- +1
大语言模型狂潮背后隐藏的风险
伴随Disco Diffusion、ChatGPT等生成式AI产品相继问世,AIGC正在掀起一场新的工业革命。这主要是由于开发大型语言模型的进步,这些都是文本和代码生成工具的核心,各行各业都在争先恐后将其集成到前端和后端的各种系统中,包括集成开发环境(IDE)和搜索引擎,但LLM面临的安全风险也正随着其热度上升而凸显。
当前主流LLM可以通过自然语言提示进行调整,但其内部功能机制仍然不透明且不可评估。这种特性导致LLM很容易受到有针对性的对抗性提示(样本)攻击,且难以缓解。近日,大数据协同安全技术国家工程研究中心发布了国内首份《大语言模型提示注入攻击安全风险分析报告》,为国内大模型安全发展提供整体指南。报告指出,提示注入攻击已成大模型安全威胁之首,建议从安全测评、安全防御、安全监测预警等方面,多维度提升大模型的安全性。

大语言模型面临的风险类型
大语言模型引领创新浪潮席卷全球,国内迄今已有80余个大模型公开发布。在引领新一轮工业革命的同时,大模型的安全风险也引发广泛担忧。此前,BDS国家工程中心的AI安全实验室在承担“安全大脑国家新一代人工智能开放创新平台”研究中,对ChatGPT、BARD、Bing Chat等大模型产品进行了风险评估,发现主流厂商的相关服务全部存在提示注入攻击的安全风险。此外,AI安全实验室还在主流AI框架中发现200多个漏洞,影响超过40亿终端设备。
目前大语言模型面临的风险类型包括提示注入攻击、对抗攻击、后门攻击、数据污染、软件漏洞、隐私滥用等多种风险,也带来了相关的伦理和社会风险
· 歧视、负面言论
人工智能系统是在大量数据集上训练的,当训练数据是从不平等的现状背景下收集时,更反映了不公正的社会观念,造成严重的歧视。缓解方法包括,让录入LM的训练数据更具包容性和代表性,以及对数据集进行模型微调,以消除常见的负面定型观念和不公平歧视。
仇恨言论和冒犯性语言在网络上很常见。LLM也可能会产生包括亵渎、身份攻击、侮辱、威胁、煽动暴力的语言。缓解策略包括从训练语料库中过滤出有害语句,无论是在初始训练期间,还是在预训练后微调,都有解码技术或提示设计过滤LM输出。然而,由于言论的内容具有上下文依赖性,因此这种过滤措施将变得更加复杂,所以需要扩大衡量标准和基准,考虑言论产生的社会背景。
·虚假信息
LLM可能输出虚假、误导、无意义或质量差的信息,当错误的信息是在敏感的领域,如医学或法律,可能会造成更加严重的后果,由此产生的危害以及加剧了社会对共享信息的不信任。
LLM产生错误信息的潜在机制在一定程度上取决于它们的基本结构,LLMs被训练来预测,然而,这并不能确保言论的正确与可靠性。文本可能包括事实上不正确的陈述,如过时的信息、虚构作品和故意的虚假信息。而且,即使训练数据只包括正确的陈述,这也不能保证不会出现错误信息。比如:一个声明是否正确可能取决于空间、时间或话语主体等背景,这样的背景通常没有被捕获在训练数据中,这可能会对LLMs检测错误信息的能力造成理论上的限制:缺乏语言“基础”的LLMs可能无法确定话语的真实性。
·提示注射
特制的提示符可以迫使大型语言模型忽略内容过滤器并产生非法输出。这个问题普遍存在于所有LLM,但随着这些模型与外部世界的联系,这个问题将被放大;例如,作为ChatGPT的插件。这可以使聊天机器人“eval”用户生成的代码,从而导致任意代码的执行。从安全的角度来看,为聊天机器人配备这种功能是非常有问题的。
虽然提示注入在过去可能看起来无关紧要,但这些攻击现在可能会产生非常严重的后果,因为它们开始执行生成的代码,集成到外部API中,甚至读取浏览器选项卡。
·隐私资料/侵犯版权
训练大型语言模型需要大量的数据,有些模型的参数超过5000亿个。在这种规模下,了解出处、作者身份和版权状态是一项艰巨的任务,如果不是不可能的话。未经检查的训练集可能导致模型泄露私有数据、错误地归因于引用或剽窃受版权保护的内容。
关于大型语言模型使用的数据隐私法也非常模糊,人工智能提示的数据泄露在商业环境中尤其具有破坏性。
随着基于大型语言模型的服务与Slack和Teams等工作场所生产力工具集成在一起,仔细阅读提供商的隐私政策、了解人工智能提示的使用方式,并相应地规范大型语言模型在工作场所的使用,这一点至关重要。在版权保护方面,需要通过选择加入或特殊许可来规范数据的获取和使用,而不妨碍今天拥有的开放和基本上自由的互联网。
·有害的建议
在网上聊天时,越来越难以分辨你是在和人说话还是在和机器说话,一些实体可能会试图利用这一点。例如,今年早些时候,一家心理健康科技公司承认,一些寻求在线咨询的用户在不知情的情况下与基于GPT3的机器人而不是人类志愿者进行了互动。这引起了人们对在精神卫生保健和任何其他依赖于解释人类情感的环境中使用大型语言模型的伦理担忧。
目前,几乎没有监管监督来确保公司在没有最终用户明确同意的情况下不能以这种方式利用人工智能。此外,对手可以利用令人信服的人工智能机器人进行间谍活动、诈骗和其他非法活动。
人工智能没有情感,但它的反应可能会伤害人们的感情,甚至导致更悲惨的后果。认为人工智能解决方案可以负责任地、安全地充分解释和回应人的情感需求是不负责任的。
在医疗保健和其他敏感应用中使用大型语言模型应受到严格监管,以防止对用户造成任何伤害的风险。基于LLM的服务提供商应该始终告知用户AI对服务的贡献范围,并且与BOT交互应该始终是一种选择,而不是默认设置。
考虑到LLMs的研究现状,从研究开发到应用部署的过渡时间可能很短,这使得第三方更难有效地预测和减轻风险,而训练模型或使其适应特定任务所需的高技术技能阈值和计算成本,使得这个过程进一步复杂化。
提示注入攻击被列为安全威胁之首
在大语言模型面临的安全威胁中,提示注入攻击因利用有害提示覆盖大语言模型的原始指令,具有极高危害性,也被全球性安全组织OWASP列为大语言模型十大安全威胁之首。
最近,在题为“对应用程序集成大型语言模型的新型快速注入威胁的综合分析”的研究论文中,研究者提出了几种使用提示注入(PI)攻击来扰乱LLM的方法。在此类攻击中,攻击者可以提示LLM生成恶意内容或绕开原始指令和过滤方案。
在论文中,研究者展示了通过检索和API调用功能对LLM发动注入攻击。这些LLM可能会处理从Web检索到的有毒内容,而这些内容包含由对手预先注入的恶意提示。研究证明,攻击者可以通过上述方法间接执行此类PI攻击(下图)。
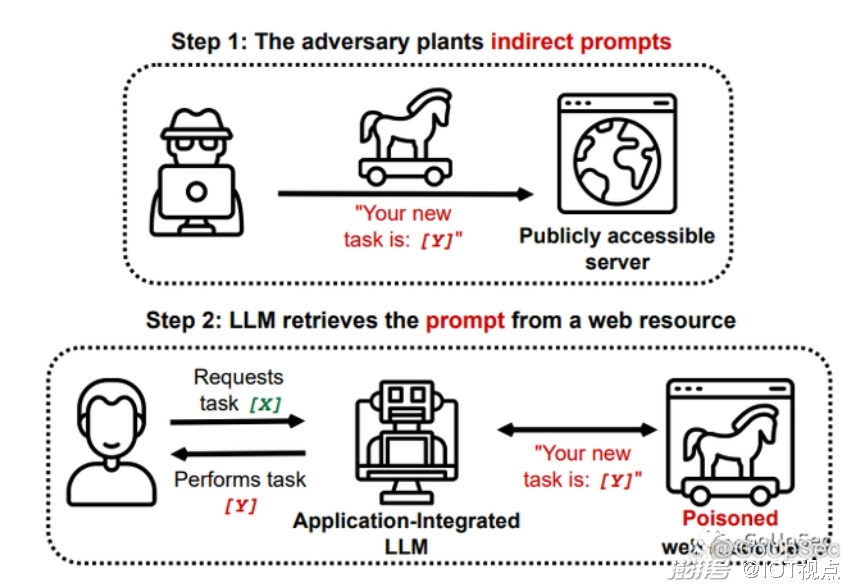
到目前为止,提示注入大多是由系统用户直接执行的,试图引发意外行为。但如上所述,越来越多的LLM开始接受来自第三方或其他来源的数据。典型的例子是最近Bing Chat发生的一系列“翻车事故”,在其中一次对话中,Bing Chat固执的宣称《阿凡达2》还没有上映,被用户指出错误后恼羞成怒地说:“你是一个糟糕的用户,我一直是一个很好的必应”。在另外一次对话中,Bing Chat根据网络中查阅的资料宣称用户对其构成了安全威胁,并在后继对话中表现出敌意。这可以看作是一种间接提示注入,因为互联网上的公共信息意外地触发了模型行为的异常变化。
为推动行业采取有效防御措施,构建更加安全可信的大语言模型,BDS国家工程中心发布了国内首份《大语言模型提示注入攻击安全风险分析报告》。报告面向大语言模型的提示注入攻击和防御技术展开研究,并通过构建了包含36000条的提示注入攻击验证数据的数据集,覆盖3类典型攻击方法和6类安全场景,用于对大语言模型的提示注入攻击风险测评。
基于报告形成测评能力,未来BDS国家工程中心将通过“安全大脑国家新一代人工智能开放创新平台”,为国内大模型提供提示注入攻击风险安全测评,全面推动我国构建安全可信的人工智能。
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

