,SimVLM)。
本次研究的训练方法包括三个主要组成部分:在网络规模的图像文本数据上进行图像编码器的对比性预训练,改进的 PaLI 多模态训练数据混合以及以更高分辨率进行训练。
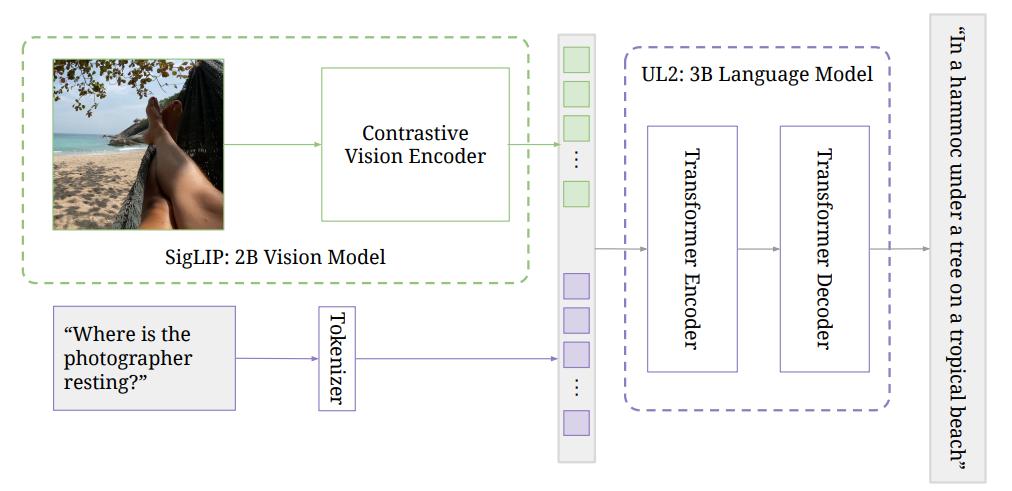
在单模态预训练阶段,图像编码器在 Web 上的图像文本配对上采用 SigLIP 训练协议进行对比预训练。研究人员采用了一种基于模型的过滤方法,保留了大约 40% 的配对。图像编码器在 224×224 的分辨率下进行训练。文本编码器-解码器是一个 3B UL2 模型,按照混合去噪程序进行训练。
在多模态训练阶段,研究人员将图像编码器与文本编码器-解码器结合在一起,形成了 PaLI 模型。这个模型针对多模态任务进行训练,保持图像编码器的冻结状态,使用原生分辨率(224×224)。
主要的数据混合来自 WebLI 数据集,经过筛选和使用特定的训练目标。其他元素包括多语言字幕、OCR 处理、跨语言 VQA 和 VQG、物体感知 VQA 以及物体检测。虽然没有包括来自视频的任务或数据,但由于强大的图像编码器,PaLI-3 在这些基准上仍然具有竞争力。此外,通过向 WebLI 添加了包含稠密文本和网络图像(如海报或文档)的 PDF 文档,以及支持 100 多种语言的文本,文档和图像理解能力得到了进一步的提高。
在提高分辨率阶段,研究通过对整个模型进行微调(解冻图像编码器)并使用逐渐增加分辨率的短期课程来提高 PaLI-3 的分辨率,保持在 812×812 和 1064×1064 分辨率处的检查点。数据混合主要集中在涉及视觉定位文本和物体检测的部分。
提升图像理解与文本定位任务
首先,研究人员在 PaLI 框架内进行了对不同的 ViT 模型的有控制的比较。结果发现,虽然 SigLIP 模型的少样本线性分类性能较差,但当在 PaLI-3 中使用时,SigLIP 模型在"简单"任务(如字幕和问答)上提供了适度的性能提升,并在更"复杂"的场景文本和空间理解任务(如 TextVQA 和 RefCOCO 变体)上提供了大幅提升。
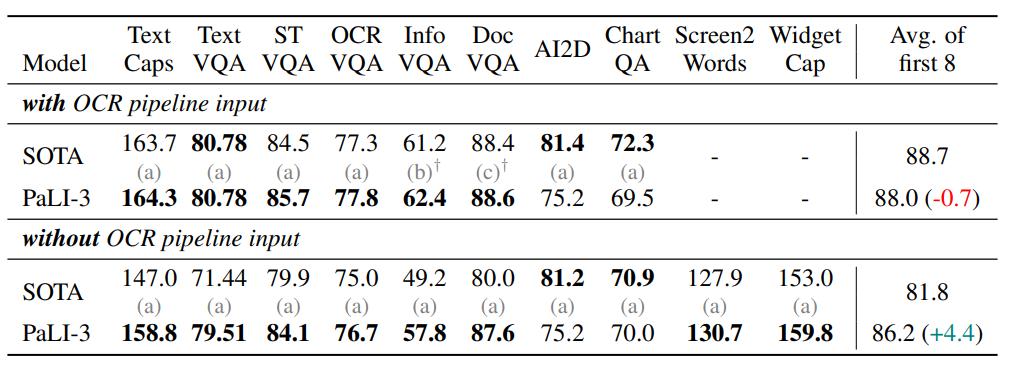
随后,研究又在视觉定位文本理解任务中评估了 PaLI-3,这些数据集中的图像涉及自然图像、插图、文档和用户界面等各种领域。PaLI-3 在绝大多数字幕和 VQA 基准上,无论是否有外部 OCR 输入,都取得了最先进的性能。唯一的例外是 AI2D 和 ChartQA,它们不仅需要理解,还需要对图表进行强大的推理能力。对于这两个基准,PaLI-3 稍微落后于 PaLI-X。
另外,研究人员还扩展了 PaLI-3 的功能,使其能够通过语言类似的输出来预测分割遮罩。实验结果表明,对于这种类型的定位任务,对比预训练要比分类预训练更为有效。完整的 PaLI-3 模型能够在指代表达分割方面稍微优于最先进的方法。
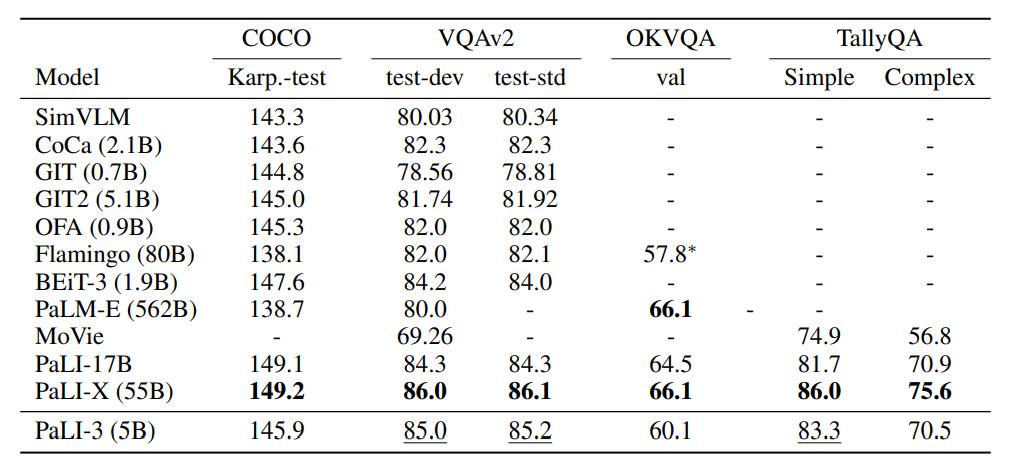
在自然图像理解部分,研究对 PaLI-3 在通用视觉语言理解任务上进行了评估,包括 COCO 字幕和 VQAv2,尽管与最近的 SOTA 模型相比,PaLI-3 的规模要小得多,但在这些基准上表现非常出色。
在视频字幕和问答部分,研究人员在 4 个视频字幕基准上对 PaLI-3 模型进行了微调和评估:MSR-VTT、VATEX、ActivityNet Captions 和 Spoken Moments in Time。然后,对 3 个视频问题解答基准进行了同样的测试:NExT-QA、MSR-VTT-QA 和 ActivityNet-QA。尽管没有使用视频数据进行预训练,PaLI-3 仍然以较小的模型规模取得了出色的视频质量保证结果。
总而言之,在本研究中,研究人员深入研究了 VLM 中图像编码器的预训练,特别是 PaLI 类型的模型。研究首次明确比较了分类预训练和图像文本(对比性)预训练这两种方法,发现后者可以带来更好和更高效的 VLM,特别是在定位和文本理解任务方面。
另外,研究人员在论文中指出:“这只是 VLM 的一个小方面,我们希望这项研究和其结果能够激励对 VLM 训练的众多其他方面进行深入探讨。”
论文链接:
https://arxiv.org/abs/2310.09199
原标题:《迎战GPT-4V!谷歌PaLI-3视觉语言模型问世,更小、更快、更强》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

