- +1
GPT-4充当评测老师,效果惊艳,港中文(深圳)开源凤凰、Chimera等大模型
机器之心专栏
作者:钟格非 (港中文深圳本科生)
港中文(深圳)“凤凰 “多语言大模型,中文效果逼近文心一言,多种语言开源 SOTA;英文版”Chimera” 逼近 ChatGPT(GPT4 评测认为其有 96% GPT 3.5 Turbo 效果),数据模型训练将全开源。
背景介绍
ChatGPT 和 GPT-4 的问世,被比尔・盖茨誉为自 1980 年以来最大的科技革命。近日,相关技术和科研以 "天" 为单位快速迭代,每天都有新的类似 ChatGPT 的模型发布。其中包括 Alpaca、Vicuna、Dolly、Belle、Baize、 Guanaco 和 LuoTuo 等。
近期备受关注的是来自香港中文大学(深圳)和深圳市大数据研究院的王本友教授团队开发的 Phoenix(凤凰) 和 Chimera 等开源大语言模型,其中文效果接近百度文心一言,GPT-4 评测达到了 97% 文心一言的水平,在人工评测中五成不输文心一言。
 此外,维护 Phoenix 和 Chimera 大模型的 github 仓库取名为 “LLM 动物园”,其中还包括其他相关即将发布的模型,如医疗领域的华佗 GPT 模型(huatuogpt.cn)、法律 GPT 模型、多模态大模型和检索增强的大模型等。具体请见其 Github 主页的技术报告。
此外,维护 Phoenix 和 Chimera 大模型的 github 仓库取名为 “LLM 动物园”,其中还包括其他相关即将发布的模型,如医疗领域的华佗 GPT 模型(huatuogpt.cn)、法律 GPT 模型、多模态大模型和检索增强的大模型等。具体请见其 Github 主页的技术报告。 项目地址:https://github.com/FreedomIntelligence/LLMZoo
项目地址:https://github.com/FreedomIntelligence/LLMZoo名字的哲学:凤凰和奇美拉
阻碍大模型发展最大的瓶颈是没有足够的候选名称可用于命名语言模型,LLAMA、Guanaco、Vicuna 和 Alpaca 已经被使用了,而且骆驼家族中已经没有更多的成员了。王本友教授团队将多语言的大模型命名为 “凤凰”。在中国文化中,“凤凰” 通常被视为鸟类之王的象征。正如成语所说,“百鸟朝凤”,表明它能够与说不同的语言的鸟类沟通,称凤凰为能够理解和说出数百种(鸟类)语言的模型。更重要的是,“凤凰” 是 “香港中文大学(深圳)”(CUHKSZ)的图腾,开发团队来自这个高校。
专门针对拉丁语的 “凤凰” 版本被称为 “奇美拉”。奇美拉是希腊神话中类似的混合生物,由来自利基亚和小亚细亚的不同动物部分组成。凤凰和奇美拉分别代表了东方和西方文化的传说生物。将它们放在一个动物园里,以期望东西方人民之间共同协作,来平民化 ChatGPT,共同打破 Open (close) AI 的 AI 霸权。
凤凰的技术特点
Phoenix 模型有两点不同之处:
(1)微调技艺:指令式微调与对话式微调的完美结合
Phoenix 模型在后训练阶段精妙地融合了基于指令的微调(Instruction-based tuning)与基于对话的微调(Conversation-based tuning),实现了两者优势的有机互补。这一结合使 Phoenix 模型在处理各类问题时具有更高的灵活性和应变能力。以 Alpaca 为代表的基于指令微调方法能够使得语言模型严格遵循人类指令,有效满足用户的信息需求;以 Vicuna 为代表的基于对话的微调方法则能够提升模型与用户自然交流的能力,提升用户的对话交互体验。凤凰模型将两者结合,不仅提高了模型的实用性,更增强了其在各种应用场景的竞争力。
(2)驾驭多语言:四十余种语言的全球化视野
Phoenix 模型坚持拥抱全球化视野,在预训练(Pre-training)与后训练(Post-training)阶段均广泛运用多种语言的训练数据。这使得 Phoenix 模型在多语言场景下表现出色,能够满足全球使用者的需求。在预训练阶段, Phoenix 模型采用 BLOOM 作为基座模型,相较于仅使用拉丁语系数据训练的 LLaMA 模型, BLOOM 模型在包括拉丁语系和非拉丁语系的多种语言训练数据上训练而成,因此将其作为基座的凤凰模型对于非拉丁语系用户更加友好。在后训练阶段,凤凰模型的指令数据集和对话数据集都涵盖了超过 40 种语言的训练数据,进一步拓展了其多语言的支持能力。因此,凤凰模型不仅在英汉语言上表现卓越,还在已评测的十余种语言中,相较于其他开源模型具备显著优势。
实验结果
中文
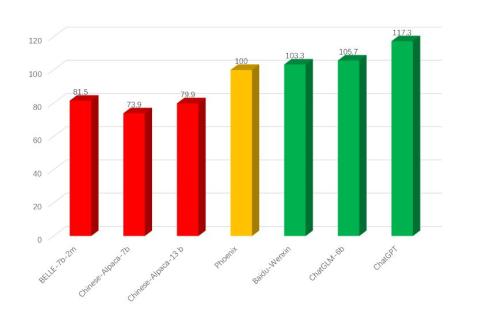 团队成员采用与 Vicuna 一致的评测方式,即使用 GPT-4 作为评估模型,对凤凰模型在多种语言中的性能表现进行了自动评估。图中展示了 Phoenix 在中文语境下与流行的中文模型的对比结果。Phoenix 超其他流行的中文开源模型(包括 BELLE -7B 和 Chinese-Alpaca-13B 等)。这表明,尽管 Phoenix 是一个多语言的模型,但在所有开源的中文模型中,它实现了 SOTA 级别的性能。与其他开源的模型相似,Phoenix 面对 ChatGPT 和文心一言等闭源大规模语言模型时略显逊色(ChatGLM-6B 未开放数据和训练细节,只开源了权重,暂归为半闭源模型家族),但在效果上已能媲美百度开发的文心一言,人工评估中近三成例子比文心一言的输出更好。
团队成员采用与 Vicuna 一致的评测方式,即使用 GPT-4 作为评估模型,对凤凰模型在多种语言中的性能表现进行了自动评估。图中展示了 Phoenix 在中文语境下与流行的中文模型的对比结果。Phoenix 超其他流行的中文开源模型(包括 BELLE -7B 和 Chinese-Alpaca-13B 等)。这表明,尽管 Phoenix 是一个多语言的模型,但在所有开源的中文模型中,它实现了 SOTA 级别的性能。与其他开源的模型相似,Phoenix 面对 ChatGPT 和文心一言等闭源大规模语言模型时略显逊色(ChatGLM-6B 未开放数据和训练细节,只开源了权重,暂归为半闭源模型家族),但在效果上已能媲美百度开发的文心一言,人工评估中近三成例子比文心一言的输出更好。多语言
除了中文,Phoenix 在多种语言上表现优异,包括但不限于西班牙语、法语、葡萄牙语、阿拉伯语、日语和韩语,涵盖了拉丁语系和非拉丁语系的多种语言。这是因为 Phoenix 在预训练阶段的基座模型、后训练阶段的指令式微调和对话式微调三个方面都采用了多语言的训练数据,使得其成为真正意义上的第一个多语言开源类 ChatGPT 大模型,为非拉丁语系的人群带来福音。特别地,Phoenix 模型的基座采用 BLOOM 模型,对商用更加友好,对普及 ChatGPT 至世界各个角落,特别是 OpenAI 限制的国家具有显著意义。想象一下,像灯泡和疫苗等现代科技产品都普及到了几乎所有发展中国家,划时代的 ChatGPT 同样应惠及全球所有人口,这正是 "democratize ChatGPT" 浪潮的应有之意。
英文
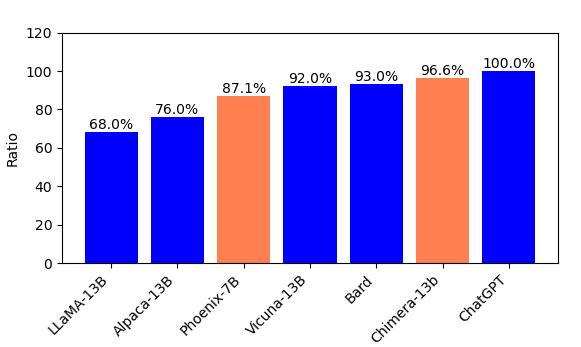
英文方面,在使用 GPT-4 进行评测时,Phoenix-7B 模型的表现超过了 Vicuna-7B 和 ChatGLM-6B,但略逊于 Vicuna-13B。造成这种差距的原因可能有多方面,一方面是模型大小仅为 Vicuna-13B 的一半;另一方面,作者认为 Phoenix 是在多语言环境下训练的,因此额外支付了 “多语言税”(multi-lingual tax),导致其主语言(英语)的表现不如专门针对拉丁语言(英文属于拉丁语言)的 Vicuna-13B。
为了抵消多语言税的影响,作者将多语言的基座模型(BLOOM)替换为仅包含拉丁语言的 LLaMA 模型,以测试其在拉丁语系,特别是英语上的表现。这个拉丁语言版的 Phoenix,被称为 “Chimera”(奇美拉)。再次使用 GPT-4 进行测试,Chimera 的表现达到了 96.6% 的 ChatGPT 水平,略超过 Vicuna-13B 和 BARD 等模型。
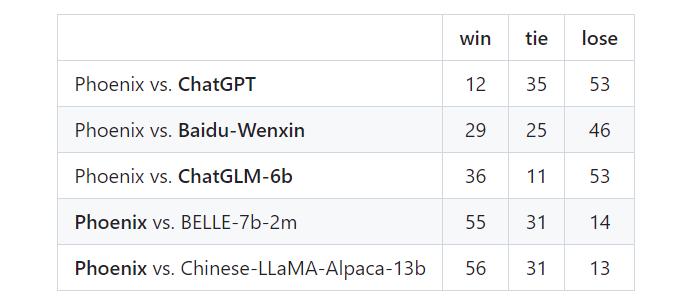
 人工评测
人工评测虽然上述的自动评测方法源自 Vicuna 的评测方式,即用 GPT-4 作为评估模型进行评测,但是使用的评测数据无论是类型还是数量都是偏少的。出于对评估可靠性的进一步考虑,香港中文大学(深圳)的团队采用人工评测的方式来评估中文大模型。人工评测的结果与 GPT-4 在中文大模型评测的结果高度一致。人工评估效果顺序为:ChatGPT、ChatGLM-6B、文心一言、凤凰、BELLE 和 Chinese-LLaMA-Alpaca -- 这与 GPT 4 的评测一样。这也是首次将 GPT-4 的结果与人工评估结果进行比较的研究。
 综上所述,Phoenix 和 Chimera 等开源大语言模型在中文和多种语言环境下都展现出了优异的表现,无论是在中文开源模型中还是在拉丁语系中。这些模型的发展将有助于推动 ChatGPT 技术在全球范围内的普及,让更多人受益于这一划时代的科技成果。© THE END
综上所述,Phoenix 和 Chimera 等开源大语言模型在中文和多种语言环境下都展现出了优异的表现,无论是在中文开源模型中还是在拉丁语系中。这些模型的发展将有助于推动 ChatGPT 技术在全球范围内的普及,让更多人受益于这一划时代的科技成果。© THE END转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
原标题:《GPT-4充当评测老师,效果惊艳,港中文(深圳)开源凤凰、Chimera等大模型》
本文为澎湃号作者或机构在澎湃新闻上传并发布,仅代表该作者或机构观点,不代表澎湃新闻的观点或立场,澎湃新闻仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。



- 报料热线: 021-962866
- 报料邮箱: news@thepaper.cn
互联网新闻信息服务许可证:31120170006
增值电信业务经营许可证:沪B2-2017116
© 2014-2026 上海东方报业有限公司

