- +1
Llama 2唯一中国合作伙伴,刚刚曝光
允中 发自 凹非寺
量子位 | 公众号 QbitAI
上周,Llama 2的发布在AI圈子引起了巨大的轰动。
Llama 2相比上一代,不仅用了更多的训练数据,而且context length直接翻倍,达到了4096。
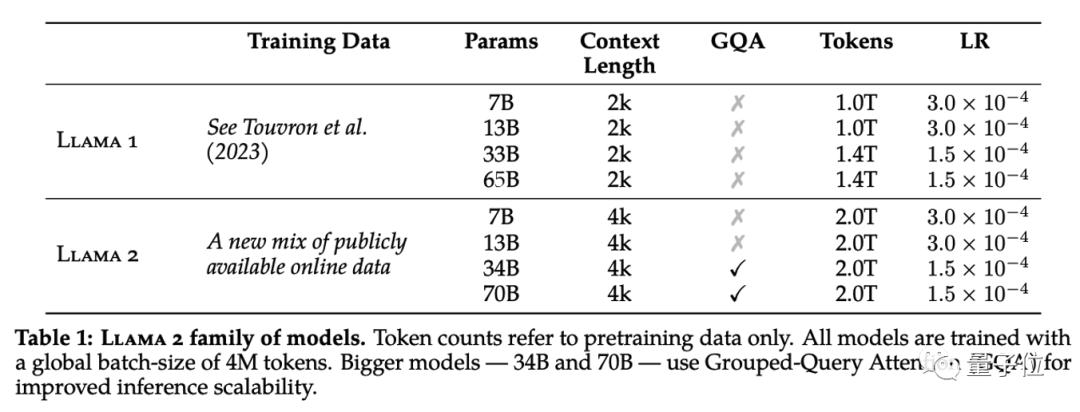
更重要的是,Llama 2在公开测试基准上的结果显示,其在代码、常识推理、世界知识、阅读理解、数学等评测维度的能力均获得了大幅的提升。仅7B的版本就在很多测试集上接近甚至超越30B的MPT模型的表现。
尤其需要注意的是,Llama 2 70B模型在MMLU和BBH测试上的成绩,分别比Llama 1 65B 的模型提升了约5和8个百分点。当规模相同时,Llama 2 7B和30B模型在除了编程基准测试之外的所有类别上,表现都优于MPT模型。
此外,对于Falcon模型,Llama 27B和34B在所有基准测试类别上,都超过了Falcon 7B和40B模型。不仅如此,Llama 2 70B模型在所有开源模型中的表现是最好的。
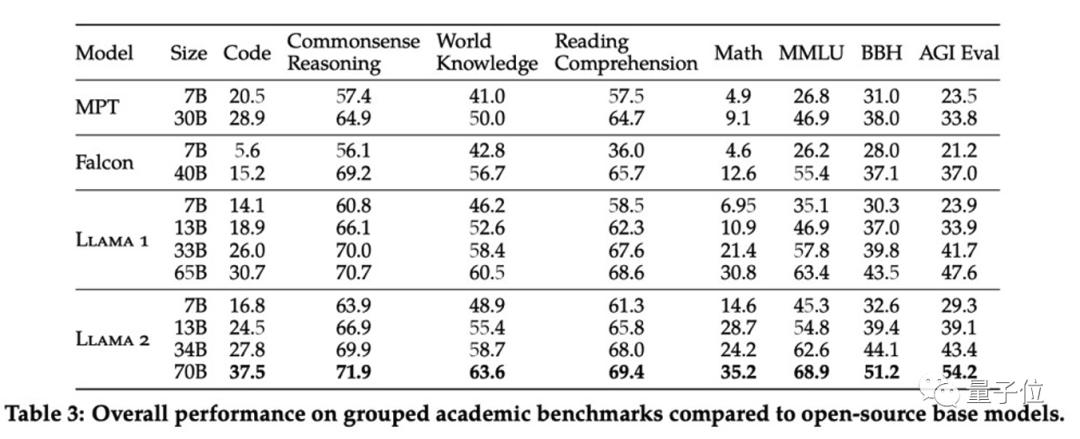
除了与开源模型进行比较,论文里也对比了Llama 2 70B与闭源模型的结果。

如表所示,Llama 2 70B在MMLU和GSM8K测试上接近GPT-3.5模型,但在编程基准测试上,两者之间存在显著的差距。在几乎所有的基准测试上,Llama 2 70B的结果都等于或优于PaLM(540B)模型。
除此之外,这次还顺带发布了一个对齐人类偏好的finetune版本——Llama-2-chat模型,其对话流畅性和安全性都会相比Llama 2有一个比较明显的提升,当然,副作用就是模型在一些任务层面的性能可能会有所损失。
而Llama-2-chat模型跟一众开源/闭源模型的pk也是惊到了读者。
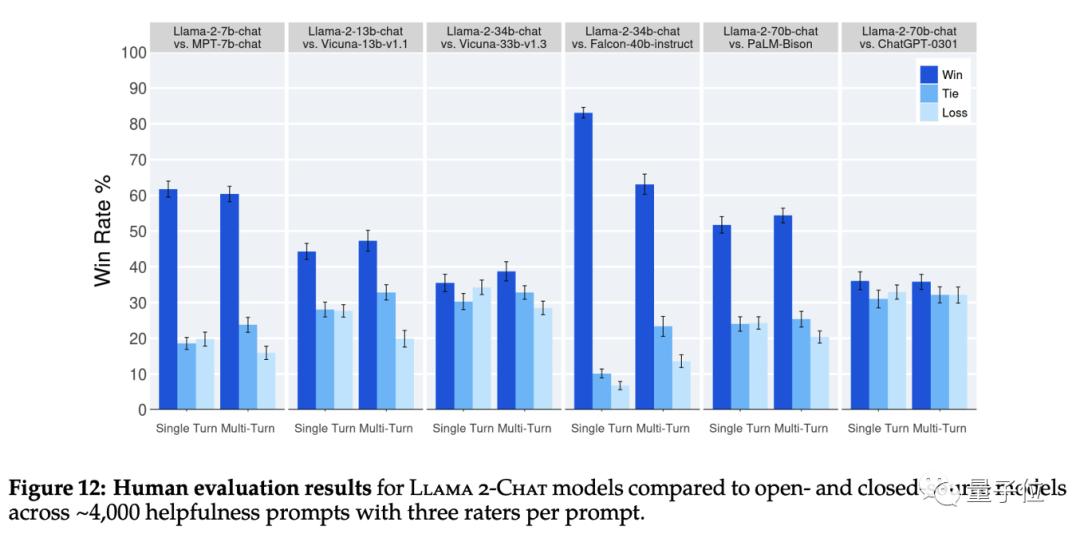
竟然都能小幅打赢ChatGPT-0301! 而且评估方式是人类评估,而不是严重有偏的刷榜式评估,虽然不是绝对无偏,但也能很大程度上表明真实的使用体验了。
那么问题来了,驱动Llama 2系列模型取得如此效果提升的关键是什么?
相信每一个算法工程师心里都有一个清晰的答案:
数据!
数据!
数据!
数据可以视为机器学习模型训练过程中的燃料,没有高质量的数据,就很难训练出高质量的模型。
模型训练对数据的依赖性主要体现在以下几个方面:
数据质量:模型的训练和预测表现在很大程度上取决于数据的质量。如果训练数据中缺乏高质量的写作数据、对话数据等等,自然就不可能产生高质量的文章和高质量的对话。
数据量:对于深度学习模型,需要大量的训练数据才能从中学习到复杂的模式。如果数据量不足,模型可能无法从中捕获到有用的信息,从而对未见过的新数据做出准确预测。一句话来说,限制模型对复杂长尾模式的学习能力。
数据代表性:训练数据必须真实反映真实世界的情况,在所有可能的输入空间中都有良好的覆盖。否则,模型可能会在面对未见过的情况时表现不佳。
数据多样性:训练集的数据应该具有高度多样性。这样,模型可以学习到训练数据中的一般特征,而不是特定于某些特例的特征。
而Llama 2不仅仅是在训练数据量的层面相比上一代Llama 1增加了40%,而且在数据来源和丰富性上也有了很大的改善。但Llama 2在论文中对数据来源的细节却没有过多表述。这也更加说明了,数据来源对模型效果的关键性影响。

在Llama 2以及Llama-2-chat模型的训练中,数据对模型效果起到了至关重要的作用。那么问题来了,除了众所周知的数据外,还有没有哪些数据是提之甚少或秘而不宣,但对模型效果起到了非常重要的作用呢?
由于笔者没有参与Llama 2的训练,自然没法直接回答。
但是,笔者在Llama的官网注意到,在众多Llama 2的全球合作伙伴,有一家公司叫海天瑞声。
海天瑞声的COO李科及CTO黄宇凯也出现在了Llama 2的supporters list里面,支持Meta的这种开源行为,可以让每个人都能从这个技术中受益良多,并为技术带来足够的透明度、审慎性和可信性。

笔者不禁好奇的扒了一下海天瑞声,发现这家公司确实不简单。
根据官网介绍:
海天瑞声(股票代码:688787)成立于2005年,是我国最早从事AI训练数据解决方案提供商之一。海天瑞声作为AI数据行业首家主板上市公司,致力于为AI企业、研发机构提供AI数据集及服务。
海天瑞声向全行业提供多语言、跨领域、跨模态的人工智能数据及相关数据服务,涵盖智能语音(语音识别、语音合成等)、计算机视觉、自然语言等多个核心领域,覆盖全球近200个主要语种及方言。
深耕行业近20年,与阿里巴巴、腾讯、百度、科大讯飞、海康威视、字节跳动、微软、亚马逊、三星、中国科学院、清华大学等全球810家科技互联网、社交、IoT、智能驾驶等领域的主流企业,以及教育科研机构等建立了深度合作关系,以专业、可靠、安全的数据服务,成功交付数千个定制项目,深得客户信赖。依托覆盖70多个国家、近200种语言及方言的优质资源,技术完善的算法研发团队,经验丰富的项目团队,全方位助力AI前沿项目的全球商业落地。
尤其要强调的,就是其在多语言数据集方面的能力,这个对于大模型基础能力的训练来说是十分重要的保障。
笔者深入挖掘了一下,发现海天瑞声还在大模型数据领域打造了一套完整的文本标注一体化平台,并汇聚众多特定垂类领域背景的本硕专业人才,在能够满足大模型迭代周期频繁、高质量数据集需求、特定领域知识等各类需求,并确保数据的安全合规。

也难怪,在这样强大的数据提供商的能力加持下,无论是预训练,还是微调、RLHF,大模型的基础到专业能力都会有一个比较扎实的保障。
超大规模中文千万轮对话数据集:DOTS-NLP-216
Llama 2发布的同时,海天瑞声也发布了一个符合中国人语言表达习惯的超大规模中文多轮对话数据集——DOTS-NLP-216。
这个数据集有多大呢?
Token数量达到了上亿规模,对话轮数高达千万轮!
我们知道,当前在中文对话领域,公开的数据集往往量少、分布有偏、价格昂贵甚至不能商用。这就导致大模型在中文对话方面的能力,相比英文对话,总是显得“略像智障”。尤其是在一些需要比较深的中文语言理解能力的对话场景,无论开源的还是闭源的大模型,都往往表现不佳。
而这份DOTS-NLP-216数据集,不仅仅是数据规模大,而且对话场景覆盖到了工作、生活、校园等方方面面,更是涉及到了金融、教育、娱乐、体育、汽车、科技等诸多领域。
笔者有幸拿到了数据集的一些样本,看了下,质量确实非常高,贴个case感受一下:

在数据集构成上,DOTS-NLP-216包含了对真实场景的对话采集,和高度还原真实场景的模拟对话这两种方式,来兼顾了分布的代表性、多样性和样本规模。
值得注意的是,DOTS-NLP-216是海天瑞声自有版权的数据集,可以授权商用,这意味着DOTS-NLP-216很可能会成为以后中文大模型厂商提升模型中文对话能力必备的数据集。
总的来说,海天瑞声近期发布的DOTS-NLP-216数据集,精准切中了当下大模型训练的刚需问题,无论数据规模、分布的覆盖度、安全合规以及商用方面,都做到了恰到好处。尤其在语言表达方面,笔者发现其非常契合中国人的语言表达习惯,相信这份数据集会让大模型的“中文味”得到一个不错的提升!
最后,附上数据集传送门(也可点击文末【阅读原文】):
参考资料:
[1]https://ai.meta.com/research/publicationsllama-2-open-foundation-and-fine-tuned.chat-models/==Llam
*本文系量子位获授权刊载,观点仅为作者所有。
— 完 —
原标题:《Llama 2唯一中国合作伙伴,刚刚曝光》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

