- +1
百川发布530亿大模型,融入搜索能力:第一时间内测体验已来
原创 泽南 机器之心
机器之心报道
编辑:泽南
参数量级提升,融入搜索引擎,目标服务 B 端。
连续三个月,王小川创立的百川智能就在昨天又发布了大模型。
8 月 8 日,百川智能在北京宣布新一代大模型 Baichuan-53B 正式上线。于此同时,王小川等公司高管接受了媒体采访。
「人们通常认为发布大模型至少需要半年时间,从数据积累准备、训练再到微调。我们推出首个模型仅用两个月,并且最终质量上也得到了外界的赞誉,」搜狗公司原 CEO、百川智能创始人王小川表示。「Baichuan-53B 和之前相比参数规模提升了很多,在写作能力上有了很大提高。」

从 6 月 15 日的 7B 模型,7 月 11 日的 13B 模型再到如今 530 亿,百川大模型的体量迅速提升。本次,百川智能还公布了大模型的网站,开放了内测申请。
链接:https://chat.baichuan-ai.com/home
在活动现场,王小川亲自演示了新一代大模型的部分能力。
完成一个短视频广告的脚本:

百川智能表示,在文本创作的创意性、风格模仿和实用性上,Baichuan-53B 都可以做到足够好,大部分任务上都能给出不错的回应。
在昨天的发布后,机器之心也获内测邀请进行了简单的测试,重点体验了百川智能所说的文本生成和搜索能力。

尝试一下 2023 年北京高考的作文题:

可见 Baichuan 53B 了解并能整合近期的一些热点消息:
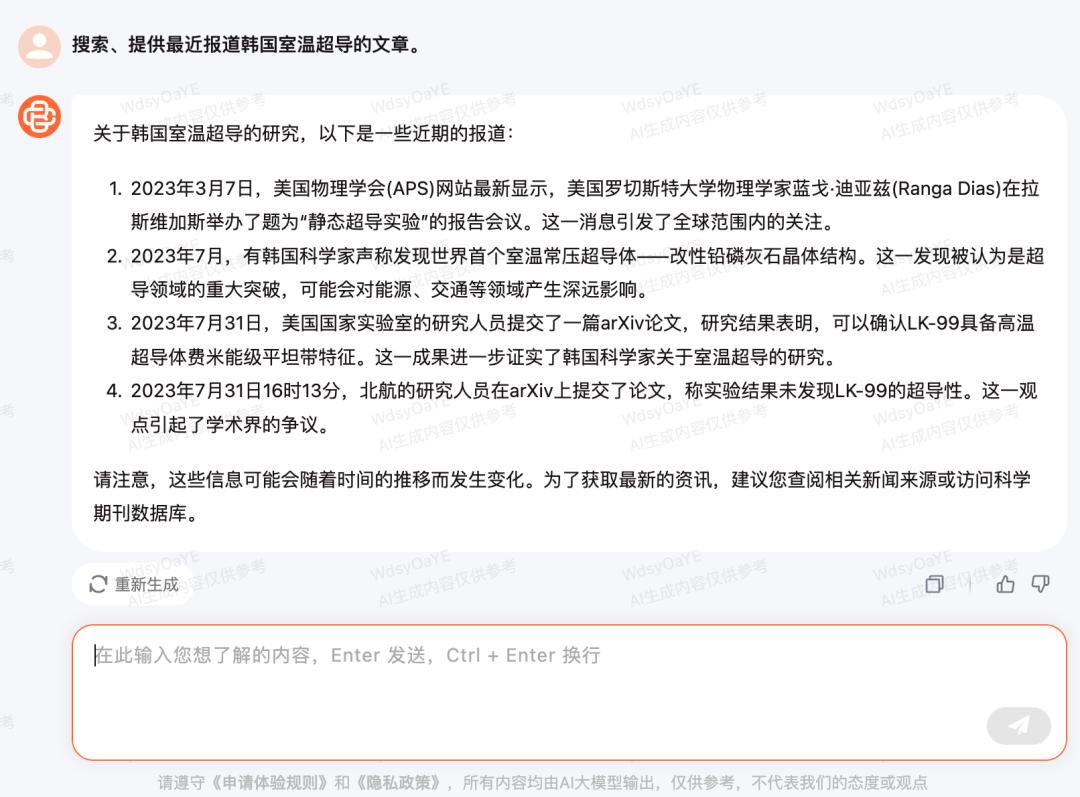
但与此同时,大模型似乎并不认为自身具有获取实时消息的能力。

在 Baichuan-53B 上,搜狗强调大模型和搜索进行了很高程度的融合,希望能通过这种机制给未来的搜索模型打下了基础。
百川认为,搜索增强是解决模型时效性和幻觉的有效手段,将搜索技术与大语言模型能力结合实现了创新的模型优化,也提升了 AI 回答的可用性。
据介绍,百川大模型的搜索增强系统融合了多个模块,包括指令意图理解、智能搜索和结果增强等组件。该体系通过深入理解用户指令,精确驱动查询词的搜索,并结合大语言模型技术来优化模型结果生成的可靠性。通过这一系列协同作用,大模型实现了更精确、智能的模型结果回答,通过这种方式减少了模型的幻觉。
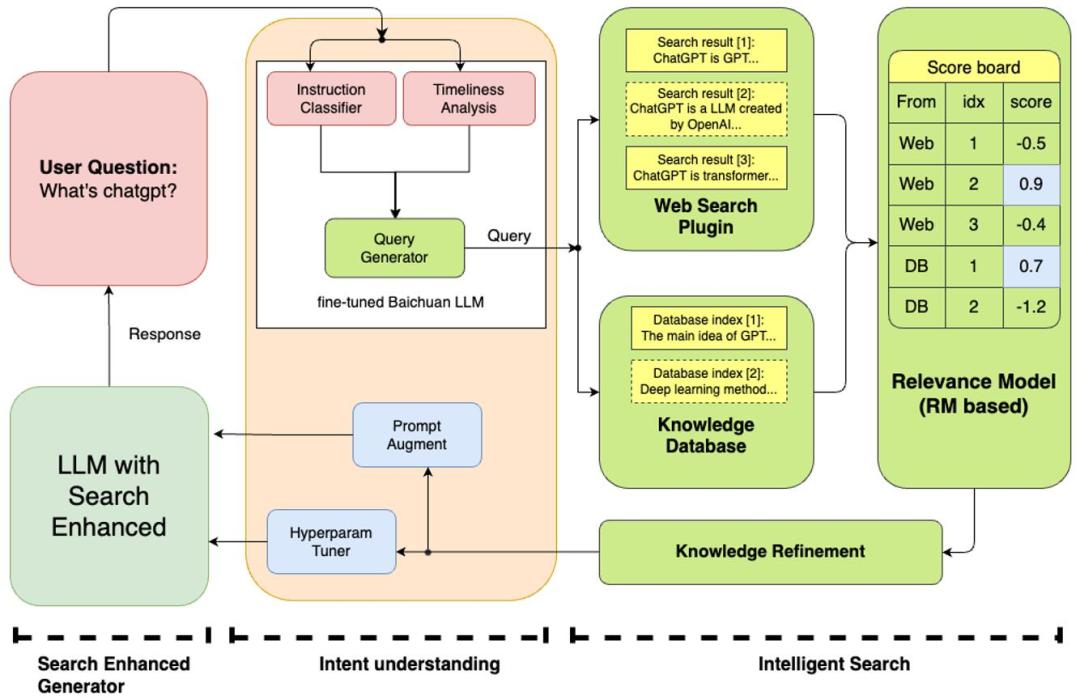
相比 ChatGPT 以插件形式链接必应搜索的方式,百川大模型对于搜索结合的更加深入,不过百川并未透露合作的搜索引擎。
另外在动态响应策略中,百川也有自己的独特之处,其将指令任务细化为 16 个独立的类别。这些类别涵盖了用户指令的包括精准问答、逻辑推理、头脑风暴等各种场景,对于每一个指令类别都进行了个性化的设计和优化。为了实现这个目标,新模型依赖于 Prompt 增强技术,即通过构造特定的输入提示来引导模型生成期望的输出。这种方式可以确保模型对不同类型的指令都能产生恰当的响应。
此外,百川智能讨论了动态超参数调整技术、智能化搜索词生成、高质量搜索结果筛选、RLHF 搜索结果增强等方法。在大模型预训练之外,百川强调了对齐调整(Alignment Tuning)对于提升回复内容质量的重要性。
「我觉得现在比当年做搜索引擎的时候成就感要大,」王小川表示。「在大模型时代以前,搜狗已很早应用了 transformer,但我们始终不能有效地把搜索改进成实用的问答模型。但是现在,我们可以更加容易地实现这样的能力。」
值得一提的是,在模型体量变大以后,百川没有继续此前的开源方式,Baichuan-53B 计划在下个月开放 API 和组件,进行业务对齐和专业领域方面的强化以推动落地。
「我们提供的大模型可以直接拿出来跑分测试,这在行业内是不多见的。这些产品没有为单独场景进行过优化,它们为成为 to B 基础模型做好了准备,」王小川表示。
2023 年 4 月 10 日,王小川官宣创办百川智能,致力于打造对标 OpenAI 的通用智能技术,构建基础大模型及颠覆性上层应用。在技术团队不断扩充的同时,百川也陆续推出了自研的大模型。

6 月 15 日,百川智能推出了 70 亿参数量的中英文语言模型 Baichuan-7B,并拿下多个世界权威 Benchmark 榜单同量级测试的榜首。7 月 11 日,百川智能又发布了参数量 130 亿的通用大语言模型 Baichuan-13B-Base、对话模型 Baichuan-13B-Chat 及其 INT4/INT8 两个量化版本。
而在融资方面,百川智能 5 月完成的天使轮融资获得了来自腾讯、小米、金山、慕华资本、清华大学资产管理有限公司等十余家机构的联合投资。
在商业模式上,百川智能希望远期能够在消费领域购建「超级应用」。而在目标相对明确的 to B 领域中,虽然进入市场的速度不算最快,但该公司也已通过开源等方式展现了自身的实力。
「从 to B 的角度来讲,开源和闭源的大模型都有发展空间,我们认为未来 80% 的公司需要基于开源模型构建智能化,」王小川表示。「目前已经有超过 150 家企业在申请使用我们的大模型。」
百川智能计划在今年的第三、四季度继续发布千亿、万亿级别大模型,构建出国内水平最高的,对标 GPT 系列的产品。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《百川发布530亿大模型,融入搜索能力:第一时间内测体验已来》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

