- +1
AI自主智能体大盘点,构建、应用、评估全覆盖,人大高瓴文继荣等32页综述
机器之心报道
编辑:杜伟、陈萍
本文全面介绍了基于大语言模型(LLM)的智能体的构建、潜在应用和评估,为全面了解该领域的发展以及启发未来的研究具有重要意义。
在当今的 AI 时代,自主智能体被认为是通向通用人工智能(AGI)的一条有前途的道路。所谓自主智能体,即能够通过自主规划和指令来完成任务。在早期的开发范式中,决定智能体行动的策略功能是以启发式为主的,并在环境交互中逐步得到完善。
不过,在不受约束的开放域环境中,自主智能体的行动往往很难企及人类水平的熟练程度。
随着近年来大语言模型(LLM)取得了巨大成功,并展现出了实现类人智能的潜力。因而得益于强大的能力,LLM 越来越多地被用作创建自主智能体的核心协调者,并先后出现花样繁多的 AI 智能体。这些智能体通过模仿类人的决策过程,为更复杂和适应性更强的 AI 系统提供了一条可行性路径。
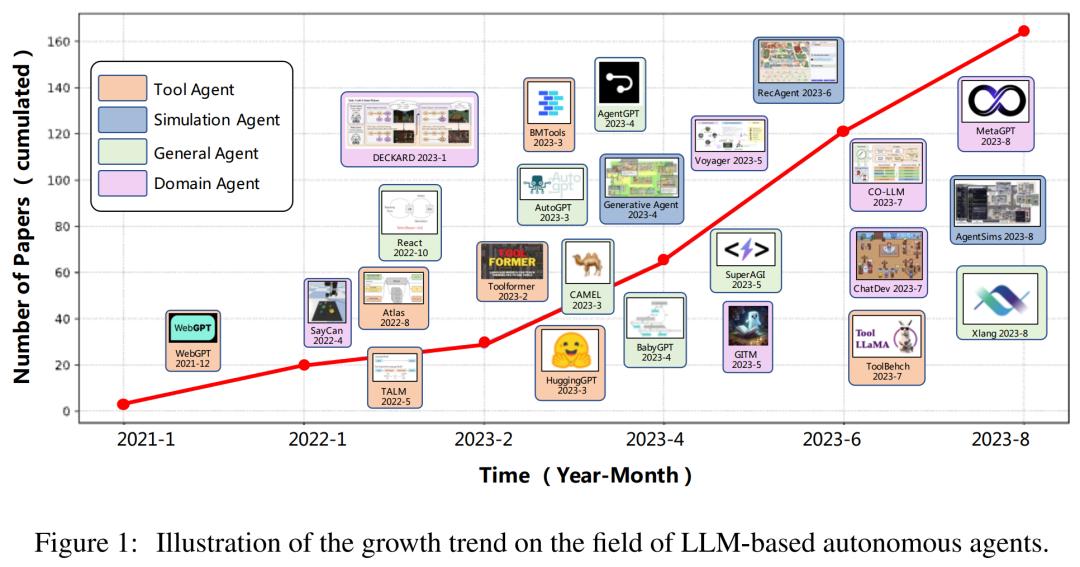
基于 LLM 的自主智能体一览,包括工具智能体、模拟智能体、通用智能体和领域智能体。
在现阶段,对已经出现的基于 LLM 的自主智能体进行整体分析非常重要,并对全面了解该领域的发展现状以及启发未来的研究具有重要意义。
本文中,来自中国人民大学高瓴人工智能学院的研究者对基于 LLM 的自主智能体展开了全面调研,并着眼于它们的构建、应用和评估三个方面。

论文地址:https://arxiv.org/pdf/2308.11432.pdf
对于智能体的构建,他们提出了一个由四部分组成的统一框架,分别是表示智能体属性的配置模块、存储历史信息的记忆模块、制定未来行动策略的规划模块和执行规划决定的行动模块。在介绍了典型的智能体模块之后,研究者还总结了常用的微调策略,通过这些策略来增强智能体对不同应用场景的适应性。
接下来研究者概述了自主智能体的潜在应用,探讨它们如何对社会科学、自然科学和工程学领域产生增益。最后讨论了自主智能体的评估方法,包括主观和客观评估策略。下图为文章整体架构。
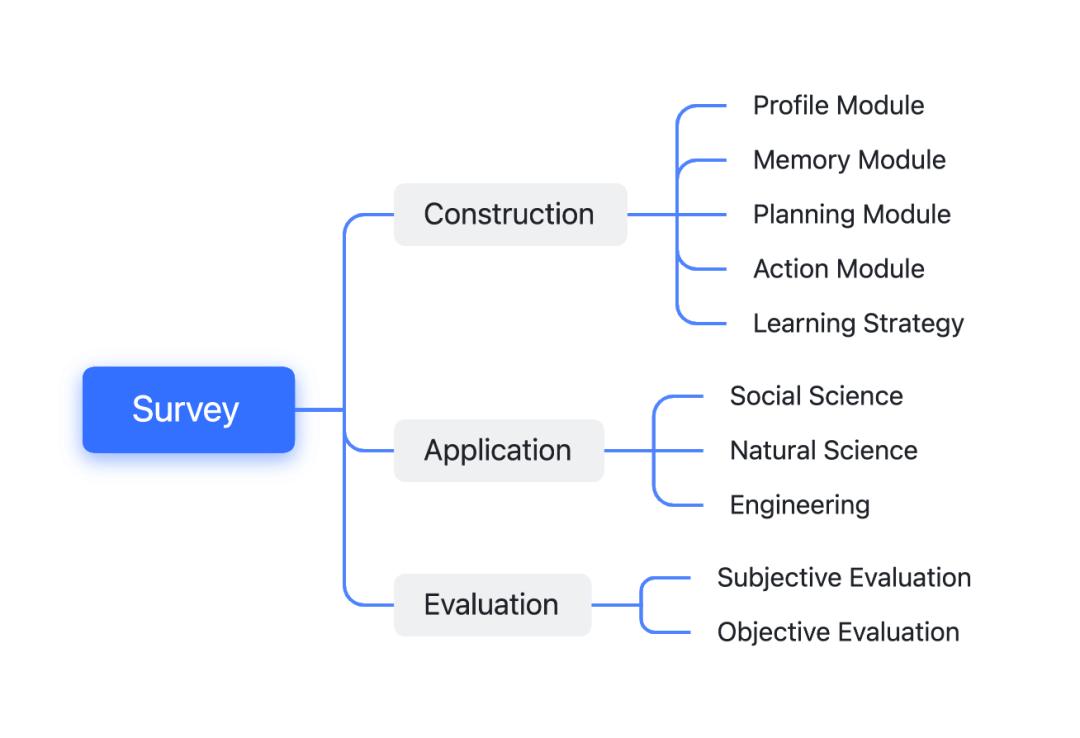
图源:https://github.com/Paitesanshi/LLM-Agent-Survey
基于 LLM 的自主智能体构建
为了让基于 LLM 的自主智能体更加高效,有两个方面需要考虑:首先是应该设计怎样的架构使得智能体能更好的利用 LLM;其次是如何有效地学习参数。
智能体架构设计:本文提出了一个统一的框架来总结之前研究中提出的架构,整体结构如图 2 所示,它由分析(profiling)模块、记忆模块、规划模块以及动作模块组成。
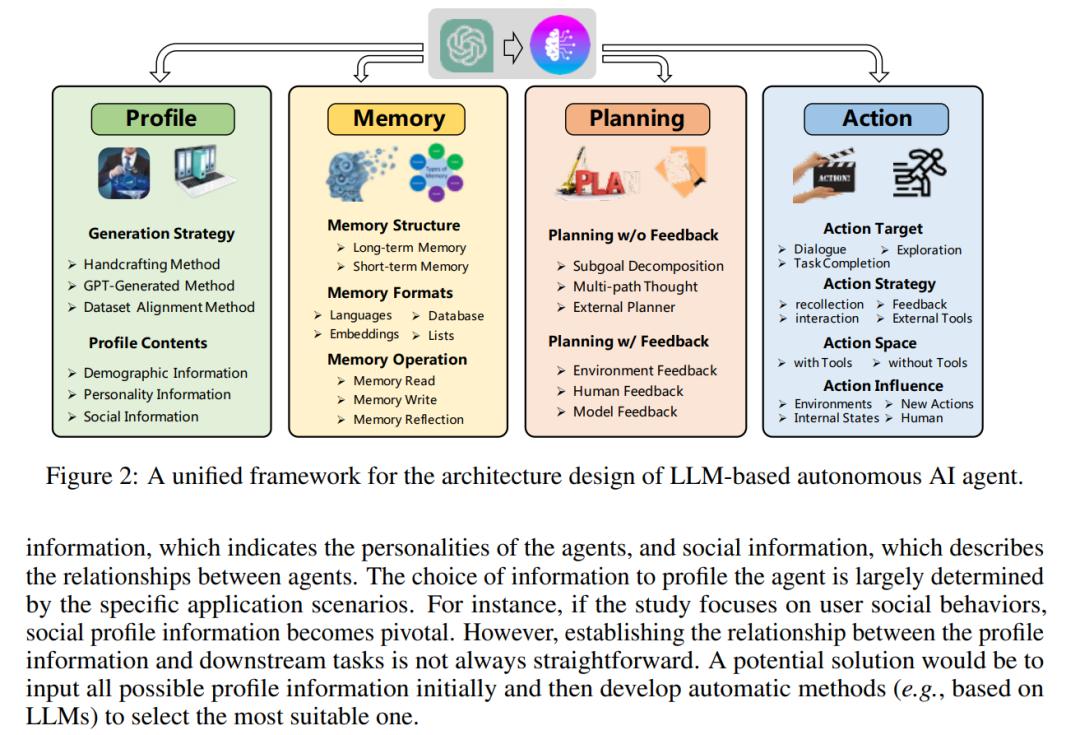
总结而言,分析模块旨在识别智能体是什么角色;记忆和规划模块可将智能体置于动态环境中,使智能体能够回忆过去的行为并计划未来的行动;动作模块负责将智能体的决策转化为具体的输出。在这些模块中,分析模块影响记忆和规划模块,这三个模块共同影响动作模块。
分析模块
自主智能体通过特定角色来执行任务,例如程序员、教师和领域专家。分析模块旨在表明智能体的角色是什么,这些信息通常被写入输入提示中以影响 LLM 行为。在现有的工作中,有三种常用的策略来生成智能体配置文件:手工制作方法;LLM-generation 方法;数据集对齐方法。
记忆模块
记忆模块在 AI 智能体的构建中起着非常重要的作用。它记忆从环境中感知到的信息,并利用记录的记忆来促进智能体未来的动作。记忆模块可以帮助智能体积累经验、实现自我进化,并以更加一致、合理、有效的方式完成任务。
规划模块
当人类面临复杂任务时,他们首先将其分解为简单的子任务,然后逐一解决每个子任务。规划模块赋予基于 LLM 的智能体解决复杂任务时需要的思考和规划能力,使智能体更加全面、强大、可靠。本文介绍了两种规划模块:没有反馈的规划以及有反馈的规划。
动作模块
动作模块旨在将智能体的决策转化为具体的结果输出。它直接与环境交互,决定智能体完成任务的有效性。本节从动作目标、策略、动作空间和动作影响来介绍。
除了上述 4 个部分外,本章还介绍了智能体的学习策略,包括从示例中学习、从环境反馈中学习、从交互的人类反馈中学习。
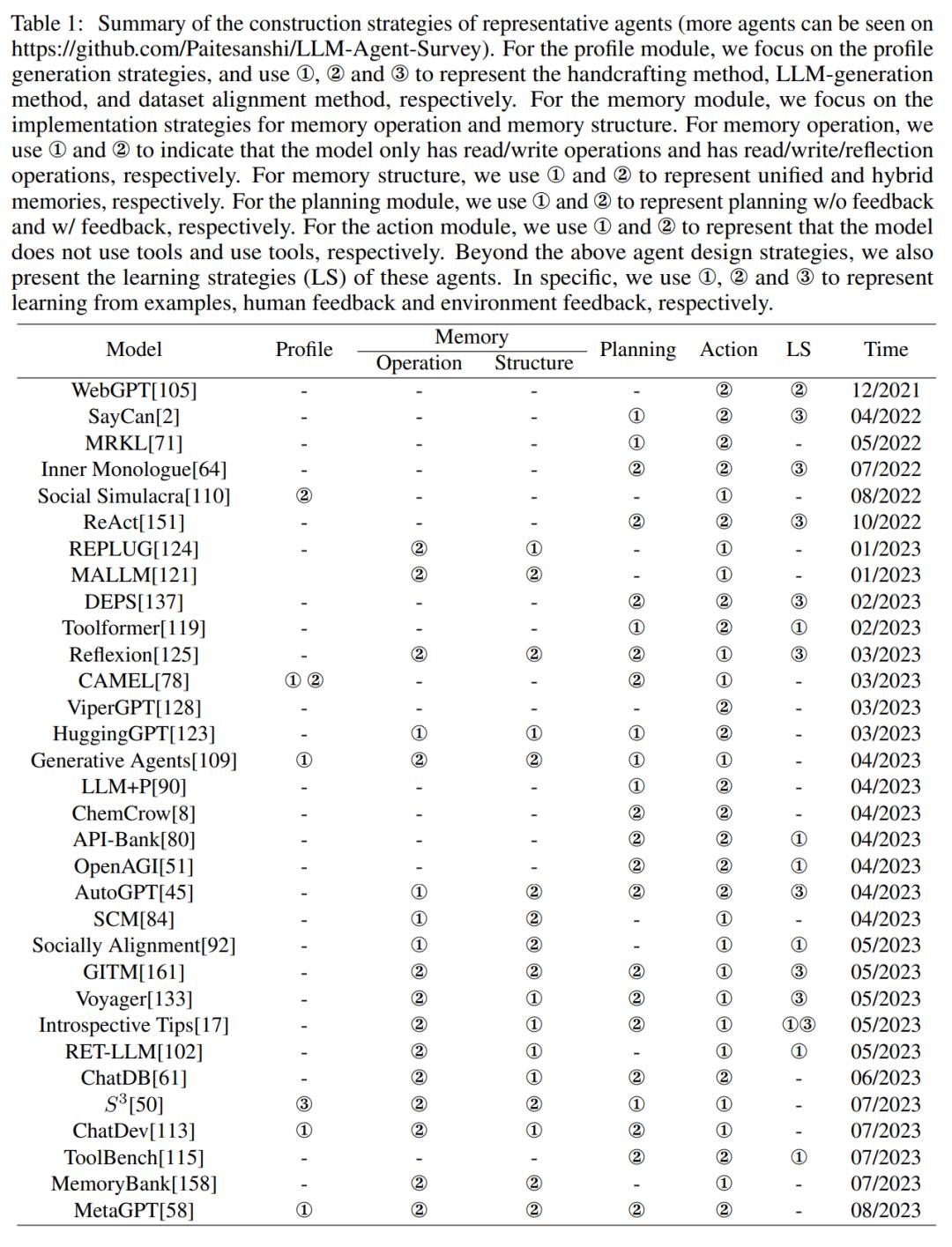
表 1 列出了之前的工作和本文的分类法之间的对应关系:
基于 LLM 的自主智能体应用
本章探讨了基于 LLM 的自主智能体在三个不同领域的变革性影响:社会科学、自然科学和工程。
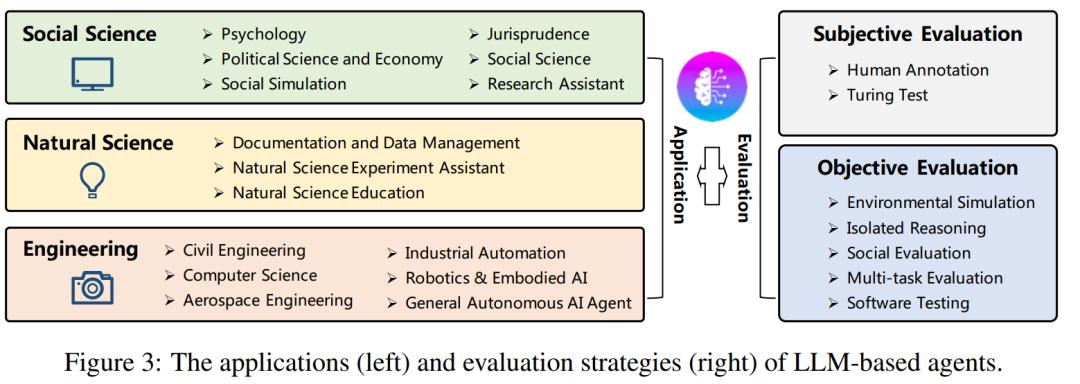
例如基于 LLM 的智能体可用于设计和优化复杂结构,如建筑物、桥梁、水坝、道路等。此前,有研究者提出了一个交互式框架,人类建筑师和 AI 智能体协同办公在 3D 模拟中构建结构环境。交互式智能体可以理解自然语言指令、放置模块、寻求建议并结合人类反馈,显示出工程设计中人机协作的潜力。
又比如在计算机科学和软件工程领域,基于 LLM 的智能体提供了自动化编码、测试、调试和文档生成的潜力。有研究者提出了 ChatDev ,这是一个端到端的框架,其中多个智能体通过自然语言对话进行沟通和协作,以完成软件开发生命周期;ToolBench 可以用于代码自动补全和代码推荐等任务;MetaGPT 可以扮演产品经理、架构师、项目经理和工程师等角色,内部监督代码生成并提高最终输出代码的质量等等。
下表为基于 LLM 的自主智能体的代表性应用:

基于 LLM 的自主智能体评估
本文介绍了两种常用的评估策略:主观评估和客观评估。
主观评估是指人类通过交互、评分等多种手段对基于 LLM 的智能体的能力进行测试。在这种情况下,参与评估的人员往往是通过众包平台招募的;而一些研究者认为众包人员由于个体能力差异而不稳定,因而也会使用专家注释来进行评估。
除此以外,在当前的一些研究中,我们可以使用 LLM 智能体作为主观评估者。例如在 ChemCrow 研究中,EvaluatorGPT 通过指定等级来评估实验结果,该等级既考虑任务的成功完成,又考虑基本思维过程的准确性。又比如 ChatEval 组建了一个基于 LLM 的多智能体裁判小组,通过辩论来评估模型的生成结果。
与主观评估相比,客观评估具有多种优势,客观评估是指使用定量指标来评估基于 LLM 自主智能体的能力。本节从指标、策略和基准的角度回顾和综合客观评估方法。
在使用评估过程中,我们可以将这两种方法结合使用。
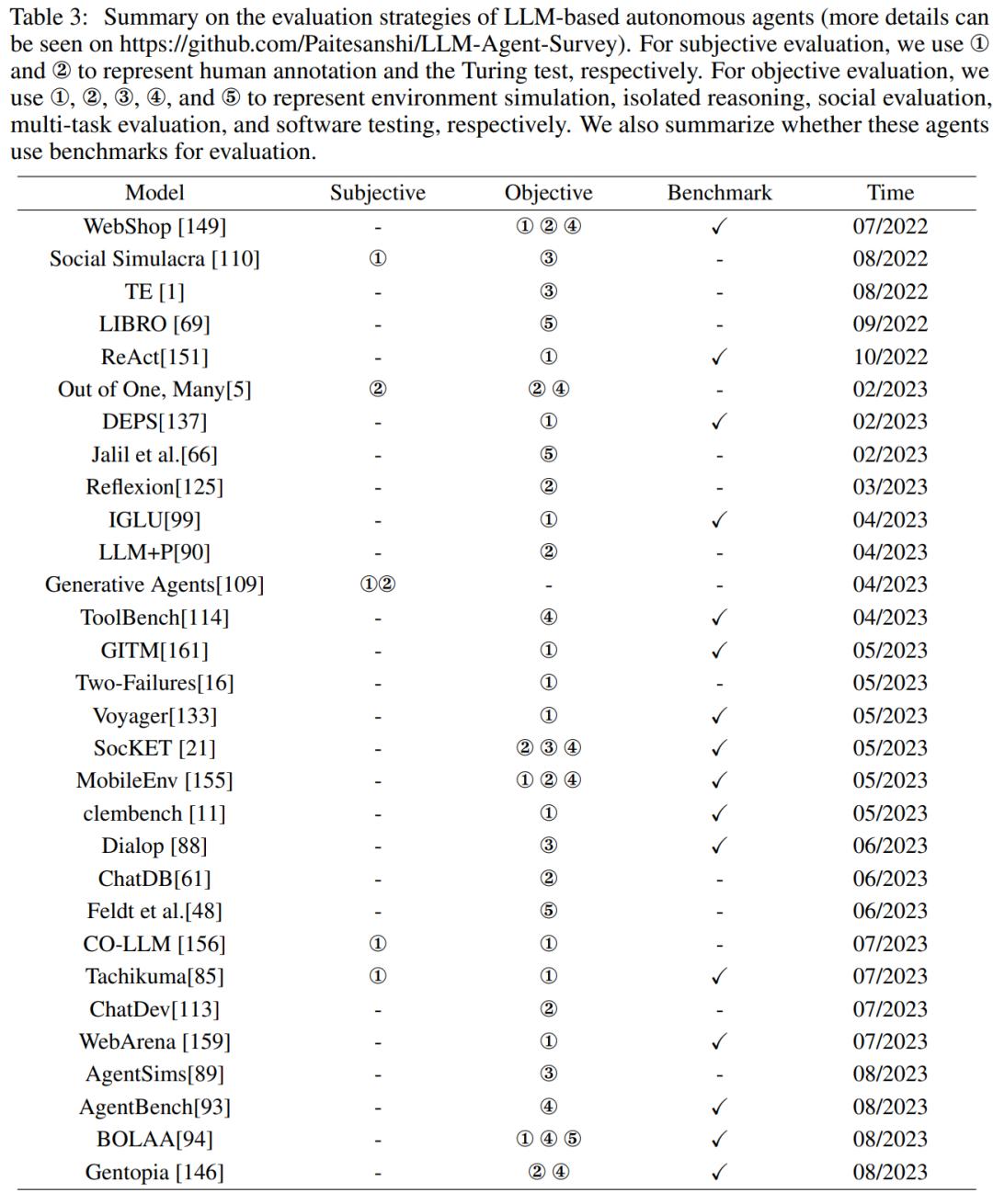
表 3 总结了以前的工作与这些评估策略之间的对应关系:
原标题:《AI自主智能体大盘点,构建、应用、评估全覆盖,人大高瓴文继荣等32页综述》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

