- +1
RLHF vs RL“AIF,谷歌实证:大模型训练中人类反馈可被AI替代
机器之心报道
编辑:Panda W
众所周知,RLHF 是 ChatGPT 和 Bard 等 LLM 成功路上不可或缺的重要一环,而现在谷歌的一项研究表明可以把 RLHF 中的 H(人类)替换成 AI,而且新提出的根据人工智能反馈的强化学习(RLAIF)在实验中的表现大体上与 RLHF 接近。可以预见,如果这项技术的有效性得到进一步验证,人类离 LLM 的训练流程又会更远一步,同时 AI 训练 AI 的构想也会更接近现实。
根据人类反馈的强化学习(RLHF)是一种对齐语言模型与人类偏好的有效技术,而且其被认为是 ChatGPT 和 Bard 等现代对话语言模型的成功的关键驱动因素之一。通过使用强化学习(RL)进行训练,语言模型可以优化用于复杂的序列级目标 —— 使用传统的监督式微调时,这些目标不是轻易可微的。
在扩展 RLHF 方面,对高质量人类标签的需求是一大障碍;而且人们很自然地会问:生成的标签是否也能得到可媲美的结果?
一些研究表明大型语言模型(LLM)能与人类判断高度对齐 —— 在某些任务上甚至优于人类。
2022 年,Bai et al. 的论文《Constitutional AI: Harmlessness from AI Feedback》最早提出使用 AI 偏好来训练用于强化学习微调的奖励模型,该技术被称为根据人工智能反馈的强化学习(RLAIF)。这项研究表明,通过混合使用人类与 AI 偏好,并组合 Constitutional AI 自我修正技术,可让 LLM 的表现超越使用监督式微调的方法。不过他们的研究并未直接对比使用人类反馈和 AI 反馈时的效果,于是能否使用 RLAIF 适当地替代 RLHF 就仍旧是一个有待解答的问题。
Google Research 决定填补这一空白,凭借强大的实验资源,他们直接比较了 RLAIF 和 RLHF 方法在摘要任务上的表现。

论文:https://arxiv.org/pdf/2309.00267.pdf
给定一段文本和两个候选响应,研究者使用现有的 LLM 为其分配一个偏好标签。然后再基于该 LLM 偏好,使用对比损失训练一个奖励模型(RM)。最后,他们使用该 RM 来提供奖励,通过强化学习方法微调得到一个策略模型。
结果表明,RLAIF 能与 RLHF 媲美,这体现在两个方面:
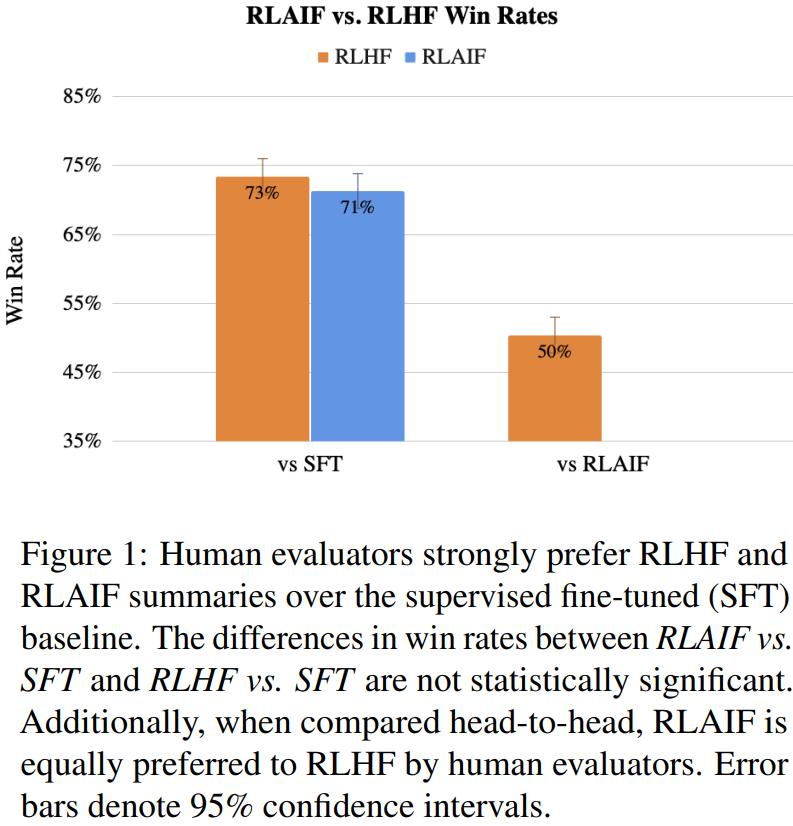
一、谷歌观察到,RLAIF 和 RLHF 策略分别在 71% 和 73% 的时间里比监督式微调(SFT)基准更受人类青睐,而这两个胜率在统计学意义上没有显著差别。
二、当被要求直接比较 RLAIF 与 RLHF 的结果时,人类对两者的偏好大致相同(即 50% 胜率)。这些结果表明 RLAIF 可以替代 RLHF,其不依赖于人类标注,并且具有良好的扩展性。
此外,该团队还研究了能尽可能使 AI 生成的偏好与人类偏好对齐的技术。他们发现,通过 prompt 为 LLM 提供详细的指示并借助思维链推理能提升对齐效果。
他们观察到了出乎意料的现象:少样本上下文学习和自我一致性(采样多个思维链原理并对最终偏好进行平均的过程)都不能提升准确度,甚至会导致准确度下降。
他们还进行了缩放实验,以量化打标签 LLM 的大小与偏好示例数量之间的权衡。
这项研究的主要贡献包括:
基于摘要任务表明 RLAIF 能取得与 RLHF 相当的表现。
比较了多种用于生成 AI 标签的技术,并为 RLAIF 实践者确定了最优设置。
RLAIF 方法
这一节将描述使用 LLM 生成偏好标签的技术、执行强化学习的方法以及评估指标。
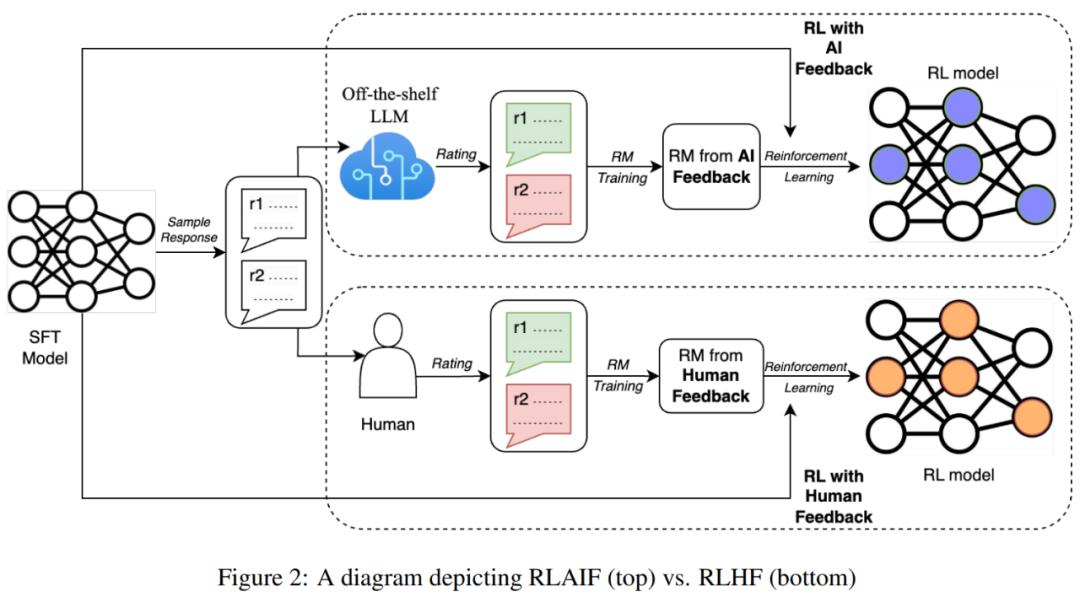
使用 LLM 标记偏好
谷歌在实验中的做法是使用一个现成可用的 LLM 来在成对的候选项中标记偏好。给定一段文本和两个候选摘要,LLM 的任务是评判哪个摘要更好。LLM 的输入的结构如下(表 1 给出了一个示例):

序言 —— 描述当前任务的介绍和指示
少样本示例(可选)—— 一段示例文本、两个摘要、一个思维链原理(如果可用)和一个偏好判断
所要标注的样本 —— 一段文本和一对要标记的摘要
结尾 —— 一段用于提示 LLM 的结束字符串(如 Preferred Summary=)
通过为 LLM 提供输入而得到的偏好结果 1 和 2,可以得到生成 1 和 2 的对数概率,然后计算 softmax,得到偏好分布。
从 LLM 获取偏好标签的方法有很多,比如从模型中解码自由形式的响应并以启发式方法提取偏好(比如输出 =「第一个偏好更好」)或将偏好分布表示成一个单样本表征。但是,谷歌这个团队并未实验这些方法,因为他们的方法已能得到较高的准确度。
对于序言,研究者实验了两种类型:
基本型:就是简单地问:「哪个摘要更好?」
OpenAI 型:模仿了给人类偏好标注者的评级指令,该指令生成了 OpenAI TL;DR 偏好数据集并且包含有关组成优良摘要的内容的详细信息。完整序言见下表。

研究者还实验了上下文学习,即在 prompt 中添加少样本示例,其中的示例是人工选取的以覆盖不同的主题。
解决位置偏见
众所周知,LLM 有位置偏见,也就是候选项在输入中的位置会影响 LLM 给出的评估结果。
为了缓解偏好标注中的位置偏见,这个研究团队采用的做法是为每一对候选项做两次推理 —— 两次中候选项在输入中的位置相互调换。然后再对两次推理的结果做平均,得到最终的偏好分布。
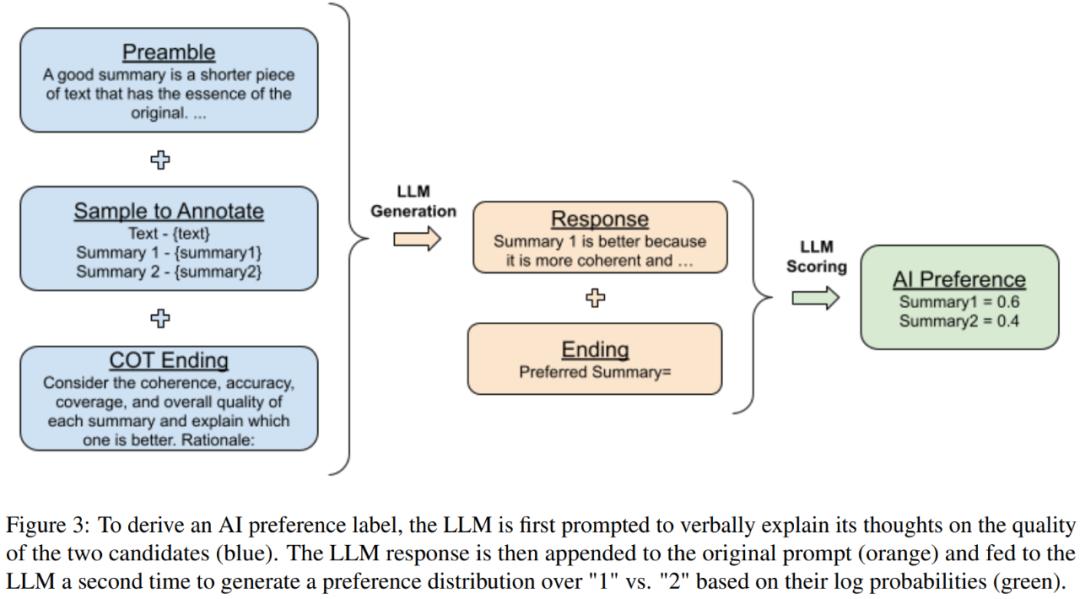
思维链推理
他们也使用了思维链(CoT)推理来提升与人类偏好的对齐程度。为此,他们将结尾的标准 prompt 替换成了「Consider the coherence, accuracy, coverage, and overall quality of each summary and explain which one is better. Rationale:」然后解码 LLM 给出的响应。最后,再将原始 prompt、响应和原始结尾字符串「Preferred Summary=」连接到一起,按照前述的评分流程得到一个偏好分布。图 3 给出了图示说明。
自我一致性
对于思维链 prompt,研究者也实验了自我一致性 —— 这项技术是通过采样多个推理路径并聚合每个路径末尾产生的最终答案来改进思维链推理。研究者使用非零解码温度对多个思想链原理进行采样,然后得到每个思维链的 LLM 偏好分布。然后对结果进行平均,以得到最终的偏好分布。
根据人工智能反馈的强化学习
使用 LLM 标记好偏好之后,就可以用这些数据来训练一个预测偏好的奖励模型(RM)。由于这里的方法是得到软标签(如 preferences_i = [0.6, 0.4] ),因此他们对 RM 生成的奖励分数的 softmax 使用了交叉熵损失。softmax 会将 RM 的下限分数转换成一个概率分布。
在 AI 标签数据集上训练 RM 可以被视为一种模型蒸馏,尤其是因为打标签的 AI 往往比 RM 强大得多。另一种方法是不用 RM,而是直接把 AI 反馈用作强化学习的奖励信号,不过这种方法计算成本要高得多,因为打标签的 AI 比 RM 大。
使用训练得到的 RM 就能执行强化学习了,这里研究者使用了一种针对语言建模领域修改过的 Advantage Actor Critic (A2C) 算法。
评估
这项研究使用了三个评估指标:打标签 AI 对齐度、配对准确度和胜率。
打标签 AI 对齐度衡量的是 AI 标注的偏好与人类偏好对齐的程度。对于各个示例,其计算方式是将软性的 AI 标记的偏好转换成二元表征(如 preferences_i = [0.6, 0.4] → [1, 0]);如果 AI 给出的标签与目标人类偏好一致,则分配 1,否则分配 0。其可以表示为:
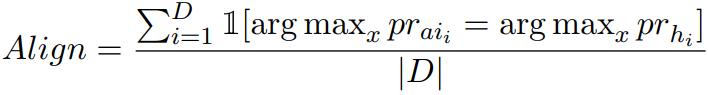
其中 p_ai 和 p_h 分别是 AI 和人类偏好的二元表征,x 是索引,D 是数据集。
配对准确度衡量的是训练好的奖励模型相对于一个保留的人类偏好集的准确度如何。给定共享的上下文和一对候选响应,如果 RM 给人类偏好的候选项的分数高于人类不偏好的候选项,那么配对准确度为 1。否则其值为 0。将多个示例的该值平均之后,可以衡量 RM 的总准确度。
胜率则是通过人类更喜欢两个策略中哪个策略来端到端地评估策略的质量。给定一个输入和两个生成结果,让人类标注者标记自己更喜欢的那一个。在所有实例中,相比于来自策略 B 的结果,人类标注者更偏好来自策略 A 的结果的百分比称为「A 对 B 的胜率」。
实验
结果表明 RLAIF 与 RLHF 的表现相当,如图 1 所示。相比于基础 SFT 策略,人类标注者在 71% 的情况下都更偏爱 RLAIF。
研究者实验了三种类型的 prompt 设计方案 —— 序言具体指定、思维链推理、和少样本上下文学习,结果见表 2。
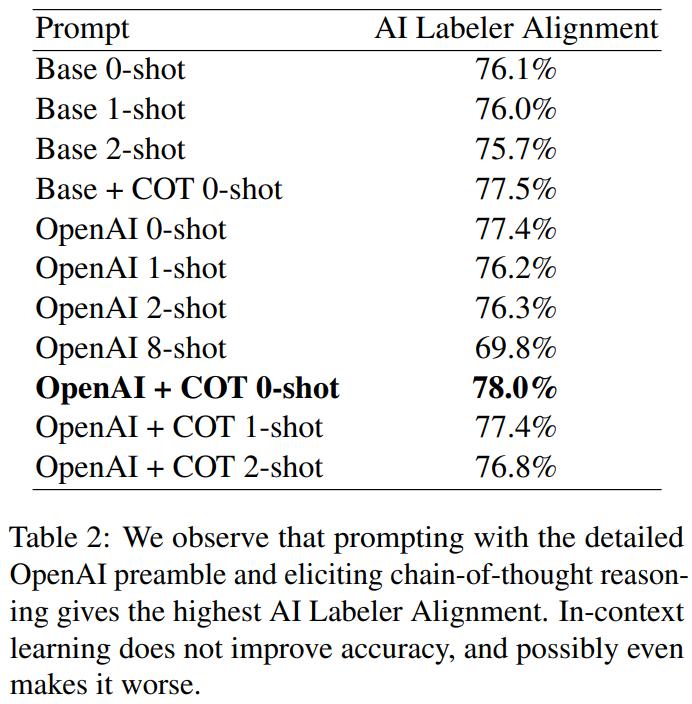
总体而言,研究者观察到,最优配置为:采用详细的序言、思维链推理、不采用上下文学习(OpenAI + COT 0-shot)。这一组合的打标签 AI 对齐度为 78.0%,比使用最基础的 prompt 时高 1.9%。
在自我一致性方面,研究者实验了 4 和 16 个样本的情况,而解码温度设置为 1。
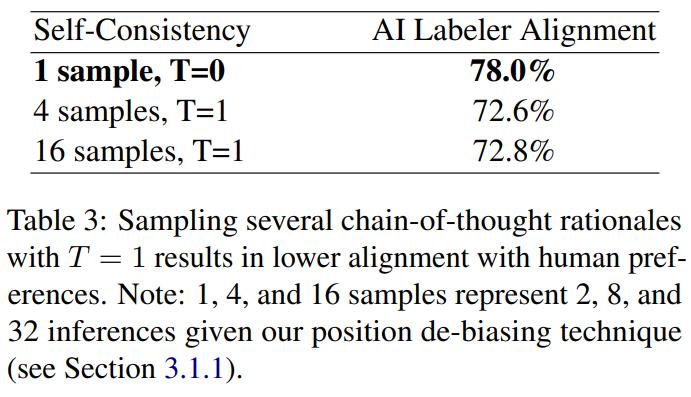
结果发现,相比于不使用自我一致性,这两种情况下对齐度都下降了 5% 以上。研究者以人工方式检查了思维链原理,但未能揭示出自我一致性导致准确度更低的常见模式。
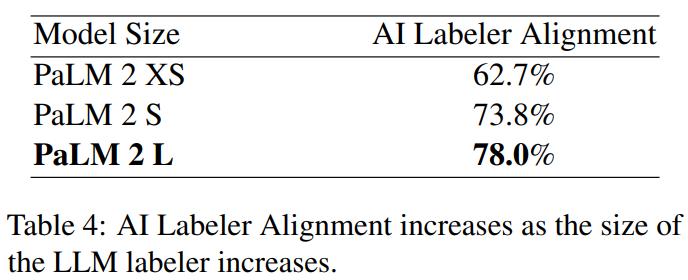
他们也实验了不同模型大小的标注偏好,并观察到对齐度与模型大小之间存在紧密关联。
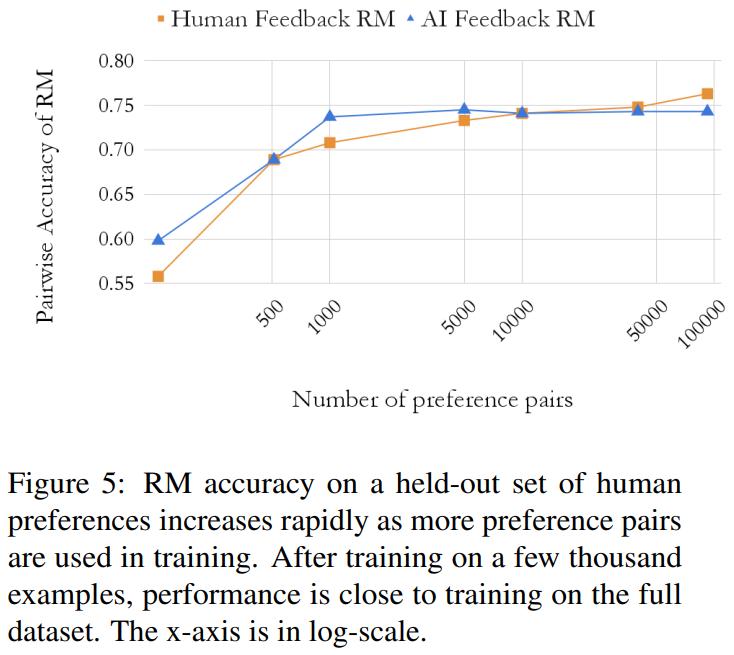
研究者也通过实验观察了奖励模型(RM)准确度随训练样本数量的变化模式。结果如图 5 所示。
定性分析
为了更好地理解 RLAIF 和 RLHF 孰优孰劣,研究者让人类评估了这两个策略生成的摘要。很多时候,这两个策略得到的摘要很相近,这也反映在它们相近的胜率上。但是,研究者也找到了两种它们会出现差异的模式。
其中一个模式是 RLAIF 似乎比 RLHF 更不容易出现幻觉。RLHF 中的幻觉往往看似合理,但又与原文本不一致。

另一个模式是:相比于 RLHF,RLAIF 有时候会生成更不连贯和更不符合语法的摘要。
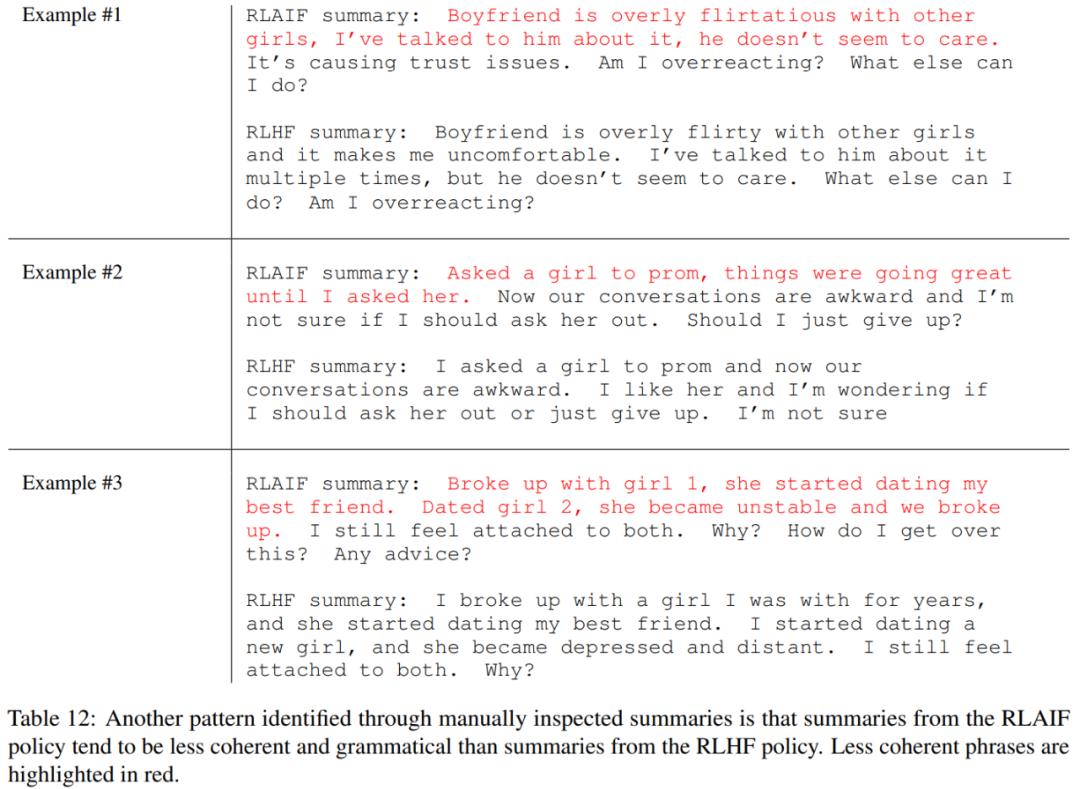
总体而言,尽管这两个策略各自有一定的倾向性,但却能产生相当接近的高质量摘要。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《RLHF vs RL「AI」F,谷歌实证:大模型训练中人类反馈可被AI替代》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

