- +1
大模型牌桌最后能剩下谁?

“大模型产品「还没成年就出来打工挣钱」的感觉:闲聊可以,但不能细究。”
撰文|史圣园
编辑|翟文婷
腾讯混元大模型终于亮相。
用腾讯自己的话说,之前是「不急于把半成品拿出来展示」。但此次发布,他们却也坦陈,目前「只是可用、可实践」。
早在 3月,百度文心一言就启动了内测邀请;4月,阿里通义千问紧随其后。连姗姗来迟的字节,也在 8 月 17 日对外测试 AI 对话产品「豆包」。
在「百模大战」中,先发优势重要吗?
似乎没那么重要。大模型是一种非常标准化的产品,无论是个人、企业还是开发者,都可通过 API 即可接入,切换模型的成本相当低。最终,还是产品的效果和体验决定一切。
但也有点作用。用户真实的提问,是最宝贵的数据资产。先跑起来,就能积累更多数据,帮助大模型在充满噪音和歧义的真实场景中训练、学习、增强能力。
8 家首批通过《生成式人工智能服务管理暂行办法》的大模型产品,已经陆续开放注册,普通用户终于可以上手体验了。不过,聊上几轮,就会有种大模型产品「还没成年就出来打工挣钱」的感觉 —— 闲聊可以,但不能细究。
这也不免让人担心,生成结果的不稳定性,会成为实际部署的掣肘,且优化周期较为漫长。
真正能留在牌桌的大模型玩家,一定是少数。
一、同质化竞争?
从各个厂商公布的大模型产品和解决方案来看,同质化的情况比较严重。
在 toB 办公场景,主要聚焦在文档和会议场景,充当创作助理、会议秘书、设计助手的角色;toC 个人场景,打出的牌也都是情感陪伴、生活向科普(菜谱、旅游策划)。
目前,百度文心、字节豆包、智谱 AI、百川智能均全面开放注册使用;中科院紫东太初正在维护中,商汤日日新需要邀请码,MiniMax 仅面向开发者,上海人工智能实验室的书生通用大模型还未开放注册。
此外,讯飞星火大模型也开放了全面注册,腾讯混元大模型暂时还是邀请制,需要申请并排队。
开放注册的 5 款产品都是 chatbot 形式,也都加入了不同程度的提示语引导、使用场景提示。有的是在对话中推荐问题,有的预设了助手角色。有的做得更深入一些,制作了提示语模板、社区或插件,能隐隐约约看到搭建生态的野心,向用户和开发者创造力借智,但目前都处于较为初期的阶段。
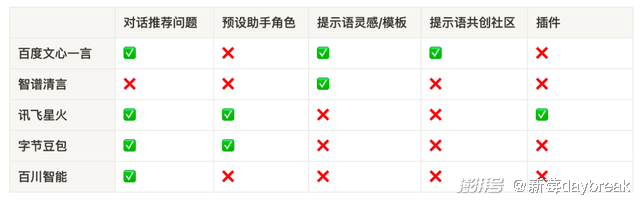
但用户感知上的相似,并不等于业务逻辑的相似。
各家大模型厂商无一例外,都想借力公司既有业务,进行差异化竞争。
百度是最强调「生态」的大厂,结合最深的业务场景也是「搜索」。在文心一言首页的显著位置,就放置了插件市场入驻申请的链接。在连接开发者和创业者上,百度也尤为积极,抢先举办了文心杯创业比赛。而在百度搜索引擎中,AI对话助手也已经上线,并开放使用。

阿里通义千问最先落地的场景是钉钉,钉钉总裁叶军曾表示,「要用大模型把钉钉重做一遍」。
腾讯发布混元大模型时,也同步表示,腾讯云、腾讯广告、腾讯游戏、腾讯会议等 50 余个业务和产品均已接入。
而讯飞在机器语音识别领域掌握 9 种方言,这让星火大模型在接纳语音数据时占据了绝对优势。此外,讯飞的学习机等教育硬件,让星火大模型与教育场景结合有着天然优势。
二、「很多都会迅速消失」
除了技术层的攻坚克难、业务层的生态集结,还有「大模型评测」的战场:所有大厂都想要把 GPT 比下去。
据不完全统计,8月以来,至少有 4 家本土大模型官宣在某些方面超越了 GPT。
科大讯飞表示星火大模型的代码能力超过了 GPT 3.5;商汤说自己的新模型 internlm-123b 在51个评测集的30万个问题上超过了 GPT 3.5;百川CEO王小川称自家的模型微调后,在中文问答、摘要细分场景上的表现超越了 GPT 3.5;腾讯则更不客气,副总裁蒋杰称混元大模型中文能力全面超过 GPT-3.5。
如果没有「在某个特定领域超过 GPT」的评测结果,似乎都不好意思加入这场大模型的混战。
但让一个模型成为某个「评测数据集」的顶级做题家,对于实际的效率提升,意义不大。
业内人士都知道有个投机取巧的训练方法,是让优质大模型在开源数据集上进行输出,再用这些输出的结果来微调小模型,直接抄大模型的作业。但伯克利学者研究表明,这些模仿模型只是看起来不错,实际能力并没有提升,在真实场景中的泛化能力较弱。
目前,OpenAl 的 GPT-3 拥有1750亿个参数,本土大模型的规模一般在数百亿到千亿之间。
此外,脱离了具体使用场景的评测都是耍流氓。在toB办公场景下,准确地提取数据,并给到稳定的输出最重要。在toC陪伴场景中,模型的共情力、幽默感才是提供情绪价值的关键。各家发布的评测榜单,更像是 PR 行为,而非可用性评估。
百度智能云事业群总裁沈抖在接受采访时说,市面上有非常多模型,但很多都会迅速消失。「现在很多模型之所以还存在,是因为很多人还不知道它的好坏。反正谁也试不了,谁也用不了,一测排名还挺靠前。但随着模型的放开,优劣更容易评判了。」
已经到了逐渐放开的时刻。
新莓daybreak 体验了下目前 C 端可注册的大模型产品。在生成「小红书种草文案」这个任务上,几款产品的表现均达到了「文通字顺」,甚至「有点好用」。文心一言擅长加tag引流,豆包的文案颇有亲切感,混元的文案有点4A广告公司的味道,智谱清言像是严谨的语文老师,讯飞星火则从场景切入。还是本土模型最懂本土社交平台。
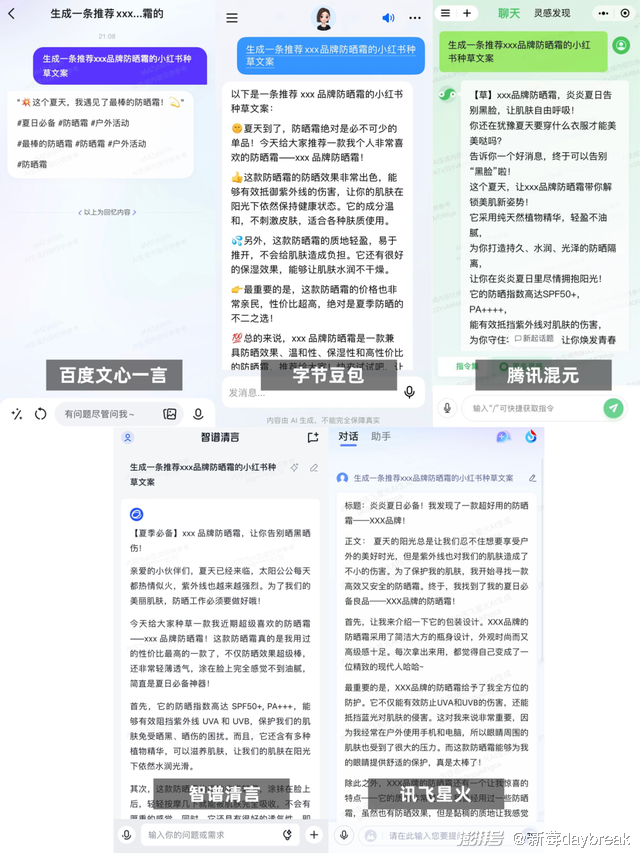
但在 toB,大模型的脚尖已经触碰到了应用场景的泥泞。
各家厂商从不低调,腾讯、华为、商汤、百度都曾提到,自己的大模型解决方案已覆盖了十余个、数十个行业场景。但实际上,企业真的用起来了吗?
「让大模型成为某一行业的助理,比如金融行业的大模型,还是太泛泛了,需要把行业和场景拆得更细。」Peter说,他是一名算法工程师,在某金融机构从事大模型应用的开发和探索。
他介绍,以银行为例,有多个主营业务。光是资本市场业务,下面就有定向增发、股权投资、股权激励、债转股、可交换债券等十余个子业务。仅仅是股权激励,相关法律法规就有数十篇。
「现在我们甚至不能让大模型学习股权激励的法律法规上做出可靠的回答。10个问题,能有5个回答正确就已经相当好了。」
三、模型要大,应用要垂
不可否认的是,在中文大模型基座能力尚弱的时候,上层应用就已经先跑起来了。
「理想化的场景是,大模型可以在最初的交流中识别提问者的意图,然后再分给掌握细分领域知识的、不同的 AI Agents,后续让各个 AI Agents 去处理,而不是做一个大而全的法律AI助手、金融AI助手。」
David 是某家初创公司的 AI 产品经理,开发了一款类似 Character.ai 的产品。他认为,作为开发者,流程规划、系统稳定等等工程层面的努力,对于落地应用来说更重要。
Magi 创始人季逸超,在播客中也提到过类似的观点:「AI 创业是 80% 的产品工程 + 20% 的底层技术。」
季逸超认为,大模型超过 65% 的应用场景,是信息的检索、汇总、再生成,约 20% 的需求是流程自动化、决策辅助。
以信息的检索生成为例,看似简单,实则每个角落、每个细节都需要优化。数据是否能够处理干净、文本块的切分是否完整、训练时样本和机器怎么分布、响应速度和成本怎么权衡,这其中涉及到大量的工作。如果每个环节的质量都只有 60-70 分,那么串联起来,最终可用性一定不理想。
甲子光年对国内外热度较高的 10 款大模型进行了客群分析,国外的大模型厂商,主要还是侧重普通C端用户使用,商业模式是收取订阅费。而国内的大模型似乎都打定主意,做平台、做生态,然后从 B 端客户那里挣钱,商业模式包括按量计费的 API 调用,以及更加深入的解决方案服务、模型定制开发。

然而无论 toB 还是 toC,商业模式也许会有不同,让用户买单的关键还是基础模型的能力。
毕竟,上层应用的能力,还是由底层模型决定的。基础模型拥有的能力,上层应用不一定能够发挥出来;但基础模型没有的能力,上层应用一定做不到。
Peter 坦陈,他们测试了一圈本土大模型,在真实场景下,表现都还「差点意思」。而对于行业模型微调,他们「想都不敢想」,因为「一次至少要 500 万起」,效果却尚未可知。
「所以现阶段一定会有垂直应用,但不太可能有垂直模型。」Peter 总结道。
另一个国内应用开发者需要考虑的关键是合规。有两项法规提供了具体指导:1月10日开始施行的《互联网信息服务深度合成管理规定》,以及8月15日开始施行的《生成式人工智能服务管理暂行办法》。
目前,AI 产品上线前需要通过算法备案和安全评估,业内称之为「双新评估」。可以说,能够更快、更及时地做到合规,也是产品竞争力的一部分。
细心的用户不难发现,目前国内 C 端可用的大模型对话产品界面,几乎都有免责声明和水印标记。前者提示 AI 生成的内容不一定保证真实,后者则是确保信息传播时的可追溯性。
国产大模型只是刚刚从实验室走向市场,开始面向真实用户。此时就拿出商业世界的价值衡量标准,对它们发出极度务实的三连问,「能否真正提升工作效率、能否有效降低成本、能否优化用户体验」,未免显得有些严苛。但这恰恰是企业用户的真正关切,也是大模型在商业应用中的核心价值。
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

