- +1
达摩院后的下一站:陈俊波推出具身智能大模型,要给所有机器人做一颗脑袋
原创 张倩 机器之心
机器之心原创
作者:张倩
「麻烦借过一下,谢啦。」对于很多大学生来说,这是一个熟悉的声音。它来自阿里的「小蛮驴」无人驾驶物流机器人。该机器人 2016 年开始路测,如今已累计送达快递上千万件,为阿⾥奠定了快递配送机器⼈第⼀的地位。

但今年 3 月份,它背后的灵魂技术人物、原阿里达摩院自动驾驶负责人陈俊波却被爆出离职创业的消息。消息称,他与前阿里机器人 CEO 谷祖林等人共同创办了一家名为「有鹿机器人」的新公司,至于这家公司具体做什么,外界没有得到确切答复。
近期,抱着这个疑问,机器之心与陈俊波展开了深入对谈。
在对谈中,陈俊波透露,他要做的并不是某一款机器人,而是一个放到任何传统自动化设备(比如清扫车、挖掘机、铲车等)上都能正常运转的通用机器人「脑袋」。这个「脑袋」可以跨模态、跨场景、跨行业,具有极强的环境适应性,就像《变形金刚》里的「火种」一样。从上述传统设备当前的智能化率来看,这个「脑袋」一旦做出来,有望服务于上亿台设备。

「火种」是《变形金刚》里的能量块,是变形金刚最基本也是最神秘的组成部分,火种赐予变形金刚具体的身形、意识及生命。
当然,这也意味着更大的技术考验。因此,在过去的大半年的时间里,陈俊波带领「有鹿」一头扎进了比自动驾驶更复杂的「具身智能」领域,希望借助大模型的力量赋予机器人在物理世界完成更多任务的能力,把类似 ChatGPT 的能力扩展到物理世界。
具身智能:AI 领域的下一个「北极星问题」
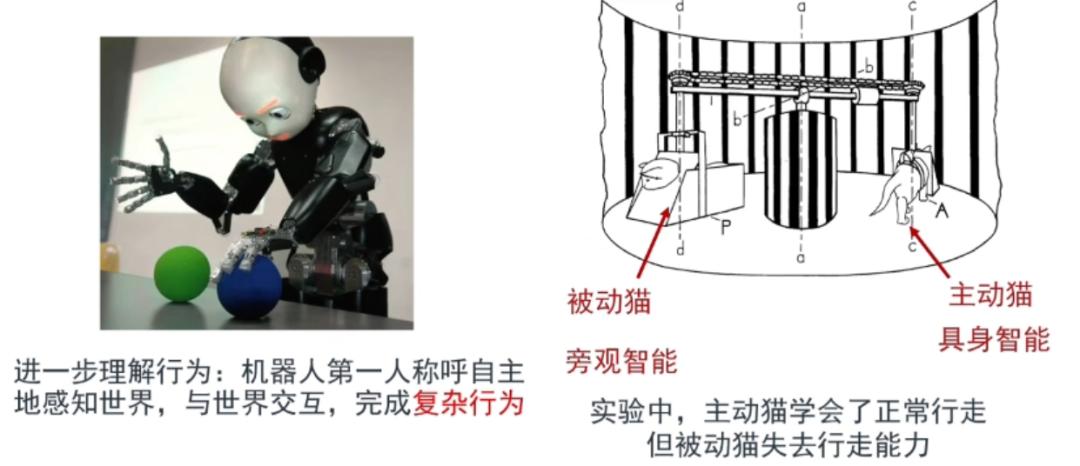
生物的进化总能给智能的研究带来很多启发。过去 5.4 亿年来,地球上所有的生物都是通过身体逐步产生智能的。有了身体,智能体就可以在快速变化的环境中移动、导航、生存、操纵和做出改变。相比之下,没有身体的智能体只能「旁观」,很难适应现实世界。因此,人工智能研究也自然而然地走向了「具身」的道路。人们希望机器人也能像生物体一样,通过与环境交互以及自身的学习,产生对于客观世界的理解和改造能力。具身智能也被斯坦福大学教授李飞飞定义为 AI 领域的。
图源:《》
不过,由于涉及学科众多,具身智能在过去的几十年里并没有取得很大进展。直到最近几年,情况才有所改变,尤其是在「大模型 + 机器人」的组合流行起来之后。谷歌的 PaLM-E、斯坦福的 VoxPoser 都是基于大模型构造的具身智能体。它们能够直接「听懂」自然语言指令,并将其拆解成若干个动作来完成,准确率已经达到了相当高的水平。

斯坦福大学李飞飞团队的 VoxPoser 机器人。
作为阿里内部「最早领潮自动驾驶的人」,陈俊波也一直在关注具身智能领域,毕竟自动驾驶车也是具身智能的重要载体。其多年来不断积累的多模态学习、强化学习等能力在具身智能领域至关重要。
在陈俊波看来,「大模型 + 机器人」组合的成功其实意味着具身智能领域正在经历一场范式转变,基于 Transformer 架构的极具表达能力的模型、互联网规模的数据都是推动这一转变的关键力量。但是,要想在物理世界充分利用这些力量,现有的工作做得还远远不够。
从实验室到现实世界,具身智能还有哪些工作要做?
陈俊波以谷歌的 PaLM-E 为例,向我们展示了现有的具身智能大模型存在哪些改进空间。这个模型集成了参数量 540B 的 PaLM 和参数量 22B 的视觉 Transformer(ViT),使用文本和来自机器人传感器的多模态数据(比如图像、机器人状态、场景环境信息等)作为输入,输出以文本形式表示的机器人运动指令,进行端到端的训练。

它的结构如下图中间部分所示:绿色的部分用来编码机器人本身的状态,包括底盘、机械臂的位置等状态量;传感器捕捉到的图像由一个 ViT 模型来编码(图中蓝色部分)。给定这些条件,人类就可以发出一个自然语言指令,比如「如何抓起蓝色的木块」,然后这个指令就会被编码为嵌入,并经过一个 CoT(chain of thought)的过程被转换为一系列动作。这些动作会由一个动作解码器(图中的紫色部分)来执行,它会把每个步骤的指令转化为机器人的扭矩等参数。

经过测试,整个模型完成任务的成功率接近 80%。作为一个端到端的框架,「这是一个让人觉得非常不可思议的工作,」陈俊波评价说。但在实际的工作场景中,80% 的成功率离落地还有很大距离,「想象一下,如果说我下发 100 个任务,它有 20 个都失败了…… 而且,这还是在实验室的场景下,」陈俊波说到。
究竟是哪里出了问题?陈俊波指出了两个关键点。
第一个问题是,在传感器图像和文本 prompt 输入的处理上,PaLM-E 只是将 VLM 与 LLM 简单拼合,做隐式建模。前者输出的是抽象等级很低的像素级的特征,后者输出的是抽象等级很高的自然语言级别的特征,二者直接拼合会带来不匹配的问题,导致模型的泛化能力非常有限。「有句话叫一图胜千言,就是说图像里面包含太多的细节,不可能用一个一个的文本就很简单地把它们对应起来,」陈俊波解释说。
具体来说,PaLM-E 使用 ViT 来处理图像,ViT 会把整个图像切分成小的图块(patch),然后从每个图块中提取出关于图像的基础细节特征,比如颜色、边缘、纹理,这些特征是「low level」的。与之对应,图像中还有很多「high level」特征,比如不同物体之间的几何关系、现实世界里的物理学规律、交通参与者的意图…… 这是无法做显式建模的 ViT 所提取不到的,这是它编码物理世界的一个缺陷。
在 Prompt 的处理上,虽然 PaLM-E 会把人的高级指令拆解为更详细的指令,但这一步的输出仍然是自然语言。自然语言的问题在于,它是一种高度抽象、模糊的系统,「比如说『人类』虽然只有四个字节,却囊括了地球上几十亿的人类,」陈俊波解释说。这不仅和 ViT 输出的「low level」的特征不匹配,对于底层控制器来说也不够友好,后者需要更具体、更精确的指令来执行任务。
第二个问题是,PaLM-E 的动作解码器存在天然缺陷,无法从海量无标签的机器人数据中学习,也无法扩展到交互场景。
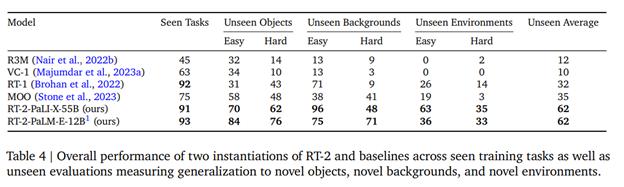
这是因为,PaLM-E 的动作解码器采用了一个名为「RT-1」(Robotics Transformer-1)的模型,这个模型接收自然语言和图像作为输入,输出机器人运动指令(底盘位置和机械臂末端位置)。局限在于,这个模型是采用模仿学习的方式训练出来的,而模仿学习本质上属于监督学习,因此无法在海量无标注数据上学习。
最近公布的 RT-2 模型使用了更多的训练数据(在原来示教数据的基础上增加了互联网级别的 VQA 数据),将模型在没见过(Unseen)的任务上的成功率从 32%(RT-1)提高到了 62%。如果将 PaLM-E 中的动作解码器组件换成 RT-2,PaLM-E 的泛化能力想必也会大幅提升。但陈俊波指出,这并不会从根本上解决问题,因为在学习机器人数据时,它本质上用到的还是模仿学习。
此外,模仿学习学到的函数针对一个固定的输入只能输出一个或一组固定的动作,而交互场景要求针对相同的输入,根据交互对象的选择动态调整输出,所以模仿学习学到的模型本质上无法在交互博弈场景中工作,而这项能力又是具身智能机器人走出实验室所必需的。
已经在园区跑起来的 LPLM
陈俊波在具身智能方向的工作主要围绕以上待解决的问题展开。具体来说,他提出了一个名为「LPLM」(large physical language model)的大模型。整个模型的架构如下所示:
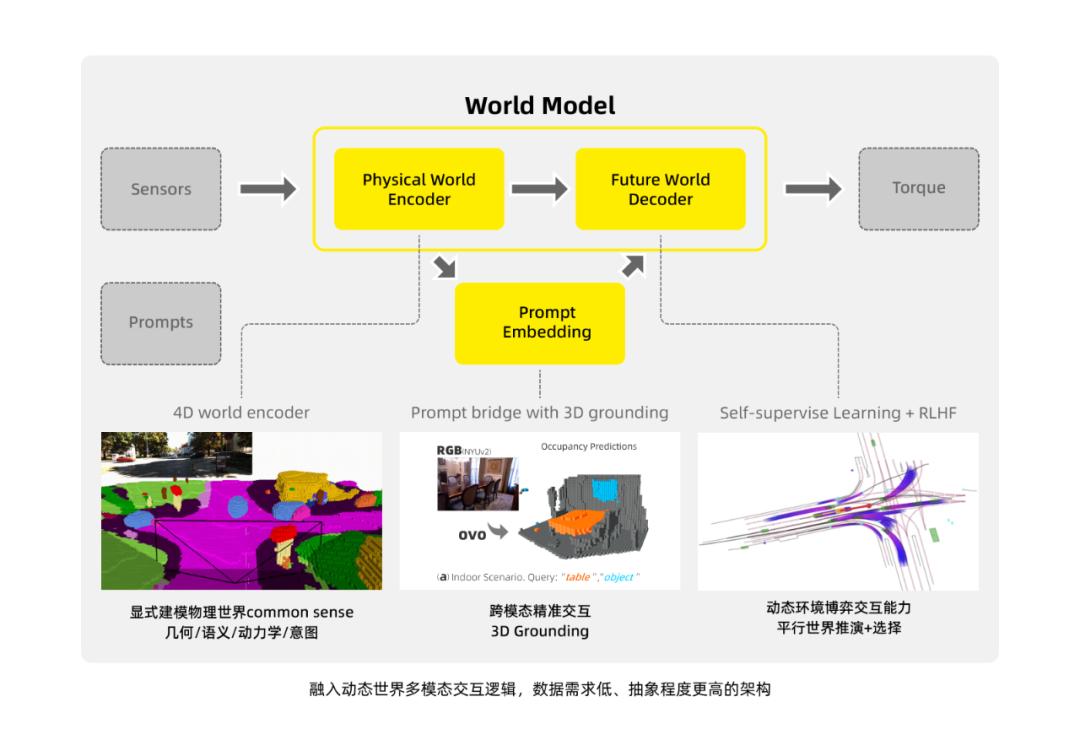
首先,这个模型会把物理世界抽象到一个很高的程度,确保这些信息能跟 LLM 里特征的抽象等级对齐,做显式建模,从而实现很好的融合。回忆一下语言学中的能指(用以表示抽象概念的语言符号,比如「人」这样一个单词)和所指(语言符号所表示的具体事物,比如图像空间中的每一个人)的概念,LPLM 将物理世界中每一个所指的实体显式建模为 token,编码几何、语义、运动学与意图信息,相当于在物理世界建模了一套全新的语言体系。
具体来说,这种对齐是通过多种方式来实现的,包括利用点云等多模态数据捕捉几何信息;在多帧甚至无限帧数据之间做时序融合以跟踪实体在不同时间点的变化,捕捉其运动学和动力学约束关系;在空间中建模各个实体之间的关系,从而捕捉它们在交互博弈环境中的意图信息等。
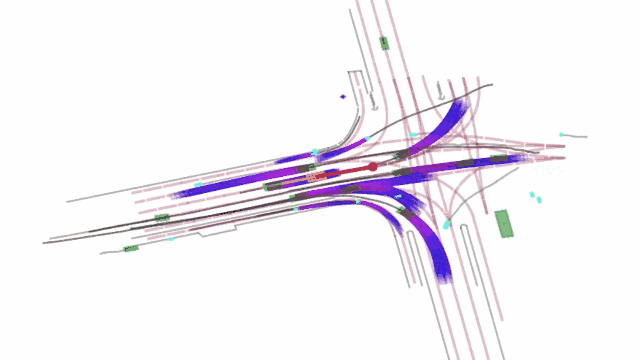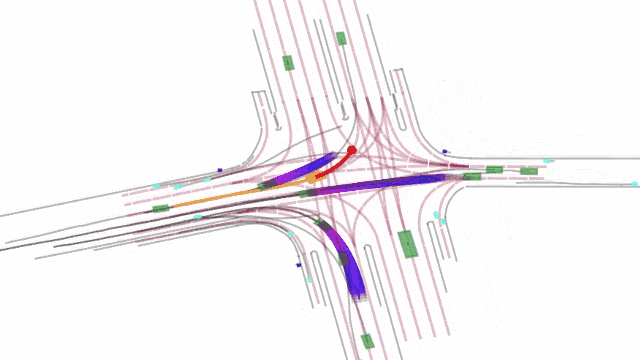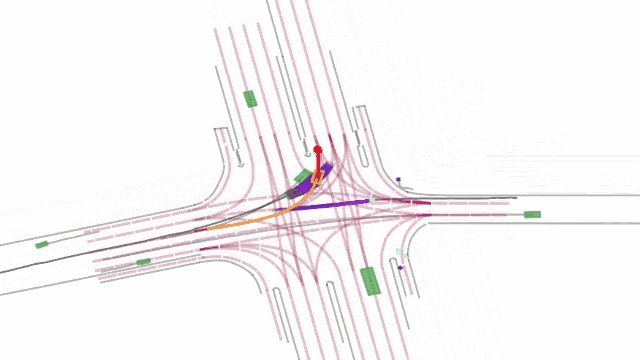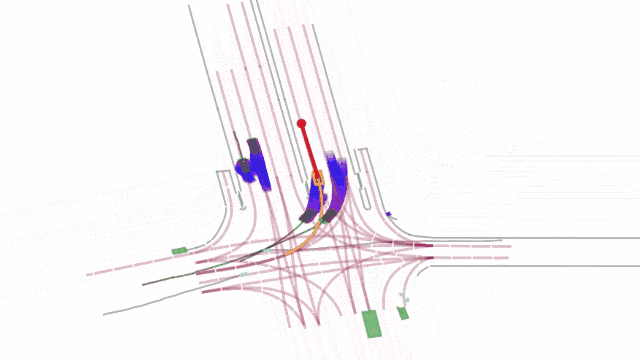
令人兴奋的是,LPLM也很好地降维完成了自动驾驶行业对端到端的技术追求。比如在一个交通场景中,LPLM 展现了建模物理世界实体意图方面的能力。在这个场景中,智能车要在有加塞车辆的情况下安全左转,此时模型就需要判断加塞车辆是否会做出让行等动作(意图),才能决定自己下一步的动作。这种交互博弈场景没有固定答案,需要模型随机应变。
其次,在自然语言指令的编码上,LPLM 也做出了一些改进,加入了 3D grouding(grouding 可以理解为机器人怎么把用户的语言对应到真实环境)。以有人问「桌子在哪儿」为例,之前的 visual grounding 方法会把桌子所在区域的像素高亮出来,但加入了 3D grouding 的 LPLM 会先把三维空间里的几何关系恢复出来,然后再把桌子所在的三维空间作 grounding。这相当于在物理世界中,明确告诉机器人作业目标在哪儿,在一定程度上弥补了自然语言不够精确的缺陷。
最后,在解码器的设计上,为了让模型具备从海量无标签数据中学习的能力,LPLM 的解码器是通过不断预测未来的方式去学习的。如此一来,对于任何一段给定的数据,任何当前状态都是对过去状态的自动标注,无需人工示教数据。在这一点上,陈俊波谈到了 Yann LeCun 的思想 —— 智能的本质是预测 —— 对于自己的启发。「一个一两岁的孩子肯定不知道什么是万有引力,但通过长期的实践和观察(比如扔东西),他的身体已经知道了。我们也是用同样的方法教机器人学习,」陈俊波谈到。
那么,这一套方法到底有没有效?陈俊波已经用他们的第一款产品 —— 有鹿智能清洁机器人给出了答案。和传统的只能进行全覆盖清扫和巡检清扫的室外清洁机器人不同,内置了 LPLM 大模型的有鹿机器人支持随叫随到的清扫模式,比如你可以让它「去 1 号楼清扫一下落叶」,或者说「路边有点脏,贴边清扫一下吧」,机器人都能听懂,并且能在充满行人、车辆的园区交互博弈环境中安全穿行,功耗仅 50 瓦。这体现了该机器人对语言语义、物理环境及行为意图的融合理解。据悉,这款机器人将在即将到来的杭州亚运会上亮相。


给所有机器人做一颗脑袋
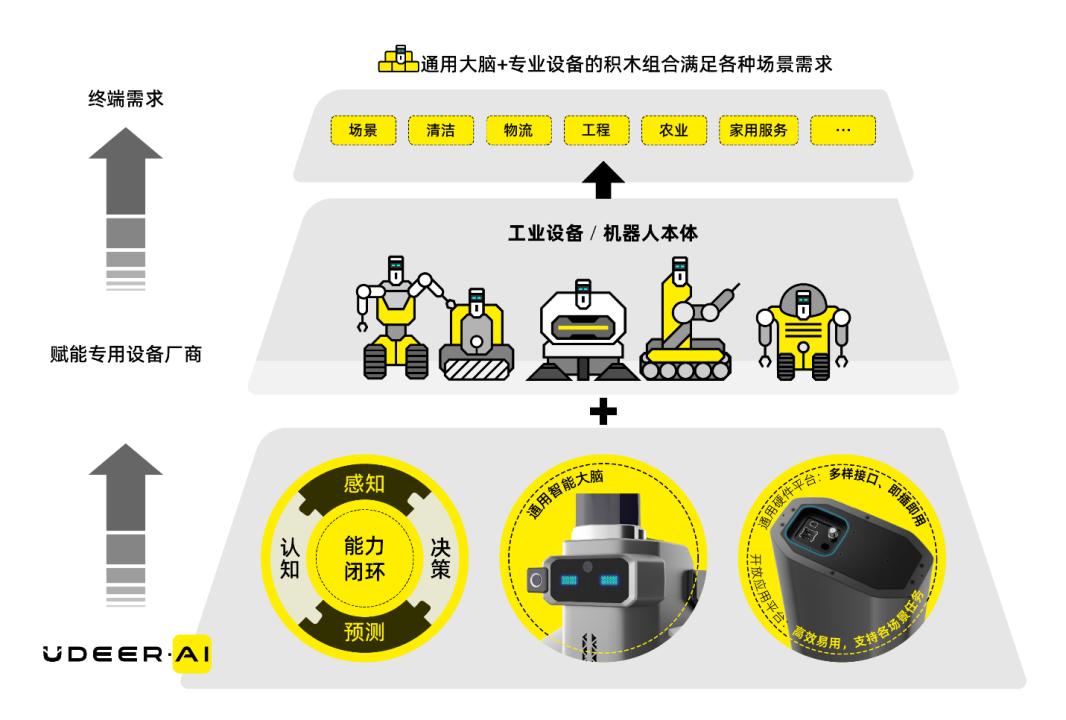
当然,对于陈俊波来说,将内置 LPLM 大模型的「脑袋」安在清洁机器人身上只是一个开始。未来,这套方案还将扩展到挖掘机、铲车等传统设备上。在他看来,比起开发一款服务于单个场景的完整产品,开发一个通用的脑袋具有更大的社会价值。

有鹿的机器人大脑多种应用场景
在谈到这件事情的可行性时,陈俊波提到,虽然表面看起来这是一些跨模态、跨场景、跨行业的设备,但当模型对于物理世界的理解提升到三维甚至四维,很多共性的东西就可以被提取出来。这种情况下,以 LPLM 为代表的具身大模型相当于充当了物理世界的 Foundation model。此外,有鹿还定义了一个通用的硬件标准,这个标准会兼容现在所有的设备厂商。
不过,眼前还有很多待解决的问题,比如海量机器人数据如何获取?这也是有鹿在很短的时间内就推出第一款产品的一大原因。他们希望借助这些产品尽快让数据飞轮转起来,就像很早就开放 API 接口的 GPT 类产品一样。
在早年和蒋昌建谈梦想的时候,陈俊波说,他希望未来⼈类会像拥有个⼈电脑⼀样拥有机器⼈。一路走来,他已经越来越接近自己的梦想。当初做小蛮驴的时候,他也经历了「机器一直掉螺丝,送不出几个包裹」的阶段,但到了 2022 年,平均每秒钟都会有两位消费者收到小蛮驴送出的包裹,这款产品也让陈俊波看到了具身智能背后巨大的市场空间。
其实,和小蛮驴所处的物流领域一样,很多传统行业对具身智能机器人都有着强烈的需求。这些行业拥有海量的存量专业设备和专业机器人,也积累了丰富的行业经验和渠道品牌,只是设备的智能化率仍有很大的提升空间,而具身智能的快速发展有望为这些行业带来一场大范围的智能化升级。凭借多年来在具身智能领域的探索经验,陈俊波希望能与这些行业的企业家一起,迎接这场升级过程中的挑战与机遇。

参考链接:
https://mp.weixin.qq.com/s/MM_VLWmrrxev1zWuLKZZUQ
https://hub.baai.ac.cn/view/15855
https://mp.weixin.qq.com/s/2ASdgAER2EYsmjipIiVyDg
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《独家 | 达摩院后的下一站:陈俊波推出具身智能大模型,要给所有机器人做一颗脑袋》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

