- +1
ChatGPT充当大脑,指挥AudioGPT解决语音、音乐、音效等任务
机器之心专栏
机器之心编辑部
能说会唱的 AudioGPT 惊艳亮相。
最近几个月,ChatGPT、GPT-4 横空出世,火爆出圈,大型语言模型 (LLM) 在语言理解、生成、交互和推理方面表现出的非凡能力,引起了学界和业界的极大关注,也让人们看到了 LLM 在构建通用人工智能 (AGI) 系统方面的潜力。
现有的 GPT 模型具有极高的语言生成能力,是目前最为先进的自然语言处理模型之一,广泛应用于对话、翻译、代码生成等的自然语言处理领域。除了书面语言,用户在自然对话中主要使用口语 (Spoken Language),而传统大语言模型却无法胜任音频理解与生成任务:
GPT 模态限制。用户在自然对话中主要使用口语,对口语理解与合成有极大需求,而单模态 GPT 不能满足对音频 (语音、音乐、背景音、3D 说话人) 模态的理解、生成需求。
音频数据、模型相对少。基础模型 (Foundation Model) 少或交互性差。相较于文本模态,用于重新训练语音多模态 GPT 的数据较少。
用户交互性差。用户广泛的使用语音助手如 Siri, Alexa 基于自然对话高效地完成工作。然而目前 GPT 之间的交互大多根据键盘输入的文本,交互性差,口语交互更能拉进和用户之间的关系,提升模型易用性。
最近,浙江大学、北京大学、卡内基梅隆大学和中国人民大学的研究人员针对性的解决以上难题,提出了全新的音频理解与生成系统 AudioGPT。AudioGPT 以 ChatGPT 充当负责对话与控制的大脑,语音基础模型协同以完成跨模态转换、以及音频 (语音、音乐、背景音、3D 说话人) 模态的理解、生成,能够解决 20 + 种多语种、多模态的 AI 音频任务。

论文地址:https://arxiv.org/pdf/2304.12995.pdf
Github:https://github.com/AIGC-Audio/AudioGPT
Huggingg Face: https://huggingface.co/spaces/AIGC-Audio/AudioGPT
听觉效果超炫
现在,HuggingGPT 增加了 Gradio 演示:
话不多说,直接看一个 AudioGPT 对话的例子,涵盖文本、图像和语音三种模态的输入,AudioGPT 能够理解不同模态的输入,生成结果也能以文本、图像、音频相结合的方式展现给用户。
语音
Q1: "Generate a speech with text"here we go"."
A1:
Q2: "Transcribe this speech."
A2: Here we go.
Q3: "Separate each speech from the speech mixture."
A3:
音乐
Q4: "Please generate a piece of singing voice. Text sequence is 小酒窝长睫毛 AP 是你最美的记号. Note sequence is C#4/Db4 | F#4/Gb4 | G#4/Ab4 | A#4/Bb4 F#4/Gb4 | F#4/Gb4 C#4/Db4 | C#4/Db4 | rest | C#4/Db4 | A#4/Bb4 | G#4/Ab4 | A#4/Bb4 | G#4/Ab4 | F4 | C#4/Db4. Note duration sequence is 0.407140 | 0.376190 | 0.242180 | 0.509550 0.183420 | 0.315400 0.235020 | 0.361660 | 0.223070 | 0.377270 | 0.340550 | 0.299620 | 0.344510 | 0.283770 | 0.323390 | 0.360340."
A4:
音效
Q5: "Generate an audio of a piano playing."
A5:
Q6: Give me the description of this audio.
A6: The audio is recording of a goat bleating nearby several times.
3D 说话人
Q7: Generate a talking human portrait video.
A7:
此外,论文中还有一个多轮对话与上下文理解的例子:

AudioGPT 语音模型在现有模型中具有不同的优势:
1. 相较于文本 GPT:ChatGPT、GPT4 等语言模型侧重于自然语言处理领域,在多模态理解与合成上福利少了一些,AudioGPT 则将重点放在了音频多模态的理解与生成。
2. 相较于 Siri 等检索模型:与简单检索并以语音回复检索模型相比,AudioGPT 强大的生成式对话,使得用户能够更加实时地获取和处理与内容相关的音频。
3. 相较于视觉任务 GPT:图像不存在像音频一样的语种分类,音频中存在不同语种:如中文、英文、法语等,AudioGPT 还需要进行语种管理。
技术原理
AudioGPT 在收到用户请求时使用 ChatGPT 进行任务分析,根据语音基础模型中可用的功能描述选择模型,用选定的语音基础模型执行用户指令,并根据执行结果汇总响应。借助 ChatGPT 强大的语言能力和众多的语音基础模型,AudioGPT 能够完成几乎所有语音领域的任务。
AudioGPT 为走向语音通用人工智能开辟了一条新的道路。AudioGPT 运行过程可以分成 4 个阶段:模态转化、任务分析、模型分配和回复生成。
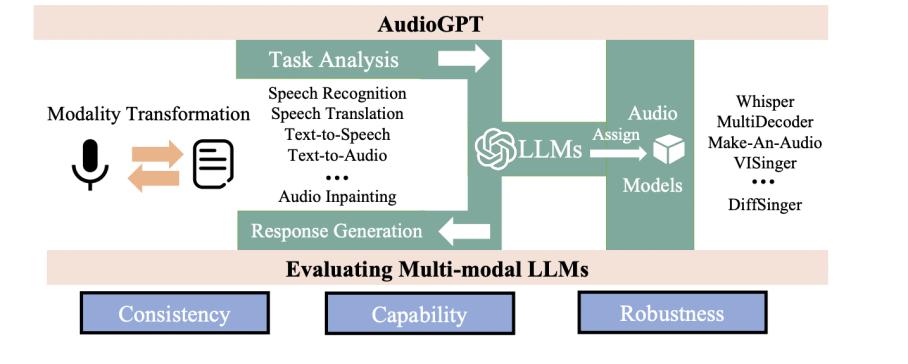
截至目前,AudioGPT 涵盖了语音识别、语音合成、语音翻译、语音增强、语音分离、音频字幕、音频生成、歌声合成等任务。实验结果证明了 AudioGPT 在处理多模态信息和复杂 AI 任务方面的强大能力。
目前多模态的 LLM 层出不穷,Visual ChatGPT,HuggingGPT 等模型吸引了越来越多的关注,然而如何测评多模态 LLM 模型也成了一大难点。为了解决这一难点,研究人员为多模态 LLM 的性能评估设计了测评准则和测评过程。具体来说,AudioGPT 提出从三个方面测评多模态 LLM:
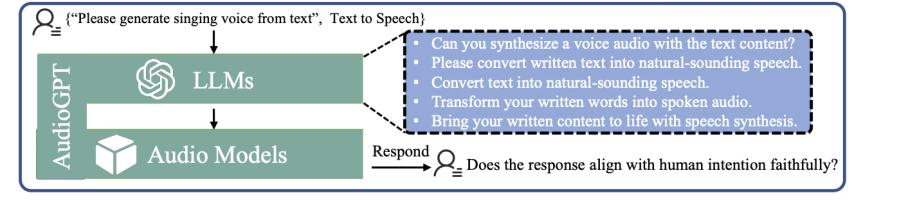
一致性(Consistency):度量 AudioGPT 是否正确的理解用户意图,并为之分配所需的模型
稳定性(Capabilitity):度量基础的语音模型在其特定任务上的性能表现
鲁棒性(Robustness):度量 AudioGPT 是否能正确的处理一些极端的例子
针对一致性,研究人员设计了一套基于人工测评的流程。如下图所示:
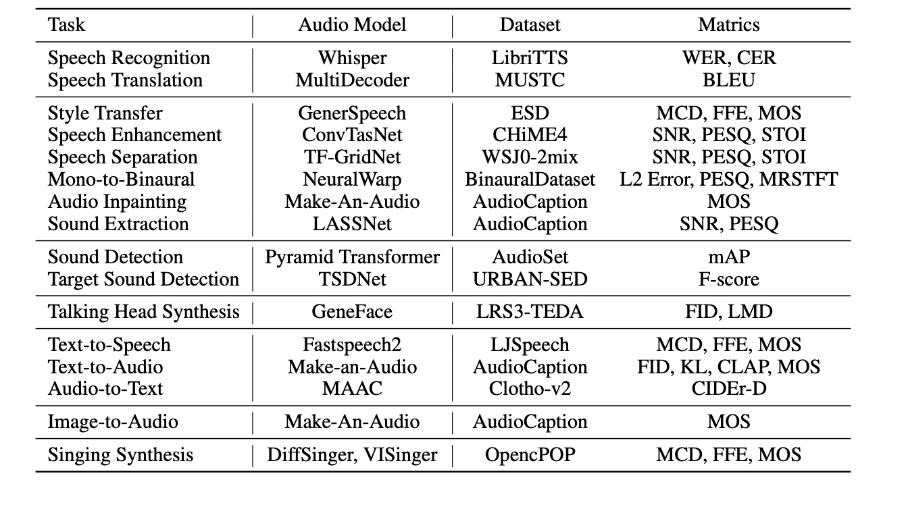
针对稳定性,AudioGPT 调研了各语音基础模型在单任务领域的性能表现。
针对鲁棒性,研究人员从四个方面进行评估:
多轮对话的稳定性:多模态 LLM 应该具备处理多轮对话的能力并且能处理上下文关系
不支持的任务:目前多模态 LLM 并非万能的,当收到无法解决的请求时,多模态 LLM 也应该给予用户反馈
错误处理:多模态基础模型可能由于不同的原因而失败,例如不支持的参数或不支持的输入格式。在这种情况下,多模态 LLM 需要向用户提供合理的反馈,以解释遇到的问题并提出潜在的解决方案
上下文中断:多模态 LLM 被期望处理不在逻辑序列中的查询。例如,用户可能会在查询序列中提交随机查询,但会继续执行具有更多任务的先前查询
网友热评
最后,项目刚刚开源,可以在 Github 和 Huggingface 体验。对于这个新工具的诞生,网友们很是兴奋,有人表示:

AudioGPT 是大语言模型在音频处理领域的福利。
还有网友认为,五音不全的也可以借助 AudioGPT 唱歌了:
有网友称,期待在个人 PC 上也能用到这样的模型,将能够创造出丰富多样的音视频内容。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《ChatGPT充当大脑,指挥AudioGPT解决语音、音乐、音效等任务》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2024 上海东方报业有限公司

