- +1
时滞任务中的权重扰动学习VS节点扰动学习:权重扰动学习表现更优
原创 集智编辑部 集智俱乐部
关键词:机器学习,神经网络,权重扰动学习,节点扰动学习
论文题目:Weight versus Node Perturbation Learning in Temporally Extended Tasks: Weight Perturbation Often Performs Similarly or Better
论文来源:Physics Review X
论文链接:https://journals.aps.org/prx/abstract/10.1103/PhysRevX.13.021006
在理论神经科学和机器学习的背景下,出现了很多奖励式学习模型(reward-based learning),依据学习效果选择神经网络参数。此种学习主要有两种实现途径:1.权重扰动学习(weight perturbation,WP);2.节点扰动学习(node perturbation,NP)。基本思想都是利用扰动试探学习效果,若学习效果变好,则往扰动方向改变。
对于没有时间的实验来说,WP 要探索维度等于权重数的空间,而 NP 只需要探索维度等于节点数的空间。由于WP的探索空间更大,所以人们认为NP方法更适合奖励式学习。
然而,最近发表在 PRX 的一篇论文认为,NP 更优越的前提条件(比如:时滞奖励反馈、神经轨迹有效维度较低)在许多生物学情况中并不成立。他们在这篇文章中对具有这些特征的任务的扰动学习进行了分析和数值研究,认为在有时滞奖励的系统中,WP方法优于NP方法。
他们首先介绍了所采用的 WP 和 NP 学习模型。然后推导出时滞线性网络中低维任务,预期误差(LOSS)的解析表达式,从而确定了 WP 优于 NP 的根本原因。此外他们还描绘了区分权重和误差动态的定性特征,通过数值实验,表明:WP 在不同的生物相关和标准网络学习应用中的表现等于或优于 NP。
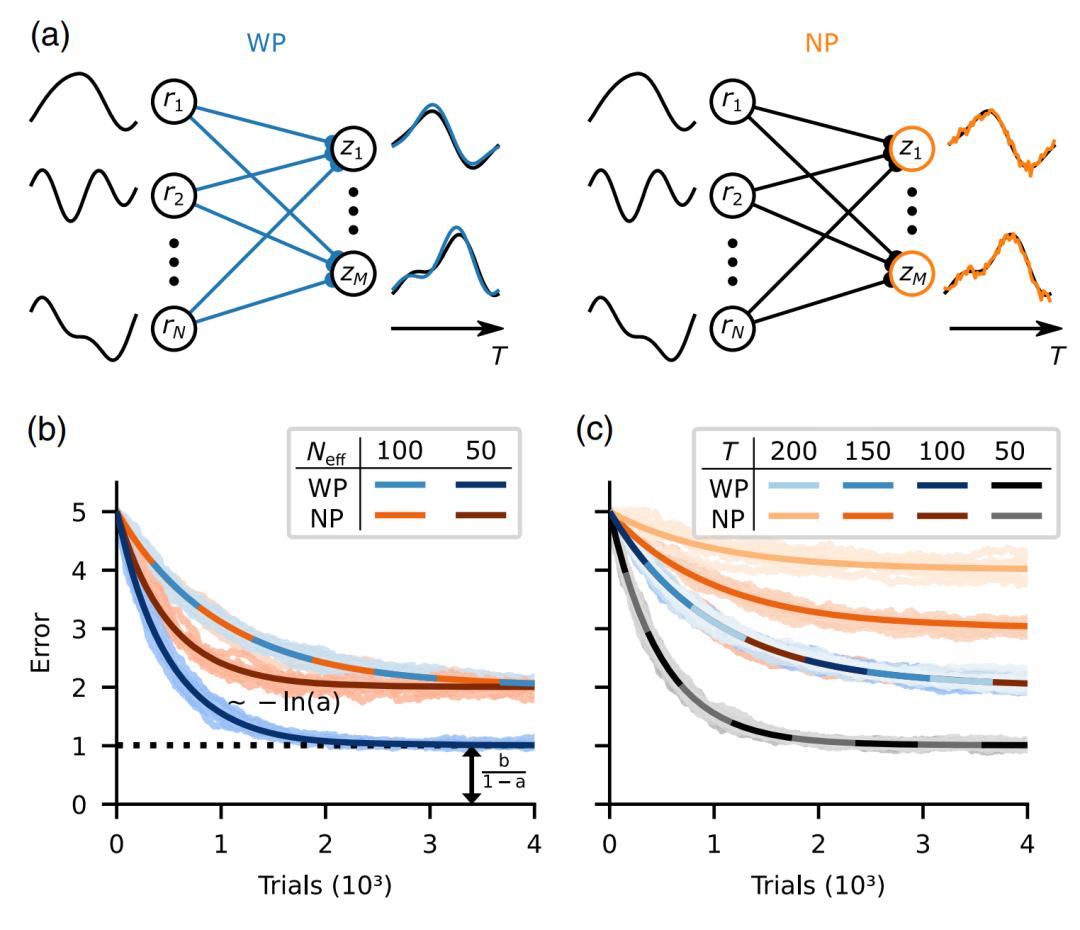
图1. 时滞线性网络任务的学习。
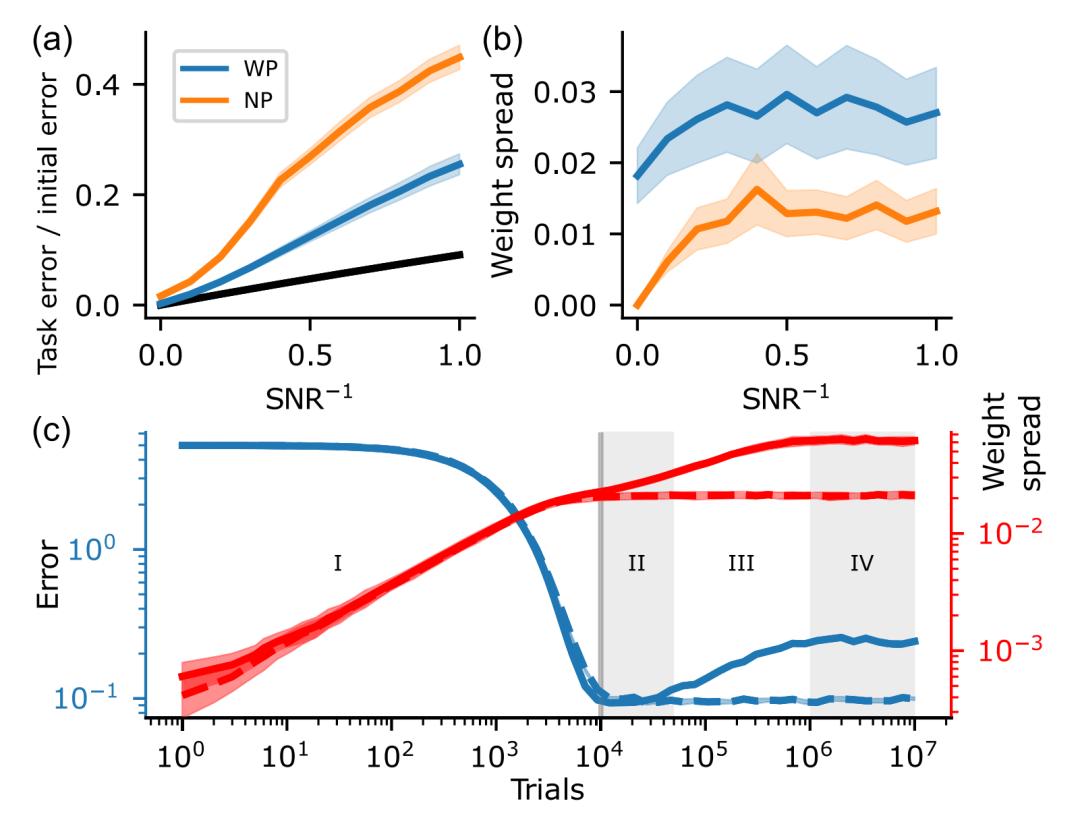
图2. 输入噪声对任务误差和不相关权重扩散的影响。
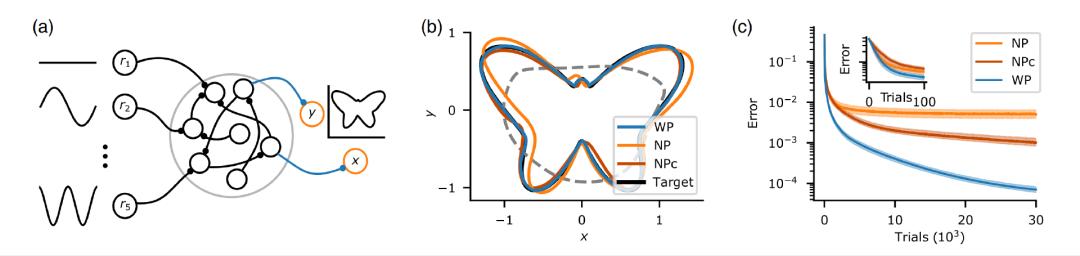
图3. WP在基于reservoir计算的绘图任务上优于NP。
编译|朱欣怡
原标题:《PRX 速递:时滞任务中的权重扰动学习 VS 节点扰动学习: 权重扰动学习表现更优》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2025 上海东方报业有限公司

