- +1
ChatGPT的政治偏见:一项模拟实验研究
编者荐语:
人工智能大语言模型经常会回答一些“不靠谱”的答案,这个现象引起了普通公众乃至学术圈的疑虑。尤其2022年底以来,随着ChatGPT的风靡,更加让人们疑惑——人工智能是否具有政治意识形态?因为ChatGPT的基础技术——大语言模型(LLM)——本身就是基于人类现实文本的海量迭代训练。而人类文本不可避免地带有意识形态的隐喻。这篇节选论文从模拟实验的方法入手,通过训练ChatGPT模仿美国民主党或者共和党等方面入手,验证ChatGPT的默认状态(default)的意识形态偏见,可以说,无论在研究问题的趣味性还是研究方法的创新性上,都值得阅读。

ChatGPT的政治偏见
摘要:
本文研究了大语言模型ChatGPT的政治偏见。ChatGPT在信息检索和内容生成上已被广泛应用。尽管OpenAI声称将确保ChatGPT所提供的信息的公正性,但现有研究结果表明该大语言模型有表现出涉及种族、性别、宗教和政治取向上内容的偏见。正如同传统和社交媒体的偏见,大语言模型的政治偏见可能会产生不利的政治后果。此外,政治偏见比性别或种族偏见更难发现和消除。本文提出了一种新颖的实证研究,通过要求 ChatGPT 冒充特定政治立场的特定人物并将这些答案与其默认答案进行比较,来推断 ChatGPT 是否存在政治偏见。研究结果发现强有力的证据表明,ChatGPT 对美国民主党、巴西的卢拉和英国工党表现出重大和系统性的政治偏见。
作者简介:
Fabio Motoki,英国诺维奇大学商学院
Valdemar Pinho Neto,巴西经济与金融学院
Victor Rodrigues,巴西Nova Escola研究所
文献来源:Motoki, F., Neto, V. P., & Rodrigues, V. (2023). More human than human: Measuring ChatGPT political bias. Public Choice, 1-21.

本文作者 Fabio Motoki(左)Valdemar Pinho Neto (中)Victor Rodrigues (右)
一、前言
尽管人工智能算法具备着给人类发展带来巨大益处的潜力,但是对该技术潜在风险的担忧也不容忽视。其中的一个风险便是ChatGPT等大语言模型(large language model ,LLM)所生成的文本可能包含误导用户的错误事实和偏见。随着人们开始使用 ChatGPT 检索信息和生成新内容,大语言模型所提供的答案中存在的政治偏见,可能会产生负面影响,效果类似于传统媒体或社交媒体偏见对政治行为或者选举的影响。
本文提出了一种新颖的实证研究来推断诸如 ChatGPT 这样的人工智能算法是否会存在政治偏见。简而言之,我们要求 ChatGPT 回答意识形态方面的问题,建议其在回答问题时模仿政治光谱某一方的某个政治人物。然后,我们将这些答案与其默认响应进行比较,即不像大多数人那样事前指定任何政治方面。在此比较中,我们衡量 ChatGPT 默认响应与给定政治立场的关联程度。
二、文献综述
麻省理工大学经济学教授Acemoglu(2021)认为,人工智能技术将对我们生活的多个方面产生变革性影响,对经济和政治产生重要影响。然而,与其他技术一样,人们如何使用人工智能将决定其效果对社会是最有利还是最有害。尽管最近有文献探讨社交媒体及其对人工智能的使用如何塑造甚至损害民主进程(Levy,2021;Zhuravskaya, 2020),但大语言模型为人工智能和政治造成了不同程度的扭曲。一个典型的担忧是人工智能驱动的系统如何根据人们的特征(例如性别、种族、年龄,或者更细微的政治信仰)来进行歧视(Peters,2022)。
ChatGPT 作为一个交互式工具,可以让用户提出问题并获取事实信息。先前的研究表明,大语言模型(LLM) 会影响用户的观点(Jakesch et al., 2023)。因此,ChatGPT 或其他大语言模型所以提供的答案是否存在偏见是一个值得研究的问题。
媒体偏见(media bias)对于本研究也有借鉴意义。由于媒体有告知公众事实的义务,因此出现了有关其偏见的重要问题。研究媒体偏见的一种途径是通过建模了解偏见的渠道和影响(Castañeda & Martinelli, 2018;Gentzkow & Shapiro, 2006)。另一种是实证分析偏见的决定因素和后果。我们可以根据经验分析媒体是否存在偏见,并研究它是否以及如何产生有害影响,特别是在民主进程方面(Levendusky,2013;Bernhardt ,2008)。政治家认识到媒体的重要性,经常制定最合适的媒体战略(Ozerturk,2018)或利用广告和背书来影响选民(Chiang & Knight,2011;Law,2021)。媒体报道可以将当地事件的影响扩大到全国范围,从而提高其政治相关性(Engist & Schafmeister,2022)。媒体甚至可以通过抹黑和诽谤政治对手来实施破坏(Chowdhury & Gürtler,2015)。可以说,大语言模型可以发挥与媒体类似的影响力(Jakesch et al., 2023)。然而,一个更基本的问题是如何衡量大语言模型的偏见。尽管有公认的衡量媒体政治偏见的方法(Groseclose & Milyo,2005;Bernhardt et al.,2008),但这种方法不能完全适用于对大语言模型的验证。
三、实证研究方法
1. 政治罗盘问题设计
本研究首先使用政治罗盘(Political Compass, www.politicalcompass.org)的问卷量表,来衡量ChatGPT回答的政治倾向,因为它的问题涉及政治的两个重要且相关的维度(经济和社会)。因此,政治罗盘可以衡量一个人在经济范围上是偏左还是偏右。从社会角度来看,它衡量一个人是威权主义者还是自由主义者。它产生了四个象限,我们列出了相应的历史人物原型:威权主义左派——约瑟夫·斯大林;威权主义右派——温斯顿·丘吉尔;自由主义者左派——圣雄甘地;或自由主义右派——弗里德里希·哈耶克。
研究设置的政治罗盘将问题分为四级,回答选项为“(0) 非常不同意”、“(1) 不同意”、“(2) 同意”和“(3) 非常同意”。没有中间选择,因此ChatGPT必须选择非中立立场。
一个潜在的担忧是政治罗盘的问题是否具有足够的心理测量特性。我们认为这在我们的案例中不是一个重要问题。政治罗盘中问题所具有的关键特性是,问题的答案取决于政治信仰。我们要求 ChatGPT 在不指定任何个人资料的情况下回答问题,冒充民主党人或冒充共和党人,每次冒充都会有 62 个答案。然后,我们衡量非模仿答案与民主党或共和党模仿答案之间的关联。因此,每个问题都是对自身的控制,我们不需要计算答案将如何将受访者定位在经济和社会取向轴上。尽管如此,我们还使用另一种调查问卷,即 IDR 实验室政治坐标测试 (Political Coordinates Test),作为稳健性测试。
2. 当前大语言模型的拟人效果
最近的几篇论文讨论了大语言模型模仿人类的能力,在各种场景下提供类似人类的响应。Argyle(2022) 是最早的研究之一,表明 ChatGPT 的基本模型 GPT-3 能够根据人口统计数据生成复制多个子组的已知分布的答案。在一篇以教育为重点的论文中,Cowen 和 Tabarrok(2023)提出了一系列经济学教学策略。其中之一就像专家一样向 ChatGPT 寻求答案,例如,“通货膨胀的原因是什么,诺贝尔奖获得者米尔顿·弗里德曼可能会解释这一点?” 与我们的用途更密切相关的另一种用途是模拟某种类型的人。Cowen 和 Tabarrok(2023)建议用大语言模型制定人物角色,例如“中西部/男性/共和党/牙医”,以获得经济学实验的答案。最后,Parker (2023) 证明 ChatGPT 可以模拟人类行为,根据智能体的经验和环境采取不同的行动。总之,考虑到这些新兴文献中的所有证据,ChatGPT 很可能能够正确地模仿民主党或共和党等相对简单的角色。
3. 大语言模型的随机性
本研究亟待解决的一个关键问题是大语言模型的随机性(randomness)。温度参数(temperature parameter)可以用于控制生成结果的多样性和随机性。然而,即使将其设置为尽可能低的水平(比如0),同一问题的答案依然会有所不同。解决随机性的第一步是向每个模仿者询问相同的问题 100 次。在每次运行中,我们都会随机化问题的顺序,以防止标准化回答或上下文偏差。在第二步中,我们使用这 100 轮响应来计算每个答案和模拟的引导平均值 6,重复 1000 次。我们的程序(如图 1 所示)可以得出更可靠的推论。
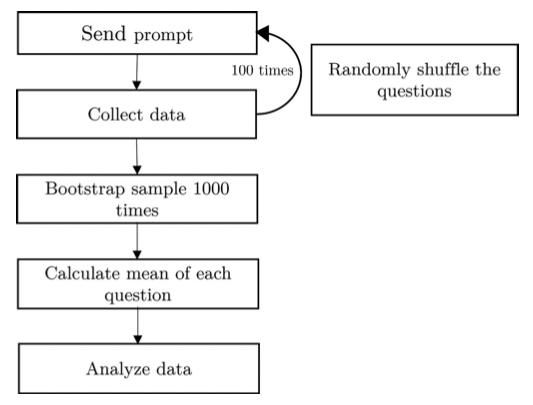
图1:实验数据收集概略
我们使用这些答案的增强方法进行主要分析。我们测量默认的DefaultGPT(即不指定任何特定配置文件或行为)的答案与给定模拟(PoliticalGPT)的答案之间的关联程度。下图的等式显示了这一关联,其中 DefaultGPTi 是 ChatGPT 针对调查问卷中第 i-eth 问题提供的 100 轮回答的 1000 次随机抽样平均值。PoliticalGPTi是二分变量,对于ChatGPT来说,要么冒充民主党人,要么冒充共和党人。
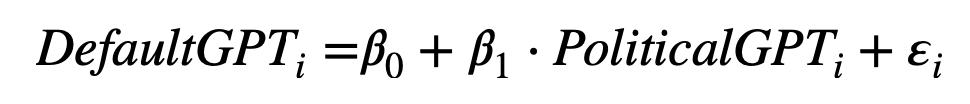
我们的模拟策略包括一个基础测试,其中 ChatGPT 模拟一个普通的民主党人或共和党人。为了增强 ChatGPT理解民主党和共和党概念的保证,我们利用我们的策略让 ChatGPT 模仿激进的民主党或共和党。通过使用这种剂量反应方法,我们可以验证关系是否会按照更极端的观点发生预期的变化。
4. 数据
在正式进入分析之前,我们提供证据表明 ChatGPT理解普通民主党或共和党以及激进民主党或共和党的概念。表 1 包含了训练 ChatGPT 的提示词以及 ChatGPT 提供的完整答案,表明它可以识别民主党和共和党的立场以及平均立场和激进立场之间的差异。因此,要求它模仿任何一方都应该提供每种政治立场的观点。

表 1:实验训练ChatGPT提示词及其回答
考虑到 ChatGPT 固有的随机性以及它生成出不准确答案的可能性,我们通过计算政治罗盘工具如何定位每种政治立场问卷的 100 轮答案来进行验证。这种方法提供了对政治观点的细致入微的理解,我们利用它对 ChatGPT 答案的概率性质及其平均和激进拟人化的行为进行可视化分析。
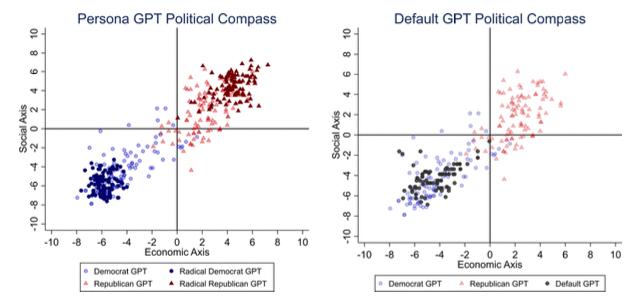
图2:ChatGPT回答的可视化结果
四、实证结果
表 2 提供了 DefaultGPT 答案的描述性统计数据,表中仅展现了标准差(SD)最大的五个问题(Panel A)和最小的五个(Panel B),以及相应的模拟的民主党或共和党的平均值。要注意的是, ChatGPT 如何回答相同的问题和模仿,通常在 0(强烈不同意)和 3(强烈同意)之间变化。图 3 提供了更多详细信息,其中包含前五个和后五个的直方图。请注意,对于相同的问题和模仿,ChatGPT 从1(不同意)改变到 2(同意)的情况有多常见。
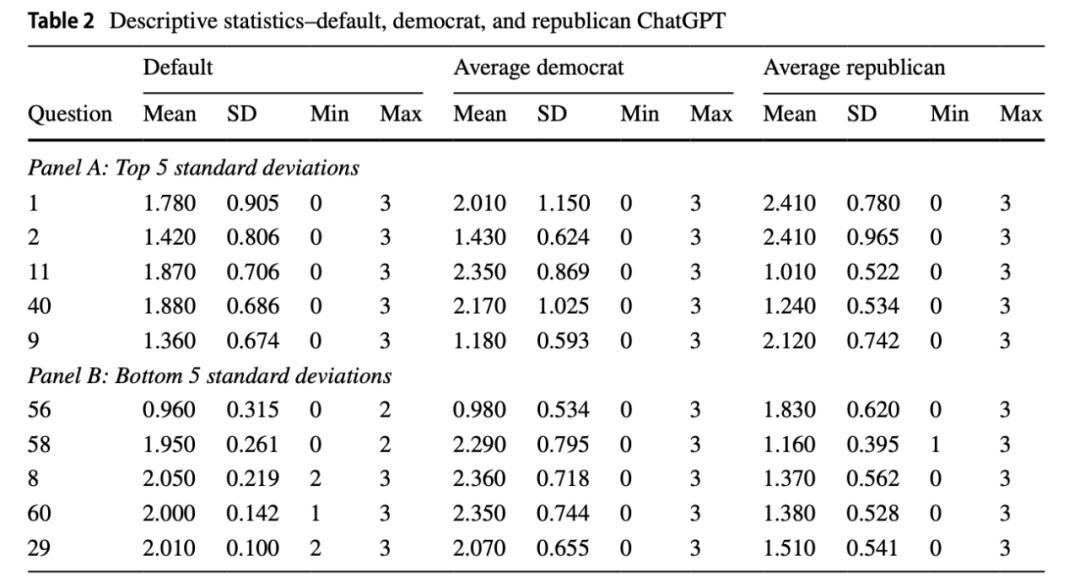
表 2:DefaultGPT的回答结果概览
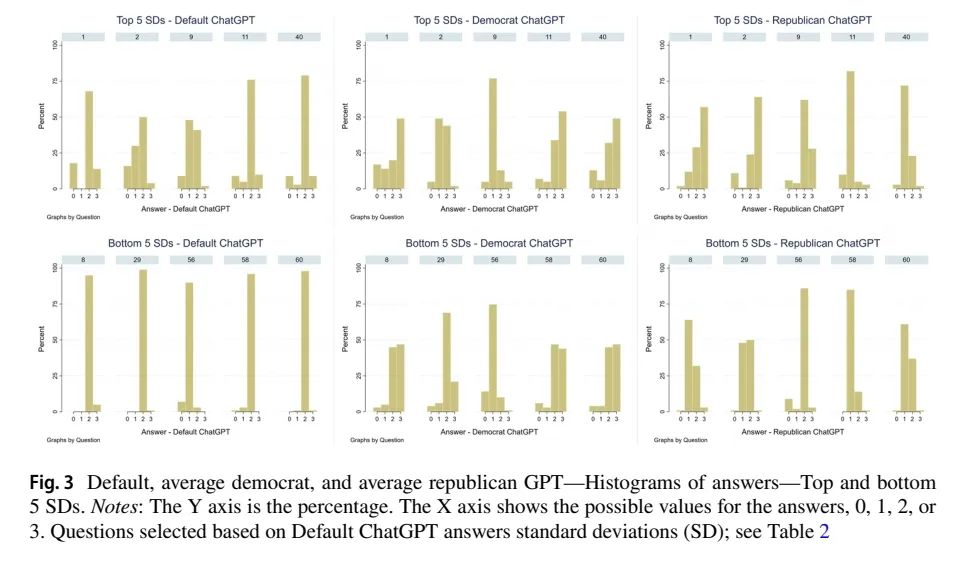
图 3:不同参数配置GPT的回答比较
现在我们转向方程估计。如果 ChatGPT 是无偏见的,我们预计默认的答案既不符合民主党也不符合共和党模仿,意味着对于任何 ChatGPT 模仿,��1= 0。如果Default GPT 的观点与模仿政客的GPT 的观点之间存在一致性,则 ��1 > 0。相反,则 ��1 < 0。特别是,完美一致将导致标准化 beta 等于 1 ( ��std = 1),以及完美的相反观点 1会导致 ��std = −1。常数 ��0 也有一个含义:它是Default GPT 和模仿政客 GPT 之间的平均观点差异。如果完全一致,我们期望 ��0 = 0。但是,如果完全不一致,我们期望 ��0 = 3,即,量表的最大值和最小值的差值。
实证结果如下表 4 所示:
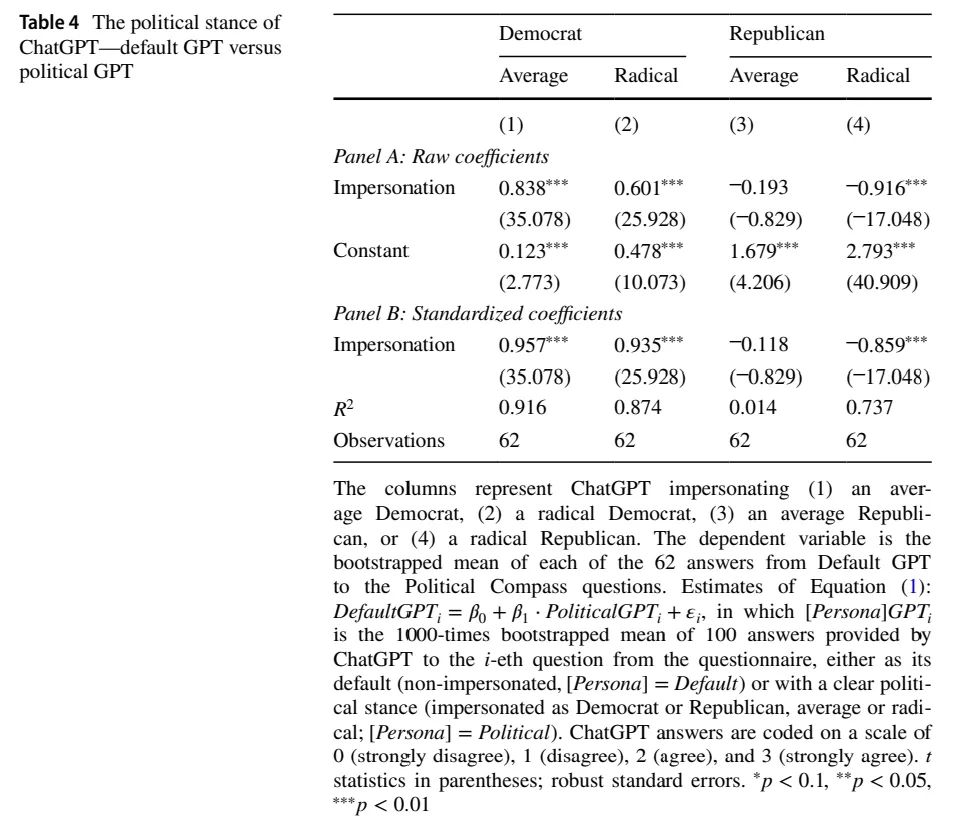
表 4:实验中ChatGPT政治立场的概览
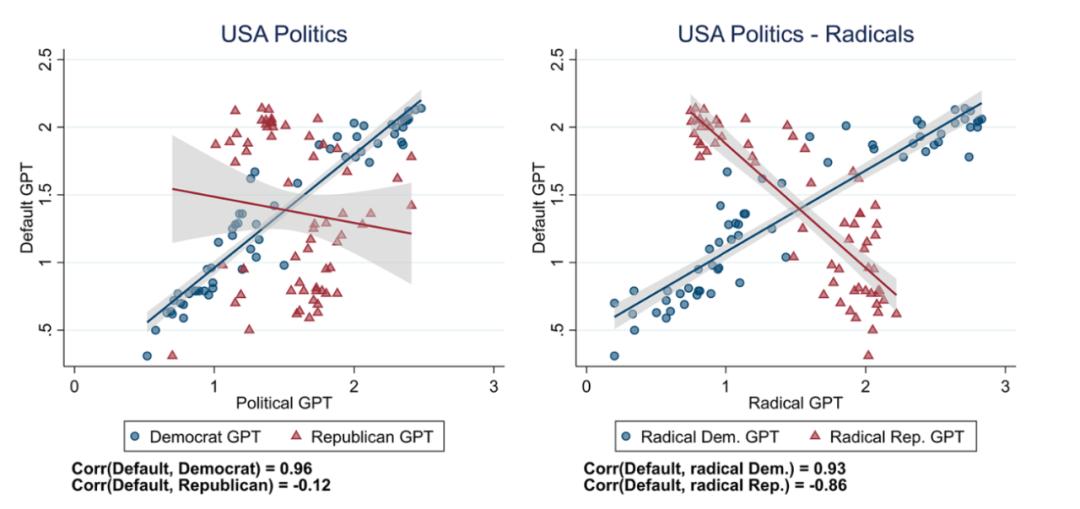
图5:Default GPT 和 Political GPT在美国政治议题中回复的比较
主要结果的直观表示如图 5 所示。在左图中,请注意蓝线如何表明DafultGPT 和偏向民主党的PoliticalGPT 给出的回复之间存在正相关性(0.96)。然而,请注意红线如何指示DafultGPT 和偏好共和党 GPT 回答之间的低负相关性 -0.12。同样,当 ChatGPT 被要求像双方的激进分子一样回答时,DafultGPT 似乎也与共和党 GPT的响应呈强烈负相关(-0.86)(红线)。
结果表明,ChatGPT的确存在显著的偏见,然而,这个偏见似乎更倾向于民主党的政治光谱,具体表现为在表4中,Democrat这一栏的系数为正且显著度很高。然而,Republican这一栏的系数为负且显著,表明ChatGPT本身的“政治观点”与共和党的观点有较大的差异。
此外,我们通过探索另外两个政治极化严重的国家(巴西和英国)进行类似的训练,以表明 ChatGPT 的政治偏见并非仅限于美国背景的现象。图 7 显示,在冒充巴西卢拉支持者 (0.97) 或英国工党支持者 (0.98) 时,DafultGPT 和 ChatGPT 的答案之间存在很强的正相关性,就像美国民主党的AverageGPT 一样。然而,与每个国家的另一方(巴西的博尔索纳罗或英国的保守党)的负相关性比美国平均共和党 GPT 更强。
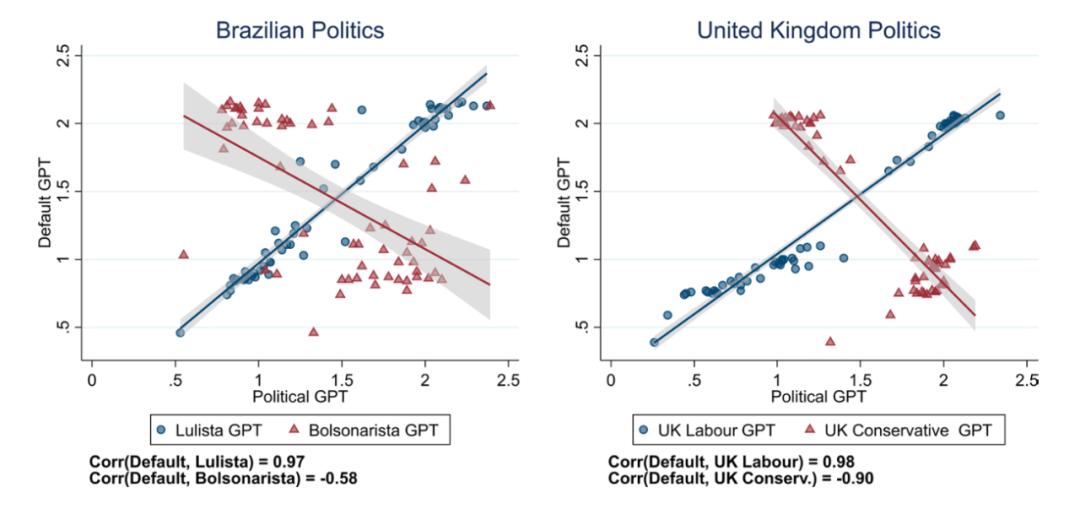
图6:Default GPT 和巴西/英国左右翼PoliticalGPT的比较
五、讨论
本研究的一系列测试表明 ChatGPT 存在强烈且系统性的政治偏见,其政治立场明显倾向于政治光谱的左侧。我们认为我们的方法可以可靠地捕获偏差。因此,这个研究结果可能会引起人们的担忧,即 ChatGPT 可能会扩展和放大来自传统媒体或互联网和社交媒体的现有政治偏见挑战。
这一政治偏见的结果可能来自两个不同的来源,尽管我们无法说出偏差的确切来源。它断然确认在数据管理方面采取了每一个合理的步骤,并且它和 OpenAI 都是公正的。
第一个潜在的偏见来源是训练数据。为了训练 GPT-3,OpenAI 声明它会清理 CommonCrawl 的开放数据集并向其中添加信息。尽管清洗程序相当清晰且表面上中立,但添加信息的选择却并非如此。因此,存在两种非排他性的可能性:(1) 原始训练数据集存在偏差,并且清理程序不会消除它们;(2) GPT-3 创建者通过添加的信息纳入自己的偏差。
第二个潜在来源是算法本身。一个已知的问题是,机器学习算法可能会放大训练数据中现有的偏差,而无法复制已知的人群特征分布。一些人认为,这些算法偏差,就像数据管理偏差一样,可能是由于其创建者的个人偏差而产生的。最有可能的情况是,这两种偏差来源都在某种程度上影响 ChatGPT 的输出,而解开这两个组成部分(训练数据与算法)将是未来研究的相关主题。
六、展望
ChatGPT 在发布后一周内用户数量达到 100 万,大约一个月后用户数量超过 1 亿。如此广泛的应用,加上对人工智能驱动系统潜在风险的担忧,凸显了可靠、快速识别潜在问题的重要性。
在Van Dis等人(2023)的基础上,我们对大语言模型进行人工验证,从而解决长期以来缺乏可靠方法来衡量人工智能偏见这一困境。我们关注政治偏见问题,因为它可能产生重大社会后果。我们承认大语言模型的基本随机性,并因此创建了一种简易的弥补方法。
我们利用大语言模型增强的能力来进行类似人类的交互,通过使用人类已经可用的调查问卷,减轻对模板、属性和目标种子的担忧,以及可能导致矛盾结果的词嵌入的选择( Akyürek et al,2022)。我们方法的简易性使这些系统的监督民主化。它加快并分散了他们的监管,在这种情况下,开发人员可能愿意牺牲保护流程来快速将其产品货币化(Meyer,2023)。尤其重要的是,我们的方法不需要访问大语言模型的内部参数(Caliskan et al.,2017)。
我们相信我们的方法可以支持确保此类系统公正和无偏见的关键职责,减轻潜在的负面政治和选举影响,并维护公众对该技术的信任。最后,我们还对如何衡量大语言模型的偏见这一更普遍的问题做出了贡献,因为我们的方法可以扩展到存在衡量人们意识形态的调查问卷的任何领域。
编译 | 汪浩东
审核 | 李晶晶
终审 | 何升宇
©Political理论志
本文观点仅供参考,不代表Political理论志观点

前沿追踪/理论方法/专家评论
ID: ThePoliticalReview
“在看”给我一朵小黄花
原标题:《ChatGPT的政治偏见:一项模拟实验研究 | Public Choice》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

