- +1
所有基准测试都优于Llama 2 13B,最好的7B模型来了
机器之心报道
编辑:陈萍、大盘鸡
这是真正的开源。
在 Llama 2 系列模型发布后的这几个月里,各大公司机构也在不断推出自家产品。
近日,一家法国人工智能初创公司 Mistral AI 发布了一款新模型 Mistral 7B,其在每个基准测试中,都优于 Llama 2 13B,并且在代码、数学和推理方面也优于 LLaMA 1 34B。
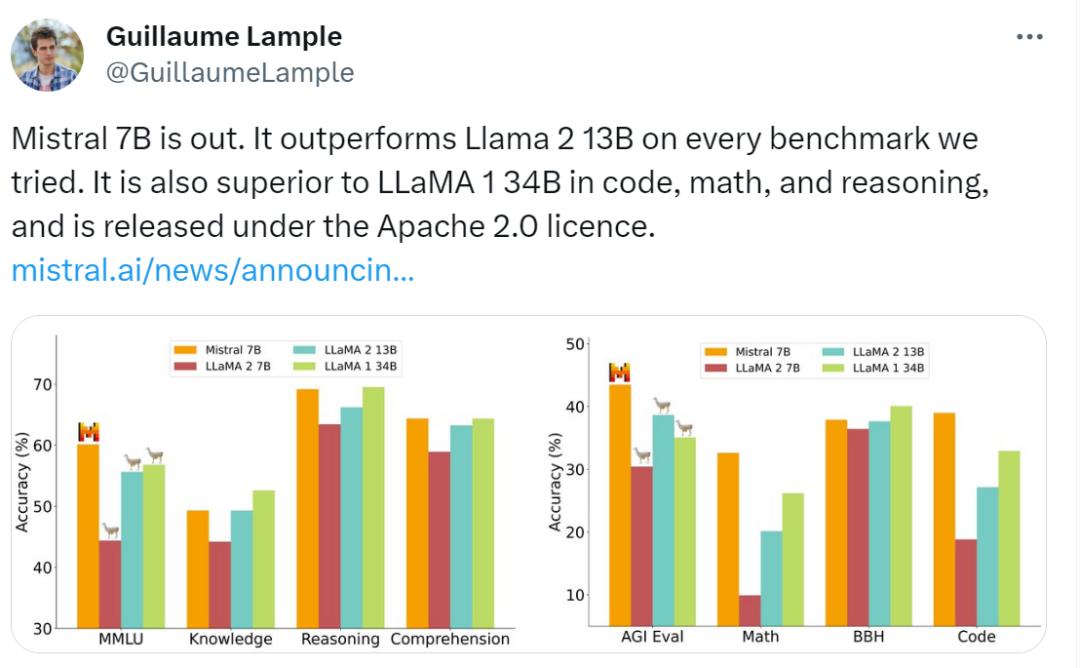
Mistral AI 联合创始人兼首席科学家 Guillaume Lample 也在推特上宣布了这一好消息。
在其官方博客中,他们表示,「这是迄今为止最好的 7B 模型,Apache 2.0。」

具体而言,Mistral 7B 具体参数量为 7.3B:
在所有基准测试中均优于 Llama 2 13B;
在多个基准测试中优于 Llama 1 34B;
代码性能接近 CodeLlama 7B,同时对英语任务非常擅长;
使用分组查询注意力(GQA,Grouped-query attention)来加快推理速度;
使用滑动窗口注意力(SWA,Sliding Window Attention)以较小的成本处理较长的序列。
值得一提的是,Mistral 7B 是在 Apache 2.0 许可下发布的,这是一种高度宽松的方案,除了归属之外,对使用或复制没有任何限制。这意味着该模型可以被业余爱好者、价值数十亿美元的公司等使用,只要他们拥有能够在本地运行该模型的系统或愿意支付必要的云资源费用。
下载完以后可以在任何地方使用(包括本地);
使用 vLLM 推理服务器和 skypilot 将其部署在任何云 (AWS/GCP/Azure) 上;
可以在 HuggingFace 上使用它。
用户还可以在不同任务上对 Mistral 7B 进行微调。
性能表现
首先,Mistral AI 将 Mistral 7B 与 Llama 2 家族模型进行了比较:
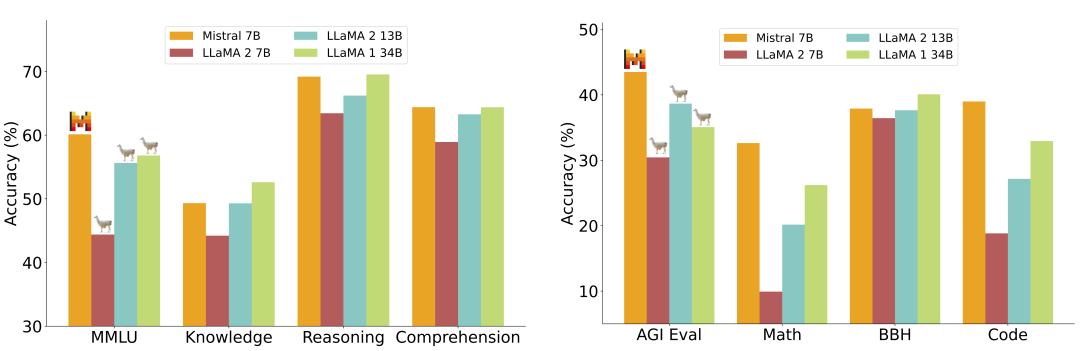
Mistral 7B 和不同 Llama 版本在各种基准测试中的性能。结果显示 Mistral 7B 在所有指标上都显著优于 Llama 2 13B,并且与 Llama 34B 相当(由于 Llama 2 34B 尚未发布,因而只报告了 Llama 34B 的结果)。
实验中,Mistral AI 将基准测试按照主题进行了分类:
常识推理:Hellaswag、Winogrande、PIQA、SIQA、OpenbookQA、ARC-Easy、ARC-Challenge 和 CommonsenseQA 的 0-shot 平均值;
世界知识:NaturalQuestions 和 TriviaQA 的 5-shot 平均值;
阅读理解:BoolQ 和 QuAC 的 0-shot 平均值;
数学:maj@8 的 8-shot GSM8K 和 maj@4 的 4-shot MATH 的平均值;
代码:0-shot Humaneval 和 3-shot MBPP 的平均值;
热门聚合结果:5-shot MMLU、3-shot BBH 和 3-5-shot AGI Eval(仅限英文多项选择题)。

在推理、理解和 STEM 推理 (MMLU) 方面,Mistral 7B 的性能与大小为其 3 倍以上的 Llama 2 相当。这既节省了内存,又增加了吞吐量。
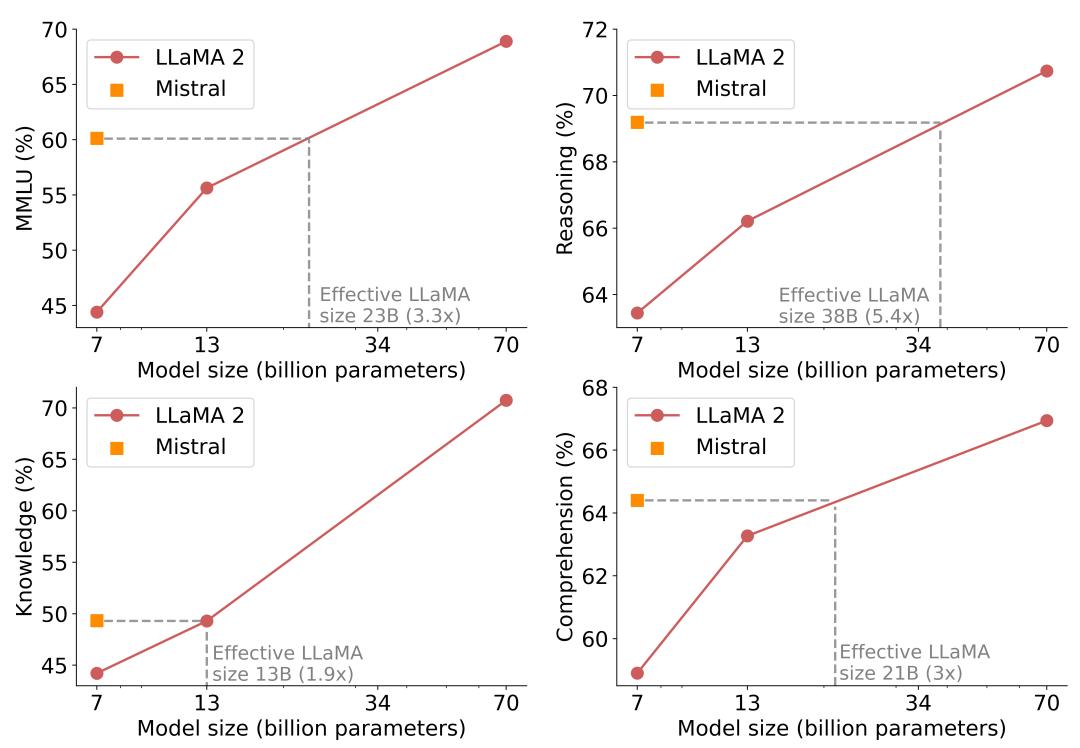
Mistral 7B 和 Llama 2 (7B/13/70B) 在 MMLU、常识推理、世界知识和阅读理解上的结果。Mistral 7B 在所有评估中都大大优于 Llama 2 13B,除了在知识基准方面,它们处于同等水平。
在训练方法上,该研究使用 GQA 和 4096 个 token 的滑动窗口对其进行训练,从而获得恒定的缓存大小和线性解码速度。此外该研究对 FlashAttention v2 和 xFormers 支持滑动窗口的更改已向社区开放。
具体到细节,Mistral 7B 采用 SWA 机制,其中每一层都会关注之前的 4096 个隐藏状态,其线性计算成本为 O(sliding_window.seq_len)。在实践中,Mistral AI 对 FlashAttention 和 xFormers 所做的修改使 4k 窗口下 16k 序列长度的速度提高了 2 倍。
SWA 机制利用了 Transformer 的堆叠层来关注过去超出窗口大小的内容:第 k 层的 token i 会关注第 k-1 层的 token [i-sliding_window, i]。这些 token 关注 token [i-2*sliding_window, i]。比起注意力模式所需要的,更高层能够接触到更久远的过去信息。
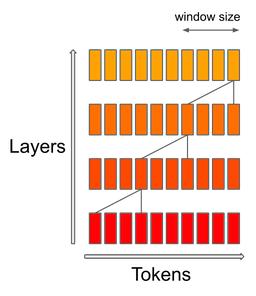
最后,固定的注意力跨度意味着可以使用旋转缓冲区将缓存的大小限制在 token sliding_window 的范围内。这为 8192 序列长度的推理节省了一半的缓存内存,而不会影响模型质量。
针对聊天微调 Mistral 7B
为了展示 Mistral 7B 的泛化能力,研究者在 HuggingFace 上公开的指令数据集上对其进行了微调。没有技巧,没有专有数据。由此产生的模型 Mistral 7B Instruct 在 MT-Bench 上优于所有 7B 模型,并可与 13B 聊天模型相媲美。
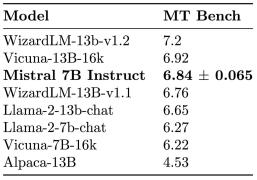
Mistral 7B Instruct 模型证明了微调基础模型以获得非常好性能是容易做到的。
参考链接:
https://twitter.com/GuillaumeLample/status/1707053786374496726
https://mistral.ai/news/announcing-mistral-7b/© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《所有基准测试都优于Llama 2 13B,最好的7B模型来了,免费用》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

