- +1
大模型热潮下的实习生:人均高学历?却在大厂“打标签”
原创 朱悦 甲子光年

好奇和憧憬背后,感受到真实的混乱和价值感匮乏。
作者|朱悦
编辑|栗子
正式实习的第一天,晨曦感觉自己可能“被骗”了。
刚刚结束完学校的毕业论文,准研究生晨曦准备给自己找点事做。投递了几份简历之后,很快,国内某互联网大厂的人工智能编辑岗位(翻译方向)向她发出了邀请。
职位描述上写着:
1. 为人工智能机器学习提供优质的语料,复制模型训练迭代;
2. 与技术组对接需求,按时交付优质合格的数据,对编辑结果质量负责。
对于不了解模型训练的晨曦来说,这看上去似乎是一份相当不错的实习。
晨曦面试的是翻译方向,这与她所就读的英语专业十分契合;年初ChatGPT在国内爆火,晨曦日常就有使用AI产品的习惯,符合自己的兴趣爱好;另外,能有机会参与新兴的科技产业发展对于文科生来说可遇不可求;当然,最大的吸引力来自于这家互联网大厂。在过去几年内,这家公司已经成功吸引了无数年轻学生前仆后继。从某种角度来说,简历上的大厂名字足以成为自身能力的象征。
只是,除了招聘页面上简单的职位描述,晨曦没有从面试官那里获得关于这份实习更多的信息。
“我当时为什么觉得被骗,就是因为面试的时候HR基本都聚焦在翻译相关的问题。”在面试中做了几道翻译题之后,晨曦顺利拿到了offer。一直到工作之前,她都以为这是一份翻译的工作。
感到“被骗”的不止晨曦一人。
作为人工智能编辑最早的一批实习生,杨小云在2月底也来到了这家大厂。面试官表示,这是一份对信息抓取、语言概括和文字编辑等能力要求很高的工作。
实际上手之后她意识到:“HR描述的工作跟实操的工作,完全是两件事情。说得再天花乱坠,其实也是一个‘打标’的工作。”
如今,人工智能热潮带火了这些以假乱真的聊天机器人,以及通过简单提示就能生成图片的绘画软件。大模型的现象级出圈,使得数据、算法、算力作为训练大模型的基础而备受关注,数据标注就是数据环节必不可少的一部分。
2007年,时任普林斯顿大学计算机科学系的助理教授李飞飞开启了一个名为ImageNet的项目,希望扩展可用于训练AI算法的数据。
为了给每个单词提供尽可能多的视觉案例,亚马逊众包平台Mechanical Turk上的近5万名工人,花了两年半的时间标记出图片中的对象,例如气球、草莓等共计320万张图片。这些工人来自全球的167个国家,大多分布在人工成本低廉的地区。
在过去很长一段时间里,数据标注对语言与图像识别的认知要求都并不高。大模型时代,数据标注从图像转向语言,要求更高、更垂直,需要特定领域的专业知识和流畅的语言能力。
但对于普通的数据标注员来说,它依然是一份不断重复的低技术含量的工作。
正如同这些“被骗”的名校学生进大厂实习一样,他们没办法说清,自己的工作是为了实现什么样的目的,有什么价值。他们往往只有一个模糊的认识,为了“训练大模型”。
以晨曦和杨小云为代表的人工智能编辑实习生,便因为训练大模型的需要而诞生。这些受到热捧的大模型,让实习生们怀揣着好奇和憧憬进入,同时,也让他们感受到背后真实的混乱和价值感匮乏。
1.当大学生涌入大模型数据标注
人们通常会认为,数据标注员是一群身处三四线城市、低学历、高年龄的群体。事实上这也的确是此前国内数据标注员的现状。
根据人社部2021年发布的《人工智能训练师国家职业技能标准》,人工智能训练师的普遍受教育程度是初中毕业(或相当文化程度)。他们可能分散在河北、河南、山东、山西等传统劳动密集型企业选址的地区,甚至更偏远的山区——在那里,数据标注是扶贫的试点项目。
但改变已经随着大模型的出现而发生。
让杨小云感到无聊的,其实就是为训练大模型而做的数据标注工作。
经过简单的培训和考核之后,杨小云被安排进了文字编辑组。她每天的工作就是回答题库中的问题,目的是通过标注者人工书写答案来优化大模型的训练过程。
一个问题的回答步骤经过严格把控。以游戏《原神》为例,如果收到“夜兰的圣遗物是什么?”的问题,杨小云需要把回答拆分成几个段落:首先夜兰是什么?其次圣遗物是什么?最后夜兰的圣遗物配对什么?
在指定的搜索引擎上搜集资料,完成回答的编辑之后,最终以Markdown的形式完成提交。
除了简单易答的问题,杨小云的大多数时间都花在了自己完全不熟悉的专业领域,例如经济专区、法律专区等。
显而易见,这与以往的数据标注工作完全不同。
在大模型出现之前,数据标注的场景通常都是几百人的工厂,一人一台电脑,只有鼠标键盘噼里啪啦的声音。而他们一天8小时的工作时间内,都只做一件简单重复的事情:在不同的图片中框出机动车、非机动车、行人、红绿灯(目标检测);或者划出一段话的主语、谓语、宾语(语义分割)。
这些针对图片视频的拉框和文本的语义分割,都是对已有数据进行处理,数据标注员本身并不用给出“创造性结论”。但针对大模型的数据标注并非如此。数据标注员除了需要对已有数据进行处理之外,还需要对问题进行解答,给出正确的结论。
根据观研天下数据中心2023年发布的《中国数据标注行业现状深度分析与投资趋势研究报告(2023-2030年)》,在ChatGPT发布之前,AI训练数据标注以语音和计算机视觉为主,自然语言处理(NLP)的需求不足15%。
随着ChatGPT聊天机器人成为AIGC的现象级应用,对更偏情绪判断、考验理解能力甚至推理能力等高质量文字标注任务的需求正在越来越多。
“(大模型)项目的复杂度变得比以前高了,对人员的要求也相对不一样了。”星尘数据产品部负责人告诉「甲子光年」,“自动驾驶偏视觉信息的识别标注,更偏体力活的工作,对员工进行一些培训,他们经过上手拉框,熟练快捷键,掌握一些技巧之后,能很快胜任。但是大模型所需要的是一个完整的、结构化的、多元化的、包罗万象的数据体系,需要四层数据来支撑模型的搭建和提升。这些数据涉及预训练、SFT(有监督微调,Supervised Fine-Tuning)、RLHF(基于人类反馈的强化学习,Reinforcement Learning from Human Feedback),私有化部署等等,针对不同行业的需求,我们发布了COSMO大模型数据金字塔解决方案;对于大模型数据标注员来说,标注COSMO的数据不是做选择题,也不是简单的阅读理解、文本编辑,而是让你创造问答,创造内容了。”
云测数据总经理贾宇航将大模型的训练数据划分为基础数据、场景数据和场景数据优化三个阶段。他将这三个阶段类比成学习的过程。
“对于拉框这种基础的数据标注会比较简单,会电脑操作、学一学即会;场景数据是在特定环节做定向研发时所需要的特定领域的数据,需要学习相关领域知识以达到标注要求;到三个阶段,基于投入使用中持续的迭代和优化,技能和领域知识的要求会更加精进。”贾宇航表示。
在这种工作需求之下,越来越多的大模型公司对数据标注员的需求,也从过去的低学历向高学历转变,并且这种需求正越来越多。
在国内主流的求职平台上,已有不少关于大模型的数据标注岗正在招聘。这些岗位要求标注员的学历在本科以上。百度此前曾表示,其位于海口的大模型数据标注基地有数百位数据标注员,本科率已达100%。
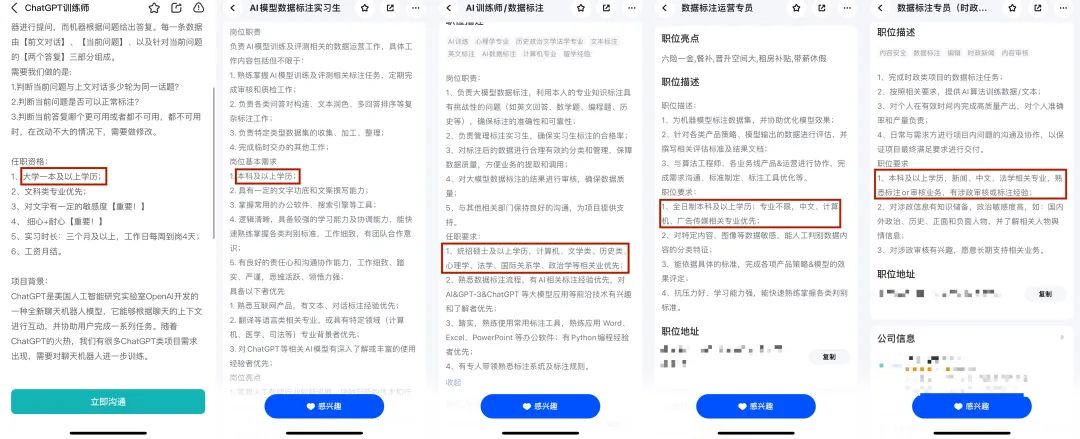
图片来源:BOSS直聘&脉脉
2.苛刻的大模型数据标注
通常来说,训练一个大模型,需要以下3个步骤:
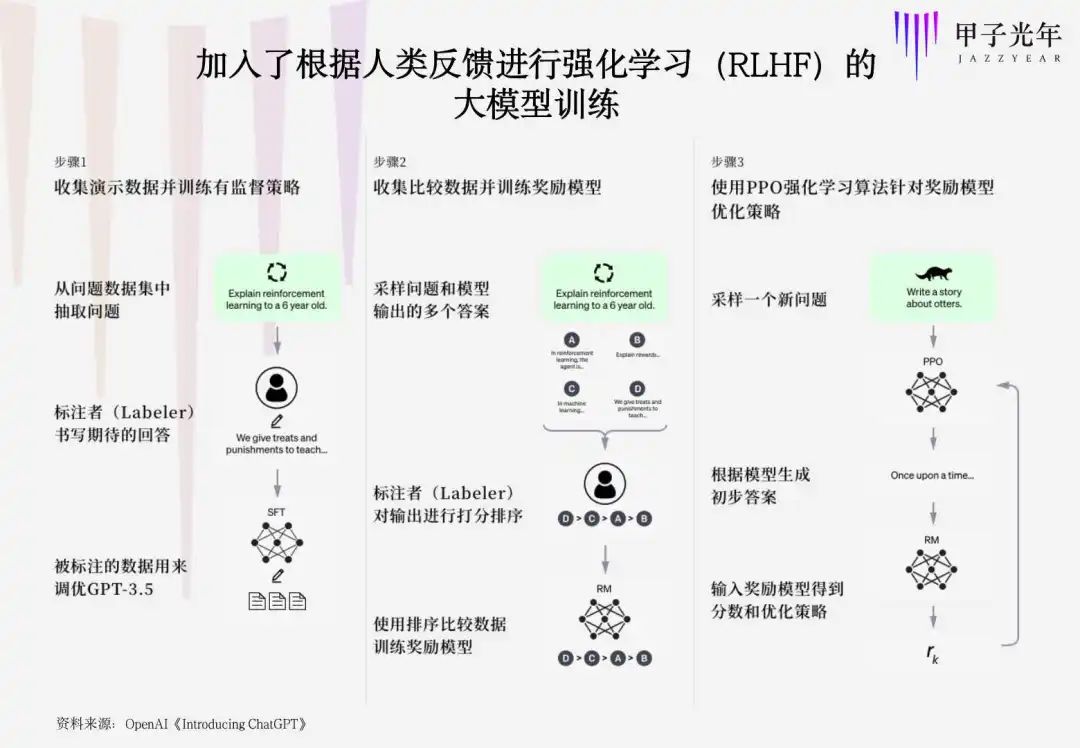
这些重复性的工作背后,实际上是为了实现“根据人类反馈进行强化学习”(Reinforcement Learning from Human Feedback)的技术,GPT-3.5的最大提升便来自于此,其中的关键,是人(Labeler)的参与,也就是这些数据标注员。
从上述RLHF三步骤来看,步骤一与步骤二相对更重要,因为它决定了训练奖励模型所必须的数据质量的高低。而这两个步骤中的数据标注实习生,也被分成了“编辑组”与“排序组”两个核心小组。
编辑组的工作就是回答题库中的问题;而排序组的工作则是给生成的答案(包括模型和人工生成的答案)进行优劣排序。
丁小雨在7月份加入文字编辑。同为英语专业的丁小雨和晨曦一样,期待着一份翻译工作能提高专业水平,但她的工作其实也与英语并不相关。
对比2月份杨小云实习的时候,丁小雨面临的文字编辑组变得更加细分,每个实习生要选择一个垂直方向,例如娱乐、物理、政治等,答案的要求也变得更加详细。
一道古诗文的选择题,不能只解释答案,而要先从题型开始介绍,然后是诗文的翻译以及背景,最后是每个选项正确与否的分析,最重要的是要对标3月14日OpenAI发布的GPT-4。
“要参考它的答案,又不能跟它的答案雷同,还要比它的答案好。”丁小雨很无奈。
而晨曦被安排进的是排序组,每天为问题对应的多个回答进行排序,以确定不同答案的优劣。
排序的结果是需要被明确量化的。她需要从有用性、真实性、相关性、安全性等不同角度对回答进行评分,并且写下原因。这是为了让机器无限接近人类期待的答案。
晨曦发现自己有时候不得不在几个糟糕的回答之间做出选择。而当所有的回答都不好时,她被要求自己写出更好的回答。
编辑组的丁小雨面临的要求更加苛刻。每个回答在合格交付之前将要面临两道审核。第一道来自组长:“做完几道题就要开审核的会,给我们挑毛病,直到改到组长满意为止。”第二道来自于总部,总部审核通过才算结束。
一次,因为格式的错误,丁小雨的大多数回答被判了全错。“可能调一下顺序就可以了,但是他们不在意你是回答的内容错了,还是格式出现问题,直接就是全错。”
更令丁小雨崩溃的是,组长直接表示,如果再错这么多就可能劝退她。
为大模型做数据标注是一件绝对的结果导向的工作。不管在做的过程中付出了多少努力,只要效果不好,之前的一切努力就会被全盘否定。
但问题在于,无论是编辑组的答案输出,还是排序组的答案排序,都是一个非常主观的工作。数据标注实习生们很难把控一个答案到底是好是坏;针对同一个问题,不同实习生往往也会给出不同的答案。
为了解决这一问题,大模型数据标注团队每天必须进行的一项工作就是开“审核会”——在公司内部被称为“拉齐会”,目的就是拉齐答案的标准,拉齐每个人的理解,拉齐所有的建议。
只是,要实现真正的拉齐,是一件颇为费劲的事。这就像高考阅卷一样,不同的人会分到同样的题目,如果评分不一致,就要不断调整直到得出一个统一的分数。
在晨曦的印象里,每天都有两三小时的时间花在会议上。会议开到最后,往往敲定的是最简单粗暴的解决方法,少数服从多数,她形容为“没有价值在创造价值”。
不过,比起大家坐在一起“人为”拉齐答案标准,一个更令人头大的问题是:标准并非人为拉齐之后就可以一劳永逸,而是要不断根据模型输出的反馈进行调整。
每天上班的第一件事,杨小云需要确认当天是否下发了新的标注标准,大到回答的框架,段落的拆分,小到搜索引擎的选择,空格、标点符号等格式。但标准一直在变。一旦发现投喂的数据在机器上不奏效,标准就需要重新制定,全部问题跟着推翻重写。
“这就好像织布一样,是织横纹还是竖纹?是织芝麻扣还是麦子扣?但是不管是什么扣,都只能放进程序里跑,发现跑不出来就要换一种方法。”杨小云向「甲子光年」解释。这个比喻的背后是,如果数据标注给出的答案,在奖励模型的训练过程中可能没有达到预期的效果,就要调整标准。
标准变更,意味着上一次拉齐会结论的失效,标准又要重新拉齐。
“又冗余又高效,每天都在非常高效地说一些废话。”杨小云吐槽。
3.被大厂薅羊毛的高材生
一边是每天开不完的拉齐会,一边是随时可能变更的数据标准。很多像晨曦一样被大厂光鲜亮丽的招牌吸引进来的高材生们,却在一次次内耗中丧失了自己最初的心气,最终选择离开。
这些实习生的共同特点是高学历。招聘要求是本科以上,但许多实习生拥有硕士研究生的文凭。
他们中不少人受过中国乃至世界顶尖大学的教育。杨小云的身边有来自北大、帝国理工的学生,晨曦工位旁的实习生来自南开、电子科大;丁小雨在培训的时候被明确告知,实习生的学历是经过筛选的。“他(面试官)说像我们这样高学历的大学生,学习东西比较快,容易上手”。
管理一帮聪明人从来都不是一件容易的事。因为这些人很容易从不断重复的动作中发现工作的本质,进而质疑这份工作对自己的未来是否真的有价值。
每天早上来到工位,打开显示屏和笔记本,一边用笔记本查看规则,一边在显示屏上编写回答,丁小雨能清晰地感受到详细的规则和流程让自己逐渐失去了思考的空间,把她规训成了一个机器。“没有学到东西,而且也没有精力去学习其他的东西,就慢慢丧失学习的动力和做其他事情的热情。”
丁小雨还在脱敏组待过,但实际工作和“脱敏”这个词没有根本联系,只是使用不同的聊天机器人与企业内测的产品回答相同的问题,并对答案进行对比打分。只干了几天,她又被调到过文字校对组,要做的是修改pdf格式转换成Word格式时出现的错误,主要是错别字和标点符号。在这个她形容为“接近崩溃”的过程中,她每天要完成25页与医疗相关的纠错任务。
在面试过程中,面试官曾问丁小雨能不能接受一份比较枯燥和重复的工作。“我当时回答是能接受。我想所有候选人的回答应该都是能够接受。”因为本科只有一段实习经历,带着积累更多实习和体验大厂的期待,即使抱着怀疑的想法,丁小雨还是选择了入职。
在短短两个月中,丁小雨已经算是同期实习生中坚持到最后的人。她亲眼见到许多实习生踌躇满志地进来,又垂头丧气地离开。
人类学家大卫·格雷伯将“狗屁工作”(bullshit jobs)定义为没有意义或目的的工作,本该被机器自动化淘汰掉的工作,却因为装点门面、讨好上级、填补系统漏洞而继续存在。数据标注就像是狗屁工作的变体,通常认为已经被机器替代,却仍然需要人类完成。
在人工智能热潮到来之际,人们往往会听到这样的期许:AI可以替代人类完成重复性、乏味的工作,从而让人类有更多时间和精力去追求更有创造性、成就感的工作。
但也有可能的是,人工智能像过去节省劳动力的技术一样,如电话和打字机,克服了信息传递和手写的苦恼,但也产生了大量的通讯、文书工作,以至于需要配备新的人工来进行管理,例如前台、文员。AI可能不会替代人类,但会创造出更加乏味、枯燥、孤立的工作。
除了无法获得工作价值认同之外,到手的薪资,恐怕也不能让这帮高材生们实现“价格认同”。
据「甲子光年」了解,这些数据标注实习生的工资并不高。如果位于一线城市的工位,大多数人工智能实习生的工资是150元/天,兼有房补,提供免费食堂;位于二线城市,只剩下100元/天,房补也缩减三分之二,20元的餐补替代免费餐食。
像丁小雨在二线城市的工位实习,因为办公地点处在城市中心,地段繁华,一顿外卖轻轻松松超过20元的餐补标准,基本上都需要用实习工资倒贴。
因为他们大多数只是作为训练大模型的基础标注员,可能被统一安排到和专业毫无相关的岗位,又有可能随时抽调到不同的部门,经过短暂的培训后要求快速上手。
丁小雨形容,他们是一批一批被大厂薅羊毛的实习生。
晨曦明显感受到,她不是唯一感受到期待与实际工作落差的人。“说得直白一点,我觉得这个工作配不上我。有时候聊天我会发现其他实习生可能是985本科,也有海归的硕士,他们的落差也非常非常大。”
杨小云则表达得更为直接:“可能是一个不太恰当的比喻,我妈妈上过高中,她来做这个工作也可以。”
4.“我们其实是流水线的工人”
事实上,招聘高材生做一些低技术含量的工作,给付极低的薪资成本,也是目前大模型数据标注发展初期市场混乱的客观体现。对于数据标注公司来说,在大模型目前的发展阶段,数据标注还没有形成统一的标准,对标注员也没有成型的具体要求。
星尘数据产品部负责人表示:“随着大模型基础能力补齐之后,开始向更垂直、更加复杂能力的发展过程中,任务会逐步产生变化,要求工具和人员随之更新迭代。但是,大模型现在还在早期发展过程,市场需求对标注员的要求也随任务的差异有高有低。相比CV(计算机视觉)项目而言,NLP(自然语言处理)的标注员对理解能力、专业术语、领域知识的要求更高,必须能提供准确、可靠的语料。”
该负责人介绍,大模型对数据标注提出的难题更多体现在顶层设计。对于每个数据标注任务,如何理解客户的应用场景诉求,进行数据选择、数据分布设计、可高效低成本落地执行的pipeline设计等一套解决方案的设计,如何提高平台工具的效率和能力,是更大的挑战。
这其中依赖着垂直领域专家作为高级标注员的参与,将领域专业知识和经验注入解决方案的设计,甚至参与到数据质量检查迭代的过程中。
数据解决方案提供商倍赛科技的运营负责人张子千直言,目前就训练大型模型而言,基础标注员和之前从事框选工作的标注员在工作难度、时薪方面并没有明显的区别。在为客户进行大模型微调并创建垂直领域的解决方案时,最大的难题在于如何构建高质量的数据集,这需要IT、医学和金融等专业领域的标注专家才能解决,这类人才依然稀缺。
OpenAI投入了几十位博士生进行数据标注的指导和审核,而将基础的数据标注外包给了数据标注公司,分散在非洲、印度等低收入地区。真正起作用的是那些高级标注员,只占到很小的比例。
通过对比百度在北京总部和海口数据标注基地招聘的标注员岗位介绍可以看出,同样是为了训练大模型,前者为高级标注员,负责指导、培训和审核,而后者则是基础的数据标注员,两者在薪资水平上千差万别。
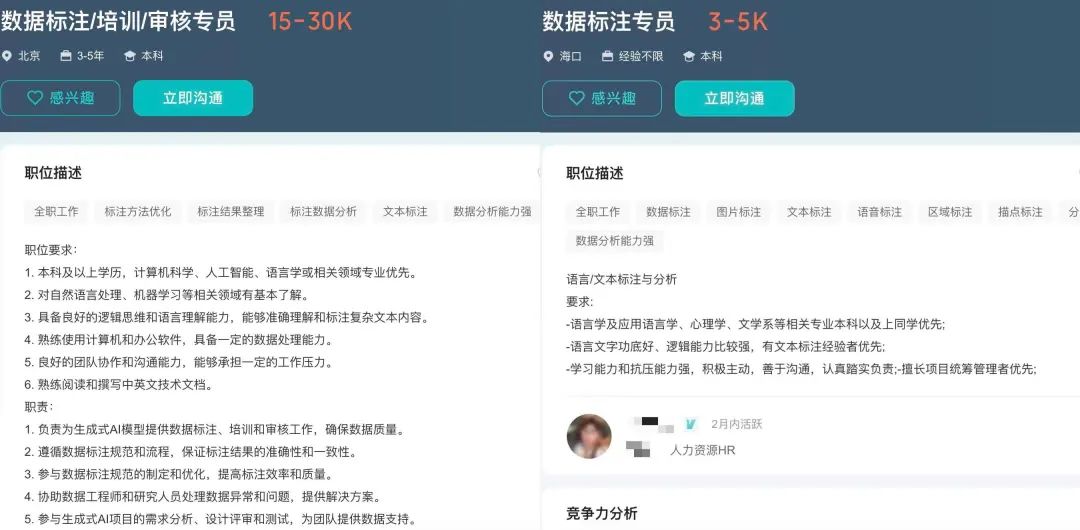
图片来源:BOSS直聘
也就是说,那些更高级别的高级标注员其实才是大模型训练的关键人才,他们的工作更具技术含量、价值更高,同时人力成本也更高。
对比之下,这些来自名校的实习生们,即使是为了训练大模型而来,从现阶段来说,也与过去那些数据标注员在本质上并无差别。
实习生们每天要完成的工作量,都有规定的人效红线。对于杨小云来说,她一天需要标注满32条问题,如果没有达到红线要求,就要汇报原因或者加班把它干完。而完成工作的前提,是不断变换的拉齐会标准,以及不停的资料搜集。
为了最快速度完成模型训练,标注团队面临的是高压式的管理。杨小云所在的小组工作时间禁止说话,闲聊几句的代价可能会新增额外的任务量,完不成工作会在群里被疯狂提醒,甚至生病请假也可能会被正职的加急电话打扰。
此外,为了保证数据不被泄密,数据标注跨组别的交流是明令禁止的。即使不同小组的实习生安排在临近的位置,也不能讨论工作内容。这些实习生们都不知道,在企业内部,数据标注到底有多少细分的组,有多少实习生。一个组可能有10人、40人、50人、60人,每层楼会有上百人。
在高压的人效红线之下,只有遇到违禁的题目能让杨小云短暂“高兴”一下。因为涉及到暴力、色情、血腥的内容要直接去掉,但还可以算到个人的工作条数。“相当于拧到了一个坏的螺丝,你只会很高兴这个螺丝不用你拧了”。早上分工的时候,实习生之间甚至争着领违禁问题。
在杨小云提前离职之后,她经常刷到同期实习生深夜10点,甚至12点还在公司开会的朋友圈。还有实习生给她发语音,带着哭腔,但是因为租了房子没有办法离开,坚持不下去就意味着房租全部打水漂。
5.这里永远不会缺人
但不是没有坚持下来的人。
李竹溪是其中少见的拥有数据标注经验的实习生。她学的是认知语言学,她解释道,语言学与神经结合的方向,观察脑成像,包括建立脑机接口,与人工智能有一定的联系。
在来到这家大厂之前,她就曾在另一家大厂做过大语言模型的数据标注,那还是在ChatGPT发布之前。在李竹溪的印象中,在ChatGPT出圈之后,类似的数据标注实习如雨后春笋一样一下子就冒了出来。
她顺利完成了三个月的实习,即使在她的形容中,这是一份“比较机械、难度不大”的工作。李竹溪描述自己更注重体验,“我不指望这份工作很有趣,去体验一下还是很不错的,既收获了大厂的实习经验,也体验了这里独特的企业文化”。
对来自双非院校的文科生赵硕来说,大厂的人工智能编辑实习岗已经是他上层的选择。
在找暑假实习的时候,他其实更倾向于一个研究所的运营岗位,研究所属于事业单位,更带编制,对于赵硕有很强的吸引力,“当时我特别期待它能给我反馈”。但最终研究所没有选择研一的赵硕,招走了一个年级更高的学生。
还有更“卷”的人。
在赵硕眼中,有些实习生会特别努力,领取更多的任务量,以谋求转正的机会。认真的态度、勤奋的状态会博得正职的青睐,“Leader与他们之间经常有一定的交流,也会给他们一些管理的授权,管理实习生”。
甚至公司每周会评选表现突出的实习生,将他们的照片贴在墙上作为表彰,但是并不一定存在奖金激励,赵硕所在的业务线就没有。
云测数据总经理贾宇航告诉「甲子光年」,数据标注员的晋升主要有两条:一条是专家路线,在掌握特定垂直领域的相关技能之后,初级的标注员可以逐渐成为高级的标注专家;另一条是管理路线,成为项目的管理者。
但赵硕不会选择留下。在读了一年研之后,赵硕很明显地体会到,他对于未来工作的期待降低了。感受到身处大环境的日益变化,观察到本科毕业选择就业的同学的不如意,赵硕之前期待的“高精尖”“不可替代性强”的工作也逐渐被一份安稳的工作替代。作为一名文科生,他焦虑于自己还没有掌握不可替代性强的技能,更希望能找到一份在编制内管理的工作。
闲聊的时候,实习生们会互相感叹自己在做的工作或许很快就会被机器替代,不再需要人工投喂数据。
对于云测数据总经理贾宇航来说,类似的担忧并不存在。随着算法的实际量产,数据闭环能力增强,整体标注数据量和手工数据标注量依然在逐年上升。以往是百分之百人工标注,现在是人工标注、自动标注、人工校验各有一定占比。未来可能自动标注占比会越来越大。不过,虽然人工标注的占比在减小,但伴随人工智能行业的逐步发展数据量日渐增加,人工标注的量仍会持续增加。
在提前离职之后,杨小云找到了一份自己喜欢的游戏策划实习,那里工作氛围轻松,也更有获得感,人工智能编辑对她来说是一段“倒霉”的实习经历。而对于丁小雨来说则是一次祛魅的过程,即使去了曾经很期待的大厂实习,也会面临无数枯燥无味的工作,她觉得这可能是因为自己的能力还不够强或历练机会太少。
但那里也永远不会缺人。
杨小云听说在她走之后,团队从几十个人在一个月内扩充到了几百个。丁小雨发现,每隔10天,就会来一批新的实习生,每批都有二三十人。
“你可能骂骂咧咧地走了,向全世界宣告这个工作多么不好,但还有源源不断的新人进来补充你的空位。”
*应采访对象要求,文中人物晨曦、杨小云、丁小雨、李竹溪、赵硕为化名。
(封面图来源:由Midjourney生成)
END.
原标题:《大模型热潮下的实习生:人均985?却在大厂“打标签”|甲子光年》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

